 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
УНІВЕРСИТЕТ 2 страница
|
|
Это нужно только для того, чтобы сложить Н с MBRU в микрокоманде iload2. В разработке с двумя шинами нет возможности складывать два произвольных регистра, поэтому один из них сначала нужно копировать в регистр Н. В трехшинной архитектуре мы можем сэкономить один цикл, как показано в табл. 4.8. Мы добавили основной цикл к команде IL0AD, но при этом длина пути не увеличилась и не уменьшилась. Однако дополнительная шина сокращает общее время выполнения команды с шести циклов до пяти циклов. Теперь мы знаем второй способ сокращения длины пути: переход от двухшинной к трехшинноп архитектуре.

Блок выборки команд
Оба эти способа стоит использовать, но чтобы достичь существенного продвижения, требуется нечто более радикальное. Давайте вернемся чуть-чуть назад и рассмотрим обычные составные части любой команды: поле вызова и поле декодирования. Отметим, что в каждой команде могут происходить следующие операции:
1. Значение PC пропускается через АЛУ и увеличивается на 1.
2. PC используется для вызова следующего байта в потоке команд.
3. Операнды считываются из памяти.
4. Операнды записываются в память.
5. АЛУ выполняет вычисление, и результаты сохраняются в памяти.
Если команда содержит дополнительные поля (для операндов), каждое поле
должно вызываться эксплицитно по одному байту. Поле можно использовать только после того, как эти байты будут объединены. При вызове и компоновке поля АЛУ должно для каждого байта увеличивать PC на единицу, а затем объединять получившийся индекс или смещение. Когда помимо выполнения основной работы команды приходится вызывать и объединять поля этой команды, АЛУ используется практически в каждом цикле. Чтобы объединить основной цикл с какой-нибудь микрокомандой, нужно освободить АЛУ от некоторых таких задач. Для этого можно ввести второе АЛУ, хотя работа полного АЛУ в большинстве случаев не потребуется. Отметим, что АЛУ часто применяется для копирования значения из одного регистра в другой.
Эти циклы можно убрать, если ввести дополнительные тракты данных, которые не проходят через АЛУ. Полезно будет, например, создать тракт от TOS к MDR или от MDR к TOS, поскольку верхнее слово стека часто копируется из одного регистра в другой.
В микроархитектуре Mic-1 с АЛУ можно снять большую часть нагрузки, если создать независимый блок для вызова и обработки команд. Этот блок, который называется блоком выборки команд, может независимо от АЛУ увеличивать значение PC на 1 и вызывать байты из потока байтов до того, как они понадобятся. Этот блок содержит инкрементор, который по строению гораздо проще, чем полный сумматор. Разовьем эту идею. Блок выборки команд может также объединять 8-битные и 16-битные операнды, чтобы они могли использоваться сразу, как только они стали нужны.
Это можно осуществить, по крайней мере, двумя способами:
1. Блок выборки команд может интерпретировать каждый код операции, определять, сколько дополнительных полей нужно вызвать, и собирать их в регистр, который будет использоваться основным операционным блоком.
2. Блок выборки команд может постоянно предоставлять следующие 8- или
16-битные куски информации независимо от того, имеет это смысл или нет.
Тогда основной операционный блок может запрашивать любые данные,
которые ему требуются.
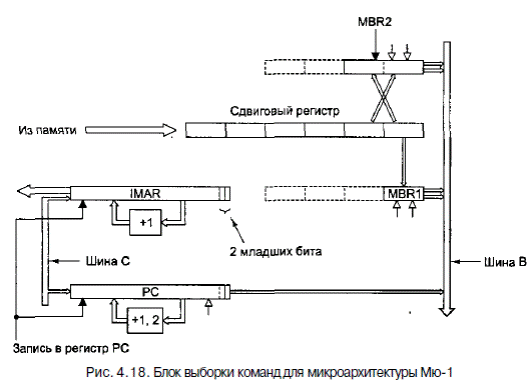
На рис. 4.18 показан второй способ реализации. Вместо одного 8-разрядного
регистра MBR (буферного регистра памяти) здесь есть два регистра MBR: 8-разрядныи MBR1 и 16-разрядный MBR2. Блок выборки команд следит за самым последним байтом или байтами, которые поступили в основной операционный блок. Кроме того, он передает следующий байт в регистр MBR, как и в архитектуре Mic-1, только в данном случае он автоматически определяет, когда значение регистра считано, вызывает следующий байт и сразу загружает его в регистр MBR1. Как и в микроархитектуре Mic-1, он имеет два интерфейса с шиной В: MBR1 и MBR1U. Первый получает знаковое расширение до 32 битов, второй дополнен нулями. Регистр MBR2 функционирует точно так же, но содержит следующие 2 байта. Он имеет два интерфейса с шиной В: MBR2 и MBR2U, первый из которых расширен по знаку, а второй дополнен до 32 битов нулями.
