 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Решение. Статистический ряд: Значение частота
|
|
Вариационный ряд: 1, 2, 3, 3, 5, 6, 6.
Статистический ряд:
| Значение | |||||
| частота |
Мода – значение, имеющее наибольшую частоту – 3.
Медиана – значение в середине вариационного ряда. Поскольку число членов ряда четно, то медиана – среднее арифметическое средних соседних элементов (в нашем случае – четвертого и пятого), т.е. тоже 3.
Среднее (сумма всех значений, деленная на число элементов) – (1+2+3+3+3+5+6+6)/8 = 29/8 = 3,625.
Выборочная дисперсия (смещенная оценка): Dв = 
Несмещенная оценка выборочной дисперсии: Dнесм=  .
.
Dв = (1×1+4×1+9×3+25×1+36×2)/8 – (3,625)2» 16,125 - 13,141» 2,984.
График эмпирической функции распределения приведен на рис. 6.2.
 |
Рис. 6.2.
6.2. Системы случайных величин
(Многомерные случайные величины)
До сих пор мы рассматривали только одномерные случайные величины, возможные значения которых определялись одним числом. Однако в результате испытания мы можем получать и несколько характеристик объекта (например, число листьев и длину стебля растения; высоту собаки в холке, ее возраст, вес и расстояние от кончика носа до кончика хвоста) – т.е. систему случайных величин Х1, Х2, …, Хn или, иначе говоря, многомерную (n-мерную) случайную величину (случайный вектор) Х=(Х1, Х2, …, Хn ).
Геометрически двумерную (n=2) случайную величину можно истолковать как точку на плоскости со случайными координатами, трехмерную (n=3) – как точку трехмерного пространства и т.д. Мы ограничимся рассмотрением двумерных случайных величин или систем из двух случайных величин.
Для описания системы случайных величин можно использовать математическое ожидание и дисперсию составляющих, а также функции распределения.
Функция распределения двумерной случайной величины Х=(Х, Y) – функция F(Х, Y), выражающая вероятность совместного выполнения неравенств Х<x и Y <y, т.е. F(х, y) = Р(Х<x, Y<y).
Введем еще несколько понятий применительно к системе двух случайных величин.
Назовем две случайные величины независимыми, если закон распределения одной из них не зависит от того, какие значения приняла другая величина.
Теорема: Для того чтобы случайные величины Х и Y были независимыми, необходимо и достаточно, чтобы функция распределения системы (Х, Y) была равна произведению функций распределения составляющих: F(x,y)=F1(x) F2(y).n
Для независимых случайных величин X и Y верно следующее:
М (XY) = М X М Y
D (X + Y) = D (X) + D (Y).
Ковариация – числовая характеристика совместного распределения случайных величин, равная математическому ожиданию произведения отклонений случайных величин от своих математических ожиданий:
mху= М [(Х- М (Х)) (Y- М (Y))]
Другие обозначения: Kxy, cov(X,Y)
Коэффициент корреляции rxy случайных величин Х и Y – отношение ковариации к произведению средних квадратических отклонений этих величин:
rxy = mху /(sхsу)
Коэффициент корреляции (r)[8] измеряет силу линейной связи между случайными величинами. Значение его изменяется от –1 до 1. Рис. 6.3 иллюстрирует соотношения между переменными при r = 1, r = -1, r = 0.
| r = 1 | r = -1 | r = 0 |
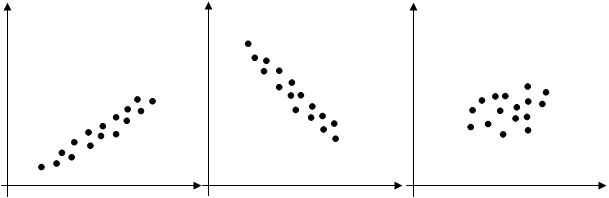
Рис. 6.3.
На практике формулировка вопроса о зависимости между случайными величинами определяется конкретной ситуацией, соответственно должны быть разработаны и различные методы получения ответа на этот вопрос. Рассмотрим три естественно возникающих задачи.
Задача 1. Установить факт зависимости (независимости) двух случайных величин.
Задача 2. Измерить степень зависимости двух случайных величин.
Задача 3. Установить форму зависимости между случайными величинами и дать прогноз значений зависимой случайной величины.
Заметим, что по сути дела речь идет о том, насколько эмпирические данные исследований согласуются с гипотезой. Каждая задача сводится к соответствующей статистической гипотезе, т.е. предположению о законе распределения случайной величины, в проверке которой и заключается решение задачи.
Дата публикования: 2014-10-25; Прочитано: 446 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
