 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
УНІВЕРСИТЕТ 4 страница
|
|
До сих пор мы предполагали, что цель каждого условного перехода известна.
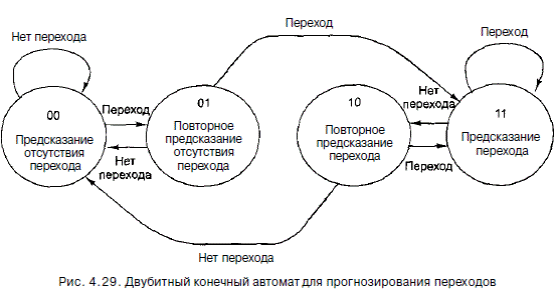
Обычно или в явном виде давался адрес, к которому нужно перейти (он содержался прямо в самой команде), или было известно смещение относительно текущей команды (то есть число со знаком, которое нужно было прибавить к счетчику команд). Часто это предположение имеет силу, но некоторые команды условного перехода вычисляют целевой адрес, выполняя определенные арифметические действия над значениями регистров, а затем уже переходят туда. Даже если взять конечный автомат, изображенный на рис. 4.29, который точно прогнозирует переходы, такой прогноз будет не нужен, поскольку целевой адрес неизвестен. Один из возможных выходов из подобной ситуации - сохранить в таблице адрес, к которому был осуществлен переход в прошлый раз, как показано на рис. 4.28, в. Тогда,
если в таблице указано, что в прошлый раз, когда встретилась команда перехода по адресу 516, переход был совершен в адрес 4000, и если сейчас предсказывается совершение перехода, то целевым адресом снова будет 4000. Еще один подход к прогнозированию ветвления - следить, были ли совершены последние к условных переходов, независимо от того, какие это были команды. Это k-битное число, которое хранится в сдвиговом регистре динамики переходов, затем сравнивается параллельно со всеми элементами таблицы с к-битным ключом, и в случае совпадения применяется то предсказание, которое найдено в этом элементе. Удивительно, но эта технология работает достаточно хорошо.
Статическое прогнозирование ветвления
Все технологии прогнозирования ветвления, которые обсуждались до сих пор, являются динамическими, то есть выполняются во время работы программы. Они также приспосабливаются к текущему поведению программы, и это их положительное качество. Отрицательной стороной этих технологий является то, что они требуют специализированного и дорогостоящего аппаратного обеспечения, а также наличия очень сложных микросхем. Можно пойти другим путем и призвать на помощь компилятор. Когда компилятор получает такое выражение, как
for (1=0 1 < 1000000, 1++)
это знает, что переход в конце цикла будет происходить практически всегда. Если бы только был способ сообщить это аппаратному обеспечению, можно было бы избавиться от огромного количества работы.
Хотя это связано с изменением архитектуры (а не только с вопросом реализации), в некоторых машинах, например UltraSPARC II, имеется еще один набор команд условного перехода помимо обычных (которые нужны для обратной совместимости). Новые команды содержат бит, по которому компилятор определяет, совершать переход или не совершать. Когда встречается такой бит, блок выборки команд просто делает то, что ему сказано. Более того, нет необходимости тратить драгоценное пространство в таблице предыстории переходов для этих команд, что сокращает количество конфликтных ситуаций. Наконец, наша последняя технология прогнозирования ветвления основана на профилировании. Это тоже статическая технология, только в данном случае программа не заставляет компилятор вычислять, какие переходы нужно совершать, а какие нет. В данном случае программа действительно выполняется, а ветвления фиксируются. Эта информация поступает в компилятор, который затем использует специальные команды условного перехода для того, чтобы сообщить аппаратному обеспечению, что нужно делать.
Спекулятивное выполнение
В предыдущем разделе мы ввели понятие переупорядочения команд. Эта процедура нужна для улучшения производительности. В действительности имелось в виду переупорядочение команд в пределах одного базового элемента программы. Рассмотрим этот аспект подробнее.
Компьютерные программы можно разбить на базовые элементы, каждый из
которых представляет собой линейную последовательность команд с точкой входа в начале и точкой выхода в конце. Базовый элемент не содержит никаких управляющих структур (например, условных операторов i f или операторов цикла whi I e), поэтому при трансляции на машинный язык нет никаких ветвлений. Базовые элементы связываются операторами управления.
