 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 10.3. Более сложный драйвер контроллера гибкого диска 2 страница
|
|
В качестве параметра стратегическая функция получает указатель на структуру запроса, в которой содержатся код требуемой операции и блок данных. При этом возникает сложный вопрос, а именно — в каком адресном пространстве размещается этот блок?
На первый взгляд, идеальным решением было бы размещение этого блока сразу в пользовательском адресном пространстве. Проблема здесь в том, что стратегическая функция — особенно при обработке не первого запроса в очереди — исполняется не в пользовательском контексте, когда можно применять примитивы обмена данными с адресным пространством задачи,в контексте fork -процесса, а то и в контексте прерывания, когда адресное пространство пользователя не определено.
Возможны два варианта решения этой проблемы: хранить в структуре запроса иноке и указатель на пользовательское адресное пространство, либо все-таки копировать данные в адресное пространство системы на этапе предобработки, и обратно в пользовательское на этапе постобработки запроса. Драйвер в этом случае не должен беспокоиться ни о каком копировании, зато разработчик ОС получает дополнительную головную боль в виде логики управления буферами в адресном пространстве системы и выделения памяти для них.
Буферизация запросов и формирование очереди к блочным устройствам в Unix осуществляется специальным модулем системы, который называется дисковым кэшем. Принцип работы дискового кэша будет обсуждаться в разд. Дисковый кэш. Очереди запросов к потоковым устройствам имеют меньший объем, поэтому выделение памяти для них осуществляется обычным kmalloc.
Сервисы ядра, доступные драйверам
Следует провести различие между системными вызовами и функциями ядра, доступными для драйверов. Наборы системных вызовов и драйверных сервисов совершенно независимы друг от друга. Как правило, системные вызовы недоступны для драйверов, а драйверные сервисы — для пользовательских программ.
Системный вызов включает в себя переключение контекста между пользовательской программой и ядром. В системах с виртуальной памятью во время такого переключения процессор переходит из "пользовательского" режима, в котором запрещены или ограничены доступ к регистрам диспетчера памяти, операции ввода-вывода и ряд других действий, в "системный", в котором все ограничения снимаются. Обычно системные вызовы реализуются с использованием специальных команд процессора, чаше всего — команды программного прерывания.
Драйвер же исполняется в "системном" режиме процессора и, как правило, в контексте ядра, поэтому для вызова сервисов ядра драйверу не надо делать никаких переключений контекста. Практически всегда такие вызовы реализуются обычными командами вызова подпрограммы.
Еще одно важное различие состоит в том, что, исполняя системный вызов, программисту не надо заботиться о его реентерабельности: ядро либо обеспечивает подлинную реентерабельность, либо создает иллюзию рентабельности благодаря тому, что исполняется с более высоким приоритетом, чем все пользовательские программы. Напротив, доступные драйверам сервисы ядра делятся на две группы — те сервисы, которые можно вызывать из обработчиков прерываний и те, которые нельзя.
Сервисы, доступные для обработчиков прерываний, должны удовлетворят двум требованиям: они должны быть реентерабельными и завершаться за гарантированное время. Например, выделение памяти может потребовать сборки мусора или даже поиска жертвы для удаления в адресных пространствах пользовательских задач. Кроме того, выделение памяти требует работы с разделяемым ресурсом (пулом памяти ядра) и его достаточно сложно реализовать реентерабельным образом, поэтому обработчикам прерываний очень редко разрешают запрашивать память.
Копирование данных между пользовательским и системным адресными пространствами может привести к возникновению страничного отказа, время обработки которого может быть непредсказуемо большим.
Далее, для краткости, мы будем называть доступные для обработчиков прерываний сервисы реентерабельными, хотя для них важна не только реентерабельность, но и завершение в течение фиксированного времени. В предыдущих разделах мы упоминали некоторые категории сервисов, предоставляемых драйверам. Эти сервисы включают в себя (приведенный список не является исчерпывающим) следующие.
- Взаимодействие с конфигурацией системы — доступ к данным средств автоконфигурации и, кроме того, регистрация драйвера и управляемых им устройств в системе.
- Сбор и сохранение статистики.
- Запросы на выделение и освобождение системных ресурсов, в первую очередь памяти.
