 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 11.1. Командная строка компилятора
|
|
ее main.С c-code.c asm-code.s obj-code.o\ libraryl.a Iibrary2.so -o program
Например, стандартный драйвер компилятора в системах семейства Unix — программа со — определяет тип файла именно по расширению. Командная строка, приведенная в примере 11.1, будет интерпретироваться следующим образом.
- main.С — текст на языке C++. Его нужно обработать препроцессором и откомпилировать компилятором C++, а затем передать то, что получится, редактору связей. Большинство компиляторов в Unix генерируют код на ассемблере, т. е. вывод компилятора еще нужно пропустить через ассемблер.
- c-code.c — текст на языке С. Он обрабатывается так же, как и программа на С ++, только вместо компилятора C++ используется компилятор С.
- asm-code.s — программа на языке ассемблера. Ее нужно обработать ассемблером и получить объектный модуль.
- obj-code.o — объектный модуль, который непосредственно можно передавать редактору связей.
- library1.a — объектная библиотека, которую нужно использовать для разрешения внешних ссылок наравне со стандартными библиотеками.
- library2.so — разделяемая библиотека, которую надо связать с создаваемым динамическим модулем.
Многие ОС, разработанные в 70-е годы, такие как RT-11, RSX-11, VAX/VMS, CP/M, навязывают программисту разделение имени на собственно имя и расширение, интерпретируя точку в имени файла как знак препинания. В таких системах имя может содержать только одну точку и соответственно иметь только одно расширение. Напротив, в ОС нового поколения — OS/2, Windows NT и даже в Windows 95 — реализована поддержка имен файлов свободного формата, которые могут иметь несколько каскадированных расширений, как и в Unix.
Однако никакие средства операционной системы не могут навязать прикладным программам правил выбора расширения для файлов данных. Это приводит к неприятным коллизиям. Например, почти все текстовые процессоры от Лексикона до Word 2000 включительно используют расширение Файла.doc (сокращение от document), хотя форматы файлов у различных процессоров и даже у разных версий одного процессора сильно различаются.
Другая проблема связана с исполняемыми загрузочными модулями. Обычно система использует определенное расширение для исполняемых файлов.
Так, VMS и системы семейства СР/М используют расширение.ехе: сокращение от executable (исполняемый). Однако по мере развития системы формат загрузочного модуля может изменяться. Так, например, OS/2 v3.0 поддерживает по крайней мере шесть различных форматов загрузочных модулей.
- 16-разрядные сегментированные загрузочные модули: формат OS/2 х
- 32-разрядные загрузочные модули, использующие "плоскую" (flat) модец, памяти: формат OS/2 2.x (LE — Linear Executable).
- 32-разрядные модули нового формата, использующие упаковку кода данных: формат OS/2 3.x (LX — Linear executable extended).
- ехе- и corn-модули DOS.
- Загрузочные модули Win 16 (NE).
- Загрузочные модули Win32s (РЕ — Portable Executable).
Для исполнения последних трех типов программ OS/2 создает виртуальную машину, работающую в режиме совместимости с 8086. Эта задача запускает копию ядра DOS и, если это необходимо, копию MS Windows, которые уже выполняют загрузку программы. Загрузочные модули всех трех "родных" форматов загружаются системой непосредственно. Так или иначе, загрузчик должен уметь правильно распознавать все форматы. При этом он не может использовать расширение файла: файлы всех перечисленных форматов имеют одинаковое расширение ЕХЕ.
Похожая ситуация имеет место в системах семейства Unix, где бинарные загрузочные модули и командные файлы вообще не имеют расширения. При этом большинство современных версий системы также поддерживает несколько различных исторически сложившихся форматов загрузочного модуля.
Разработчики Unix столкнулись с этой проблемой еще в 70-е годы. В качестве решения они предложили использовать магические числа (magic number) или сигнатуры (signature — подпись) — соглашение о том, что файлы определенного формата содержат в начале определенный байт или последовательность байтов. Первоначально это были численные коды; файл /etc/magic содержал коды, соответствующие известным типам файлов. Позднее в качестве магических чисел стали использоваться длинные текстовые строки. Так, например, изображения в формате CompuServe GIF 87а должны начинаться с символов GIF87a.