Программа в такой форме может быть представлена в виде ориентированного графа, как показано на рис. 4.30. Здесь мы вычисляем сумму кубов четных и нечетных целых чисел до какого-либо предела и помещаем результаты в evensum и oddsum соответственно (листинг 4.6). В пределах каждого базового элемента технологии, упомянутые в предыдущем разделе, работают отлично.

Проблема состоит в том, что большинство базовых элементов очень короткие
и в них недостаточно параллелизма. Следовательно, нужно сделать так, чтобы переупорядочение последовательности команд можно было применять не только в пределах конкретного базового элемента. Выгоднее всего будет передвинуть потенциально медленную операцию в графе повыше, чтобы ее выполнение началось раньше. Это может быть команда LOAD, операция с плавающей точкой или даже начало длинной цепи зависимостей. Перемещение кода вверх по ребру графа называется подъемом.
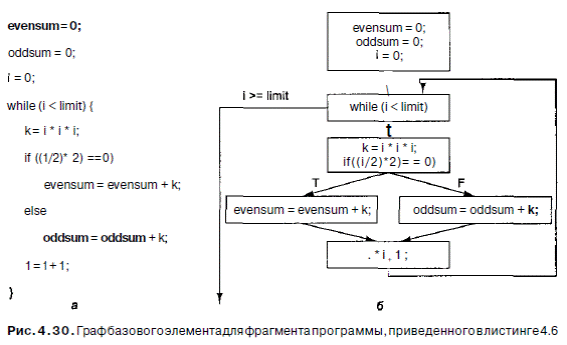
Посмотрите на рис. 4.30. Представим, что все переменные были помещены в регистры, кроме evensum и oddsum (из-за недостатка регистров). Тогда имело бы смысл переместить команды LOAD в начало цикла до вычисления переменной к, чтобы выполнение этих команд началось раньше, а полученные результаты были бы доступны в тот момент, когда они понадобятся. Естественно, при каждой итерации требуется только одно значение, поэтому остальные команды LOAD будут отбрасываться, но если кэш-память и основная память конвейеризированы, то подобная процедура имеет смысл. Выполнение команды до того, как стало известно, понадобится ли вообще эта команда, называется спекулятивным выполнением. Чтобы использовать эту технологию, требуется поддержка компилятора, аппаратного обеспечения, а также некоторое усовершенствование архитектуры. В большинстве случаев переупорядочение команд за пределами одного базового элемента находится вне компетенции аппаратного обеспечения, поэтому компилятор должен перемещать команды явным образом. В связи со спекулятивным выполнением команд возникают некоторые интересные проблемы. Например, очень важно, чтобы ни одна из спекулятивных команд не имела окончательного результата, который нельзя отменить, поскольку позднее может оказаться, что эти команды не нужно было выполнять. Обратимся к листингу 4.6 и рис. 4 30. Очень удобно производить сложение, как только появляется значение к (даже до условною оператора if), но нежелательно сохранять результаты в памяти. Чтобы предотвратить перезапись регистров до того, как стало известно, полезны ли полученные результаты, нужно переименовать (подменить) все выходные регистры, которые используются спекулятивной командой. Как вы можете себе представить, счетчик обращений для отслеживания всего этого очень сложен, но при наличии соответствующего аппаратного обеспечения его
вполне можно сделать. Однако при наличии спекулятивных команд возникает еще одна проблема, которую нельзя решить путем подмены регистров А что происходит, если спекулятивная команда вызывает исключение (exception)? В качестве примера можно привести команду LOAD, которая вызывает промах кэш-памяти в компьютере с достаточно большим размером строки кэш-памяти (скажем, 256 байт) и памятью, которая работает гораздо медленнее, чем центральный процессор и кэш. Если нам требуется команда LOAD и работа машины останавливается на много циклов, на то время, пока загружается строка кэш-памяти, то это не так страшно, поскольку данное слово действительно нужно. Но если машина простаивает, чтобы вызвать слово, которое, как окажется позднее, совершенно ни к чему, это совершенно не рационально. Если подобных «оптимизаций» слишком много, то центральный процессор будет работать медленнее, чем если бы этих «оптимизаций» вообще не было. (Если машина содержит виртуальную память, которая обсуждается в главе 6, то спекулятивное выполнение команды LOAD может даже вызвать обращение к отсутствующей странице Подобные ошибки могут сильно повлиять на производительность, поэтому важно их избегать)
В ряде современных компьютеров данная проблема решается следующим образом. В них содержится специальная команда SPECULATIVE-LOAD, которая производит попытку вызвать слово из кэш-памяти, а если слова там нет, просто прекращает вызов. Если значение находится там и если в данный момент оно действительно требуется, его можно использовать, но если оно в данный момент не требуется, аппаратное обеспечение должно сразу получить это значение. А если окажется, что данное значение нам не нужно, то никаких потерь не будет. Более сложную ситуацию можно проиллюстрировать следующим выражением: if (x>0) z-y/x;