Блок выборки команд отвечает за вызов байтов. Для этого он использует стандартный 4-байтный порт памяти, ввыдает их по одному или по два за раз в том порядке, в котором они вызываются из памяти. Задача сдвигового регистра - сохранить последовательность поступающих байтов для загрузки в регистры MBR1 и MBR2. MBR1 всегда содержит самый старший байт сдвигового регистра, a MBR2 - 2 старших байта (старший байт - левый байт), которые формируют 16-битное целое число (см. рис. 4.14, б). Два байта в регистре MBR2 могут быть из различных
слов памяти, поскольку команды IJVM никак не связаны с границами слов.
Всякий раз, когда считывается регистр MBR1, значение сдвигового регистра
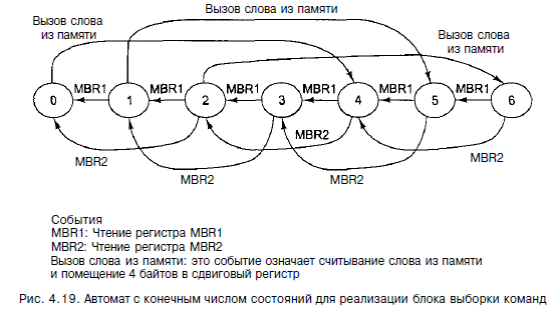
сдвигается вправо на 1 байт. Всякий раз, когда считывается регистр MBR2, значение сдвигового регистра сдвигается вправо на 2 байта. Затем в регистры MBR1 и MBR2 загружается самый старший байт и пара самых старших байтов соответственно. Если в данный момент в сдвиговом регистре осталось достаточно места для целого слова, блок выборки команд начинает цикл обращения к памяти, чтобы считать следующее слово. Мы предполагаем, что когда считывается любой из регистров MBR, он перезагружается к началу следующего цикла, поэтому новое значение можно считывать уже в последующих циклах. Блок выборки команд может быть смоделирован в виде автомата с конечным числом состояний (или конечного автомата), как показано на рис. 4.19. Во всех конечных автоматах есть состояния (на рисунке это кружочки) и переходы (это дуги от одного состояния к другому). Каждое состояние - это одна из возможных ситуаций, в которой может находиться конечный автомат. Данный конечный автомат имеет семь состояний, которые соответствуют семи состояниям сдвигового регистра, показанного на рис. 4.18. Семь состояний соответствуют количеству байтов, которые находятся в данный момент в регистре (от 0 до 6 включительно).
Каждая дуга репрезентирует событие, которое может произойти. В нашем ко-
нечном автомате возможны три различных события. Первое событие - чтение
одного байта из регистра MBR1. Оно активизирует сдвиговый регистр, самый правый байт в нем убирается, и осуществляется переход в другое состояние (меньшее на 1). Второе событие - чтение двух байтов из регистра MBR2. При этом осуществляется переход в состояние, меньшее на 2 (например, из состояния 2 в состояние 0 или из состояния 5 в состояние 3). Оба эти перехода вызывают перезагрузку регистров MBR1 и MBR2. Когда конечный автомат переходит в состояния 0,1 или 2, начинается процесс обращения к памяти, чтобы вызвать новое слово (предполагается, что память уже не занята считыванием слова). При поступлении слова номер состояния увеличивается на 4. Чтобы функционировать правильно, схема выборки команд должна блокироваться в том случае, если от нее требуют произвести какие-то действия, которые она выполнить не может (например, передать значение в MBR2, когда в сдвиговом регистре находится только 1 байт, а память все еще занята вызовом нового слова). Кроме того, блок выборки команд не может выполнять несколько операций одновременно, поэтому вся поступающая информация должна передаваться последовательно. Наконец, всякий раз, когда изменяется значение PC, блок выборки команд должен обновляться. Все эти детали усложняют работу блока. Однако многие устройства аппаратного обеспечения конструируются в виде конечных автоматов.
Блок выборки команд имеет свой собственный регистр адреса ячейки памяти
(IMAR), который используется для обращения к памяти, когда нужно вызвать новое слово. У этого регистра есть специальный инкрементор, поэтому основному АЛУ не требуется прибавлять 1 к значению PC для вызова следующего слова. Блок выборки команд должен контролировать шину С, чтобы каждый раз при загрузке регистра PC новое значение PC также копировалось в IMAR. Поскольку новое значение в регистре PC может быть и не на границе слова, блок выборки команд должен вызвать нужное слово и скорректировать значение сдвигового регистра соответствующим образом. Основной операционный блок записывает значение в PC только в том случае, если необходимо изменить характер последовательности байтов. Это происходит в команде перехода, в команде INVOKEVIRTUAL и команде IRETURN. Поскольку микропрограмма больше не увеличивает PC явным образом при вызове кода операции, блок выборки команд должен обновлять PC сам. Как это происходит? Блок выборки команд способен распознать, что байт из потока команд получен, то есть, что значения регистров MBR1 и MBR2 (или их вариантов без знака) уже считаны. С регистром PC связан отдельный инкрементор, который увеличивает значение на 1 или на 2 в зависимости от того, сколько байтов получено. Таким образом, регистр PC всегда содержит адрес первого еще не полученного байта. В начале каждой команды в регистре MBR находится адрес кода операции этой команды.