Легко понять, что магические числа ничуть не лучше расширении, а во многих отношениях даже хуже. Например, пользователь, просмотрев содержимое каталога, не может сразу узнать типы содержащихся в нем файлов. Еще хуже ситуация, когда расширение файла не соответствует его реальному типу. Это будет вводить в заблуждение не только пользователя, но и некоторые программы, полагающиеся при определении формата на расширение вместо магического числа.
С длинными мнемоническими текстовыми строками связана еще одна забавная проблема, которая может иметь неприятные последствия. Например-текстовый файл следующего содержания:
GIF87a — это очень плохой формат хранения изображений. Он будет воспринят некоторыми программами как изображение в формате CompuServe (GIF 87а, каковым он, безусловно, не является.
Оригинальное развитие идея магических чисел получила в современных системах семейства Unix, где сигнатура вида #!/bin/sh означает, что данный файл представляет собой интерпретируемую программу, интерпретатор которой хранится в файле /bin/sh (в данном случае это стандартный командный процессор).
Пытаясь как-то решить проблему идентификации типа файла, разработчики Macintoch отказались как от расширений, так и от магических чисел. В MacOS каждый файл состоит из двух частей или ветвей (forks): ветви данных (data fork) и ветви ресурсов (resource fork). Кроме идентификатора типа файла, ветвь ресурсов хранит информацию о:
- значке, связанном с этим файлом;
- расположении значка в открытой папке (folder);
- программе, которую нужно запустить при "открытии" этого файла.
Еще дальше в этом же направлении пошли разработчики системы OS/2. В этой системе с каждым файлом связан набор расширенных атрибутов (extended attributes). Атрибуты имеют вид "ИМЯ:Значение". При этом значение может быть как текстовой строкой, так и блоком двоичных данных произвольного формата и размера. Некоторые расширенные атрибуты используются оболочкой Workplace Shell (WPS) как эквивалент ветви ресурсов в MacOS: для идентификации типа файла, связанного с ним значка и размещения этого значка в открытом окне. Тип файла идентифицируется текстовой строкой. Например, программа на языке С идентифицируется строкой С code. Это резко уменьшает вероятность конфликта имен типов — ситуацию, довольно часто возникающую при использовании расширений или магических чисел.
Другие атрибуты могут применяться для других целей. Например, LAN Server — файловый сервер фирмы IBM — использует расширенные атрибуты для хранения информации о владельце файла и правах доступа к нему. Некоторые текстовые редакторы применяют расширенные атрибуты для хранения положения курсора при завершении последней сессии редактирования, так что пользователь всегда попадает в то место, где он остановился в прошлый раз.
Кроме того, расширенные атрибуты могут использоваться и для хранения сведений о назначении файла. В OS/2 существуют предопределенные расширенные атрибуты с именами subject (тема), comment (комментарии) и Key phrases (ключевые фразы), которые могут, например, использоваться для поиска документов, относящихся к заданной теме. К сожалению, такой поиск возможен, только если создатель документа позаботился о присвое нии этим атрибутам правильных значений.
Простые файловые системы
Наиболее простой файловой системой можно считать структуру, создаваемую архиватором системы UNIX — программой tar (Tape ARchive — архив на [магнитной] ленте). Этот архиватор просто пишет файлы один за другим помещая в начале каждого файла заголовок с его именем и длиной (рис. 11.5). Аналогичную структуру имеют файлы, создаваемые архиваторами типа arj; в отличие от них, tar не упаковывает файлы.

Рис. 11.5. Структура архива tar
Для поиска какого-то определенного файла вы должны прочитать первый заголовок; если это не тот файл, то отмотать ленту до его конца, прочитать новый заголовок и т. д. Это не очень удобно, если мы часто обращаемся к отдельным файлам, особенно учитывая то, что цикл перемотка — считывание — перемотка у большинства лентопротяжных устройств происходит намного медленнее, чем простая перемотка. Изменение же длины файла в середине архива или его стирание вообще превращается в целую эпопею. Поэтому tar используется для того чтобы собрать файлы с диска в некую единую сущность, например, для передачи по сети или для резервного копирования, а для работы файлы обычно распаковываются на диск или другое устройство с произвольным доступом.
