 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Линейные и нелинейные регрессии
|
|
Линейная регрессия: 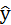 =a+bx+e.
=a+bx+e.
Нелинейные регрессии:
§ гипербола 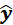 =a+b/x+e,
=a+b/x+e,
§ показательная =abxe,
§ степенная =axbe,
§ экспоненциальная =ea+bx+e и т.д.
Линейная регрессия находит широкое применение на практике ввиду четкой экономической интерпретации ее параметров.
Коэффициент «а» указывает величину Y при х=0, «b» указывает наклон линии регрессии. Коэффициент «b» называется коэффициентом регрессии. Он показывает среднее изменение результата при изменении фактора на единицу.
Регрессионное уравнение 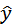 =a+bx+е указывает, что при увеличении «х» на единицу «y» увеличивается на «b» единиц.
=a+bx+е указывает, что при увеличении «х» на единицу «y» увеличивается на «b» единиц.
Регрессионное уравнение =a-bx+е указывает, что при увеличении «х» на единицу «y» уменьшается на «b» единиц.
Оценить параметры уравнений линейной регрессии и нелинейных, но приводимых к линейным, можно с помощью метода наименьших квадратов (МНК). Он позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений от теоретических минимальна.
Параметры уравнения регрессии можно определить с помощью следующей системы нормальных уравнений:
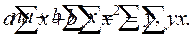 |
 |
Оценка качества построенной модели.
Для того чтобы регрессионная модель могла быть использована для прогнозирования, необходимо чтобы ее качество было высоким.
Качество регрессионной модели считается высоким, если:
1. коэффициент детерминации больше или равен 0,5;
2. средняя ошибка аппроксимации менее или равна 10%;
3. Fтабл<Fфакт.
Если хоть одно из условий не выполняется, то качество модели считается низким и модель не может быть использована для прогнозирования.
Рассмотрим показатели, определяющие качество модели.
Коэффициент детерминации рассмотрен в предыдущей теме.
Средняя ошибка аппроксимации – это среднее отклонение расчетных значений от фактических. Она вычисляется по формуле:
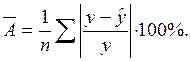 |
Допустимый предел значений средней ошибки аппроксимации не более 8-10%:
· А<8%, то ошибка аппроксимации небольшая, и регрессионная модель хорошо описывает изучаемую закономерность.
· 8% 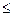 А 10% - ошибка аппроксимации высокая, но регрессионная модель хорошо описывает изучаемую закономерность.
А 10% - ошибка аппроксимации высокая, но регрессионная модель хорошо описывает изучаемую закономерность.
· А>10%, ошибка аппроксимации высокая, регрессионная модель плохо описывает изучаемую закономерность.
F- критерий Фишера.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Сравниваются фактическое Fфакт и критическое (табличное) Fтабл значения F- критерий Фишера.
Гипотеза Н0 – природа оцениваемых характеристик случайна.
Гипотеза Н1 – природа оцениваемых характеристик не случайна.
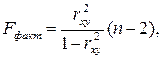 |
Fфакт можно рассчитать по формуле:
где n – число единиц совокупности.
Fтабл - максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a- вероятность отвергнуть правильную гипотезу при условии, что она верна (a равна 0,05 или 0,01).
При нахождении Fтабл. в таблице значений F-критерия Фишера принимаются: k1=m и k2=n-2, где n – объем выборки, m- количество объясняющих переменных.
Если Fтабл.<Fфакт., то гипотеза Н0 – о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность с вероятностью 1-a, следовательно, принимается гипотеза Н1.
Если Fтабл.>Fфакт., то гипотеза Н0 – о случайной природе оцениваемых характеристик не отклоняется и признается их статистическая незначимость и ненадежность с вероятностью 1-a, следовательно, принимается гипотеза Н0.
Выбор наилучшего варианта регрессионной модели осуществляется сравнением их качественных характеристик. Лучшему варианту модели должны соответствовать лучшие характеристики.
После расчета точечного прогноза того или иного показателя необходимо рассчитать ошибку прогноза по формуле:
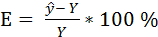 ,
,
где – прогнозное значение результативного показателя;
у – фактическое значение результативного показателя.
Образец решения задачи контрольной работы:
По приведенным в табл. 3.7 данным, построить однофакторную линейная модель типа =a+bx.
Таблица 3.7
| Период | Y | X |
| 0,5 | ||
| 1,2 | ||
11+ 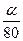
| 2,8 | |
13+ 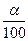
| 2+
|
Оцените качество модели с помощью коэффициента детерминации, средней ошибки аппроксимации и F-критерия Фишера. Табличное значение F-критерия Фишера (Fтабл.) равно 10,13 при Р=0,95.
Выполнить прогноз на следующие три периода и рассчитать ошибку прогноза, если х изменялся следующим образом:
| Период | Изменение х в текущем периоде по сравнению с предыдущим | Фактическое значение переменной у |
| +5% | ||
| +7,1% | ||
| +1,7% |
Сделать выводы.
Решение.
Пусть α = 302.
Определим фактические значения:
| Период | Y | X |
| 0,5 | ||
| 1,2 | ||
11+ 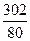 = 14,775 = 14,775
| 2,8 | |
13+ 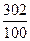 = 16,02 = 16,02
| 2+ = 5,02
|
Для построения однофакторной линейной модели типа =a+bx, необходимо определить ее параметры. Для этого построим вспомогательную таблицу:
| Период | Y | X | Х2 | Х*Y | Y2 |
| 0,5 | 0,25 | ||||
| 1,2 | 1,44 | 14,4 | |||
| 14,775 | 2,8 | 7,84 | 41,37 | 218,3006 | |
| 16,02 | 5,02 | 25,2004 | 80,4204 | 256,6404 | |
| Итого | 52,795 | 9,52 | 34,7304 | 141,1904 | 718,941 |
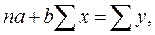 |
 Составим и решим систему нормальных уравнений, для нахождения параметров уравнения регрессии.
