 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Поиск в Интернет. Поисковые машины
|
|
Поисковая система – веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet. В последнее время появился новый тип поисковых движков, основанных на технологии RSS. Комплекс программ, обеспечивающий функциональность поисковой системы, называют поисковый движок или поисковая машина. Основными критериями качества работы поисковой машины являются релевантность (степень соответствия запроса и найденного), полнота базы, учёт морфологии языка. Индексация информации осуществляется специальными поисковыми роботами.
Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, который создавал «World Wide Web Wanderer» — бот, разработанный Мэтью Грэйем (англ. Matthew Gray) из Массачусетского технологического института в 1993. Также в 1993 году появилась поисковая система «Aliweb», работающая до сих пор. Первой полнотекстовой (т. н. «crawler-based» – то есть индексирующей ресурсы при помощи робота) поисковой системой стала «WebCrawler», запущенная в 1994. В отличие от своих предшественников, она позволяла пользователям искать по любым ключевым словам на любой веб-странице, с тех пор это стало стандартом во всех основных поисковых системах. Кроме того, это был первый поисковик, о котором было известно в широких кругах. В 1994 был запущен «Lycos», разработанный в университете Карнеги Мелона. В 1996 году русскоязычным пользователям интернета стало доступно морфологическое расширение к поисковой машине Altavista и оригинальные российские поисковые машины Rambler и Aport. 23 сентября 1997 года была открыта поисковая машина Яндекс.
В апреле 1997 был запущен Ask Jeeves как поисковик, позволяющий формулировать запросы на естественном языке. Ask Jeeves использовал людей в качестве редакторов. Ask использовал технологию DirectHit для ранжирования результатов по популярности, но эта технология оказалась неустойчива к спаму. В 2000 году вышел поисковик Teoma, который использовал систему кластеров по теме, спецификации, популярности. В 2001 Ask купил Teoma для того чтобы заменить им технологию DirectHit. AllTheWeb – это поисковая платформа, запущенная в мае 1999 для того, чтобы продемонстрировать возможности быстрых поисковых технологий. У них был глянцевый интерфейс и множество возможностей для продвинутого поиска, но 23 февраля 2003 года AllTheWeb был куплен Overture за 70 миллионов. После того как Yahoo выкупила Overture, они позаимствовали некоторые из технологий AllTheWeb и сейчас иногда используют AllTheWeb как тестовую площадку.
Помимо поисковых машин для Всемирной паутины существовали и поисковики для других протоколов, такие как Archie для поиска по анонимным FTP-серверам и «Veronica» для поиска в Gopher.
Запрос – это формулирование своей информационной необходимости пользователем некоторой поисковой системы. Для составления запроса используется язык поисковых запросов. Все запросы к поисковым системам условно (из-за некоторых случаев неоднозначности) можно разделить на три типа:
- информационные запросы. Пользователь ищет определенную информацию, не заботясь о том, на каком именно веб-сайте он ее обнаружит;
- навигационные запросы. Пользователь ищет сайт, где, по его предположению, содержится интересующая его информация;
- транзакционные запросы. В формулировке запроса пользователь выражает свою готовность совершить какое-либо действие.
Поисковая оптимизация (англ. search engine optimization, SEO) – оптимизация HTML-кода, текста, структуры и внешних факторов сайта с целью поднятия его в выдаче поисковой системы.
Поисковая система учитывает следующие параметры сайта при вычислении его релевантности (степени соответствия введённому запросу):
- частота ключевых слов; сложные алгоритмы современных поисковиков позволяют производить семантический анализ текста, чтобы отсеять поисковый спам, когда ключевое слово встречается слишком часто (более определённого процента от всего содержимого) на странице;
- индекс цитирования сайта, или количество ресурсов, ссылающихся на данный сайт; многими поисковиками не учитываются обратные ссылки (друг на друга), также важно, чтобы ссылки были с сайтов той же тематики, что и раскручиваемый сайт.
Соответственно, работа по оптимизации включает в себя работу с внутренними факторами – приведение текста и разметки страниц в соответствие с выбранными запросами, улучшение качества и количества текста на сайте, оптимизация структуры, навигации и внутренних ссылок сайта, а также внешними факторами – обмен ссылками, регистрация в каталогах и прочие мероприятия для повышения и стимулирования ссылаемости на ресурс. Лицо, проводящее работу по оптимизации, называется оптимизатор.