Для того чтобы не заниматься при каждом новом поиске просмотром всего устройства, удобнее всего разместить каталог в определенном месте, например в начале ленты. Наиболее простую, из знакомых автору, файловую систему такого типа имеет ОС RT-11. Это единственная известная автору файловая система, которая с одинаковым успехом применялась как на лентах, так и на устройствах с произвольным доступом. Все более сложные ФС, обсуждаемые далее, используются только на устройствах произвольного доступа. В наше время наиболее распространенный тип запоминающего устройства произвольного доступа — это магнитный или оптический диск, поэтому далее в тексте мы будем называть такие устройства просто дисками — для краткости, хотя такое сокращение и не вполне корректно.
В этой ФС, как и во всех обсуждаемых далее, место на диске или ленте выделяется блоками. Размер блока, как правило, совпадает с аппаратным размером сектора (512 байт у большинства дисковых устройств), однако многие фС могут использовать логические блоки, состоящие из нескольких секторов (так называемые кластеры).
Использование блоков и кластеров вместо адресации с точностью до байта обусловлено двумя причинами. Во-первых, у большинства устройств произвольного доступа доступ произволен лишь с точностью до сектора, т. е. нельзя произвольно считать или записать любой байт — нужно считывать или записывать весь сектор целиком. Именно поэтому в системах семейства Unix такие устройства называются блочными (block-oriented).
Во-вторых, использование крупных адресуемых единиц позволяет резко увеличить адресуемое пространство. Так, используя 16-битный указатель, с точностью до байта можно адресовать всего 64 Кбайт, но если в качестве единицы адресации взять 512-байтовый блок, то объем адресуемых данных сможет достичь 32 Мбайт; если же использовать кластер размером 32 Кбайт, то можно работать с данными объемом до 2 Гбайт. Аналогично, 32-битовый указатель позволяет адресовать с точностью до байта 4 Гбайт данных, т. е. меньше, чем типичный современный жесткий диск; но если перейти к адресации по блокам, то адресное пространство вырастет до 2 Тбайт, что уже вполне приемлемо для большинства современных запоминающих устройств.
Таким образом, адресация блоками и кластерами позволяет использовать в системных структурах данных короткие указатели, что приводит к уменьшению объема этих структур и к снижению накладных расходов. Под накладными расходами в данном случае подразумевается не только освобождение дискового пространства, но и ускорение доступа: структуры меньшего размера быстрее считываются, в них быстрее производится поиск и т. д. Однако увеличение объема кластера имеет оборотную сторону — оно приводит к внутренней фрагментации (см. разд. Алгоритмы динамического управления памятью).
Ряд современных файловых систем использует механизм, по-английски называемый block siiballocation, т. е. размещение частей блоков. В этих ФС кластеры имеют большой размер, но есть возможность разделить кластер на несколько блоков меньшего размера и записать в эти блоки "хвосты" от нескольких разных файлов (рис. 11.6). Это, безусловно, усложняет ФС, но позволяет одновременно использовать преимущества, свойственные и большим, и маленьким блокам. Поэтому ряд распространенных ФС, например файловая система Novell Netware 4.1 и FFS (известная также как UFS и Berkley FS), используемая во многих системах семейства Unix, применяе этот механизм.

Рис. 11.6. Субаллокация блоков
Субаллокация требует от файловой системы поддержания запаса свободных блоков на случай, если пользователю потребуется увеличить длину одного из файлов, "хвост" которого был упакован во фрагментированный блок. Учебные пособия по Netware рекомендуют поддерживать на томах с субаллокацией не менее тысячи свободных кластеров, но не предоставляют штатных методов обеспечения этого требования. Напротив, UFS показывает свободное место на диске с учетом "неприкосновенного" резерва свободного пространства, так что нулевое показываемое свободное пространство соответствует 5% или 10% физического свободного места. Объем этого резерва настраивается утилитами конфигурации ФС.