Отметим, что существует два разных инкрементора, которые выполняют разные функции. Регистр PC считает байты и увеличивает значение на 1 или на 2. Регистр Ш AR считает слова и увеличивает значение только на 1 (для 4 новых байтов). Как и MAR, регистр IMAR соединен с адресной шиной, при этом бит 0 регистра IMAR связан с адресной линией 2 и т. д. (перекос шины), чтобы осуществлять переход от адреса слова к адресу байта. Мы скоро увидим, что если нет необходимости увеличивать значение PC в основном цикле, это приводит к большому выигрышу, поскольку обычно в микрокоманде, в которой происходит увеличение PC, кроме этого больше ничего не происходит. Если эту команду устранить, длина пути сократится. Однако для увеличения скорости работы машины требуется больше аппаратного обеспечения. Таким образом, мы пришли к третьему способу сокращения длины пути: команды из памяти должны вызываться специализированным функциональным блоком.
Микроархитектура с упреждающей выборкой команд из памяти: Mic-2
Блок выборки команд может сильно сократить длину пути средней команды.
Во-первых, он полностью устраняет основной цикл, поскольку в конце каждой команды просто стразу осуществляется переход к следующей команде. Во-вторых, АЛУ не нужно увеличивать значение PC. В-третьих, блок выборки команд сокращает длину пути всякий раз, когда вычисляется 16-битный индекс или смещение, поскольку он объединяет 16-битное значение и сразу передает его в АЛУ в виде 32-битного значения, избегая необходимости производить объединение в регистре Н. На рис. 4.20 показана микроархитектура Mic-2, которая представляет собой усовершенствованную версию Mic-1, к которой добавлен блок выборки команд, изображенный на рис. 4.18. Микропрограмма для усовершенствованной машины приведена в табл. 4.9. Чтобы продемонстрировать, как работает Mic-2, рассмотрим команду IADD. Она берет второе слово из стека и выполняет сложение, как и раньше, но только сейчас ей не нужно осуществлять переход к Mainl после завершения операции, чтобы увеличить значение PC и перейти к следующей микрокоманде. Когда блок выборки команд распознает, что в цикле iadd3 произошло обращение к регистру MBR1, его внутренний сдвиговый регистр сдвигает все вправо и перезагружает MBR1 и MBR2. Он также осуществляет переход в состояние, которое на 1 ниже текущего. Если новое состояние - это состояние 2, блок выборки команд начинает вызов слова из памяти. Все это происходит в аппаратном обеспечении. Микропрограмма ничего не должна делать. Именно поэтому команду IADD можно сократить с пяти до трех микрокоманд.
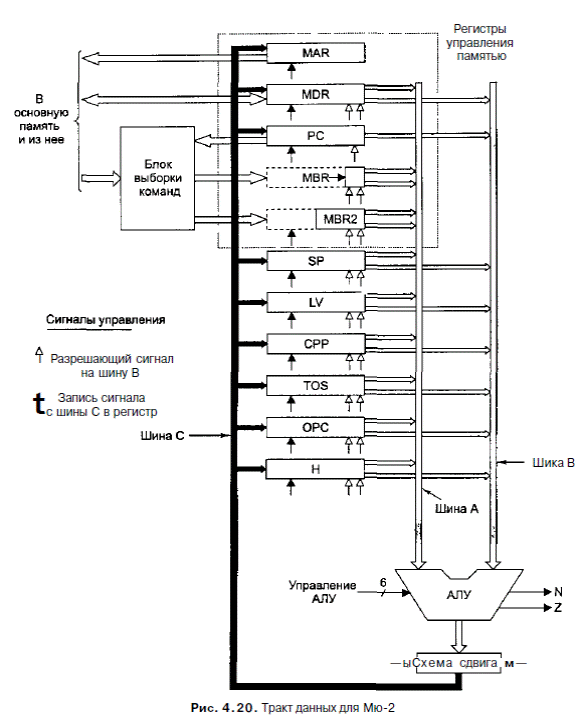

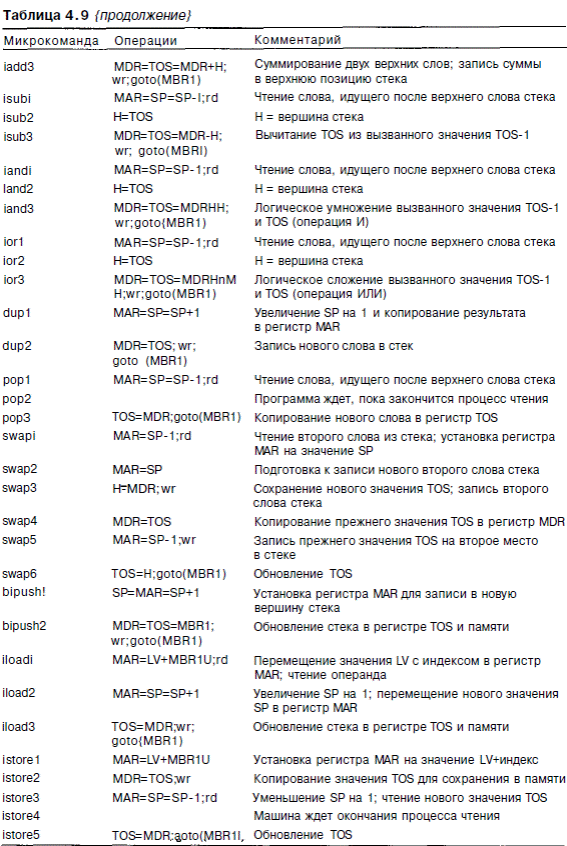

