 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
УНІВЕРСИТЕТ 3 страница
|
|
Нужно обсудить еще один аспект микроархитектуры Mic-4: микропереходы.
Некоторым командам IJVM нужен условный переход, который осуществляется с помощью бита N. Когда происходит такой переход, конвейер не может продолжать работу. Именно поэтому нам пришлось добавить в микрооперацию бит перехода. Когда в блок формирования очереди поступает микрооперация с таким битом, блок воздерживается от передачи сигнала о получении данных блоку декодирования. В результате машина будет простаивать до тех пор, пока этот переход не разрешится.
Предположительно, некоторые команды IJVM, не зависящие от этого перехода, уже переданы в блок декодирования, но не в блок формирования очереди, поскольку он еще не выдал сигнал о получении. Чтобы разобраться в этой путанице и вернуться к нормальной работе, требуется специальное аппаратное обеспечение и особые механизмы, но мы не будем рассматривать их в этой книге. Э. Дейкстра, написавший знаменитую работу «GOTO Statement Considered Harmful» («Выражение GOTO губительное), был прав.
Мы начали с микроархитектуры Mic-1 и, пройдя довольно долгий путь, закончили микроархитектурой Mic-4. Микроархитектура Mic-i представляла собой очень простой вариант аппаратного обеспечения, поскольку практически все управление осуществлялось программным обеспечением. Микроархитектура Mic-4 является конвейеризированной структурой с семью стадиями и более сложным аппаратным обеспечением. Данный конвейер изображен на рис. 4.24. Цифры в кружочках соответствуют компонентам рис. 4.23. Микроархитектура Mic-4 автоматически вызывает заранее поток байтов из памяти, декодирует его в команды IJVM, превращает их в последовательность операций с помощью ПЗУ и применяет их по назначению. Первые три стадии конвейера при желании можно связать с
задающим генератором тракта данных, но работа будет происходить не в каждом цикле. Например, блок выборки команд совершенно точно не может передавать новый код операции блоку декодирования в каждом цикле, поскольку выполнение команды IJVM занимает несколько циклов и очередь быстро переполнится.
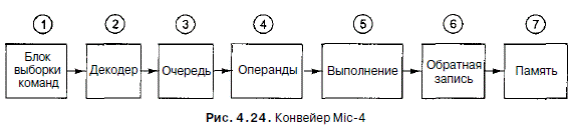
В каждом цикле значения регистров MIR перемещаются, а микрооперация,
находящаяся в начале очереди, копируется в регистр MIR1. Затем сигналы управления из всех четырех регистров MIR передаются по тракту данных, вызывая определенные действия. Каждый регистр MIR контролирует отдельную часть тракта данных и, следовательно, различные микрошаги.
В данной разработке содержится конвейеризированный процессор. Благодаря этому отдельные шаги становятся очень короткими, а тактовая частота - высокой. Многие процессоры проектируются именно таким образом, особенно те, которым приходится выполнять старый набор команд (CISC). Например, процессор Pentium II в некоторых аспектах сходен с микроархитектурой Mic-4, как мы увидим позднее в этой главе.
Лекция 11. Основные приемы увеличения производительности.
1. Использование КЭШ памяти.
2. Приемы ветвления.
3. Спекулятивное исполнение команд.
4. Кэш-память
Одним из самых важных вопросов при разработке компьютеров было и остается построение такой системы памяти, которая могла бы передавать операнды процессору с той же скоростью, с которой он их обрабатывает. Быстрый рост скорости
работы процессора, к сожалению, не сопровождается столь же высоким ростом скорости работы памяти. Относительно процессора память работает все медленнее и медленнее с каждым десятилетием. С учетом огромной важности основной памяти эта ситуация сильно ограничивает развитие систем с высокой производительностью и направляет исследование таким путем, чтобы обойти проблему очень низкой по сравнению с процессором скорости работы памяти. И, откровенно говоря, эта ситуация ухудшается с каждым годом. Современные процессоры предъявляют определенные требования к системе памяти и относительно времени ожидания (задержки в доставке операнда), и относительно пропускной способности (количества данных, передаваемых в единицу времени). К сожалению, эти два аспекта системы памяти сильно расходятся. Обычно с увеличением пропускной способности увеличивается время ожидания. Например, технологии конвейеризации, которые используются в микроархитектуре Mic-З, можно применить к системе памяти, при этом запросы памяти будут обрабатываться более рационально, с перекрытием. Но, к сожалению, как и в микроархитектуре Mic-З, это приводит к увеличению времени ожидания отдельных операций памяти. С увеличением скорости задающего генератора становится все сложнее обеспечить такую систему памяти, которая может передавать операнды за один или два цикла.