- Примитивы межпоточного взаимодействия — между нитями самого драйвера, между драйвером и другими нитями ядра и, наконец, между драйвером и нитями пользовательского процесса.
- Таймеры.
- Передача данных из пользовательского адресного пространства и обратно и другие операции над пользовательским адресным пространством.
- Сервисные функции.
Некоторые из групп этих функций будут подробнее описаны далее.
Автоконфигурация
| — В моем поле зрения появляется новый объект. Возможно, ты шкаф? — Нет — Возможно ты стол? — Нет — Каков твой номер? — Женский — Иду на вы — Иди Б. Гребенщиков |
Автоматическое определение установленных в системе устройств и их конфигурации экономит время и силы администратора при установке и перенастройке ОС. Разработчику ОС, впрочем, не следует полностью полагаться на автоконфигурацию, особенно при широком спектре оборудования, поддерживаемого системой: ошибки бывают не только в программном обеспечении, но и в аппаратных устройствах, в том числе и в той части логики контроллера, которая обеспечивает его идентификацию и автонастройку.
Автонастройка возможна только при определенной поддержке со стороны аппаратуры. Такая поддержка может обеспечиваться несколькими способами.
- Каждое устройство имеет фиксированные адреса регистров. Системная шина либо генерирует исключение по отсутствию адресуемого устройства, либо при чтении с несуществующего адреса возвращает фиксированное значение (чаще всего 0 или OxFFFFFFFF). Во втором случае достаточно, чтобы один из регистров устройства после включения питания обязательно содержал значение, отличающееся от этого фиксированного. Функция probe драйвера обращается к регистрам этого устройства, и, прочитав правильное значение и не получив при этом ошибки шины, может сделать вывод, что устройство присутствует. Устройства, у которых нет драйверов, таким способом не могут быть обнаружены, но ОС все равно не сможет с ними работать. Этот метод плох тем, что трудно применим при большом числе изготовителей периферийных устройств и широкой номенклатуре этих устройств — конфликты между адресами устройств различных изготовителей практически неизбежны.
- Каждое устройство имеет ПЗУ, которое географически отображается на адреса системной шины. После запуска загрузочный монитор сканирует все возможные адреса таких ПЗУ и исполняет хранящийся в найденных микросхемах код. Этот код регистрирует устройство в конфигурационной базе данных загрузочного монитора. ОС после загрузки обращается к этой базе. Данный метод плох тем, что применим, только если устройства подключаются к системам с бинарно совместимыми центральными процессорами.
- Каждое устройство содержит набор конфигурационных регистров, обк но также адресуемых географически. Эти регистры содержат тот или иной уникальный идентификатор устройства и, возможно, сведения о конфигурации. Сканирование этих регистров может осуществляться как самой системой, так и загрузочным монитором. Этот метод лишен татков двух предыдущих и широко применяется в большинстве современных периферийных шин, например в PCI.
Приведенные рассуждения справедливы не только для устройств, имеющих адреса на системной шине, но и для устройств, подключаемых к шинам собственной адресацией, например SCSI. Количество адресов шины SCSI невелико, поэтому подсистема автоконфигурации быстро может просканировать их все. Каждое устройство SCSI должно поддерживать команду INQUIRY, в качестве ответа на которую обязано вернуть тип устройства и другую информацию, в частности, название изготовителя и модели, поддерживаемую версию протокола SCSI и др. Одна из форм команды INQUIRY позволяет также проверить, поддерживает ли устройство какую-либо другую команду из набора команд SCSI.
Одна из серьезных неприятностей, которая может возникнуть при автоконфигурации — это конфликт устройств по каким-либо ресурсам, чаще всего — адресам всех или некоторых регистров; линии запроса или вектору прерывания. Если первый конфликт разрешим только перенастройкой аппаратуры (устройства с одним и тем же адресом на шине гарантированно неработоспособны, а в некоторых случаях могут сделать неработоспособной всю шину), то второй может быть обойден сугубо программными средствами.
Действительно, ничто не мешает драйверам конфликтующих устройств разделять один вектор прерывания. При приходе запроса прерывания по этому вектору вызывается один из обработчиков. Он анализирует состояние своего устройства, и если обнаруживает, что прерывание вызвано им, обрабатывает его. Если же прерывание не его, он просто вызывает следующий обработчик.
