 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Общее назначение
|
|
Любой закон природы или общественного развития может быть выражен в конечном счете в виде описания характера или структуры взаимосвязей (зависимостей), существующих между изучаемыми явлениями или показателями (переменными величинами или просто переменными). Если эти зависимости:
а) стохастичны по своей природе, т. е. позволяют устанавливать лишь вероятностные логические соотношения между изучаемыми событиями А и В, а именно соотношения типа «из факта осуществления события А следует, что событие В должно произойти, но не обязательно, а лишь с некоторой (как правило, близкой к единице) вероятностью Р»;
б) выявляются на основании статистического наблюдения за анализируемыми событиями или переменными, осуществляемого по выборке из интересующей нас генеральной совокупности,
то мы оказываемся в рамках проблемы статистического исследования зависимостей. Соответствующий математический аппарат, будучи таким образом нацеленным в первую очередь на решение основной проблемы естествознания: как по отдельным, частным наблюдениям выявить и описать интересующую нас общую закономерность? — занимает, бесспорно, центральное место во всем прикладном математическом анализе.
Условимся описывать функционирование изучаемого реального объекта (системы, процесса, явления) набором переменных (рис. 1), среди которых:
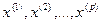 — так называемые входные переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими;
— так называемые входные переменные, описывающие условия функционирования (часть из них, как правило, поддается регулированию или частичному управлению); в соответствующих математических моделях их называют независимыми, факторами-аргументами, экзогенными, предикторными (или просто предикторами, т. е. предсказателями), объясняющими;
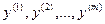 — выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми;
— выходные переменные, характеризующие поведение или результат (эффективность) функционирования; в математических моделях их называют зависимыми, откликами, эндогенными, результирующими или объясняемыми;
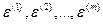 — латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные достаточные» компоненты, отражающие влияние (соответственно на ) неучтенных на входе» факторов, а также случайные ошибки в измерении анализируемых показателей (в математических моделях их, как правило, именуют просто «остатками»).
— латентные (т. е. скрытые, не поддающиеся непосредственному измерению) случайные достаточные» компоненты, отражающие влияние (соответственно на ) неучтенных на входе» факторов, а также случайные ошибки в измерении анализируемых показателей (в математических моделях их, как правило, именуют просто «остатками»).

рис.1. Общая схема взаимодействия переменных при статистическом исследовании зависимостей
Тогда общая задача статистического исследования зависимостей (в терминах изучаемых показателей) может быть сформулирована следующим образом:
по результатам n измерений 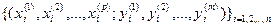 исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию
исследуемых переменных на объектах (системах, процессах) анализируемой совокупности построить такую (векторнозначную) функцию
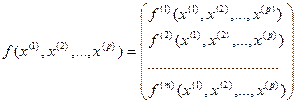 ,
,
которая позволила бы наилучшим (в определенном смысле) образом восстанавливать значения результирующих (прогнозируемых) переменных 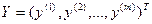 по заданным значениям объясняющих (предикторных) переменных
по заданным значениям объясняющих (предикторных) переменных 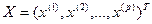 .
.
Данная формулировка задачи нуждается в уточнениях. В частности, прежде всего мы должны ответить на следующие вопросы:
а) каково математическое выражение (или структура модели) искомой зависимости между X и Y, записанное в терминах X, Y, f(X) и 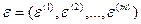 ;
;
б) в соответствии с каким именно критерием качества аппроксимации значений Y с помощью функции f(X) мы будем определять наилучший способ восстановления значений результирующих показателей по заданным значениям объясняющих переменных?
в) с какой именно прикладной целью мы проводим все наше исследование, т. е. для решения каких конкретных задач собираемся использовать построенную в результате исследовании функцию f(X)?
Рассмотрим общую схему. Пусть значение исследуемого результирующего показателя 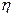 при данных фиксированных величинах объясняющих переменных случайным образом флюктуирует вокруг некоторого (вообще говоря, неизвестного) уровня
при данных фиксированных величинах объясняющих переменных случайным образом флюктуирует вокруг некоторого (вообще говоря, неизвестного) уровня 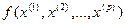 , зависящего от конкретных значений предикторов , т. е.