Но вернемся к простым файловым системам. В RT-11 каждому файлу выделяется непрерывная область на диске. Благодаря этому в каталоге достаточно хранить адрес первого блока файла и его длину, также измеренную в блоках. В RT-11 поступили еще проще: порядок записей в каталоге совпадает с порядком файлов на диске, и началом файла считается окончание предыдущего файла. Свободным участкам диска тоже соответствует запись в каталоге (рис. 11.7). При создании файла система ищет первый свободный участок подходящего размера.
Фактически эта структура отличается от формата tar только тем, что каталог вынесен в начало диска, и существует понятие свободного участка внутри области данных. Эта простая организация имеет очень серьезные недостатки.
- 1. При создании файла программа должна указать его длину. Часто это бывает затруднительно. Особенно неудобно увеличивать размер уже созданного файла. Точнее, это просто невозможно: вместо удлинения старого файла приходится создавать новый файл нужной длины и копировать содержимое старого файла в него.
- 2. При хаотическом создании и удалении файлов возникает проблема фрагментации свободного пространства. Для ее решения существует специальная программа SQUEESE (сжать [диск]), которая переписывает файлы г так, чтобы объединить все свободные фрагменты (рис. 11.8). Эта программа требует много времени, особенно для больших дисковых томов, и потенциально опасна: если при ее исполнении произойдет сбой системы (а с машинами третьего поколения такое случалось по нескольку раз в день), то значительная часть данных будет необратимо разрушена.

Рис. 11.7. Структура файловой системы RT-11

Рис. 11.8. Дефрагментация диска в RT-11
Для того чтобы решить обе эти проблемы, необходимо позволить файлам занимать несмежные области диска. Наиболее простым решением было бь хранить в конце каждого блока файла указатель на следующий, т. е. превра тить файл в связанный список блоков (рис. 11.9). При этом, естественно в каждом блоке хранить не 512 байт данных, а на 2 — 4 байта меньше. При строго последовательном доступе к файлу такое решение было бы впотне приемлемым, но при попытках реализовать произвольный доступ возникнут неудобства. Возможно, поэтому, а может и по каким-то исторически сложившимся причинам такое решение не используется ни в одной из известных автору ОС.
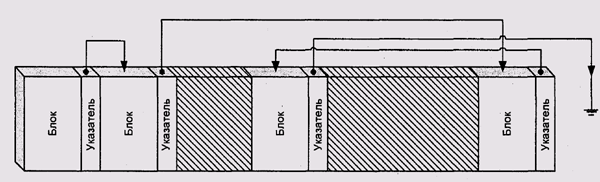
Рис. 11.9. Файл в виде односвязного списка блоков
Отчасти похожее решение было реализовано в MS DOS и DR DOS. Эти системы создают на диске таблицу, называемую FAT (File Allocation Table, таблица размещения файлов). В этой таблице каждому блоку, предназначенному для хранения данных, соответствует 12-битовое значение. Если блок свободен, то значение будет нулевым. Если же блок принадлежит файлу, то значение равно адресу следующего блока этого файла. Если это последний блок в файле, то значение — OxFFF (рис. 11.10). Существует также специальный код для обозначения плохого (bad) блока, не читаемого из-за дефекта физического носителя. В каталоге хранится номер первого блока и длина файла, измеряемая в байтах.
Емкость диска при использовании 12-битовой FAT оказывается ограничена 4096 блоками (2 Мбайт), что приемлемо для дискет, но совершенно не годится для жестких дисков и других устройств большой емкости. На таких устройствах DOS использует FAT с 16-битовыми элементами. На еще больших (более 32 Мбайт) дисках DOS выделяет пространство не блоками. а кластерами из нескольких блоков. Эта файловая система так и называется - FAT.
Она очень проста и имеет одно серьезное достоинство: врожденную устойчивость к сбоям (fault tolerance), но об этом далее. В то же время у нее есть и ряд серьезных недостатков.
