 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Випадкові події і величини, їх числові характеристики
|
|
В економічних процесах більшість явищ мають випадковий стохастичний (ймовірносний) характер. Тому при їх кількісній оцінці, яка здійснюється на основі використання інструментів економіко-математичного моделювання, необхідно визначати випадкові події і величини.
З позицій теорії пізнання спостережувані в природі й суспільстві явища можна підрозділити на такі види:
- достовірні (визначені), які обов'язково відбудуться, якщо буде здійснена певна сукупність умов, і приймуть умови, які явно можна передбачити;
- неможливі, які явно не відбудуться в певних умовах;
- випадкові, які при сукупності умов можуть відбутися або не відбутися, в результаті випробувань можуть прийняти будь-яке значення, причому невідомо, яке саме;
- невизначені, про які нічого не можна сказати, відбудуться вони або не відбудуться, незалежно від створених умов.
Слід розрізняти випадкові події - факт і випадкові величини.
Під "подією" розуміється будь-яке (не обов'язково знаменне) явище. Подія-факт в кількісному і якісному відношенні може бути величиною невизначеною, оскільки про неї нічого не можна сказати наперед з відомою ймовірністю, а випадкова величина пов'язана з характером, змістом дослідженого процесу.
Величина називається випадковою, якщо вона формується під дією багатьох дрібних причин, не піддатливих до результату випробувань повному контролю і обліку, діючих відносно незалежно один від одного.
Економіко-математичне моделювання вивчає кількісні закони масових випадкових величин і явищ, але не ставить перед собою завдання передбачити, відбудеться одинична подія чи ні, - вона просто не в силах це зробити. Одним з напрямів економіко-математичного моделювання є вивчення закономірностей масових однорідних випадкових подій.
Випадкові величини підрозділяються на дискретні (переривчасті) й безперервні.
Дискретними називають випадкові величини, які приймають окремі, строго визначені, ізольовані, кінцеві чисельні значення з певною ймовірністю, між якою не може бути проміжних (число робітників у бригаді, число перевезених за один рейс пасажирів і т.п.). При цьому число можливих значень дискретної випадкової величини може бути кінцевим і нескінченним. Частіше зустрічаються безперервні випадкові величини, які можуть мати всі можливі значення в деякому кінцевому або нескінченному проміжку. Очевидно, кількість можливих значень безперервної випадкової величини нескінченне, наприклад, рівень собівартості перевезення одного пасажира, продуктивність праці тощо.
Оскільки точність вимірювання або обліку завжди обмежена, то практично всі випадкові величини є дискретними.
Значна частина економіко-математичного моделювання пов'язана з необхідністю досліджувати і описувати велику сукупність об'єктів. Звичайно цю сукупність називають генеральною. Вона охоплює, наприклад, усіх мешканців великого міста, продукцію галузі народного господарства.
Якщо досліджена сукупність об'єктів кількісно значна або об'єкти вивчення важнодоступні, а також є інші причини, що не дозволяють вивчити всі об'єкти, то вдаються до визначення будь-якої частини генеральної сукупності, що називається вибіркою.
Вибірка повинна бути представницькою або, як зазначають, репрезентативною. Якщо вибірка представляє не всю генеральну сукупність, а відповідну її частину, то це називається зсувом вибірки. Зсув - одне з основних джерел помилок при використанні вибіркового методу.
В економіко-математичному моделюванні необхідно визначити вибірку, що складається з n однорідних одиниць (елементів). Число n називається обсягом вибірки. Одиницями вибірки можуть бути різні економічні процеси і явища, результати виробничо-господарської діяльності підприємств: продуктивність праці, собівартість продукції, фондовіддача, рентабельність та ін.
Кількісні значення, які приймає досліджена ознака, називають варіантами. Зміна величини ознаки в статистичній сукупності називається варіацією (коливається або розсіюванням).
Для того, щоб замінити в зареєстрованих значеннях процесу будь-яку закономірність, їх треба привести до доступного для аналізу вигляду, тобто впорядкувати, класифікувати, систематизувати, згрупувати. Процес розчленовування дослідженої сукупності на частини називається угрупованням.