Микроархитектура Mic-2 совершенствует некоторые команды в большей сте-
пени, чем другие. Команда LDC_W сокращается с 9 до 3 микрокоманд, и следовательно, время выполнение команды уменьшается в три раза. Несколько по-другому дело обстоит с командой SWAP: изначально там было 8 команд, а стало 6. Для общей производительности компьютера играет роль сокращение наиболее часто повторяющихся команд. Это команды ILOAD (было 6, сейчас 3), IADD (было 4, сейчас 3) и IFJCMPEQ (было 13, сейчас 10 для случая, если слова равны; было 10, сейчас 8 для случая, если слова не равны). Чтобы вычислить, насколько улучшилась производительность, можно проверить эффективность системы по эталонному тесту, но и без этого ясно, что здесь наблюдается огромный выигрыш в скорости.
Конвейерная архитектура: Mic-3
Ясно, что Mic-2 — это усовершенствованная микроархитектура Mic-1. Она работает быстрее и использует меньше управляющей памяти, хотя стоимость блока выборки команд, несомненно, превышает ту сумму, которая выигрывается за счет сокращения пространства при уменьшении управляющей памяти. Таким образом, машина Mic-2 работает значительно быстрее при минимальном росте стоимости. Давайте посмотрим, можно ли еще больше повысить скорость. А что, если попробовать уменьшить время цикла? В значительной степени время цикла определяется базовой технологией. Чем меньше транзисторы и чем меньше физическое расстояние между ними, тем быстрее может работать задающий генератор. Б технологии, которую мы рассматриваем, время, затрачиваемое на прохождение через тракт данных, фиксировано (по крайней мере, с нашей точки зрения). Тем не менее у нас есть некоторая свобода действий, и далее мы используем ее в полной мере.
Еще один вариант усовершенствования - ввести в машину больше параллелизма. В данный момент микроархитектура Mic-2 выполняет большинство операций последовательно. Она помещает значения регистров на шины, ждет, пока АЛ У и схема сдвига обработают их, а затем записывает результаты обратно в регистры. Если не учитывать работу блока выборки команд, никакого параллелизма здесь нет. Внедрение дополнительных средств параллельной обработки дает нам большие возможности.
Как мы уже говорили, длительность цикла определяется временем, необходи-
мым для прохождения сигнала через тракт данных. На рис. 4.2 показано распределение этой задержки между различными компонентами во время каждого цикла. В цикле тракта данных есть три основных компонента:
1. Время, которое требуется на передачу значений выбранных регистров в шины А и В.
2. Время, которое требуется на работу АЛУ и схемы сдвига.
3. Время, которое требуется на передачу полученных значений обратно в регистры и сохранение этих значений.