Поисковые системы состоят из пяти отдельных программных компонент:
- spider (паук): браузероподобная программа, которая скачивает веб-страницы;
- crawler: «путешествующий» паук, который автоматически идет по всем ссылкам, найденным на странице;
- indexer (индексатор): «слепая» программа, которая анализирует веб-страницы, скаченные пауками;
- the database (база данных): хранилище скаченных и обработанных страниц;
- search engine results engine (система выдачи результатов): извлекает результаты поиска из базы данных.
Spider: Паук – это программа, которая скачивает веб-страницы. Он работает точно как браузер, когда происходит соединение с веб-сайтом и загрузка страницы. Паук не имеет никаких визуальных компонент. То же действие (скачивание) можно наблюдать, когда просматривается некоторая страница и когда выбирается «просмотр HTML-кода» в браузере.
Crawler: Как и паук скачивает страницы, он может «раздеть» страницу и найти все ссылки. Это его задача – определять, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов.
Indexer: Индексатор разбирает страницу на различные ее части и анализирует их. Элементы типа заголовков страниц, заголовков, ссылок, текста, структурных элементов, элементов BOLD, ITALIC и других стилевых частей страницы вычленяются и анализируются.
Database: База данных – это хранилище всех данных, которые поисковая система скачивает и анализирует. Это часто требует огромных ресурсов.
Search Engine Results Engine: О, самое сердце зверя. Именно система выдачи результатов решает, какие страницы удовлетворяют запросу пользователя. Это та часть поисковой системы, с который вы имеете дело, осуществляя поиск.
Когда пользователь вводит ключевое слово и делает поиск, поисковая система отбирает результаты на основании постоянно меняющихся критериев. Алгоритмом называется метод, по которому она принимает решение. Профессиональные оптимизаторы (SEO) иногда употребляют термин «algos» – это и есть то, о чем идет речь.
Не смотря на то, что поисковые системы сильно изменились, большинство до сих пор отбирают результаты поиска на основании примерно следующих критериев:
- Title (заголовок): Присутствует ли ключевое слово в заголовке?
- Domain/URL (Домен/адрес): Присутствует ли ключевое слово в имени домена или в адресе страницы?
- Style (стиль): Жирный (STRONG или B), Курсив (EM или I), Заголовки HEAD: если место на странице, где ключевое слово использовано в жирных, курсивных или Hx (H1, H2,…) текстовых заголовках?
- Density (плотность): Как часто ключевое слово употреблено на странице? Количество ключевых слов относительно текста страницы называется плотностью ключевого слова.
- MetaInformation (мета данные): Хотя многие отрицают, некорые поисковые системы до сих пор читают мета ключевые слова (meta keywords) и мета описания (meta description).
- Outbound Links (ссылки наружу): На кого есть ссылки на странице и встречается ли ключевое слово в тесте ссылки?
- Inbound Links (внешние ссылки): Кто еще в Интернет имеет ссылку на данный сайт? Каков текст ссылки? Это называется «внестраничный» критерий, потому что автор страницы не всегда может им управлять.
- Insite Links (ссылки внутри страницы): На какие еще страницы данного сайта содержит ссылки эта страница?
Для выстраивания рейтинга сайтов на основании ключевого запроса алгоритм поисковой системы учитывает: Количество ключевых слов на сайте, Количество ключевых слов на странице, Соотношение общего числа слов на сайте к количеству ключевых слов на сайте, Соотношение общего числа слов на странице к количеству ключевых слов на странице, Индекс цитирования, Популярность тематики, Число запросов по конкретному ключевому слову за определённый период времени, Общее количество веб-страниц сайта, Применение стиля к веб-страницам, Объём текста сайта, Объём сайта, Объём каждой веб-страницы, Объём текста каждой веб-страницы, Возраст сайта, Название URL сайта (имя домена), Периодичность обновления информации на сайте, Последнее обновление страниц сайта, Число картинок (рисунков) на сайте, Количество мультимедийных файлов, Наличие замещающих надписей на рисунках (картинках), Длину (в количестве символов) замещающих надписей рисунков (картинок), Использование фреймов, Язык сайта (русский или иностранный), Размер шрифта, которым оформлены ключевые слова, Жирность шрифта ключевых слов, Написаны в разрядку или нет ключевые слова, Написаны или нет заглавными буквами ключевые слова, Как далеко от начала веб-страницы располагаются ключевые слова, Стиль заголовков и наименований ключевых слов, Наличие и анализ мета-тэгов, Наличие и содержание описания и свойств страницы, Наличие файла «робот», Географическое месторасположение сайта, Комментарии внутри программного кода сайта, К какому типу страниц относится каждая страница сайта: html или asp, Наличие в составе сайта flash модулей, Наличие в составе сайта веб-страниц с незначительными отличиями друг от друга, Соответствие ключевых слов сайта тому разделу каталога поисковой машины, в котором зарегистрирован сайт, Наличие «шумовых слов» («стоп слов»), Общее количество гиперссылок сайта, Количество внутренних гиперссылок сайта, Количество внешних гиперссылок сайта, Взаимное расположение внутренних гиперссылок, Глубина сайта, Ряд других специальных технических параметров.
