 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Линейная регрессия. Регрессионный анализ - раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по
|
|
Регрессионный анализ - раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным. Проблема регрессии в математической статистике характерна тем, что распределениях изучаемых величин нет достаточной информации.
Цель РА состоит в определении общего вида уравнения регрессии, построении оценок неизвестных параметров, входящих в уравнение регрессии и проверке статистических гипотез о регрессии. При изучении связи между двумя величинами по результатам наблюдений (х1, у1),…, (хn,yn) в соответствии с теорией регрессии предполагается, что одна из них У имеет некоторое распределение вероятностей при фиксированном значении х другой, так что
Е(У|х) =g(х,b) и D(У|х)=s2h2(x),
где b обозначает совокупность неизвестных параметров, определяющих функцию g(х), а h(х) есть известная функция х (в частности, тождественно равная 1) и нужно по результатам наблюдений определить значения параметров. Выбор модели регрессии определяется предположениями о форме зависимости g(x,b) от х и b. Наиболее естественной с точки зрения единого метода оценки неизвестных параметров b является модель регрессии, линейная относительно b:
g(x,b)=b0g0(x)+…+bkgk(x).
Относительно значений переменной х возможны различные предположения в зависимости от характера наблюдений и целей анализа. Для установления связи между величинами в эксперименте используется модель, основанная на упрощённых, но правдоподобных допущениях: величина х является контролируемой величиной, значения которой заранее задаются при
планировании эксперимента, а наблюдаемые значения у представимы в виде
Уi =g(xi,b)+еi, i = 1,…,k,
где величины еi характеризуют ошибки, независимые при различных измерениях и одинаково распределенные с нулевым средним и постоянной дисперсией s2.
Случай неконтролируемой переменной х отличается тем, что результаты наблюдений (хi, уi),…,(xn, уn) представляют собой выборку из некоторой двумерной совокупности. И в том, и в другом случае РA производится одним и тем же способом, однако интерпретация результатов существенно различается (если обе исследуемые величины случайны, то связь между ними изучается методами корреляционного анализа).
Предварительное представление о форме графика зависимости g(х) от х можно получить по расположению на диаграмме рассеяния (называемой также корреляционным полем, если обе переменные случайные) точек (хi,y(xi)), где у(xi) - средние арифметические тех значений у, которые соответствуют фиксированному значению хi. Например, если расположение этих точек близко к прямолинейному, то допустимо использовать в качестве приближения линейную регрессию. Стандартный метод оценки линии регрессии основан на использовании полиномиальной модели
у(х,b)=b0+b1x+…+bmxm
(этот выбор отчасти объясняется тем, что всякую непрерывную на некотором отрезке функцию можно приблизить полиномом с любой на заданной степенью точности). Оценка неизвестных коэффициентов регрессии b0…bm и неизвестной дисперсии s2 осуществляется методом наименьших квадратов.
Оценки 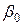 ,…,
,…,  параметров b0…bm, полученные этим методом, называются выборочными коэффициентами регрессии, а уравнение
параметров b0…bm, полученные этим методом, называются выборочными коэффициентами регрессии, а уравнение
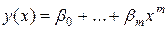
определяет т.н. эмпирическую линию регрессии. Этот метод в предположении нормальной распределенности результатов наблюдений приводит к оценкам для b0…bm и s2,совпадающим с оценками наибольшего правдоподобия. Оценки, полученные этим методом, оказываются в некотором смысле наилучшими и в случае отклонения от нормальности. Так, если проверяется гипотеза о линейной регрессии, то
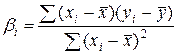 ,
,  ,
, 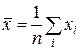 ,
, 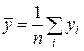 ,
,
где x и у - средние арифметические значений хi и уi, и оценка g(x)= 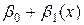 - будет несмещенной для g(x), а её дисперсия будет меньше, чем дисперсия любой другой линейной оценки:
- будет несмещенной для g(x), а её дисперсия будет меньше, чем дисперсия любой другой линейной оценки:
 .
.
Случайные величины ,…, называются выборочными коэффициентами регрессии. Многочлен 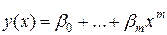 , построенный методами наименьших квадратов, называется эмпирической линией регрессии.