Составим и решим систему нормальных уравнений, для нахождения параметров уравнения регрессии.
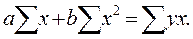 |
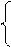 4a + 9,52b = 52,795
4a + 9,52b = 52,795
9,52a + 34,7304b = 141,1904
Для решения системы, умножим каждое значение первого уравнения на 2,38 и получим:
9,52a + 22,6576b = 125,6521
9,52a + 34,7304b = 141,1904
Далее путем вычитания первого уравнения из второго получим:
-12,0728b = -15,5383
b = 1,287
Подставим значение b в любое уравнение и найдем параметр а:
4a + 9,52*1,287 = 52,795
4a = 40,54276
a = 10,136
Однофакторная линейная модель примет вид: = 10,136 + 1,287*х.
Экономическая интерпретация, полученной модели: при увеличении фактора х на 1 единицу своего измерения результативный признак Y увеличится на 1,287 единиц своего измерения.
Для того чтобы выполнить прогноз по данной модели, необходимо проверить ее качество.
Качество регрессионной модели считается высоким, если:
1. коэффициент детерминации больше или равен 0,5;
2. средняя ошибка аппроксимации менее или равна 10%;
3. Fтабл<Fфакт.
Найдем перечисленные показатели.
Для нахождения коэффициента детерминации необходимо знать коэффициент корреляции, который определим по формуле:
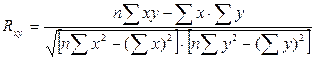
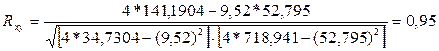
Следовательно, связь между Y и Х прямая, т.к. Rxy > 0, а теснота связи весьма высокая (по шкале Чеддока).
Коэффициент детерминации равен R2xy = (0,95)2 = 0,90 (90%). Следовательно, 90 % изменений результативного признака Y объясняется изменением фактора Х.
В нашем случае коэффициент детерминации больше 0,5, следовательно, первое условие, определяющие высокое качество модели выполнилось.
Для расчета средней ошибки аппроксимации построим вспомогательную таблицу (табл. 3.8).
Таблица 3.8
| Период | Y | X | = 10,136 + 1,287*х
| (Y - ) / Y
| |(Y - ) / Y|
|
| 0,5 | 10,7795 | -0,07795 | 0,07795 | ||
| 1,2 | 11,6804 | 0,026633 | 0,026633 | ||
| 14,775 | 2,8 | 13,7396 | 0,070078 | 0,070078 | |
| 16,02 | 5,2 | 16,59674 | -0,036 | 0,036001 | |
| Итого | 52,795 | 9,52 | 52,79624 | - | 0,210662 |
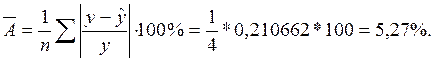 |
Определим среднюю ошибку аппроксимации по формуле:
В среднем расчетные значения отклоняются от фактических на 5,27 %. Ошибка аппроксимации небольшая (А<8%), регрессионная модель хорошо описывает изучаемую закономерность. Второе условие, определяющее высокое качество модели выполнилось.
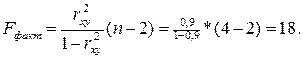 |
Определим фактическое значение критерия Фишера по формуле:
По условию задачи Fтабл. = 10,13.
Если Fтабл.<Fфакт., то гипотеза Н0 – о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность с вероятностью 1-a, следовательно, принимается гипотеза Н1. Третье условие, определяющие высокое качество модели выполнилось.
Так как, все три условия, определяющих высокое качество модели выполнились, то модель вида = 10,136 + 1,287*хможет быть использована для прогнозирования признака Y от фактора Х.
Прогнозирование по линейной однофакторной регрессии осуществляется путем подстановки ожидаемого значения х в уравнение регрессии. Определим ожидаемые значения х в прогнозных периодах.
| Период | Изменение х в текущем периоде по сравнению с предыдущим | Ожидаемое значение х в прогнозном периоде |
| +5% | 5,02*1,05 = 5,271 | |
| +7,1% | 5,271*1,071 = 5,645 | |
| +1,7% | 5,645*1,017 = 5,741 |
Выполним прогноз на следующие три периода:
5 = 10,136 + 1,287*5,271 = 16,92
6 = 10,136 + 1,287*5,645 = 17,40
7 = 10,136 + 1,287*5,741 = 17,52
Рассчитаем ошибки прогноза по формуле: ,
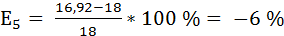 ,
,
 ,
,
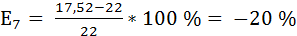 .
.
Вывод. Однофакторная линейная модель примет вид: = 10,136 + 1,287*х. Следовательно, при увеличении фактора х на 1 единицу своего измерения результативный признак Y увеличится на 1,287 единиц своего измерения.
Данная модель может быть использована для прогнозирования признака Y от фактора Х, так как выполняются условия, определяющие ее высокое качество. Наиболее точным оказался прогноз на 5-ый период (соответствует минимальное значение ошибки прогноза).
Дата публикования: 2015-10-09; Прочитано: 1491 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