где х, у и z - переменные с плавающей точкой. Предположим, что все эти переменные поступают в регистры заранее и что команда деления с плавающей точкой (эта команда выполняется медленно) перемещается вверх и выполняется еще до условного оператора i f. К сожалению, если х равен 0, то программа завершается в результате попытки деления на 0. Таким образом, спекулятивная команда приводит к сбою в изначально правильной программе. Еще хуже то, что программист изменяет программу, чтобы предотвратить подобную ситуацию, но сбой все равно происходит.
Одно из возможных решений - специальные версии команд, которые могут
вызвать исключения (exceptions). Кроме того, к каждому регистру добавляется специальный бит (poison bit). Если спекулятивная команда дает сбой, она не вызывает trap (ловушку), а устанавливает бит присутствия в регистр результатов. Если этот регистр позднее используется обычной командой, происходит trap (как и должно быть). Однако если этот результат не используется, бит присутствия сбрасывается и не причиняет программе никакого вреда.
Лекция 12. Общий обзор уровня архитектуры команд.
1. Свойства уровня команд.
2. Модели памяти.
3. Регистры.
4. Команды.
Свойства уровня команд
В принципе уровень команд - это то, каким представляется компьютер программисту машинного языка. Поскольку сейчас ни один нормальный человек не пишет программ на машинном языке, мы переделали это определение. Программа уровня архитектуры команд - это то, что выдает компилятор (в данный момент мы игнорируем вызовы операционной системы и символический язык ассемблера). Чтобы произвести программу уровня команд, составитель компилятора должен знать, какая модель памяти используется в машине, какие регистры, типы данных и команды имеются в наличии и т. д. Вся эта информация в совокупности и определяет уровень архитектуры команд. В соответствии с этим определением такие вопросы, как программируется ли микроархитектура или нет, конвейеризирован компьютер или нет, является он суперскалярным или нет и т. д., не относятся к уровню архитектуры команд, поскольку составитель компилятора не видит всего этого. Однако это замечание не совсем справедливо, поскольку некоторые из этих свойств влияют на производительность, а производительность является видимой для программиста. Рассмотрим, например, суиерскалярную машину, которая может выдавать back-to-back
команды в одном цикле, при условии что одна команда целочисленная, а одна - с плавающей точкой. Если компилятор чередует целочисленные команды и команды с плавающей точкой, то производительность заметно улучшится. Таким образом, детали суперскалярной операции видны на уровне команд, и границы между различными уровнями размыты.
Для одних архитектур уровень команд определяется формальным документом, который обычно выпускается промышленным консорциумом, для других - нет. Например, V9 SPARC (Version 9 SPARC) и JVM имеют официальные определения [156, 85]. Цель такого официального документа - дать возможность различным производителям выпускать машины данного конкретного вида, чтобы эти машины могли выполнять одни и те же программы и получать при этом одни и теже результаты,
В случае с системой SPARC подобные документы нужны для того, чтобы различные предприятия могли выпускать идентичные микросхемы SPARC, отличающиеся друг от друга только производительностью и ценой. Чтобы эта идея работала, поставщики микросхем должны знать, что делает микросхема SPARC (на уровне команд). Следовательно, в документе говорится о том, какая модель памяти, какие регистры присутствуют, какие действия выполняют команды и т. д., а не о том, что представляет собой микроархитектура. В таких документах содержатся нормативные разделы, в которых излагаются требования, и информативные разделы, которые предназначены для того, чтобы помочь читателю, но не являются частью формального определения. В нормативных разделах описаны требования и запреты. Например, такое высказывание, как: выполнение зарезервированного кода операции должно вызывать системное прерывание означает, что если программа выполняет код операции, который не определен, то он должен вызывать системное прерывание, а не просто игнорироваться. Может быть и альтернативный подход: результат выполнения зарезервированного кода операции определяется реализацией.