Початковою базою для вивчення закономірностей тих чи інших явищ є статистичні ряди розподілу, які будують за якісними і кількісними ознаками.
Якщо ряди є послідовністю чисел, що характеризують зміну показника в часі, то вони називаються тимчасовими, а якщо показують розподіл одиниць сукупності по окремих групах, виділених за певною ознакою, то їх визначають варіаційними.
Число, що показує, скільки разів зустрічається та або інша одиниці сукупності називається його частотою m.
Варіаційний ряд або ряд розподілу є таблицею, в якій в порядку убування або зростання перераховані можливі значення випадкової величини за вибіркою з вказівкою їх частот (табл. 1.1).
Таблиця 1.1 - Значення випадкової величини
| Значення випадкової величини | Х1 | Х2 | Х3 | ... | Хn |
| Частоти | m1 | m2 | m3 | ... | mn |
Очевидно, що сума всіх частот дорівнює обсягу вибірки:
 , (1.1)
, (1.1)
де n- загальне число спостережень.
Якщо різних значень випадкової величини багато, то ряди розподілу складають в інтервальній формі. Різниця між верхньою Хi і нижньої Хi-1 межами інтервалу називається його величиною:
∆Хi−Xi−Xi-1. (1.2)
Кількість інтервалів не повинна бути надмірно великим. Для того, щоб можна краще проявити характерні особливості, пов'язані з природою величин, рекомендується ділити проміжок варіації на 6÷16 інтервалів залежно від обсягу вибірки.
Отже, для визначення величини інтервалів необхідно різницю Хmax і Хmin (розмах варіювання) розділити на 6  16 залежно від числа спостережень:
16 залежно від числа спостережень:
 . (1.3)
. (1.3)
У літературі зустрічається ще таке визначення розрахунку інтервалів, як використання формули Стерджеса:
 . (1.4)
. (1.4)
Отримане значення інтервалу ∆Х звичайно округляють. За величину і особливо центр інтервалу приймають деяке "зручне число", що має невелике число значущих цифр, щоб полегшити надалі обчислення. Запис інтервальних рядів розподілу поданий в табл. 1.2.
Таблиця 1.2 - Інтервальні ряди розподілу
| Значення випадкових величин | Х1−Х2 | Х2−Х3 | Х3−Х4 | … | Xn-1−Xk |
| частоти | m1 | m2 | m3 | mk |
Сума частот представлена наступним чином:
 . (1.5)
. (1.5)
Дослідження не обмежується побудовою ряду розподілу тієї або іншої випадкової величини. Необхідно знайти декілька величин, так званих статистичних характеристик, які відображали б властивості ряду розподілу в цілому, повніше характеризували сукупність і властиві їй закономірності. Інакше кажучи, ставиться завдання знаходження такого значення випадкової величини, навколо якої групуються всі інші і зустрічаються найбільш часто. Найважливішим і найпоширенішим з них є середня арифметична, яка позначається символом  . Якщо випадкова величина приймає n значень, то середня арифметична за незгрупованими даними є сумою її значень, розділеною на їх число:
. Якщо випадкова величина приймає n значень, то середня арифметична за незгрупованими даними є сумою її значень, розділеною на їх число:
 . (1.6)
. (1.6)
Середню арифметичну зважену за групованими даними обчислюють таким чином:
 . (1.7)
. (1.7)
Середня арифметична, як і середня арифметична зважена, володіє тією властивістю, що сума відхилень значень випадкової величини від середньої арифметичної дорівнює нулю. Ця властивість дає можливість визначити середню арифметичну як центр угрупування випадкової величини.
Крім середнього значення ознаки важливо знати характер варіації, тобто як тісно концентруються всі значення елементів сукупності навколо середньої. З теоретичної точки зору самою відповідною мірою коливання ознаки служить дисперсія (від латинського dispercia - розсіяння), є квадратом відхилення досліджених даних від середнього значення:
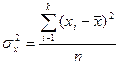 , (1.8)
, (1.8)
за незгрупованими даними,
 (1.9)
(1.9)
- за згрупованими даними.
