 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Метод Бокса-Уилсона
|
|
Идея метода заключается в использовании метода крутого восхождения в сочетании с последовательно планируемым факторным экспериментом для нахождения оценки градиента.
Процедура состоит из нескольких повторяющихся этапов:
- построение факторного эксперимента в окрестностях некоторой точки;
- вычисление оценки градиента в этой точке по результатам эксперимента;
- крутое восхождение в этом направлении;
- нахождение максимума функции отклика по этому направлению.
Допущения:
- функция отклика непрерывна и имеет непрерывные частные производные на множестве G;
- функция унимодальная (т.е. экстремум - внутренняя точка).

m – номер итерации

α влияет на шаг.  - - оператор Набла
- - оператор Набла

Δх нужно подсчитать
Метод экспериментального поиска экстремума функций многих переменных, соединяет лучшие черты градиентных методов и метода Гаусса – Зайделя. От градиентных методов здесь воспринято выполнение рабочего движения вдоль вектор – градиента, а от метода Гаусса – Зайделя взят принцип продвижения не на один рабочий шаг (как в методе градиента), а до достижения частного экстремума функции отклика, без его корректировки на каждом шаге. Пробные опыты для выяснения направления движения также выполняются по-особому – методом полного факторного эксперимента (или дробного факторного эксперимента)
Например, идея метода Бокса-Уилсона (планирование экстремального эксперимента) крайне проста. Экспериментатору предлагается ставить последовательные небольшие серии опытов, в каждой из которых одновременно варьируются по определенным правилам все факторы. Серии организуются таким образом, чтобы после математической обработки предыдущей можно было выбрать условия проведения (т.е. спланировать условия) следующей серии. Так, последовательно, шаг за шагом, достигается область оптимума. В нашем случае это предполагает выбор оптимальной стратагемы, построение плана действий на ее основе, реализация этого плана, оценка результата и выбор следующей стратагемы.
Схематически процесс эксперимента и его элементы выглядят следующим образом: 
Функция отклика j:y =j(x1, x2, …. xn).
Параметр оптимизации – характеристика цели, заданная количественно.
27. Задача классификации. Дискриминантный анализ
Цель дискриминантного анализа – получение правил для классификации многомерных наблюдений в одну из нескольких категорий или совокупностей. Число классов известно заранее.
Дискриминация в две известные совокупности.
Рассмотрим задачу классификации одного многомерного наблюдения х = (х1,х2,…хр)/ в одну из двух совокупностей. Для этих совокупностей известны р-мерные параметры нормального распределения задаются двумя скалярными величинами (мат. ожиданием и дисперсией), то в многомерном случае первым параметром служит вектор мат. ожиданий, а вторым ф-ции плотностей, Т.е. известны как форма плотности, так и ее параметры. Напомним, что если в одномерном случае – ковариационная матрица. Предположим, что р(1) и р(2) = 1-р(1) априорные вероятности появления наблюдения х из совокупностей 1 и 2.
Тогда по теореме Байеса апостериорная вероятность того, что наблюдение х принадлежит совокупности 1
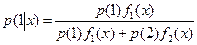
а апостериорная вероятность для х принадлежать совокупности 2

Классификация может быть осуществлена с помощью отношения

Объект относим к классу 1, если это отношение больше 1, т.е. р(1 ׀ х)>1/2, и ко второму классу, если это отношение меньше 1.
Такая процедура минимизирует вероятность ошибочной классификации. При введении функции штрафа (потерь): с(2 ׀ 1) – цена ошибочной классификации наблюдения из совокупности 1 в класс 2, а с(1 ׀ 2) -
цена ошибочной классификации наблюдения из 2 в класс 1, решающее правило принимает вид