Это значит, что составитель компилятора не может просчитать какие-то конкретные действия, предоставляя конструкторам свободу выбора. К описанию архитектуры часто прилагаются тестовые комплекты для проверки, действительно ли данная реализация соответствует техническим требованиям. Совершенно ясно, почему V9 SPARC имеет документ, в котором определяется уровень команд: это нужно для того, чтобы все микросхемы V9 SPARC могли выполнять одни и те же программы. По той же причине существует специальный документ для JVM: чтобы интерпретаторы (или такие микросхемы, как picojava II) могли выполнять любую допустимую программу JVM. Для уровня команд процессора Pentium II такого документа нет, поскольку компания Intel не хочет, что-бы другие производители смогли запускать микросхемы Pentium II. Компания Intel
даже обращалась в суд, чтобы запретить производство своих микросхем другими предприятиями.
Другое важное качество уровня команд состоит в том, что в большинстве машин есть, по крайней мере, два режима. Привилегированный режим предназначен для запуска операционной системы. Он позволяет выполнять все команды. Пользовательский режим предназначен для запуска программных приложений. Этот режим не позволяет выполнять некоторые чувствительные команды (например, те, которые непосредственно манипулируют кэш-памятью). В этой главе мы в первую очередь сосредоточимся на командах и свойствах пользовательского режима.
Модели памяти
Во всех компьютерах память разделена на ячейки, которые имеют последова-
тельные адреса. В настоящее время наиболее распространенный размер ячейки - 8 битов, но раньше использовались ячейки от 1 до 60 битов (см. табл. 2.1). Ячейка из 8 битов называется байтом. Причина применения именно 8-битных байтов такова: символы ASCII кода занимают 7 битов, поэтому один символ ASCII плюс бит четности как раз подходит под размер байта. Если в будущем будет доминировать UNICODE, то ячейки памяти, возможно, будут 16-битными. Вообще говоря, число 24 лучше, чем 23, поскольку 4 - степень двойки, а 3 - нет.
Байты обычно группируются в 4-байтные (32-битные) или 8-байтные (64-битные) слова с командами для манипулирования целыми словами. Многие архитектуры требуют, чтобы слова были выровнены в своих естественных границах. Так, например, 4-байтное слово может начинаться с адреса 0,4,8 и т. д., но не с адреса 1 или 2. Точно так же слово из 8 байтов может начинаться с адреса 0,8 или 16, но не с адреса 4 или 6. Расположение 8-байтных слов показано на рис. 5.2.
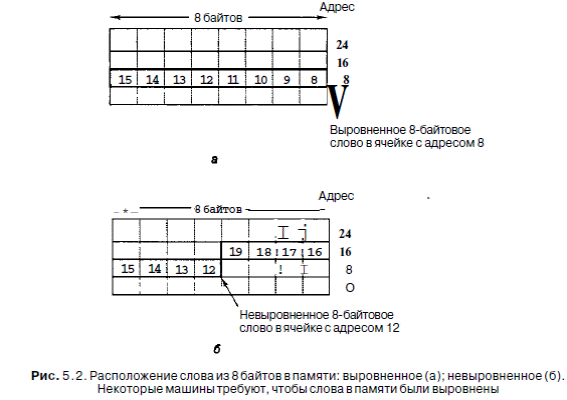
Выравнивание адресов требуется довольно часто, поскольку при этом память
работает более эффективно. Например, Pentium II, который вызывает из памяти по 8 байтов за раз, использует 36-битные физические адреса, но содержит только 33 адресных бита, как показано на рис. 3.41. Следовательно, Pentium II даже не сможет обратиться к невыровненной памяти, поскольку младшие три бита не определены явным образом. Эти биты всегда равны 0, и все адреса памяти кратны 8 байтам.