Враховуючі вищезазначене, дисперсія випадкової величини в окремих випадках може мати нереальну розмірність. Для її усунення вводять середньоквадратичне відхилення, що розглядається в тих же одиницях вимірювання:
 . (1.10)
. (1.10)
Безрозмірним показником коливання випадкової величини є коефіцієнт варіації, який є відношенням  , відображеним у відсотках:
, відображеним у відсотках:
 . (1.11)
. (1.11)
Якщо дисперсія або коефіцієнт варіації великі, то це свідчить про значний розкид середнього значення її випадкової величини.
Слід зазначити, що випадкова величина характеризується двома параметрами:
- безліччю можливих значень;
- ймовірністю того, що вона прийме ти чи інші значення з цієї множини.
Ймовітність є одним з основних понять математичної статистики, яка відображає об'єктивну можливість відбутися або не відбутися випадковому явищу.
При вивченні рядів розподілу використовують не тільки абсолютні значення появи випадкової величини mi (частоти), але й відносні частоти,
тобто  .
.
Згідно з теоремою Я. Бернуллі (1654-1705), що отримала назву "закону великих чисел" у статистиці, можна передбачати відносну частоту події.
Теорія Я. Бернуллі була опублікована в 1713г. Стосовно вибірки вона формулюється так: з вірогідністю, скільки завгодно близькою до одиниці, можна стверджувати, що різниця між відносною частотою і часткою в генеральній сукупності при достатньо великому обсязі вибірки буде скільки завгодно малою.
Коротко теорема Я. Бернуллі записується так:
 . (1.12)
. (1.12)
З цього виходить, що ймовірність події А визначається формулою
P (A) = . (1.13)
Сума всіх відносних частот дорівнює 1, тобто
 . (1.14)
. (1.14)
З визначення ймовірності випливають наступні її властивості:
1. Ймовірність неможливої події дорівнює 1. При m=n
P(A)= = 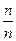 =1.
=1.
2. Ймовірність неможливої події дорівнює нулю. При m=0
Pa= =  =0.
=0.
3. Ймовірність випадкової події є позитивне число, укладене між нулем і одиницею.
Дійсно випадковій події сприяє лише частина із загального числа елементарних результатів випробувань. У цьому випадку о<m<1, значить
о< <1
о≤P(A)≤1.
4. Ймовірнсть протилежної події дорівнює різниці між одиницею і вірогідністю визначеної події, тобто
P(B)=1−P(A).
5. Якщо в результаті випробування повинно відбутися одне, і тільки одне з деяких подій А1,А2,…Ак, то сума всієї ймовірності дорівнює одиниці, тобто
P1(A1)+P2(A2)+…+Pk(Ak)=1.
Одним з узагальнюючих результатів закону великих чисел є те, що при достатньо великій кількості спостережень n середнє значення випадкової величини 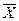 приблизно дорівнює її математичному очікуванню, або М(х)= . Така середня називається стохастичною. Таким чином, математичне очікування дискретної випадкової величини є невипадкова (постійна) величина. Тим самим П.Л. Чебишев (1821-1894) довів, що сукупні дії великої кількості чинників призводять до результату, майже не залежному від випадку.
приблизно дорівнює її математичному очікуванню, або М(х)= . Така середня називається стохастичною. Таким чином, математичне очікування дискретної випадкової величини є невипадкова (постійна) величина. Тим самим П.Л. Чебишев (1821-1894) довів, що сукупні дії великої кількості чинників призводять до результату, майже не залежному від випадку.
У вузькому значенні слова під законом великих чисел розуміється ряд математичних теорем, в яких встановлюється факт наближення середніх показників у результаті великої кількості спостережень до деяких постійних величин.
У широкому значенні слова зміст закону великих чисел полягає в тому, що при великому числі випадкових явищ їх середній результат практично перестає бути випадковим і може бути представлений з великою визначеністю.
Дослідження випадкової величини в економічних процесах здійснюється на основі відповідних законів розподілу цієї величини.
Дата публикования: 2014-11-02; Прочитано: 1723 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