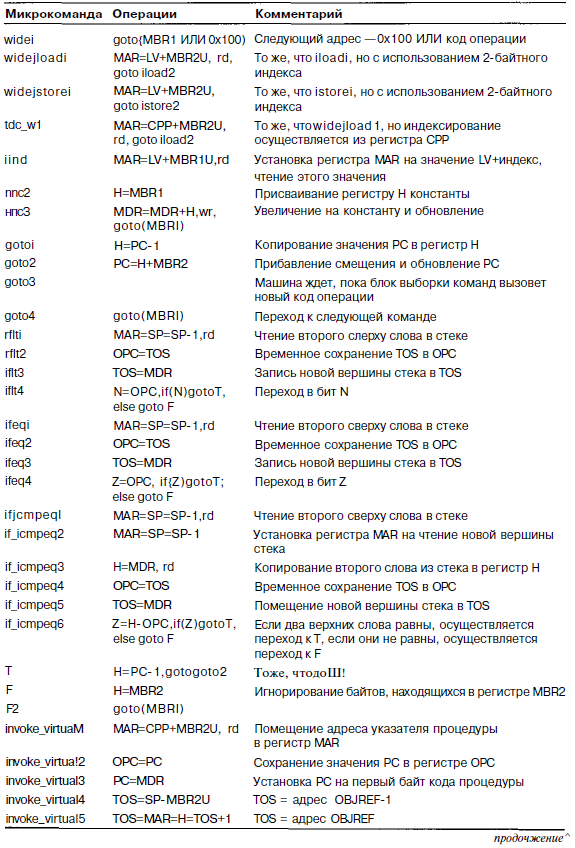
На рис. 4.21 показана новая трехшинная архитектура с блоком выборки команд и тремя дополнительными защелками (регистрами), каждая из которых расположена в середине каждой шины. Эти регистры записываются в каждом цикле. Они делят тракт данных на отдельные части, которые теперь могут функционировать независимо друг от друга. Мы будем называть такую архитектуру конвейерной моделью или Mic-3.
Зачем нужны эти три дополнительных регистра? Ведь теперь для прохожде-
ния сигнала через тракт данных требуется три цикла: один - для загрузки регистров А и В, второй - для запуска АЛУ и схемы сдвига и загрузки регистра С, и третий - для сохранения значения регистра-защелки С обратно в нужные регистры. Мы что, сумасшедшие? (Подсказка: нет). Существует целых две причины введения дополнительных регистров:
1. Мы можем повысить тактовую частоту, поскольку максимальная задержка
теперь стала короче.
2. Во время каждого цикла мы можем использовать все части тракта данных.
После разбиения тракта данных на три части максимальная задержка прохождения сигнала уменьшается, и в результате тактовая частота может повыситься. Предположим, что если разбить цикл тракта данных на три примерно равных интервала, тактовая частота увеличится втрое. (На самом деле это не так, поскольку мы добавили в тракт данных еще два регистра, но в качестве первого приближения это допустимо.)
Поскольку мы предполагаем, что все операции чтения из памяти и записи в
память выполняются с использованием кэш-памяти первого уровня и эта кэш-память построена из того же материала, что и регистры, то следовательно, операция с памятью занимает один цикл. На практике, однако, этого не так легко достичь.
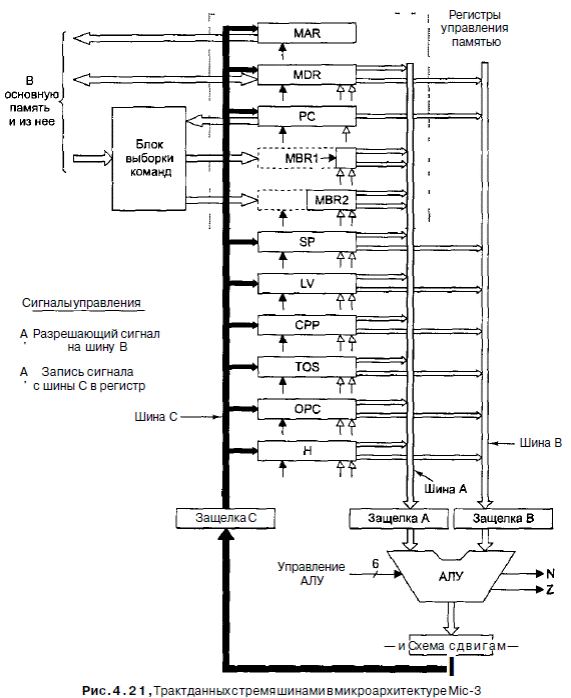
Второй пункт связан с общей производительностью, а не со скоростью выполнения отдельной команды В микроархитектуре Mic-2 во время первой и третьей части каждого цикла АЛУ простаивает Если разделить тракт данных на три части, то появляется возможность использовать АЛУ в каждом цикле, вследствие чего производительность машины увеличивается в три раза А теперь посмотрим, как работает тракт данных Mic-З. Перед тем как начать, нужно ввести определенные обозначения для защелок Проще всего назвать защелки А, В и С и считать их регистрами, подразумевая ограничения тракта данных. В таблице 4.10 приведен кусок программы для микроархитектуры Mic-2 (реализация команды SWAP).