Тем не менее требование выравнивания адресов иногда вызывает некоторые
проблемы. В процессоре Pentium II программы могут обращаться к словам, начиная с любого адреса, - это качество восходит к модели 8088 с шиной данных шириной в 1 байт, в которой не было такого требования, чтобы ячейки располагались в 8-байтных границах. Если программа в процессоре Pentium II считывает 4-байтное слово из адреса 7, аппаратное обеспечение должно сделать одно обращение к памяти, чтобы вызвать байты с 0-го по 7-й, и второе обращение к памяти, чтобы вызвать байты с 8-го по 15-й. Затем центральный процессор должен извлечь требуемые 4 байта из 16 байтов, считанных из памяти, и скомпоновать их в нужном порядке, чтобы сформировать 4-байтное слово. Возможность считывать слова с произвольными адресами требует усложнения микросхемы, которая после этого становится больше по размеру и дороже. Разработчики были бы рады избавиться от такой микросхемы и просто потребовать, чтобы все программы обращались к словам памяти, а не к байтам. Однако на вопрос инженеров: «Кому нужно исполнение старых программ для машины 8088, которые неправильно обращаются к памяти?» последует ответ продавцов: «Нашим
покупателям».
Большинство машин имеют единое линейное адресное пространство, которое
простирается от адреса 0 до какого-то максимума, обычно 232 байтов или 2е4 байтов. В некоторых машинах содержатся отдельные адресные пространства для команд и для данных, так что при вызове команды с адресом 8 и вызове данных с адресом 8 происходит обращение к разным адресным пространствам. Такая система гораздо сложнее, чем единое адресное пространство, но зато она имеет два преимущества.
Во-первых, появляется возможность иметь 232 байтов для программы и дополнительные 232 байтов для данных, используя только 32-битные адреса. Во-вторых, поскольку запись всегда автоматически происходит только в пространство данных, случайная перезапись программы становится невозможной, и следовательно, устраняется один из источников программных сбоев. Отметим, что отдельные адресные пространства для команд и для данных - это не то же самое, что разделенная кэш-память первого уровня. В первом случае все адресное пространство целиком дублируется, и считывание из любого адреса вызывает разные результаты в зависимости от того, что именно считывается: слово или команда. При разделенной кэш-памяти существует только одно адресное пространство, просто в разных блоках кэш-памяти хранятся разные части этого пространства. Еще один аспект модели памяти - семантика памяти. Естественно ожидать, что команда LOAD, которая встречается после команды STORE и которая обращается к тому же адресу, возвратит только что сохраненное значение. Тем не менее, как мы видели в главе 4, во многих машинах микрокоманды переупорядочиваются. Таким образом, существует реальная опасность, что память не будет действовать так, как ожидается. Ситуация усложняется в случае с мультипроцессором, когда каждый процессор посылает разделенной памяти поток запросов на чтение и запись, которые тоже могут быть переупорядочены. Системные разработчики могут применять один из нескольких подходов к этой проблеме. С одной стороны, все запросы памяти могут быть упорядочены в последовательность таким образом, чтобы каждый из них завершался до того, как начнется следующий. Такая стратегия сильно вредит производительности, но зато дает простейшую семантику памяти (все операции выполняются в строгом программном порядке).
С другой стороны, не дается вообще никаких гарантий. Чтобы сделать обращения к памяти упорядоченными, программа должна выполнить команду SYNC, которая блокирует запуск всех новых операций памяти до тех пор, пока предыдущие операции не будут завершены. Эта идея сильно затрудняет работу тех, кто пишет компиляторы, поскольку для этого им нужно очень хорошо знать, как работает соответствующая микроархитектура, но зато разработчикам аппаратного обеспечения предоставлена полная свобода в оптимизации использования памяти.