Один из способов решения этой проблемы - добавление кэш-памяти. Как мы
говорили в разделе «Кэш-память» главы 2, кэш-память содержит наиболее часто используемые слова, что повышает скорость доступа к ним. Если достаточно большой процент нужных слов находится в кэш-памяти, время ожидания может сильно сократиться.
Одной из самых эффективных технологий одновременного увеличения пропускной способности и уменьшения времени ожидания является применение нескольких блоков кэш-памяти. Основная технология - введение отдельной кэш- памяти для команд и отдельной для данных (разделенной кэш-памяти). Такая кэш-память имеет несколько преимуществ. Во-первых, операции могут начинаться независимо в каждой кэш-памяти, что удваивает пропускную способность системы памяти. Именно по этой причине в микроархитектуре Mic-1 нам понадобились два отдельных порта памяти: особый порт для каждой кэш-памяти. Отметим, что каждая кэш-память имеет независимый доступ к основной памяти.
В настоящее время многие системы памяти гораздо сложнее этих. Между
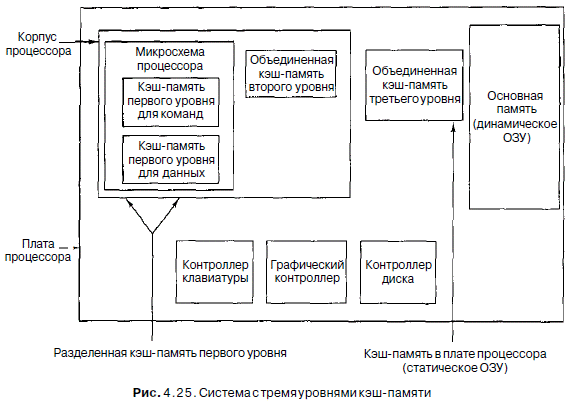
разделенной кэш-памятью и основной памятью часто помещается кэш-память второго уровня. Вообще говоря, может быть три и более уровней кэш-памяти, поскольку требуются более продвинутые системы. На рис. 4.25 изображена система с тремя уровнями кэш-памяти. Прямо на микросхеме центрального процессора находится небольшая кэш-память для команд и небольшая кэш-память для данных, обычно от 16 до 64 Кбайт. Есть еще кэш-память второго уровня, которая расположена не на самой микросхеме процессора, а рядом с ним в том же блоке. Кэш-память второго уровня соединяется с процессором через высокоскоростной тракт данных. Эта кэш-память обычно не является разделенной и содержит смесь даных и команд. Ее размер - от 512 Кбайт до 1 Мбайт. Кэш-память третьего уровня находится на той же плате, что и процессор, и обычно состоит из статического ОЗУ в несколько мегабайтов, которое функционирует гораздо быстрее, чем динамическое ОЗУ основной памяти. Обычно все содержимое кэш-памяти первого уровня находится в кэш-памяти второго уровня, а все содержимое кэш-памяти второго уровня находится в кэш-памяти третьего уровня. Существует два типа локализации адресов. Работа кэш-памяти зависит от этих типов локализации. Пространственная локализация основана на вероятности, что в скором времени появится потребность обратиться к ячейкам памяти, которые расположены рядом с недавно вызванными ячейками. Исходя из этого наблюдения в кэш-память переносится больше данных, чем требуется в данный момент. Временная локализация имеет место, когда недавно запрашиваемые ячейки запрашиваются снова. Это может происходить, например, с ячейками памяти, находящимися рядом с вершиной стека или с командами внутри цикла. Принцип временной локализации используется при выборе того, какие элементы выкинуть из кэш-памяти в случае промаха кэш-памяти. Обычно отбрасываются те элементы, к которым давно не было обращений.