Давайте перепишем эту последовательность для Mic-З. Следует помнить, что
теперь работа тракта данных занимает три цикла: один - для загрузки регистров А и В, второй - для выполнения операции и загрузки регистра С и третий - для записи результатов в регистры. Каждый из этих участков будем называть микрошагом. Реализация команды SWAP для Mic-З показана в табл. 4.11. В цикле 1 мы начинаем микрокоманду swapl, копируя значение SP в регистр В. Не имеет никакого значения, что происходит в регистре А, поскольку чтобы отнять 1 из В, ENA (сигнал разрешения А) блокируется (см. табл. 4.1). Для простоты мы не показываем присваивания, которые не используются. В цикле 2 мы производим операцию вычитания. В цикле 3 результат сохраняется в регистре MAR, и после этого, в конце третьего цикла, начинается процесс чтения. Поскольку чтение из памяти занимает
один цикл, закончится он только в конце четвертого цикла. Это показано присваиванием значения регистру MDR в цикле 4. Значение из MDR можно считывать не раньше пятого цикла.
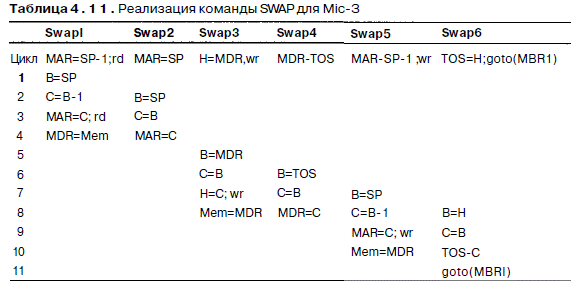
А теперь вернемся к циклу 2. Мы можем разбить микрокоманду swap2 на микрошаги и начать их выполнение. В цикле 2 мы копируем значение SP в регистр В, затем пропускаем значение через АЛУ в цикле 3 и, наконец, сохраняем его в регистре MAR в цикле 4. Пока все хорошо. Должно быть ясно, что если мы сможем начинать новую микрокоманду в каждом цикле, скорость работы машины увеличится в три раза. Такое повышение скорости происходит за счет того, что машина Mic-З производит в три раза больше циклов в секунду, чем Mic-2. Фактически мы построили конвейерный процессор. К сожалению, мы наткнулись на преграду в цикле 3. Мы бы рады начать микрокоманду swap3, но эта микрокоманда сначала пропускает значение MDR через АЛУ, а значение MDR не будет получено из памяти до начала цикла 5. Ситуация, когда следующий микрошаг не может начаться, потому что перед этим нужно получить результат выполнения предыдущего микрошага, называется реальной взаимозависимостью или RAW взаимозависимостью (Read After Write – чтение после записи). В такой ситуации требуется считать значение регистра, которое еще не записано. Единственное разумное решение в данном случае – отложить начало микрокоманды swap3 до того момента, когда значение MDR станет доступным, то есть до пятого цикла. Ожидание нужного значения называется простаиванием. После этого мы можем начинать выполнение микрокоманд в каждом цикле, поскольку таких ситуаций больше не возникает, хотя имеется пограничная ситуация: микрокоманда swap6 считывает значение регистра Н в цикле, который следует сразу после записи этого регистра в микрокоманде swap3. Если бы значение этого регистра считывалось в микрокоманде swap5, машине пришлось бы простаивать один цикл.
Хотя программа Mic-З занимает больше циклов, чем программа Mic-2, она работает гораздо быстрее. Если время цикла микроархитектуры Mic-З составляет ДТ наносекунд, то для выполнения команды SWAP машине Mic-З требуется 11ДТ не, а машине Mic-2 нужно 6 циклов по ЗДТ не каждый, то есть всего 18ДТ не. Конвейеризация увеличивает скорость работы компьютера, даже несмотря на то, что один раз приходится простаивать из-за явления взаимозависимости. Конвейеризация является ключевой технологией во всех современных процессорах, поэтому важно хорошо понимать эту технологию. На рис. 4.22 графически проиллюстрирована конвейеризация тракта данных, изображенного на рис. 4.21. В первой колонке демонстрируется, что происходит во время цикла 1, вторая колонка представляет цикл 2 и т. д. (предполагается, что простаиваний нет). Закрашенная область на рисунке для цикла 1 и команды 1 означает, что блок выборки команд занят вызовом команды 1. В цикле 2 значения регистров, вызванных командой 1, загружаются в А и В, а в это время блок выборки команд занимается вызовом команды 2. Все это также показано с помощью закрашенных серым прямоугольников.
Во время цикла 3 команда 1 использует АЛУ и схему сдвига, регистры А и В
загружаются для команды 2, а команда 3 вызывается. Наконец, во время цикла 4 работают все 4 команды одновременно. Сохраняются результаты выполнения команды 1, АЛУ выполняет вычисления для команды 2, регистры А и В загружаются для команды 3, а команда 4 вызывается.
