 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Реалізація ШПФ на нейрокомп’ютері
|
|
Розглянемо реалізацію ШПФ на базі процесора Л1879ВМ1(NM6403). Процесор Л1879ВМ1 - високопродуктивний спеціалізований мікропроцесор, що об’єднює в собі риси двох сучасних архітектур: VLIW (Very Long Instruction Word) і SIMD (Single Instruction Multiple Data) (рис.10). Тактова частота - 40 МГц; напруга живлення - від 3,0 до 3,6 В; споживана потужність - 1,3Вт. Основні обчислювальні вузли процесора - керуюче RISC-ядро і векторний співпроцесор.
RISC-ядро – центральний процесорний вузол, що виконує всі основні функції по керуванню роботою кристала. Крім того, RISC-процесор робить арифметико-логічні і операції зсуву над 32-розрядними скалярними даними і формує 32-розрядні адреси команд і даних при звертаннях до зовнішньої пам'яті. Довжина команди - 32 і 64 розряди (звичайно в команді виконуються дві операції). Процесор реалізує п’ятиступінчатий 32-розрядний конвеєр. Адресний простір - 16 Гбайт, два адресних генератори, вісім регістрів загального призначення і вісім адресних регістрів. Будь-яка інструкція виконується за один такт.
Векторний співпроцесор призначений для арифметичних і логічних операцій над 64-розрядними скалярними даними програмувальної розрядності. Обмін даними між основними вузлами процесора відбувається по трьох внутрішніх шинах, двом вхідним і однієї
вихідній.

GMI і LMI - два однакових блоки програмувального інтерфейсу з локальною і глобальною 64-розрядними зовнішніми шинами. До кожної з них може бути підключена зовнішня пам'ять, що містить до 231 32-розрядних комірок. Обмін даними з зовнішньою пам'яттю здійснюється як 32-, так і 64-розрядними словами (NM6403 одночасно вибирає дві сусідні комірки пам'яті). Кожен блок програмувального інтерфейсу дозволяє працювати з двома банками зовнішньої пам'яті різного обсягу, типу (DRAM, SRAM, Flash ROM, EDO DRAM і т.д.) і швидкодії без додаткового устаткування. Передбачено апаратну підтримку режиму розподіленої пам'яті для різних мультипроцесорних конфігурацій зовнішніх шин.
СР1 і СР2 - ідентичні комунікаційні порти, що забезпечують інформаційний обмін по двонаправленій восьмиразрядной шині. Вони призначені для побудови високопродуктивних мультипроцесорних систем і цілком сумісні з комунікаційними портами процесора ТМ320C4x. Кожен комунікаційний порт має вбудований контролер прямого доступу до пам'яті (ПДП, DMA), що дозволяє обмінюватися 64-розрядними даними з пам'яттю на зовнішніх шинах.
ВЕКТОРНИЙ СПІВПРОЦЕСОР
Векторний співпроцесор структурно являє собою матрично-векторний операційний пристрій і набір регістрів різного призначення.
Операційний пристрій (ОУ) - регулярна матрична структура 64х64 комірки (рис.11). Матриця може бути довільно розділена на стовпці і рядки. В утворені після поділу макрокомірки завантажуються вагові коефіцієнти Wіj. На вхід матриці подається вектор вхідних даних  , кожному елементу якого відповідає рядок матриці. Ширина рядка (у бітах) - розрядність даного елемента вхідних даних. У макрокомірках відбувається множення елемента вектора вхідних даних на ваговий коефіцієнт і додавання зі значенням верхньої комірки (або значень входів і U). Таким чином, для кожного стовпця обчислюється скалярне вираз
, кожному елементу якого відповідає рядок матриці. Ширина рядка (у бітах) - розрядність даного елемента вхідних даних. У макрокомірках відбувається множення елемента вектора вхідних даних на ваговий коефіцієнт і додавання зі значенням верхньої комірки (або значень входів і U). Таким чином, для кожного стовпця обчислюється скалярне вираз  . Для зниження розрядності вихідних даних і захисту від арифметичного переповнення використовується програмувальна функція насичення (рис. 12).
. Для зниження розрядності вихідних даних і захисту від арифметичного переповнення використовується програмувальна функція насичення (рис. 12).