Во всех типах кэш-памяти используется следующая модель. Основная память
разделяется на блоки фиксированного размера, которые называются строками кэш-памяти. Строка кэш-памяти состоит из нескольких последовательных байтов (обычно от 4 до 64). Строки нумеруются, начиная с 0, то есть если размер строки составляет 32 байта, то строка 0 - это байты с 0 по 31, строка 1 - байты с 32 по 63 и т. д. В любой момент несколько строк находится в кэш-памяти. Когда происходит обращение к памяти, контроллер кэш-памяти проверяет, есть ли нужное слово в данный момент в кэш-памяти. Если есть, то можно сэкономить время, требуемое на доступ к основной памяти. Если данного слова в кэш-памяти нет, то какая-либо строка из нее удаляется, а вместо нее помещается нужная строка из основной памяти или из кэш-памяти более низкого уровня. Существует множество вариаций данной схемы, но в их основе всегда лежит идея держать в кэш-памяти как можно больше часто используемых строк, чтобы число успешных обращений к кэш-памяти было максимальным.
Кэш-память прямого отображения
Самый простой тип кэш-памяти - это кэш-память прямого отображения. Пример одноуровневой кэш-памяти прямого отображения показан на рис. 4.26, а. Данная кэш-память содержит 2048 элементов. Каждый элемент (ряд) может вмещать ровно одну строку из основной памяти. Если размер строки кэш-памяти 32 байта (для этого примера), кэш-память может вмещать 64 Кбайт. Каждый элемент кэш-памяти состоит из трех частей:
1. Бит достоверности указывает, есть ли достоверные данные в элементе или нет. Когда система загружается, все элементы маркируются как недостоверные.
2. Поле «Тег» состоит из уникального 16-битного значения, указывающего
соответствующую строку памяти, из которой поступили данные.
3. Поле «Данные» содержит копию данных памяти. Это поле вмещает одну
строку кэш-памяти в 32 байта.
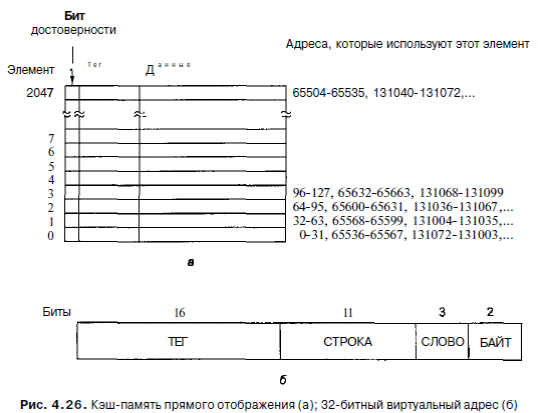
В кэш-памяти прямого отображения данное слово может храниться только в одном месте. Если дан адрес слова, то в кэш-памяти его можно искать только в одном месте. Если его нет на этом определенном месте, значит, его вообще нет в кэш-памяти. Для хранения и удаления данных из кэш-памяти адрес разбивается на 4 компонента, как показано на рис. 4.26, б:
1. Поле «ТЕГ» соответствует битам, сохраненным в поле «Тег» элемента кэш-памяти.
2. Поле «СТРОКА» указывает, какой элемент кэш-памяти содержит соответ-
ствующие данные, если они есть в кэш-памяти.
3. Поле «СЛОВО» указывает, на какое слово в строке производится ссылка.
4. Поле «БАЙТ» обычно не используется, но если требуется только один байт, поле сообщает, какой именно байт в слове нужен. Для кэш-памяти, поддерживающей только 32-битные слова, это поле всегда будет содержать 0. Когда центральный процессор выдает адрес памяти, аппаратное обеспечение выделяет из этого адреса 11 битов поля «СТРОКА» и использует их для поиска в кэш-памяти одного из 2048 элементов. Если этот элемент действителен, то производится сравнение поля «Тег» основной памяти и поля «Тег» кэш-памяти. Если юля равны, это значит, что в кэш-памяти есть слово, которое запрашивается. Такая: итуация называется удачным обращением в кэш-память. В случае удачного обрадения слово берется прямо из кэш-памяти, и тогда не нужно обращаться к основной памяти. Из элемента кэш-памяти берется только нужное слово. Остальная часть элемента не используется. Если элемент кэш-памяти недействителен (недостоверен) или поля «Тег» не совпадают, то нужного слова нет в памяти. Такая ситуация называется промахом кэш-памяти. В этом случае 32-байтная строка вызывается -13 основной памяти и сохраняется в кэш-памяти, заменяя тот элемент, который гам был. Однако если существующий элемент кэш-памяти изменяется, его нужно тписать обратно в основную память до того, как он будет отброшен. Несмотря на сложность решения, доступ к нужному слову может быть чрезвыайно быстрым. Поскольку известен адрес, известно и точное нахождение слова, ели оно имеется в кэш-памяти. Это значит, что можно считывать слово из кэш-памяти и доставлять его процессору и одновременно с этим устанавливать, правильное ли это слово (путем сравнения полей «Тег»), Поэтому процессор в действительности получает слово из кэш-памяти одновременно или даже до того, как станет известно, требуемое это слово или нет. При такой схеме последовательные строки основной памяти помещаются в поседовательные элементы кэш-памяти. Фактически в кэш-памяти может храниться до 64 Кбайт смежных данных. Однако две строки, адреса которых различаются явно на 64 К (65, 536 байт) или на любое целое кратное этому числу, не могут >дновременно храниться в кэш-памяти (поскольку они имеют одно и то же значение в поле «СТРОКА»). Например, если программа обращается к данным с адресом X, а затем выполняет команду, которой требуются данные с адресом Х+ 65, 536 (или с любым другим адресом в той же строке), вторая команда требует перезагрузки элемента кэш-памяти. Если это происходит достаточно часто, то могут возникнуть проблемы. В действительности, если кэш-память плохо работает, то тучше бы вообще не было кэш-памяти, поскольку при каждой операции с памятью считывается целая строка, а не одно слово.