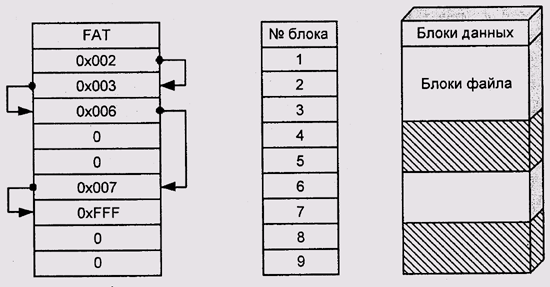
Рис. 11.10. Структура файловой системы FAT
Первый недостаток состоит в том, что при каждой операции над файлами система должна обращаться к FAT. Это приводит к частым перемещениям головок дисковода и в результате к резкому снижению производительности. Действительно, исполнение программы arj на одной и той же машине под MS DOS и под DOS-эмулятором систем Unix или OS/2 различается по скорости почти в 1,5 раза. Особенно это заметно при архивировании больших каталогов.
Использование дисковых кэшей, а особенно помещение FAT в оперативную память, существенно ускоряет работу, хотя обычно FAT кэшируется только для чтения ради устойчивости к сбоям. При этом мы сталкиваемся со специфической проблемой: чем больше диск, тем больше у него FAT, соответственно, тем больше нужно памяти. У тома Novell Netware 3.12 размером 1,115 Гбайт с размером кластера 4 Кбайт размер FAT достигает мегабайта (легко понять, что Netware использует FAT с 32-разрядными элементами. При 16-разрядном элементе FAT дисковый том такого объема с таким размером кластера просто невозможен). При монтировании такого тома Netware занимает под FAT и кэш каталогов около 6 Мбайт памяти.
Для сравнения, Netware 4 использует субаллокацию, поэтому можно относительно безнаказанно увеличивать объем кластера и нет необходимости делать кластер таким маленьким. Для дисков такого объема Netware 4 устанавливает размер кластера 16 Кбайт, что приводит к уменьшению всех структур данных в 4 раза. Понятно, что для MS DOS, которая умеет адресовать всего 1 Мбайт (1088 Кбайт, если разрешен НМА), хранить такой FAT в памяти целиком просто невозможно.
Разработчики фирмы MicroSoft пошли другим путем: они ограничили разрядность элемента FAT 16 битами. При этом размер таблицы не может превышать 128 Кбайт, что вполне терпимо. Зато вся файловая система может быть разбита только на 64 Кбайт блоков. В старых версиях MS DOS это приводило к невозможности создавать файловые системы размером 32 Мбайт.
В версиях старше 3.11 появилась возможность объединять блоки в кластеры Например, на дисках размером от 32 до 64 Мбайт кластер будет состоять из 2 блоков и иметь размер 1 Кбайт. На дисках размером 128—265 Мбайт кластер будет уже размером 4 Кбайта и т. д.
Windows 95 использует защищенный режим процессора х86, поэтому адресное пространство там гораздо больше одного мегабайта. Разработчики фирмы Microsoft решили воспользоваться этим и реализовали версию FAT с 32-битовым элементом таблицы — так называемый FAT32. Однако дисковый кэш Windows 95 не стремится удержать весь FAT в памяти; вместо этого FAT кэшируется на общих основаниях, наравне с пользовательскими данными. Поскольку работа с файлами большого (больше одного кластера) объема требует прослеживания цепочки элементов FAT, а соответствующие блоки таблицы могут не попадать в кэш, то производительность резко падает. В сопроводительном файле Microsoft признает, что производительность FAT32 на операциях последовательного чтения и записи может быть в полтора раза ниже, чем у кэшированного FAT 16.
В заключение можно сказать, что при использовании FAT на больших дисках мы вынуждены делать выбор между низкой производительностью, потребностями в значительном объеме оперативной памяти или большим размером кластера, который приводит к существенным потерям из-за внутренней фрагментации.
Для эффективного управления большими объемами данных необходимо что-то более сложное, чем FAT.
"Сложные" файловые системы
Структуры "сложных" файловых систем отличаются большим разнообразием, однако можно выделить несколько общих принципов.
Обычно файловая система начинается с заголовка, или, как это называется в системах семейства Unix, суперблока (superblock). Суперблок хранит информацию о размерах дискового тома, отведенного под ФС, указатели на начало системных структур данных и другую информацию, зависящую от типа ФС. Например, для статических структур может храниться их размер. Часто суперблок содержит также магическое число — идентификатор типа файловой системы. Аналог суперблока существует даже в FAT — это так называемая загрузочная запись (boot record).