Эта схема допускает каскадирование потенциально неограниченного количества обработчиков, с тем очевидным недостатком, что каждое дополнительное звено цепочки значительно увеличивает задержку прерывания для всех последующих драйверов.
Большинство современных ОС использует более сложный механизм обработки прерываний, когда пролог и эпилог прерывания исполняются сервисной функцией, предоставленной ядром системы, и уже эта функция вызывает собственно обработчик. Протокол обмена вызывающей функции с обработчиком может включать в себя код возврата: обработчик должен при этом сообщать, "его" это прерывание или не "его". В последнем случае необходимо вызвать следующий обработчик, и так далее.
Эта схема также допускает неограниченное каскадирование и обладает тем же недостатком, что и предыдущая, а именно — увеличивает задержку для последних обработчиков в цепочке.
В любом случае, разделение векторов прерываний требует активной кооперации со стороны обработчиков этих прерываний.
Выделение памяти
Алгоритмы выделения памяти, в том числе и пригодные для использования в ядре ОС, подробно обсуждались в главе 4. Кроме того, мы уже упомянули тот печальный факт, что в контексте прерывания система обычно не позволяет запрашивать ресурсы. Важно остановиться еще на двух аспектах проблемы.
go-первых, ядро ОС обычно размешается в физической памяти и не подвергается страничному обмену, поэтому память ядра представляет собой более дефицитный ресурс, чем виртуальная память, доступная прикладным программам. Разработчик модуля ядра должен иметь это в виду и не прибегать к экстравагантным схемам управления буферами, которые иногда применяются в прикладных программах. Управлению большими объемами буферов, в частности дисковым кэшем, в книге посвящен разд. Дисковый кэш.
Во-вторых, в ряде случаев, драйвер не может удовлетвориться любым участком физического ОЗУ: например, некоторые старые контроллеры ПДП или периферийной шины не могут адресовать всю физическую память. Так, контроллер ПДП шины ISA имеет 24-разрядный адрес и способен, таким образом, адресовать только младшие 16 Мбайт ОЗУ (рис. 10.8). Некоторые контроллеры ПДП требуют выравнивания буфера, чаще всего на границу страницы.
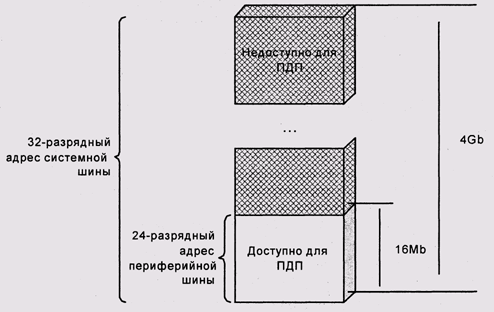
Рис. 10.8. Ограничения для буферов ПДП
Это является дополнительным доводом в пользу того, чтобы при данными с внешним устройством копировать их в системный буфер а использовать непосредственно пользовательскую память, которая может быть размешена где угодно и с каким угодно выравниванием.
При выделении буферов для ПДП многие ОС позволяют задать огранпч ния, которым должен удовлетворять физический адрес выделенного буфера Не каждый требуемый драйверу ресурс может быть выделен немедленно Многие ОС предоставляют драйверу callback-функции, вызываемые, когда требуемый ресурс становится доступен.
Таймеры
Ядро обычно предоставляет два типа таймеров — часы реального времени, указывающие астрономическое время (драйверу это время обычно интересно только для сбора статистики) и собственно таймеры — механизмы, позволяющие отмерять интервалы времени.
Таймеры интересны драйверам с нескольких точек зрения. Один из важных способов их использования приведен в примере 10.1: если устройство из-за какой-либо ошибки не сгенерирует прерывания, наивный драйвер может остаться в состоянии ожидания навсегда. Чтобы этого не происходило, драйвер должен устанавливать будильник, который' сообщит основному потоку, что устройство подозрительно долго не отвечает.