Кэш-память прямого отображения - это самый распространенный тип кэш-памяти, и она достаточно эффективна, поскольку коллизии, подобные описанной выше, случаются крайне редко или вообще не случаются. Например, очень хороший компилятор может учитывать подобные коллизии при размещении команд и щнных в памяти. Отметим, что указанный выше случай не произойдет в системе,
•де команды и данные находятся раздельно, поскольку конфликтующие запросы будут обслуживаться разными блоками кэш-памяти. Таким образом, мы видим второе преимущество наличия двух блоков кэш-памяти вместо одного: большая гибкость при разрешении конфликтных ситуаций.
Ассоциативная кэш-память с множественным доступом
Как было сказано выше, различные строки основной памяти конкурируют за правозанять одну и ту же область в кэш-памяти. Если программе, которая применяет кэш-память, изображенную на рис. 4.26, а, часто требуются слова с адресами 0 и 65 536, то будут иметь место постоянные конфликты и каждое обращение потенциально повлечет за собой вытеснение какой-то определенной строки кэш-памяти. Чтобы разрешить эту проблему, нужно сделать так, чтобы в каждом элементе кэш-памяти помещалось по две и более строк. Кэш-память с п возможными элементами для каждого адреса называется n-входовой ассоциативной кэш-памятью. Четырехвходовая ассоциативная кэш-память изображена на рис. 4.27.

Ассоциативная кэш-память с множественным доступом по сути гораздо сложнее, чем кэш-память прямого отображения, поскольку хотя элемент кэш-памяти и можно вычислить из адреса основной памяти, требуется проверить п элементов кэш-памяти, чтобы узнать, есть ли там нужная нам строка. Тем не менее практика показывает, что двувходовая или четырехвходовая ассоциативная кэш-память дает хороший результат, поэтому внедрение этих дополнительных схем вполне оправданно.
Использование ассоциативной кэш-памяти с множественным доступом ставит разработчика перед выбором. Если нужно поместить новый элемент в кэш-память, какой именно из старых элементов нужно убрать? Для многих целей хорошо подходит алгоритм LRU (Least Recenly Used - алгоритм удаления наиболее давно использовавшихся элементов). Имеется определенный порядок каждого набора ячеек, которые могут быть доступны из данной ячейки памяти. Всякий раз, когда осуществляется доступ к любой строке, в соответствии с алгоритмом список обновляется и маркируется элемент, к которому произведено последнее обращение. Когда требуется заменить какой-нибудь элемент, убирается тот, который находится
в конце списка, то есть тот, который использовался давно по сравнению со всеми другими.