| U3 | U2 | U1 |
| … … … | ||
| U3 | U2 | U1 |

| 
| 
|

| 
| 
|

| 
| 
|

| 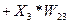
| 
|

| 
| 
|

| 
| 
|

| 
| 
|
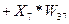
| 
| 
|
| X0 | … … … … … … … … … … | X0 | |||||
| X1 | X1 | ||||||
| X2 | X2 | ||||||
| X3 | X3 | ||||||
| X4 | X4 | ||||||
| X5 | X5 | ||||||
| X6 | X6 | ||||||
 |

| 
| 
|
| … … … | ||
|
|
|
|
Рис. 11. Структура операційного пристрою векторного співпроцесора

Рис. 12. Програмувальна функція насичення.
Операнди і вихідні значення упаковуються в 64-х розрядне слово. Всі операції в матриці ОУ робить паралельно, за один такт. Завантаження вагових коефіцієнтів відбувається за 32 такти. У векторному співпроцесорі є "тіньова" матриця, в яку вагові коефіцієнти можна завантажувати у фоновому режимі. Переключення "тіньової" і робочої матриць займає один такт. Найважливіша особливість векторного співпроцесора - робота з операндами довільної довжини (навіть не кратного степеня двійки) у діапазоні 1-64 біт. Цим досягається оптимальне співвідношення між швидкістю і точністю обчислень: при однобітових операндах на тактовій частоті 40 МГЦ продуктивність складе 11 520 MMAC (мільйонів операцій множення з нагромадженням) чи 40 000 MOPS (мільйонів логічних операцій у секунду), при 32-бітових операндах і 64-бітовому результаті вона стане номінальною – 40 MMAC. Вміння динамічно, в процесі обчислень змінювати розрядність операндів дозволяє підвищити продуктивність в тих випадках, коли звичайні процесори працюють "вхолосту", з надлишковою точністю.
Для обчислення продуктивності використовуються наступні вирази:

де: МСРS - мільйон з'єднань у секунду (еквівалентно ММАС)
64 - ширина слова даних;
Nх- ширина синапсів;
Nw- ширина ваг;
F = 50 МГЦ - тактова частота.
У випадку Nх¹1 і Nw=1, вираз набуває вигляду:
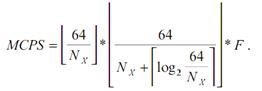
У випадку Nх=1 і Nw¹1, вираз набуває вигляду:

У випадку Nх=Nw=1, вираз набуває вигляду:

У випадку Nх=Nw=32, вираз набуває вигляду:
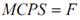
Організація паралельних обчислень в алгоритмах ШПФ на процесорі NM6403
. На практиці найбільш широке поширення одержали алгоритми ШПФ за основою 2, де кожен функціональний вузол виконує базову операцію - двохвходового "метелика". Ці алгоритми орієнтовані, насамперед, на зведення до мінімуму числа операцій множення. Але з появою векторних процесорів цей критерій стає несуттєвим. Навпроти, число одночасно виконуваних множень головним чином визначає продуктивність процесора. Тому виникає питання про розпаралелюваня обчислень і реалізацію алгоритмів ШПФ із більш високими основами і їхніми можливими комбінаціями. Послідовність обчислень будь-якого ШПФ можна описати у вигляді графа, вузли якого виконують фактично звичайне дискретне перетворення, але з меншою розмірністю вхідних векторів (меншою основою). В залежності від вибору основи міняється як загальне число арифметичних операцій, так і кількість шарів графа (рис.13).
Таблиця 1. Обчислювальна складність ШПФ
| Пряме обчислення ШПФ (основа N) | Обчислення ШПФ за основою 2 | Обчислення ШПФ з комбінованими основами 2, 16, 32 | ||||||||
| Complex muls | Complex adds | Кількість шарів графу | Complex muls | Complex adds | Кількість шарів графу | Complex muls | Complex adds | Комбінація основ | Кількість шарів графу | |
| N | N2 | N2 -N | (N/2)log2N | Nlog2N | ||||||
| 16-16 | ||||||||||
| 2-16-16 | ||||||||||
| 32-32 | ||||||||||
| 2-32-32 |
Complex muls - кількість комплексних множень
Complex adds - кількість комплексних додавань
В алгоритмах ШПФ за основою 2 кількість таких шарів максимальна (табл.1), тому при поетапному надходженні результатів обчислень від шару до шару відбувається більше нагромадження помилок округлення, ніж в алгоритмах з більш високими основами. І чим вища розмірність вектора вхідних даних, тим більша буде кількість шарів і в наслідок значніша помилка. Це особливо критично у випадках, коли обчислення проводяться в цілочисельній арифметиці (з фіксованою крапкою) чи при недостатньо широкій розрядності даних. Слід також зазначити, що в цьому випадку для запобігання переповнення проміжні результати після кожного чи після групи етапів множення (шарів графа) необхідно додатково нормалізувати, застосовуючи операцію зсуву вправо (рис.13). Нормалізація крім зсуву може містити в собі процедуру округлення, що також вносить додаткові обчислювальні витрати. Можливим компромісним рішенням може виступати підхід, оснований на збільшенні основи в алгоритмах ШПФ. Нижче розглядається варіант ШПФ-256 за основою 16. Вибір такої основи з однієїсторони дає можливість для організації паралельних обчислень, а з іншої знижує кількість шарів графа до двох.
Дискретне 256-точкове перетворення Фур'є визначається формулою:
 ,де
,де 
Дана формула після тотожних перетворень приймає вид, що є опорним для побудови
ШПФ-256 за основою 16:

Кінцевий граф обчислення ШПФ-256 за основою-16 будується з цієї формули. Структура такого графа показана на рис.13

Рис.13 Узагальнений граф обчислення ШПФ-256 Рис.14 Розгорнута схема блоку 16-точкового
за основою 16. дискретного перетворення Фур'є
Граф складається з двох шарів по 16 блоків. Кожен блок графа має 16 комплексних входів і виходів. Як показано на рис.14 кожен блок графа являє собою 16-точкове дискретне перетворення Фур'є і відрізняється від інших блоків тільки комплексними коефіцієнтами W. Таким чином, распаралелювання алгоритму БПФ фактично зводиться до реалізації ефективного обчислення ДПФ-16, тобто до знаходження 16 скалярних добутків різних векторів [W] з одним вектором [x], що еквівалентно множенню матриці коефіцієнтів перетворення Фур'є -[W] розмірністю 16х16 на вхідний вектор [х].
Всі арифметичні обчислення, що відносяться безпосередньо до обчислення ДПФ-16, виробляються на векторному співпроцесорі. Так як векторний співпроцесор дозволяє оперувати даними перемінної розрядності, то для збереження вхідних даних і результатів обчислень зручно відводити по 32 розряди на уявну і дійсну частину, а для збереження комплексних коефіцієнтів W - по 8 біт на дійсну і уявну частину. Таким чином, в одному 64р. слові може міститися одне комплексне число. Уявні і дійсні частини коефіцієнтів W зберігаються так само в упакованому виді, але в різних 64р. словах. Усі коефіцієнти W обчислюються заздалегідь і тому зберігаються усередині масиву в порядку зручному для наступних обчислень (рис.15).

Рис.15 Формат збереження вхідних даних і коефіцієнтів перетворення
Внаслідок такого представлення даних векторний помножувач працює в двох конфігураціях:
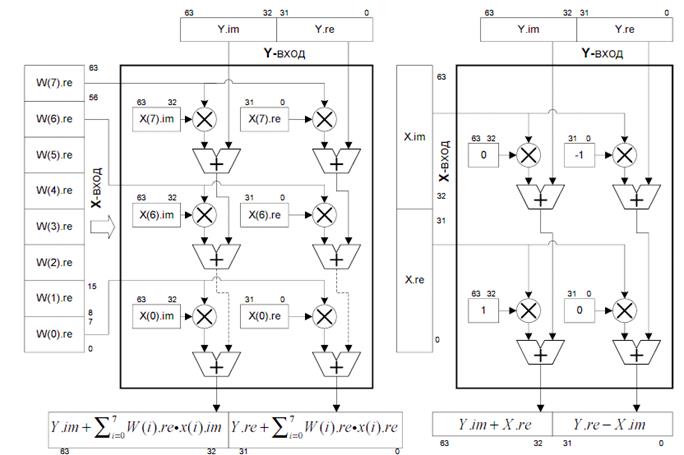
Рис.16 Еквівалентна схема помножувача векторного Рис.17 Еквівалентна схема помножувача векторного
Дата публикования: 2014-11-18; Прочитано: 527 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