Таймеры используются также как альтернатива непрерывному опросу устройства при исполнении длительных операций, например сброса устройства, если использование прерываний почему-либо нежелательно или невозможно. Если говорить именно о-сбросе, автору не известно ни одного устройства, которое генерировало бы прерывание при завершении этой операции.
Обмен данными с пользовательским процессом
Мы уже упоминали, что общение с пользовательским процессом допустимо только в одном из возможных контекстов нити ядра, а именно в пользовательском. Во всех остальных контекстах пользовательский процесс попросту не определен — точнее сказать, активный пользовательский процесс не совпадает с тем процессом, запрос которого в данный момент обрабатывается драйвером.
В этой ситуации вызов примитивов взаимодействия с этим процессом может привести к непредсказуемым результатам.
В ряде случаев вместо драйвера этот обмен осуществляют другие модули ял-ра, например процедуры пред- и постобработки запроса. Непосредственно с пользовательским адресным пространством драйвер должен общаться только в синхронной модели. В этой модели драйвер иногда оказывается вынужден решать и другие, казалось бы несвойственные ему, задачи.
Обработка сигналов драйвером в Unix
Так, в системах семейства Unix все операции ввода-вывода, а также все остальные операции, переводящие процесс в состояние ожидания, могут быть прерваны сигналом. Сигнал представляет собой примитив обработки исключений, отчасти похожий на аппаратное прерывание тем, что при обработке сигнала может быть вызвана предоставленная программистом функция-обработчик. Необработанный сигнал обычно приводит к принудительному завершению процесса.
Будучи прерван сигналом, системный вызов останавливает текущую операцию, и, если это была операция обмена данными, но данных передано не было, возвращает код ошибки EINTR, говорящий о том, что вызов был прерван и, возможно, операцию следует повторить. Код, делающий это, присутствует в примере 10.1.
Например, пользовательский процесс может использовать сигнал SIGALARM для того, чтобы установить свой собственный будильник, сигнализирующий, что операция над устройством исполняется подозрительно долго.
Если драйвер не установит своего будильника и не станет отрабатывать сигналы, посланные процессу, может возникнуть очень неприятная ситуация.
Дело в том, что в Unix все сигналы, в том числе и сигнал безусловного убийства SIGKILL, обрабатываются процедурой постобработки системного вызова. Если драйвер не передает управления процедуре постобработки, то и сигнал, соответственно, оказывается необработанным, поэтому процесс остается висеть.
Других средств, кроме посылки сигнала, для уничтожения процесса в системах семейства Unix не предусмотрено. Поэтому процесс, зависший внутри обращения к драйверу, оказывается невозможно прекратить ни изнутри, ни извне.
Автор столкнулся с этим при эксплуатации многопроцессорной версии системы SCO Open Desktop 4.0. Система была снабжена лентопротяжным устройством, подключаемым к внешней SCSI-шине. Из-за аппаратных проблем это устройство иногда "зависало", прекращая отвечать на запросы системы. Драйвер лен-топротяжки иногда правильно отрабатывал это состояние как аппаратную ошибку, а иногда тоже впадал в ступор, не пробуждаясь ни по собственному будильнику, ни по сигналам, посланным другими процессами. (По имеющимся у автора сведениям эта проблема специфична именно для многопроцессорной версии системы. По-видимому, это означает, что ошибка допущена не в драйвере, а в коде сервисных функций.) В результате процесс, обращавшийся в это время клеите, также намертво зависал, и от него нельзя было избавиться.
Из-за наличия неубиваемого процесса оказывалось невозможно выполнить нормальное закрытие системы; в частности, не получалось размонтировать файловые системы, где зависший процесс имел открытые файлы. Выполнение холодной перезагрузки системы с неразмонтированными файловыми томами
Введение в операционные систем
приводило к неприятным последствиям для этих томов. Одна из аварий, к ко торым это привело, подробно описывается в разд. Восстановление ФС после сбоя.
Сервисные функции
Набор сервисных функций, доступных драйверу, обычно представляет собой подмножество стандартной библиотеки того языка высокого уровня, на котором обычно пишутся драйверы. В большинстве современных ОС это С. При выборе этого подмножества используется простой критерий: удаляются или заменяются на более или менее ограниченные все функции, которые так или иначе содержат в себе системные вызовы. Так, функции memcpy или sprintf вполне можно оставить, malloc придется заменить на эквивалент (в ядре Linux эта функция называется kmaiioc), a fwrite драйверу вряд ли понадобится, особенно если учесть, что работа многих драйверов начинается до того, как будет смонтирована хоть одна файловая система.