Возможна также 2048-входовая ассоциативная кэш-память, которая содержит
один набор из 2048 элементов. Здесь все адреса памяти располагаются в этом наборе, поэтому при поиске требуется сравнивать нужный адрес со всеми 2048 тегами в кэш-памяти. Отметим, что для этого каждый элемент кэш-памяти должен содержать специальную логическую схему. Поскольку поле «СТРОКА» в данный момент имеет длину 0, поле «ТЕГ» — это весь адрес за исключением полей «СЛОВО» и «БАЙТ». Более того, когда строка кэш-памяти замещается, все 2048 ячеек являются возможными кандидатами на смену. Для сохранения упорядоченного списка потребовался бы громоздкий учет использования системных ресурсов, поэтому применение алгоритма LRU становится недопустимым. (Помните, что этот список следует обновлять при каждой операции с памятью.) Интересно, что кэш-память с высокой ассоциативностью часто не сильно превосходит по производительности кэш-память с низкой ассоциативностью, а в некоторых случаях работает даже хуже. Поэтому ассоциативность выше четырех встречается редко. Наконец, особой проблемой для кэш-памяти является запись. Когда процессор записывает слово, а это слово находится в кэш-памяти, он, очевидно, должен или обновить слово, или отбросить данный элемент кэш-памяти. Практически во всех разработках используется обновление кэш-памяти. А что же можно сказать об обновлении копии в основной памяти? Эту операцию можно отложить на потом до того момента, когда строка кэш-памяти будет готова к замене алгоритмом LRU.
Выбор труден, и ни одно из решений не является предпочтительным. Немедленное обновление элемента основной памяти называется сквозной записью. Этот подход обычно гораздо проще реализуется, и к тому же, он более надежен, поскольку современная память всегда может восстановить предыдущее состояние, если произошла ошибка. К сожалению, при этом требуется передавать больший поток информации к памяти, поэтому в более сложных проектах стремятся использовать альтернативный подход - обратную запись.
С процессом записи связана еще одна проблема: а что происходит, если нужно записать что-либо в ячейку, которая в текущий момент не находится в кэш-памяти? Должны ли данные переноситься в кэш-память или просто записываться в основную память? И снова ни один из ответов не является во всех отношениях лучшим. В большинстве разработок, в которых применяется обратная запись, данные переносятся в кэш-память. Эта технология называется заполнением по записи (write allocation). С другой стороны, в тех разработках, где применяется сквозная запись, обычно элемент в кэш-память при записи не помещается, поскольку эта возможность усложняет разработку. Заполнение по записи полезно только в том случае, если имеют место повторные записи в одно и то же слово или в разные слова в пределах одной строки кэш-памяти.
Прогнозирование ветвления
Современные компьютеры сильно конвейеризированы. Конвейер, изображенный на рис. 4.25, имеет семь стадий; более сложно организованные компьютеры содержат конвейеры с десятью и более стадиями. Конвейеризация лучше работает с линейным кодом, поэтому блок выборки команд может просто считывать последовательные слова из памяти и отправлять их в блок декодирования заранее, еще до того, как они понадобятся.
Единственная проблема состоит в том, что эта модель совершенно не реалистична. Программы вовсе не являются последовательностями линейного кода. В них полно команд перехода. Рассмотрим простые утверждения листинга 4.4. Переменная i сравнивается с 0 (вероятно, это самый распространенный тест на практике). В зависимости от результата другой переменной, к, присваивается одно из двух возможных значений.
Листинг 4.4. Фрагмент программы
i f (1—0)
к-1,
else
к=2:
Возможный перевод на язык ассемблера показан в листинге 4.5. Язык ассемблера мы будем рассматривать позже в этой книге, и детали сейчас не важны, но при определенных машине и компиляторе программа, более или менее похожая на программу листинга 4.5, вполне возможна. Первая команда сравнивает переменную i с 0. Вторая совершает переход к Else, если i не равно 0. Третья команда присваивает значение 1 переменной к. Четвертая команда совершает переход к следующему высказыванию программы. Компилятор поместил там метку Next. Пятая команда присваивает значение 2 переменной к.

Мы видим, что две из пяти команд являются переходами. Более того, одна из
них, BNE, - это условный переход (переход, который осуществляется тогда и только тогда, когда выполняется определенное условие, в данном случае это равенствоцвух операндов предыдущей команды СМР). Самый длинный линейный код состоит здесь из двух команд. Вследствие этого вызывать команды с высокой скоростью для передачи в конвейер очень трудно.