Практически все современные ФС разделяют список свободных блоков и структуры, отслеживающие размещение файлов. Чаще всего вместо списка свободных блоков используется битовая карта, в которой каждому блоку соответствует один бит: занят/свободен. В свою очередь, список блоков для каждого файла обычно связан с описателем файла. На первый взгляд, эти описатели кажется естественным хранить в каталоге, но их, как правило, выносят в отдельные области, часто собранные в специальные области диска — таблицу инодов, метафайл и т. д. Такое решение уменьшает объем каталога и, соответственно, ускоряет поиск файла по имени. К тому же многие ФС сортируют записи в каталоге по имени файла, также с целью ускорения поиска. Понятно, что сортировка записей меньшего размера происходит быстрее.
В файловой системе HPFS, используемой в OS/2 и Windows NT, каждая запись в каталоге содержит имя файла и указатель vtajhode (файловую запись). Каталоги в этой ФС организованы в виде В-деревьев и отсортированы по именам файлов.
Файловая запись занимает один блок на диске и содержит список так называемых extent ("расширений") — (у этого термина нет приемлемого русского аналога. В переводах документации по OS/360 (ОС ЕС) так и писали: экстент.). Каждый экстент описывает непрерывную последовательность дисковых блоков, выделенных файлу. Он задает начальный блок такой последовательности и ее длину. Вместо списка свободных блоков используется битовая карта диска, в которой каждому блоку соответствует один бит: занят/свободен.
Нужно отметить, что идея экстентов далеко не нова: аншюгичная структура используется в некоторых версиях Unix с начала 80-х годов, а истоки этой идеи теряются в глубине 60-х.
Файловая запись обычно размещается перед началом первого экстента файла, хотя это и не обязательно. Она занимает один блок (512 байт) и может содержать до десяти описателей экстентов (рис. 11.11). Кроме того, она содержит информацию о времени создания файла, его имени и расширенных атрибутах (см. разд. Тип файла). Если для списка экстентов или расширенных атрибутов места не хватает, то для них также выделяются экстенты. В этом случае экстенты размещаются в виде В-дерева для ускорения поиска. Максимальное количество экстентов в файле не ограничено ничем, кроме размера диска.
Пользовательская программа может указать размер файла при его создании. В этом случае система сразу попытается выделить место под файл так, чтобы он занимал как можно меньше экстентов. Если программа не сообщила размера файла, используется значение по умолчанию. Фактически, HPFS размещает место под файл по принципу worst fit (наименее подходящего), начиная выделение с наибольшего непрерывного участка свободного пространства. В результате фрагментированными оказываются только файлы, длина которых увеличивалась многократно или же те, которые создавались при почти заполненном диске. При нормальной работе файл редко занимает больше 3—4 экстентов.
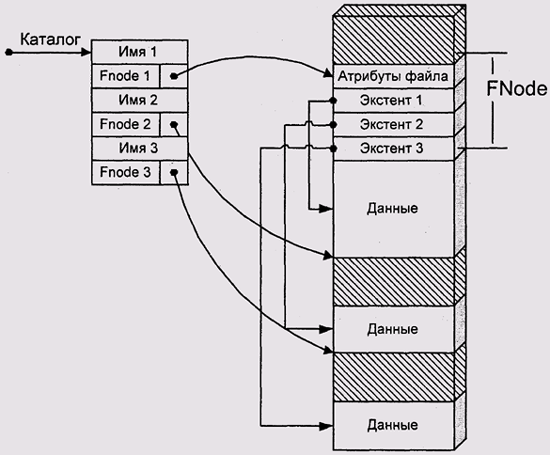
Рис. 11.11. Каталог и файловая запись в HPFS
Еще одно любопытное следствие применения стратегии worst fit заключается в том, что пространство, освобожденное стертым файлом, обычно используется не сразу. Отмечались случаи, когда файл на активно используемом диске удавалось восстановить через несколько дней после стирания.
Экстенты открытых файлов и карта свободных блоков во время работы размещаются в ОЗУ, поэтому производительность такой ФС в большинстве ситуаций намного (в 1,5—2 раза и более) выше, чем у FAT с тем же объемом кэша, при вполне приемлемых потребностях в памяти и размере кластера 512 байт.