Итак, суть дискриминантного анализа состоит в следующем. Пусть известно о существовании двух или более генеральных совокупностей и даны выборки из каждой совокупности. Задача заключается в выработке основанного на имеющихся выборках правила, позволяющего приписать некоторый новый элемент к правильной генеральной совокупности, когда нам заведомо неизвестно о его принадлежности.
Суть дискриминантного анализа – разбиение выборочного пространства на непересекающиеся области. Разделение происходит с помощью дискриминантных функций. Число дискриминантных функций равно числу совокупностей. Элемент (новый) приписывается той совокупности, для которой соответствующая дискриминантная функция при подстановке выборочных значений имеет максимальное значение.
28. Задача классификации. Кластерный анализ; общие положения.
Фактически, кластерный анализ является не столько обычным статистическим методом, сколько "набором" различных алгоритмов "распределения объектов по кластерам". Следует понимать, что кластерный анализ определяет "наиболее возможно значимое решение". Поэтому проверка статистической значимости в действительности здесь неприменима, даже в случаях, когда известны p-уровни (как, например, в методе K средних).
Области применения
Техника кластеризации применяется в самых разнообразных областях. Например, в области медицины кластеризация заболеваний, лечения заболеваний или симптомов заболеваний приводит к широко используемым таксономиям. В области психиатрии правильная диагностика кластеров симптомов, таких как паранойя, шизофрения и т.д., является решающей для успешной терапии. В археологии с помощью кластерного анализа исследователи пытаются установить таксономии каменных орудий, похоронных объектов и т.д. Известны широкие применения кластерного анализа в маркетинговых исследованиях. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным.
Объединение (древовидная кластеризация)
Назначение этого алгоритма состоит в объединении объектов (например, животных) в достаточно большие кластеры, используя некоторую меру сходства или расстояние между объектами. Типичным результатом такой кластеризации является иерархическое дерево.
связываются вместе всё большее и большее число объектов и агрегируете (объединяете) все больше и больше кластеров, состоящих из все сильнее различающихся элементов. Окончательно, на последнем шаге все объекты объединяются вместе. На этих диаграммах горизонтальные оси представляют расстояние объединения (в вертикальных древовидных диаграммах вертикальные оси представляют расстояние объединения). Так, для каждого узла в графе (там, где формируется новый кластер) вы можете видеть величину расстояния, для которого соответствующие элементы связываются в новый единственный кластер. Когда данные имеют ясную "структуру" в терминах кластеров объектов, сходных между собой, тогда эта структура, скорее всего, должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их.
Двувходовое объединение
Оказывается, что кластеризация, как по наблюдениям, так и по переменным может привести к достаточно интересным результатам. Например, представьте, что медицинский исследователь собирает данные о различных характеристиках (переменные) состояний пациентов (наблюдений), страдающих сердечными заболеваниями. Исследователь может захотеть кластеризовать наблюдения (пациентов) для определения кластеров пациентов со сходными симптомами. В то же самое время исследователь может захотеть кластеризовать переменные для определения кластеров переменных, которые связаны со сходным физическим состоянием.
Двувходовое объединение
После этого обсуждения, относящегося к тому, кластеризовать наблюдения или переменные, можно задать вопрос, а почему бы не проводить кластеризацию в обоих направлениях? Модуль Кластерный анализ содержит эффективную двувходовую процедуру объединения, позволяющую сделать именно это. Однако двувходовое объединение используется (относительно редко) в обстоятельствах, когда ожидается, что и наблюдения и переменные одновременно вносят вклад в обнаружение осмысленных кластеров.
Метод К средних
Этот метод кластеризации существенно отличается от таких агломеративных методов, как Объединение (древовидная кластеризация) и Двувходовое объединение. Предположим, вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по переменным). Вы можете указать системе образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода K средних. В общем случае метод K средних строит ровно K различных кластеров, расположенных на возможно больших расстояниях друг от друга.