, построенный методами наименьших квадратов, называется эмпирической линией регрессии.
Если дисперсия зависит от x, то метод наименьших квадратов применим с некоторыми видоизменениями.
Если изучается зависимость случайной величины y от нескольких переменных x1,…,xk, то общую линейную модель регрессии удобнее записывать в матричной форме: вектор наблюдений y с независимыми компонентами y1,…,yn имеет среднее значение и ковариационную матрицу
E(y| x1,…,xk)=xb, D(y| x1,…,xk)= 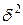 I (*), где b=(b1,…,bk) – вектор коэффициентов регрессии, X=||xij||, i=1,…,n, j=1…k,- матрица известных величин, связанных друг с другом, вообще говоря, произвольным образом, I – единичная матрица n-го порядка; при этом n>k и |XTX|
I (*), где b=(b1,…,bk) – вектор коэффициентов регрессии, X=||xij||, i=1,…,n, j=1…k,- матрица известных величин, связанных друг с другом, вообще говоря, произвольным образом, I – единичная матрица n-го порядка; при этом n>k и |XTX| 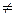 0. В более общем случае допускается корреляция между наблюдениями yi:
0. В более общем случае допускается корреляция между наблюдениями yi:
E(y| x1,…,xk)=xb, D(y| x1,…,xk)= А, где матрица А известна, но эта схема сводится к модели (*). Несмещенной оценкой b по методу наименьших квадратов является величина 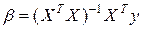 , а смещенной оценкой для служит
, а смещенной оценкой для служит 
Модель (*) является наиболее общей линейной моделью, поскольку она применима к различным регрессионным ситуациям и включает в себя все виды параболической регрессии y по x1,…,xk. При таком линейном понимании РА задача оценки b и вычисления ковариационной матрицы оценок Db= (XTX)-1 cводится к задаче обращения матрицы XTX.
Указанный метод построения эмпирической регрессии в предположении нормального распределения результатов наблюдений приводит к оценкам для b и , совпадающим с оценками наибольшего правдоподобия. Однако оценки, полученные этим методом, являются в некотором смысле наилучшими и в случае отклонения от нормальности, если только объем выборки достаточно велик.
Задачи РА не ограничиваются построением точечных оценок параметров b и общей линейной модели (*). Проблема точности построенной эмпирической зависимости наиболее эффективно разрешается при допущении, что вектор наблюдений y распределен нормально.
При допущении, что величины yi  нормально распределены, наиболее эффективно осуществляется проверка точности построенной эмпирической регрессионной зависимости и проверка гипотез о параметрах регрессионной модели. В этом случае построение доверительных интервалов для истинных коэффициентов регрессии b0…bm и проверка гипотезы об отсутствии регрессионной связи bi,=0, i = 1,…,m производится с помощью распределения Стьюдента.
нормально распределены, наиболее эффективно осуществляется проверка точности построенной эмпирической регрессионной зависимости и проверка гипотез о параметрах регрессионной модели. В этом случае построение доверительных интервалов для истинных коэффициентов регрессии b0…bm и проверка гипотезы об отсутствии регрессионной связи bi,=0, i = 1,…,m производится с помощью распределения Стьюдента.
В более общей ситуации результаты наблюдений у1…yn рассматриваются как независимые случайные величины с одинаковыми дисперсиями и математическими ожиданиями
Еуi = b1x1+…+bixki, i = 1,...,n,
где значения хjj, j‚ = 1,...,k предполагаются известными. Эта форма линейной модели регрессии является общей в том смысле, что к ней сводятся модели более высоких порядков по переменным x1…xk,. Кроме того, некоторые нелинейные относительно параметров bi модели подходящим преобразованием также сводятся к указанной линейной форме.
РA является одним из наиболее распространённых методов обработки результатов наблюдений при изучении зависимостей в физике, биологии, экономике, технике и др. областях. На моделях РA. основаны такие разделы математической статистики, как дисперсионный анализ и планирование эксперимента; модели РА широко используются в многомерном статистическом анализе.
Дата публикования: 2014-11-18; Прочитано: 1656 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