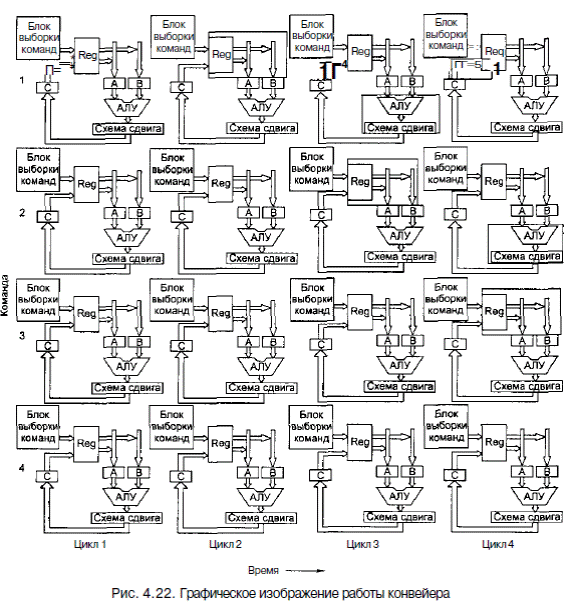
Если бы мы показали цикл 5 и следующие, модель была бы точно такой же, как в цикле 4: все четыре части тракта данных работали бы независимо друг от друга. Данный конвейер содержит 4 стадии: для вызова команд, для доступа к операндам, для работы АЛУ и для записи результата обратно в регистры. Он похож на конвейер, изображенный на рис. 2.3, а, только у него отсутствует стадия декодирования (расшифровки). Здесь важно подчеркнуть, что хотя выполнение одной команды занимает 4 цикла, в каждом цикле начинается новая команда и завершается предыдущая.
Можно рассматривать схему на рис. 4.22 не вертикально (по колонкам), а горизонтально (по строчкам). При выполнении команды 1 в цикле 1 функционирует блок выборки команд. В цикле 2 значения регистров помещаются на шины А и В. В цикле три происходит работа АЛУ и схемы сдвига. Наконец, в цикле 4 полученные результаты сохраняются в регистрах. Отметим, что имеется 4 доступные части аппаратного обеспечения, и во время каждого цикла определенная команда использует только одну из них, оставляя свободными другие части для других команд.
Проведем аналогию с конвейером на заводе по производству машин. Чтобы
изложить основную суть работы такого конвейера, представим, что ровно каждую минуту звучит гонг, и в этот момент все машины передвигаются по линии на один пункт. В каждом пункте рабочие выполняют определенную операцию с машиной, которая находится перед ними, например ставят колеса или тормоза. При каждом ударе гонга (это 1 цикл) одна новая машина поступает на конвейер и одна собранная машина сходит с конвейера. Завод выпускает одну машину в минуту независимо от того, сколько времени занимает сборка одной машины. В этом и состоит суть работы конвейера. Такой подход в равной степени применим и к процессорам, и к производству машин.
Конвейер с 7 стадиями: Mic-4
Мы не упомянули о том факте, что каждая микрокоманда выбирает следующую за ней микрокоманду. Большинство из них просто выбирают следующую команду в текущей последовательности, но последняя из них, например swap6, часто совершает межуровневый переход, который останавливает работу конвейера, поскольку после этого перехода вызывать команды заранее уже становится невозможно. Поэтому нам нужно придумать лучшую технологию. Следующая (и последняя) микроархитектура - Mic-4. Ее основные части проиллюстрированы на рис. 4.23, но значительное количество деталей не показано, чтобы сделать схему более понятной. Как и Mic-З, эта микроархитектура содержит блок выборки команд, который заранее вызывает слова из памяти и сохраняет различные значения MBR.
Блок выборки команд передает входящий поток байтов в новый компонент - блок декодирования. Этот блок содержит внутреннее ПЗУ, которое индексируется кодом операции IJVM. Каждый элемент (ряд) блока состоит из двух частей: длины команды IJVM и индекса в другом ПЗУ- ПЗУ микроопераций. Длина команды IJVM нужна для того, чтобы блок декодирования мог разделить входящий поток байтов и установить, какие байты являются кодами операций, а какие операндами. Если длина текущей команды составляет 1 байт (например, длина команды POP), то блок декодирования определяет, что следующий байт - это код операции. Если длина текущей команды составляет 2 байта, блок декодирования определяет, что следующий байт — это операнд, сразу за которым следует другой код операции. Когда появляется префиксная команда WIDE, следующий байт преобразуется в специальный расширенный код операции, например, WIDE+ILOAD превращается в WIDE_ILOAD.