Обычно, когда результаты кластерного анализа методом K средних получены, можно рассчитать средние для каждого кластера по каждому измерению, чтобы оценить, насколько кластеры различаются друг от друга. В идеале вы должны получить сильно различающиеся средние для большинства, если не для всех измерений, используемых в анализе. Значения F -статистики, полученные для каждого измерения, являются другим индикатором того, насколько хорошо соответствующее измерение дискриминирует кластеры.
Кластерный анализ – совокупность методов, позволяющих классифицировать многомерные наблюдения, каждое из которых описывается набором исходных переменных X1, Х2,.,Xm.
Цель кластерного анализа – формирование групп схожих между собой объектов, которые принято называть кластерами. Claster (англ.) - пучок, группа, класс, таксон, сгущение. Кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных.
Задача классификации. Кластерный анализ; алгоритм Forel.
Кластерный анализ – совокупность методов, позволяющих классифицировать многомерные наблюдения, каждое из которых описывается набором исходных переменных X1, Х2,.,Xm.
Цель кластерного анализа – формирование групп схожих между собой объектов, которые принято называть кластерами. Claster (англ.) - пучок, группа, класс, таксон, сгущение. Кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных.
Для процесса классификации основой служит сходство или различие отдельных объектов.
Количественное оценивание сходства базируется на понятии метрика. Объекты классификации представляются точками координатного пространства, причем замеченные сходства и различия между точками находятся в соответствии с метрическими расстояниями между ними.
Размерность пространства определяется числом переменных, использованных для описания событий.
Характерная особенность итеративных процедур, в частности алгоритмов семейства FOREL, в том, что кластеры формируются исходя из задаваемых условий разбиения (параметров), которые в процессе работы алгоритма могут быть изменены пользователем для достижения желаемого качества разбиения.
FOREL
1. Все данные, которые нужно обработать, представляются в виде точек. Каждой точке соответствует вектор, имеющий n -координат. В координатах записываются значения параметров, соответствующих этим точкам.
2. Затем строится гиперсфера радиуса R1=Rmax, которая охватывает все точки. Если бы нам был нужен один таксон, то он был бы представлен именно этой начальной сферой.
3. Уменьшаем радиус на заранее заданную величину DR, т.е. R2=R1 - DR. Помещаем центр сферы в любую из имеющихся точек и запоминаем эту точку. Находим точки, расстояние до которых меньше радиуса, и вычисляем координаты центра тяжести этих "внутренних" точек. Переносим центр сферы в этот центр тяжести и снова находим внутренние точки. Сфера как бы «плывет» в сторону локального сгущения точек.
Такая процедура определения внутренних точек и переноса центра сферы продолжается до тех пор, пока сфера не остановится, т.е. пока на очередном шаге мы не обнаружим, что состав внут-ренних точек, а, следовательно, и их центр тяжести, не меняются. Это значит, что сфера остановилась в области локального максимума плотности точек в признаковом пространстве.
4. Точки, оказавшиеся внутри остановив-шейся сферы, мы объявляем принадлежа-щими кластеру номер 1 и исключаем их из даль-нейшего рассмотрения. Для оставшихся точек описанная выше процедура повторяется до тех пор, пока все точки не окажутся включенными в таксоны.
5. Каждый кластер характеризуется своим центром. Координаты центра кластера в данном случае вычисляются как средние арифметические соответствующих координат всех точек, попавших в данный кластер.
Здесь появляется параметр DR, определяемый исследователем чаще всего подбором в поисках компромисса: увеличение DR ведёт к росту скорости сходимости вычислительной процедуры, но при этом возрастает риск потери тонкостей таксономической структуры множества точек (объектов). Естественно ожидать, что с уменьшением радиуса гиперсфер количество выделенных таксонов будет увеличиваться.
Если начальную точку менять случайным образом, то может получиться несколько разных вариантов таксономии, и тогда нужно останавливаться на таком варианте, который соответствует минимальному значению величины F.
Дата публикования: 2015-07-22; Прочитано: 3409 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