Возможны также промежуточные модели памяти, в которых аппаратное обеспечение автоматически блокирует запуск определенных операций с памятью (например, тех, которые связаны с RAW- или WAR-взаимозависимостью), при этом запуск всех других операций не блокируется. Хотя разработка этих особенностей на уровне команд довольно утомительна (по крайней мере, для составителей компиляторов и программистов на языке ассемблера), сейчас существует тенденция использовать такой подход. Эта тенденция вызвана такими реализациями, как переупорядочение микрокоманд, конвейеры, многоуровневая кэш-память и т. д. Другие неестественные примеры такого рода мы рассмотрим в этой главе чуть позже.
Регистры
Во всех компьютерах имеется несколько регистров, которые видны на уровне команд. Они нужны там для того, чтобы контролировать выполнение программы, хранить временные результаты, а также для некоторых других целей. Обычно регистры, которые видны на микроархитектурном уровне, например TOS и MAR (см. рис. 4.1), не видны на уровне команд. Тем не менее некоторые из них, например счетчик команд и указатель стека, присутствуют на обоих уровнях. Регистры, которые видны на уровне команд, всегда видны на микроархитектурном уровне, поскольку именно там они реализуются. Регистры уровня команд можно разделить на две категории: специальные регистры и регистры общего назначения. Специальные регистры включают счетчик команд и указатель стека, а также другие регистры с особой функцией. Регистры общего назначения содержат ключевые локальные переменные и промежуточные результаты вычислений. Их основная функция состоит в том, чтобы обеспечить быстрый доступ к часто используемым данным (обычно избегая обращений к памяти). Машины RISC с высокоскоростными процессорами и медленной (относительно медленной) памятью обычно содержат как минимум 32 регистра общего
назначения, а в новых процессорах количество этих регистров постоянно растет.
В некоторых машинах регистры общего назначения полностью симметричны и взаимозаменяемы. Если все регистры эквивалентны, для хранения временного результата компилятор может использовать и регистр R1, и регистр R25. Выбор регистра не имеет никакого значения.
В других машинах некоторые регистры общего назначения могут быть специализированы. Например, в процессоре Pentium II существует регистр EDX, который может использоваться в качестве регистра общего назначения, но который также получает половину произведения и содержит половину делимого при делении.
Даже если регистры общего назначения полностью взаимозаменяемы, опера-
ционная система или компиляторы часто принимают соглашения о том, каким образом используются эти регистры. Например, некоторые регистры могут содержать параметры вызываемых процедур, а другие могут использоваться в качестве временных регистров. Если компилятор помещает важную локальную переменную в регистр R1, а затем вызывает библиотечную процедуру, которая воспринимает регистр R1 как временный регистр, доступный для нее, то когда библиотечная процедура возвращает значение, регистр R1 может содержать ненужные данные. А если существуют какие-либо системные соглашения по поводу того, как нужно
использовать регистры, составители компиляторов и программисты на языке ассемблера должны следовать им.
Кроме регистров, доступных на уровне команд, всегда существует довольно
большое количество специальных регистров, доступных только в привилегированном режиме. Эти регистры контролируют различные блоки кэш-памяти, основную память, устройства ввода-вывода и другие элементы аппаратного обеспечения машины. Данные регистры используются только операционной системой, поэтому компиляторам и пользователям не обязательно знать об их существовании. Есть один регистр управления, который представляет собой привилегированно-пользовательский гибрид. Это флаговый регистр, или PSW (Program State Word - слово состояния программы. Этот регистр содержит различные биты, которые нужны центральному процессору. Самые важные биты - это коды условия. Они устанавливаются в каждом цикле АЛ У и отражают состояние результата
предыдущей операции. Биты кода условия включают:
• N - устанавливается, если результат был отрицательным (Negative);
• Z - устанавливается, если результат был равен 0 (Zero);
• V - устанавливается, если результат вызвал переполнение (oVerflow);
• С - устанавливается, если результат вызвал выход переноса самого левого
бита (Carry out);
• А - устанавливается, если произошел выход переноса бита 3 (Auxiliary
carry - служебный перенос);
• Р - устанавливается, если результат четный (Parity).