, зависящего от конкретных значений предикторов , т. е. 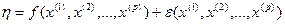 , где остаточная компонента
, где остаточная компонента 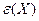 определяет случайное отклонение значения от постоянного (при фиксированных ) уровня f. При этом наличие флюктуации
определяет случайное отклонение значения от постоянного (при фиксированных ) уровня f. При этом наличие флюктуации 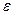 может быть присуще самой природе эксперимента или наблюдения, а может объясняться случайными ошибками в измерении величины f (тогда является результатом несколько искаженного измерения значения f). Когда говорят, что «некоторая величина () случайным образом флюктуирует вокруг определенного (неслучайного) уровня f», то, как правило, имеют в виду, что среднее значение такой флюктуирующей случайной величины должно быть равно f, т. е.
может быть присуще самой природе эксперимента или наблюдения, а может объясняться случайными ошибками в измерении величины f (тогда является результатом несколько искаженного измерения значения f). Когда говорят, что «некоторая величина () случайным образом флюктуирует вокруг определенного (неслучайного) уровня f», то, как правило, имеют в виду, что среднее значение такой флюктуирующей случайной величины должно быть равно f, т. е. 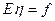 . Поскольку условия эксперимента и, в частности, уровень, около которого флюктуирует , зависят от конкретных значений некоторого набора объясняющих переменных, соответственно
. Поскольку условия эксперимента и, в частности, уровень, около которого флюктуирует , зависят от конкретных значений некоторого набора объясняющих переменных, соответственно 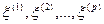 , то
, то 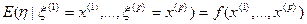 . Функция , описывающая зависимость условного среднего значения
. Функция , описывающая зависимость условного среднего значения 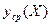 результирующего показателя (вычисленного при условии, что величины предсказывающих переменных зафиксированы на уровнях ) от заданных фиксированных значений предсказывающих переменных, называется функцией регрессии.
результирующего показателя (вычисленного при условии, что величины предсказывающих переменных зафиксированы на уровнях ) от заданных фиксированных значений предсказывающих переменных, называется функцией регрессии.
Происхождение термина «регрессия» (лат. «regression» — отступление, возврат к чему-либо) связано только с прикладной спецификой одного из первых конкретных примеров, в котором это понятие было использовано, но никак не с его общесмысловым наполнением. Этот термин был введен английским психологом и антропологом Ф. Гальтоном в связи с вопросом о наследственности роста. Обрабатывая статистические данные, Гальтон нашел, что сыновья отцов, отклоняющихся по росту на л- дюймов от среднего роста всех отцов, сами отклоняются от среднего роста всех сыновей меньше, чем на х дюймов. Гальтон назвал выявленную тенденцию «регрессией к среднему состоянию» («regression to mediocrity»).
Иногда, при проведении анализа линейной модели, исследователь получает данные о ее неадекватности. В этом случае, его по-прежнему интересует зависимость между предикторными переменными и откликом, но для уточнения модели в ее уравнение добавляются некоторые нелинейные члены. Самым удобным способом оценивания параметров полученной регрессии является Нелинейное оценивание. Например, его можно использовать для уточнения зависимости между дозой и эффективностью лекарства, стажем работы и производительностью труда, стоимостью дома и временем, необходимым для его продажи и т.д. На самом деле Нелинейное оценивание можно считать обобщением методов множественной регрессии и дисперсионного анализа. Так, в методе множественной регрессии (и в дисперсионном анализе) предполагается, что зависимость отклика от предикторных переменных линейна. Нелинейное оценивание оставляет выбор характера зависимости за вами. Например, вы можете определить зависимую переменную как логарифмическую функцию от предикторной переменной, как степенную функцию, или как любую другую композицию элементарных функций от предикторов.
Если позволить рассмотрение любого типа зависимости между предикторами и переменной отклика, возникают два вопроса. Во-первых, как истолковать найденную зависимость в виде простых практических рекомендаций. С этой точки зрения линейная зависимость очень удобна, так как позволяет дать простое пояснение: “чем больше x (т.е., чем больше цена дома), тем больше y (тем больше времени нужно, чтобы его продать); и, задавая конкретные приращения x, можно ожидать пропорциональное приращение y ”. Нелинейные соотношения обычно нельзя так просто проинтерпретировать и выразить словами. Второй вопрос - как проверить, имеется ли на самом деле предсказанная нелинейная зависимость.
Дата публикования: 2014-11-18; Прочитано: 1037 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