Многие поисковые машины алгоритма, как такового, вообще не имеют. Их работа сводится к очистке текста сайта от программного кода и выстраиванию слов, встречающихся на сайте по их частоте. Чем сложнее алгоритм работы поисковой машины, тем, с одной стороны, больше вероятность получения наиболее точных и полных результатов, но, с другой стороны, больше вероятность ошибок в работке самого алгоритма.
Усложняя алгоритм работы поисковой машины можно как достичь более полных и точных результатов, так и, наоборот, получить менее точные и полные результаты (рис.2). Любой инженер знает, что чем сложнее какая-либо машина, тем, с одной стороны, она может выполнять больше функций, но, с другой стороны, больше вероятность выхода её из строя.
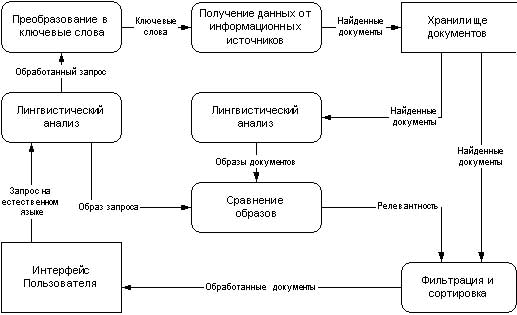
Рис. 2 Алгоритм поиска поисковой системы
Виды поисковых запросов
Поисковые запросы пользователей состоят из различных ключевых слов или словосочетаний. Они в основном составляют семантическое ядро для сайта или блога. Как и многое другое ключевые слова имеют свою классификацию.
Все ключевые слова по частотности запросов делятся на 4 вида: низкочастотные, среднечастотные и высокочастотные, и длинный хвост.
Низкочастотные запросы – это ключевые слова, которые запрашиваются в поисковых системах не чаще чем 1000 раз в месяц. Например, поисковый запрос «приготовление красной икры» является низкочастотным. Создав специальную оптимизированную страницу под такое словосочетание, можно без особых усилий попасть в топ 10 поисковых систем. Это происходит в связи со слабой конкуренцией.
Среднечастотные запросы – это ключевые слова, которые вводят в поиск пользователи в диапазоне от 1000 до 10000 раз в месяц. В этом случае можно привести другой пример. Запрос «красная икра» будет уже являться среднечастотником. Чтобы продвинуться в десятку поисковых систем по таким запросам, необходимо уже приложить больше силы и времени. Здесь не будет достаточно просто создать качественную страницу с текстом. Возможно, придется поставить немного ссылок с других ресурсов и с внутренних страниц сайта.
Высокочастотные запросы – это ключевые слова, которые запрашиваются в поисковиках довольно часто, например, 100.000 раз в месяц. На самом деле нет четкой грани в цифрах, которая бы могла отнести тот или иной запрос к определенной частотности. Все делается по опыту и «на глаз». Примером высокочастотника может служить запрос «икра». Выйти на первую страницу выдачи поисковых систем в данном случае будет уже трудно. Такая работа длиться обычно не менее 2-3 месяцев и носит комплексный характер: грамотная страница, внутренняя перелинковка и качественный линкбилдинг.
Длинный хвост – это поисковые запросы, которые имеют очень маленькую частотность. Другими словами, их ищут в месяц не более 1-10 раз. Например, запрос «приготовление красной икры в домашних условиях летом» относится как раз к длинному хвосту или как еще называют long tail запросу. Несмотря на такую частотность, подобные ключевые слова приносят сайт до 90% всех посетителей. В связи с этим к таким запросам необходимо подходить особенно внимательно.
Дата публикования: 2015-11-01; Прочитано: 1147 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