На первый взгляд может показаться, что безусловные переходы, например команда BR Next в листинге 4.5, не влекут за собой никаких проблем. Вообще говоря, в данном случае нет никакой двусмысленности в том, куда дальше идти. Почему же блок выборки команд не может просто продолжать считывать команды из целевого адреса (то есть из того места, куда будет затем осуществлен переход)? Сложность объясняется самой природой конвейеризации. На рис. 4.23, например, мы видим, что декодирование происходит на второй стадии. Следовательно, блоку выборки команд приходится решать, откуда вызывать следующую команду еще до того, как он узнает, команду какого типа он только что вызвал. Только в следующем цикле он сможет узнать, что получил команду безусловного перехода, и до этого момента он уже начал вызывать команду, следующую за безусловным
переходом. Вследствие этого существенная часть конвейеризированных машин (например, UltraSPARC II) обладает таким свойством, что сначала выполняется команда, следующая после безусловного перехода, хотя по логике вещей этого не должно быть. Позиция после перехода называется отсрочкой ветвления. Pentium II (а также машина, используемая в листинге 4.5) не обладает таким качеством, но обойти эту проблему путем усложнения внутреннего устройства чрезвычайно тяжело. Оптимизирующий компилятор постарается найти какую-нибудь полезную команду, чтобы поместить ее в отсрочку ветвления, но часто ничего подходящего нет, поэтому компилятор вынужден вставлять туда команду NOP. Это сохраняет правильность программы, но зато программа становится больше по объему и работает медленнее. С условными переходами дело обстоит еще хуже. Во-первых, они тоже содержат отсрочки ветвления, а во-вторых, блок выборки команд узнает, откуда нужно считывать команду, гораздо позже. Первые конвейеризированные машины просто простаивали до тех пор, пока не становилось известно, нужно ли совершать переход или нет. Простаивание по три или четыре цикла при каждом условном переходе, особенно если 20% команд являются условными переходами, сильно снижает производительность.
Поэтому большинство машин прогнозируют, будет производиться условный
переход, который встретился на пути, или нет. Для этого, например, можно предполагать, что все условные переходы назад будут осуществляться, а все условные переходы вперед не будут. Что касается первой части предположения, причина такого выбора состоит в том, что переходы назад часто помещаются в конце цикла. Большинство циклов выполняется много раз, поэтому переход к началу цикла будет встречаться очень часто.
Со второй частью данного предположения дело обстоит сложнее. Некоторые
переходы вперед осуществляются в случае обнаружения ошибки в программном обеспечении (например, файл не может быть открыт). Ошибки случаются редко, поэтому в большинстве случаев подобные переходы не происходят. Естественно, существует множество переходов вперед, не связанных с ошибками, поэтому процент успеха здесь не так высок, как в переходах назад. Однако это правило по крайней мере лучше, чем ничего.
Если переход правильно предсказан, то ничего особенного делать не нужно.
Просто продолжается выполнение программы. Проблема возникает в том случае, когда переход предсказан неправильно. Вычислить, куда нужно перейти, и перейти именно туда несложно. Самое сложное - отменить команды, которые уже выполнены, но которые не нужно было выполнять.
Существует два способа отмены команд. Первый способ - продолжать выполнять команды, вызванные после спрогнозированного условного перехода, до тех пор, пока одна из этих команд не попытается изменить состояние машины (например, сохранить значение в регистре). Тогда вместо того, чтобы перезаписывать этот регистр, нужно поместить вычисленное значение во временный (скрытый) регистр, а затем, когда уже станет известно, что прогноз был правильным, просто скопировать это значение в обычный регистр. Второй способ - записать значение любого регистра, который, вероятно, скоро будет переписан (например, в скрытый временный регистр), поэтому машина может вернуться в предыдущее состояние в случае неправильно предсказанного перехода. Реализация обоих способов очень сложна и требует громоздкого учета использования системных ресурсов. А если встречается второй условный переход до того, как стало известно, был ли первый условный переход предсказан правильно, все может совершенно запутаться.
Динамическое прогнозирование ветвления
Ясно, что точные прогнозы очень ценны, поскольку это позволяет процессору работать с полной скоростью. В настоящее время проводится множество исследований, целью которых является усовершенствование алгоритмов прогнозирования ветвления (например, [32,70,108,125,138,163]). Один из подходов - хранить специальную таблицу (в особом аппаратном обеспечении), в которую центральный процессор записывает условные переходы, когда они встречаются, и там их можно искать, когда они снова появятся. Простейшая версия такой схемы показана на рис. 4.28, а. В данном случае эта таблица содержит одну ячейку для каждой команды условного перехода. В ячейке находится адрес команды перехода, а также бит, который указывает, был ли сделан переход, когда эта команда встретилась последний раз. Прогноз состоит в том, что программа пойдет тем же путем, каким она пошла в прошлый раз после этой команды перехода. Если прогноз неверен,
бит в таблице меняется.
