 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Оценка рыночной стоимости земельного участка под индивидуальное жилищное строительство с применением метода регрессионного анализа
|
|
Цель работы: изучить методику построения нелинейного уравнения множественной регрессии методом включения; освоить методы проверки адекватности построенной модели; научиться строить точечный и интервальный прогноз, используя полученную модель.
Задачи работы:
1.Методом регрессионного анализа (МРА) выполнить оценку рыночной стоимости земельного участка под индивидуальное жилищное строительство, расположенного в одном из районов Санкт-Петербурга.
2.Интерпретировать результаты решения.
Пояснение к лабораторной работе:
Каждый вариант содержит одну задачу. Исходные данные выдаются преподавателем. Необходимо провести анализ структуры представленных данных, построить модель, проверить её адекватность и провести прогноз (точечный и интервальный). Найти точечное прогнозное значение отклика при условии, что значение каждого значимого фактора меньше максимального значения значимого фактора на 10% величины размаха этого фактора. Интервальный прогноз построить с надежностью 95% при тех же значениях факторов.
Исходные данные для всех вариантов представлены в одной таблице, содержащей 18 столбцов и 120 строк. В первых двух столбцах указаны номер участка и его цена (т.руб./сот.), а остальные столбцы содержат значения факторов, характеризующих каждый участок. Перечень факторов:
1) наличие электричества;
2) наличие водопровода;
3) наличие газа;
4) наличие средств связи;
5) расстояние до ближайшего водного рекреационного объекта, км;
6) расстояние до административного центра, км;
7 расстояние до центра населенного пункта, км;
8) расстояние до ближайшей остановки общественного транспорта, км;
9) расстояние до транспортного узла, км;
10) расстояние до ближайшей торговой точки (магазина, рынка), км;
11) расстояние до медицинского пункта, км;
12) эстетичность ландшафта;
13) загрязненность используемой воды;
14) загрязненность атмосферного воздуха;
15) расстояние до линейных промышленных объектов, км;
16) попадание в зону воздействия промышленных объектов.
Каждый вариант включает 7 столбцов и 80 строк из исходной таблицы. Соответствие между вариантами и номерами строк и столбцов определяется данными табл. 4.
Таблица 4
Варианты заданий
| № | Столбцы | Строки | № | Столбцы | Строки |
| 1,2,3,4,6,7,10 | 1-80 | 1,2,3,4,6,7,10 | 21-100 | ||
| 1,2,4,6,7,10,11 | 11-90 | 1,2,4,6,7,10,11 | 31-110 | ||
| 1,2,3,6,7,10,12 | 21-100 | 1,2,6,7,10,11,12 | 41-120 | ||
| 1,2,4,6,7,10,13 | 31-110 | 1,2,6,7,10,11,13 | 1-80 | ||
| 1,2,4,6,7,10,14 | 41-120 | 1,2,4,6,10,11,14 | 11-90 | ||
| 1,2,3,6,7,10,15 | 1-80 | 1,2,3,6,10,11,15 | 21-100 | ||
| 1,2,3,4,6,10,16 | 11-90 | 1,2,3,6,10,11,16 | 31-110 | ||
| 1,2,6,7,10,12,13 | 41-120 |
Все основные теоретические сведения по построению и использованию уравнения множественной регрессии приведены в [2]. Главные отличия данной работы – это построение нелинейной модели методом включения и построение интервального прогноза.
Множественная регрессия – уравнение связи зависимой переменной 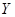 с независимыми переменными
с независимыми переменными 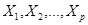 :
:
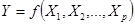 (6)
(6)
В зависимости от вида 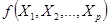 различают линейные и нелинейные уравнения.
различают линейные и нелинейные уравнения.
Линейное уравнение множественной регрессии имеет вид:
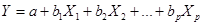 (7)
(7)
где: 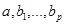 - параметры уравнения
- параметры уравнения
Частным видом нелинейного уравнения множественной регрессии является уравнение вида:
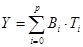 (8)
(8)
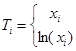 (9)
(9)
где: 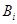 - коэффициенты регрессии.
- коэффициенты регрессии.
Таким образом, в аддитивную модель входят или сами факторы или их логарифмы. Использование логарифма фактора 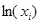 , если фактор
, если фактор 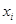 качественный, не имеет смысла. В качестве
качественный, не имеет смысла. В качестве  используем единичный вектор, содержащий n единиц, где n - количество наблюдений, тогда смысл
используем единичный вектор, содержащий n единиц, где n - количество наблюдений, тогда смысл 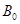 - свободный член в уравнении регрессии.
- свободный член в уравнении регрессии.
Пусть исходные данные приведены в виде таблицы содержащей данные по 114 участкам. Фрагмент таблицы приведен на рис. 1.
Уравнения множественной регрессии могут включать в качестве независимых переменных фиктивные переменные, которые используются для обозначения качественные признаков (наличие электричества, воды, канализации, и др.). Чтобы ввести такие переменные в регрессионную модель присвоим им значения «1» - если данный фактор присутствует, «0» - в противоположном случае.
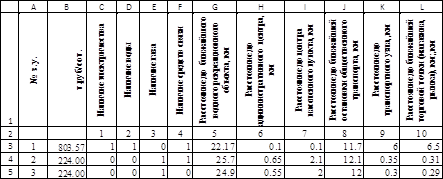
Рис.1. Исходные данные
Для выявления связей между факторами и откликом проведем предварительный анализ, используя инструмент «Анализ данных» >Корреляция. Результат приведен на рис.2.
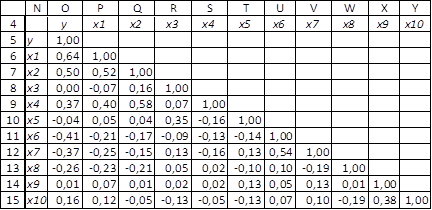
Рис.2. Исходные данные
Анализ коэффициентов парной корреляции показывает, что отклик (цена) заметно коррелирует с факторами «наличие электричества», «наличие воды» и «расстояние до административного центра» (коэффициенты парной корреляции по модулю выше 0.4). Судя по вычисленному коэффициенту корреляции между ценой и фактором «наличие газа» (он практически равен нулю), связь между ними отсутствует. Фактор «наличие средств связи» заметно коррелирован с факторами «наличие электричества» и «наличие воды», что служит доводом в пользу наличия мультиколлинеарности между факторами.
Для построения модели будем использовать пошаговый метод включения, который позволяет избежать включения в уравнение малоинформативных факторов и мультиколлинеарности между ними.
Суть метода включения — в последовательном включении переменных в модель до тех пор, пока качество регрессионной модели будет повышаться. Первыми включаются в регрессионное уравнение факторы, имеющие относительно исследуемого показателя большее значение коэффициента корреляции.
Схема применения этого метода включения для линейной модели подробно описана в [2]. В отличие от чисто линейной модели на каждом шаге необходимо пытаться включить в уравнение не только сам фактор, но и его логарифм (для факторов, не являющихся качественными переменными).
Пусть k – номер шага. На k -м шаге (k =1) с помощью табличной функции ЛИНЕЙН() найдем наиболее информативную переменную среди и . Методом перебора устанавливаем, что это 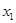 (рис. 3).
(рис. 3).