Коды условия очень важны, поскольку они используются при сравнениях и
условных переходах. Например, команда СМР обычно вычитает один операнд из другого и устанавливает коды условия на основе полученной разности. Если операнды равны, то разность будет равна 0 и во флаговом регистре будет установлен бит Z. Последующая команда BEQ (Branch Equal - переход в случае равенства) проверяет бит Z и совершает переход, если он установлен. Флаговый регистр содержит не только коды условия. Его содержимое меняется от машины к машине. Дополнительные поля указывают режим машины (например, пользовательский или привилегированный), трассовый бит (который используется для отладки), уровень приоритета процессора, а также статус разрешения прерываний. Флаговый регистр обычно можно считать в пользовательском режиме, но некоторые поля могут записываться только в привилегированном режиме (например, бит, который указывает режим).
Команды
Главная особенность уровня, который мы сейчас рассматриваем, - это набор машинных команд. Они управляют действиями машины. В этом наборе всегда присутствуют команды LOAD и STORE (в той или иной форме) для перемещения данных между памятью и регистрами и команда MOVE для копирования данных из одного регистра в другой. Всегда присутствуют арифметические и логические команды и команды для сравнения элементов данных и переходов в зависимости от результатов. Некоторые типичные команды мы уже рассматривали (см. табл. 4.2.). А в этой главе мы рассмотрим многие другие команды.
Общий обзор уровня команд машины Pentium II
В этой главе мы обсудим три совершенно разные архитектуры команд: IA-32 компании Intel (она реализована в Pentium II), Version 9 SPARC (она реализована в процессорах SPARC) и JVM (она реализована в picojavall). Мы не преследуем цель дать исчерпывающее описание каждой из этих архитектур. Мы просто хотим продемонстрировать важные аспекты архитектуры команд и показать, как эти аспекты меняются от одной архитектуры к другой. Начнем с машины Pentium II.
Процессор Pentium II развивался на протяжении многих лет. Его история восходит к самым первым микропроцессорам, как мы говорили в главе 1. Основная архитектура команд обеспечивает выполнение программ, написанных для процессоров 8086 и 8088 (которые имеют одну и ту же архитектуру команд), а в машине даже содержатся элементы 8080 - 8-разрядный процессор, который был популярен в 70-е годы. На процессор 8080, в свою очередь, сильно повлияли требования совместимости с процессором 8008, который был основан на процессоре 4004 (4-битной микросхеме, применявшейся еще в каменном веке). С точки зрения программного обеспечения, компьютеры 8086 и 8088 были 16-разрядными машинами (хотя компьютер 8088 содержал 8-битную шину данных). Их последователь 80286 также был 16-разрядным. Его главным преимуществом был больший объем адресного пространства, хотя небольшое число программ использовали его, поскольку оно состояло из 16 384 64 К сегментов, а не представляло собой линейную 224-байтную память.
Процессор 80386 был первой 32-разрядной машиной, выпущенной компанией Intel. Все последующие процессоры (80486, Pentium, Pentium Pro, Pentium II, Celeron и Хеоп) имеют точно такую же 32-разрядную архитектуру, которая называется IA-32, поэтому мы сосредоточим наше внимание именно на этой архитектуре. Единственным существенным изменением архитектуры со времен процессора 80386 было введение команд ММХ в более поздние версии системы Pentium и их включение в Pentium II и последующие процессоры. Pentium II имеет 3 операционных режима, в двух из которых он работает как 8086. В реальном режиме все особенности, которые были добавлены к процессору со времен системы 8088, отключаются, и Pentium II работает как простой компьютер 8088. Если программа совершает ошибку, то происходит полный отказ системы. Если бы компания Intel занималась разработкой человеческих существ, то внутрь каждого человека был бы помещен бит, который превращает людей обратно в режим шимпанзе (примитивный мозг, отсутствие речи, питание в основном
бананами и т.д.). На следующей ступени находится виртуальный режим 8086, который делает возможным выполнение старых программ, написанных для 8088, с защитой. Чтобы запустить старую программу 8088, операционная система создает специальную изолированную среду, которая работает как процессор 8088, за исключением того, что если программа дает сбой, операционной системе передается соответствующая информация и полного отказа системы не происходит. Когда пользователь WINDOWS начинает работу с MS-DOS, ""рограмма, которая действует там, запускается в виртуальном режиме 8086, чтобы программа WINDOWS не могла вмешиваться в программы MS-DOS.
Дата публикования: 2014-10-17; Прочитано: 526 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