Блок декодирования передает индекс в ПЗУ микроопераций, который он находит в своей таблице, следующему компоненту, блоку формирования очереди. Этот блок содержит логические схемы и две внутренние таблицы: одна - для ПЗУ и одна - для ОЗУ. В ПЗУ находится микропрограмма, причем каждая команда IJVM содержит набор последовательных элементов, которые называются микрооперациями. Эти элементы должны быть расположены в строгом порядке, и, например, переход из wide_iload2 в iload2, который допустим в микроархитектуре Mic-2, не разрешается. Каждая последовательность микроопераций должна выполняться полностью, в некоторых случаях последовательности дублируются.
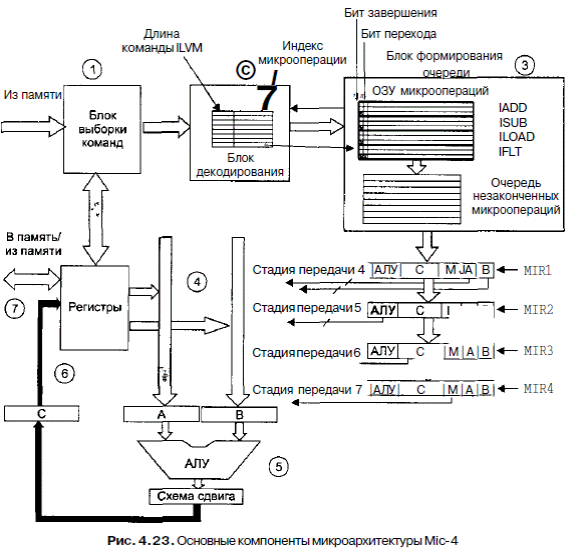
Структура микрооперации сходна со структурой микрокоманды (см. рис.4.4),
только в данном случае поля NEXT_ADDRESS и JAM отсутствуют и требуется новое поле для определения входа на шину А. Имеется также два новых бита: бит завершения (Final bit) и бит перехода (Goto bit). Бит завершения устанавливается на последней микрооперации каждой последовательности (чтобы обозначить эту операцию). Бит перехода нужен для указания на микрооперации, которые являются условными микропереходами. По формату они отличаются от обычных микроопераций. Они состоят из битов JAM и индекса в ПЗУ микроопераций. Микрокоманды, которые раньше осуществляли какие-либо действия с трактом данных, а также выполняли условные микропереходы (например, iflt4), теперь нужно разбивать на две микрооперации.
Блок формирования очереди работает следующим образом. Он получает от
блока декодирования индекс микрооперации ПЗУ. Затем он отыскивает микрооперацию и копирует ее во внутреннюю очередь. Затем он копирует следующую микрооперацию в ту же очередь, а также следующую за этой микрооперацией. Так продолжается до тех пор, пока не появится микрооперация с битом завершения. Тогда блок копирует эту последнюю микрооперацию и останавливается. Если блоку не встретилась микрооперация с битом перехода и у него осталось достаточно свободного пространства, он посылает сигнал подтверждения приема блоку декодирования. Когда блок декодирования воспринимает сигнал подтверждения, он посылает блоку формирования очереди следующую команду IJVM. Таким образом, последовательность команд IJVM в памяти в конечном итоге превращается в последовательность микроопераций в очереди. Эти микрооперации передаются в регистры MIR, которые посылают сигналы тракту данных. Но есть еще один фактор, который нам нужно рассмотреть: поля каждой микрооперации не действуют одновременно. Поля А и В активны во время первого цикла, поле АЛУ активно во время второго цикла, поле С активно во время третьего цикла, а все операции с памятью происходят в четвертом цикле. Чтобы все эти операции выполнялись правильно, мы ввели 4 независимых регистра MIR в схему на рис. 4.23. В начале каждого цикла (на рис. 4.2 это время Aw) значение MIR3 копируется в регистр MIR4, значение MIR2 копируется в регистр MIR3, значение MIR1 копируется в регистр MIR2, а в MIR1 загружается новая микрооперация из очереди. Затем каждый регистр MIR выдает сигналы управления, но используются только некоторые из них. Поля А и В из регистра MIR1
применяются для выбора регистров, которые запускают защелки А и В, а поле АЛУ в регистре MIR1 не используется и не связано ни с чем на тракте данных.
В следующем цикле микрооперация передается в регистр MIR2, а выбранные
регистры в данный момент находятся в защелках А и В. Поле АЛУ теперь используется для запуска АЛУ. В следующем цикле поле С запишет результаты обратно в регистры. После этого микрооперация передается в регистр MIR4 и инициирует любую необходимую операцию памяти, используя загруженное значение регистра MAR (или MDR для записи).
Дата публикования: 2014-10-17; Прочитано: 900 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