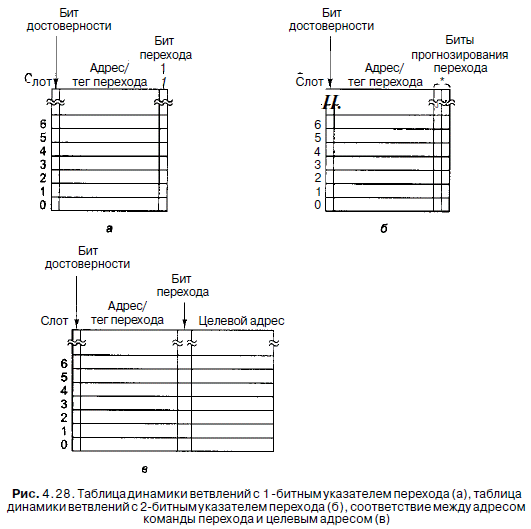
Существует несколько способов организации данной таблицы. В действи-
тельности точно такие же способы используются при организации кэш-памяти. Рассмотрим машину с 32-битными командами, которые расположены таким образом, что два младших бита каждого адреса памяти - 00. Таблица содержит 2П ячеек (строк). Из команды перехода можно извлечь п+2 младших бита и осуществить сдвиг вправо на два бита. Это n-битное число можно использовать в качестве индекса в таблице, где проверяется, совпадает ли адрес, сохраненный там, с адресом перехода. Как и в случае с кэш-памятью, здесь нет необходимости сохранять п+2 младших бита, поэтому их можно опустить (то есть сохраняются только старшие адресные биты — тег). Если адреса совпали, бит прогнозирования используется для предсказания перехода. Если тег неправильный или элемент недействителен, значит, имеет место несовпадение. В этом случае можно применять правило
перехода вперед/назад. Если таблица динамики переходов содержит, скажем, 4096 элементов, то адреса 0, 16384, 32768,... будут конфликтовать; аналогичная проблема встречается и при работе с кэш-памятью. Здесь возможно такое же решение: двухальтернативный, четырехальтернативный, n-альтернативный ассоциативный элемент. Как и у кэш-памяти, предельный случай - один п-альтернативный ассоциативный элемент. При достаточно большом размере таблицы и достаточной ассоциативности эта схема хорошо работает в большинстве ситуаций. Тем не менее систематически встречается одна проблема. Когда происходит выход из цикла, переход в конце будет предсказан неправильно, и, что еще хуже, этот неправильный прогноз изменит бит в таблице, который теперь будет указывать, что переход совершать не надо.
В следующий раз, когда опять будет выполняться цикл, переход в конце первого прохождения цикла будет спрогнозирован неправильно. Если цикл находится внутри другого цикла или внутри часто вызываемой процедуры, эта ошибка будет повторяться слишком часто.
Для устранения такой ситуации мы немного изменим метод, чтобы прогноз
менялся только после двух последовательных неправильных предсказаний. Такой подход требует наличия двух предсказывающих битов в таблице: один указывает, предполагается ли совершить переход или нет, а второй указывает, что было сделано в прошлый раз. Таблица показана на рис. 4.28, 6. Этот алгоритм можно представить в виде конечного автомата с четырьмя состояниями (рис. 4.29). После ряда последовательных успешных предсказаний «перехода нет» конечный автомат будет находиться в состоянии 00 и в следующий раз также прогнозировать, что «перехода нет». Если этот прогноз неправильный, автомат переходит в состояние 01, но в следующий раз все равно предсказывает отсутствие перехода. Только в том случае, если это последнее предсказание ошибочно, конечный автомат перейдет в состояние 11 и будет все время прогнозировать наличие перехода. Фактически, левый бит - это прогноз, а правый бит - это то, что было сделано в прошлый раз (то есть был ли совершен переход). В данной разработке используется только 2 специальных бита, но возможно применение и 4, и 8 битов. Это не первый конечный автомат, который мы рассматриваем. На рис. 4.19 тоже изображен конечный автомат. На самом деле все наши микропрограммы можно считать конечными автоматами, поскольку каждая строка представляет особое состояние, в котором может находиться автомат, с четко определенными переходами к конечному набору других состояний. Конечные автоматы очень широко используются во всех аспектах разработки аппаратного обеспечения.
Дата публикования: 2014-10-17; Прочитано: 793 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