Рис. 3.
2-й шаг (k=2). Среди всевозможных пар (, ), и (, ) выбирается наиболее информативная пара, путем последовательного применения табличной функции ЛИНЕЙН к различным парам.
Анализируя R 2, приходим к выводу, что наиболее информативной парой является пара (, 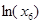 ) (рис. 4).
) (рис. 4).

Рис. 4
С включением коэффициент детерминации существенно вырос, следовательно, это правильное решение.
3-й шаг (k =3). Среди всевозможных троек (, , ), и (, , ), выбирается наиболее информативная (в смысле R 2) тройка. Последовательно применяя табличную функцию ЛИНЕЙН к различным тройкам, приходим к выводу, что наиболее информативной тройкой является (, , 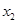 ) (рис.5).
) (рис.5).
С включением x2 коэффициент детерминации существенно вырос, следовательно, его включение оправдано без анализа R 2adj.
4-й шаг (k=4). Среди всевозможных четвёрок (, , , ) и (, , , ), ищется наиболее информативная, путем последовательного применения табличной функции ЛИНЕЙН к различным четвёркам.
Наиболее информативной четвёркой является (, , , 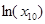 ) (рис. 6-7).
) (рис. 6-7).

Рис. 5
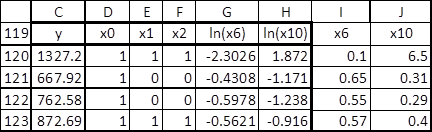
Рис. 6
С включением ln(x10) коэффициент детерминации R 2 существенно вырос, с 0,717 до 0,73, следовательно, его включение оправдано без анализа R 2adj.
5-й шаг (k =5). При добавлении пятой переменной в уравнение регрессии среди всевозможных комбинаций (х1, ln(x6), х2, ln(x10), xj) и (х1, ln(x6), х2, ln(x10), ln(xj)), не удалось найти такую, которая существенно улучшает модель.
Поэтому, более подробно исследуем уравнение, полученное после 4-х шагов.
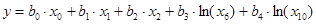 , (10)
, (10)
 .Рис. 7
.Рис. 7
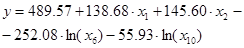 (11)
(11)
Для исследования этой модели, применив инструмент “Регрессия” надстройки «Пакет Анализа» MS Excel (рис. 8). Коэффициент детерминации R2 равен 0,732. Это значение показывает, что 73,2% вариации цены объясняется этим уравнением. Высокое качество уравнения, также подтверждается значимостью уравнения в целом (значимость F существенно ниже уровня значимости в 5%). На рис. 8-9 представлен фрагмент отчёта регрессии по четырем указанным факторам.
В уравнении (11) все коэффициенты значимы, на уровне значимости 5%. Необходимо заметить, что коэффициент при x10 наименее значим (р -значение равно 1,7%).
Дата публикования: 2015-07-22; Прочитано: 342 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