Видно также, что структура HPFS упрощает произвольный доступ к файлу: вместо прослеживания цепочки блоков нам нужно проследить цепочку экстентов, которая гораздо короче.
Более подробное описание структуры HPFS можно найти в статье [PC Magazine 1995|. Пользователи OS/2 считают целесообразным форматировать все разделы емкостью более 12SM под HPFS, поскольку при этом выигрывается скорость и увеличивается эффективность использования дискового пространства; кроме того, исчезает необходимость в дефрагментацин и появляется возможность создавать файлы и каталоги с длинными именами, не укладывающимися в модель 8.3, принятую в MS DOS.
За эти преимущества приходится платить неустойчивостью к сбоям (проблема устойчивости к системным сбоям обсуждается в разд. Устойчивость ФС к сбоям). В отличие от ДОС, спонтанные разрушения системы с последующим зависанием в OS/2 случаются относительно редко, даже при запуске программ, заведомо содержащих ошибки (как при разработке или тестировании прикладного программного обеспечения). С другой стороны, на практике "неустойчивость" приводит лишь к тому, что после аварийной перезагрузки автоматически запускается программа восстановления ФС, что увеличивает время перезагрузки в несколько раз; реальный же риск потерять данные при сбое не выше, а как показывает практика, даже существенно ниже, чем при использовании FAT, поэтому игра явно стоит свеч.
Наиболее интересна структура файловых систем в ОС семейства Unix. В этих ФС каталог не содержит почти никакой информации о файле. Там хранится только имя файла и номер его инода (i-node — по-видимому, сокращение от index node: индексная запись). Иноды всех файлов в данной ФС собраны в таблицу, которая так и называется: таблица инодов. В ранних версиях Unix таблица инодов занимала фиксированное пространство в начале устройства; в современных файловых системах эта таблица разбита на участки, распределенные по диску.
Например, в файловой системе BSD Unix FFS (Fast File System — быстрая файловая система), которая в Unix SVR4 называется просто UFS (Unix File System), диск разбит на группы цилиндров. Каждая группа цилиндров содержит копию суперблока, битовую карту свободных блоков для данного участка и таблицу инодов для файлов, расположенных в пределах этого участка (рис. 11.12). Такая распределенная структура имеет два преимущества.
- Ускорение доступа к системным структурам данных. Когда системные данные расположены вблизи от блоков пользовательских данных, уменьшается расстояние, на которое перемещаются головки дисковода.
- Повышенная устойчивость к сбоям носителя. При повреждении участка поверхности диска теряется только небольшая часть системных данных. Даже потеря суперблока не приводит к потере структуры файловой системы.
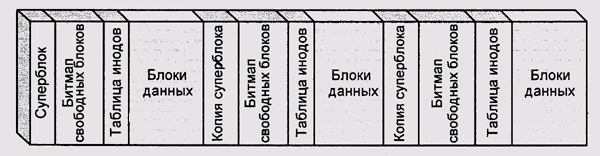
Рис. 11.12. Блоки цилиндров FFS
Инод хранит информацию о самом файле и его размещении на диске (рис. 11.13, пример 11.2). Информационная часть инода может быть получена системным вызовом
int stat(const char * fname, struct stat * buf);
Формат структуры stat описан во многих руководствах по языку С. ОС UNIX и стандарту POSIX, например, в работе (Керниган-Ритчи 2000|. Эта структура содержит следующую информацию.
- Тип файла. Исследуя это поле, можно понять, является данный объект файлом данных или специальным файлом. В этом же поле закодированы права доступа к файлу.
- Идентификаторы владельца файла и группы. Вместе с правами доступа эти два идентификатора образуют список контроля доступа файла (см разд. Списки контроля доступа).
- Время:
- создания файла;
- последней модификации файла;
- последнего доступа к файлу.
- Длина файла. Для специальных файлов это поле часто имеет другой смысл.
- Идентификатор файловой системы, в которой расположен файл.
- Количество связей файла. Это поле заслуживает отдельного обсуждения.

Рис. 11.13. Каталоги и иноды файловых систем семейства Unix
Дата публикования: 2014-11-18; Прочитано: 343 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