Важную роль среди сервисных функций занимают операции, часто исполняемые одной командой, но такой, которую компиляторы ЯВУ в обычных условиях не генерируют. Это, прежде всего, операции обращения к регистрам ввода-вывода в машинах с отдельным адресным пространством ввода-вывода, а также команды разрешения и запрещения прерываний. На С такие операции реализуются в виде макроопределений, содержащих ассемблерную вставку.
Правила кодирования драйверов во многих ОС требуют, чтобы даже на машинах с единым адресным пространством обращения к регистрам устройств происходили посредством макросов. Такой код может быть легко портнро-ван на процессор с отдельным адресным пространством. В наше время, когда одни и те же устройства и одни и те же периферийные шины подключаются к различным процессорам, портирование драйверов между различными процессорами осуществляется весьма часто.
При портировании драйвера разработчик должен также принимать во внимание различия в порядке байтов устройства и текущего процессора. Для приведения этого параметра в соответствие обычно предоставляются функции или макросы перестановки байтов как в одном слове, так и в блоках значительного размера.
Асинхронная модель ввода-вывода с точки зрения приложений
В разд. Синхронный ввод-вывод, обсуждая асинхронную модель драйвера, мы задались вопросом: должна ли задача, сформировав запрос на ввод-вывод, дожидаться его завершения? Ведь система, приняв запрос, передает его асинхронному драйверу, который инициирует операцию на внешнем устройстве и освобождает процессор. Сама система не ожидает завершения запроса. Так должна ли пользовательская задача ожидать его?
Если было запрошено чтение данных, то ответ, на первый взгляд, очевиден:
должна. Ведь если данные запрошены, значит они сейчас будут нужны программе.
Однако можно выделить буфер для данных, запросить чтение, потом некоторое время заниматься чем-то полезным, но не относящимся к запросу, и лишь к точке, когда данные действительно будут нужны, спросить систему: а готовы ли данные? Если готовы, то можно продолжать работу. Если нет, то придется ждать (рис. 10.9).
Во многих приложениях, особенно интерактивных или работающих с другими устройствами-источниками событий, асинхронное чтение оказывается единственно приемлемым вариантом, поскольку оно позволяет задаче одновременно осуществлять обмен с несколькими источниками данных и таким образом повысить пропускную способность и/или улучшить время реакции на событие.
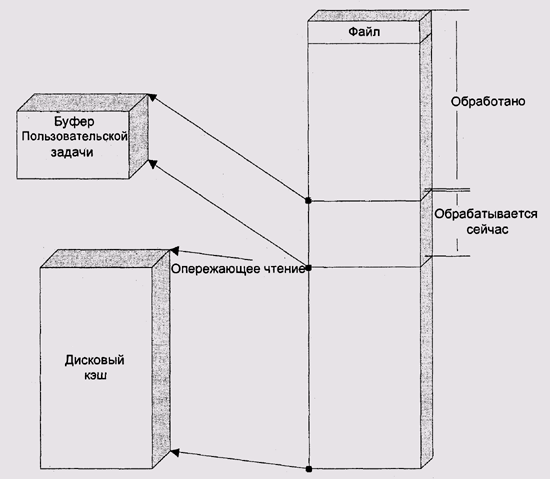
Рис. 10.9. Опережающее чтение
При записи, казалось бы, нет необходимости дожидаться физическою вершения операции. При этом мы получаем режим, известный как отложенная запись (lazy write— "ленивая" запись, если переводить дослоцц0\ Однако такой режим создает две специфические проблемы.
Во-первых, программа должна знать, когда ей можно использовать буфер данными для других целей. Если система копирует записываемые данные из пользовательского адресного пространства в системное, то эта же проблема возникает внутри ядра; внутри ядра проблема решается использованием многобуферной схемы, и все относительно просто. Однако копирование приводит к дополнительным затратам времени и требует выделения памяти под буферы. Наиболее остро эта проблема встает при работе с дисковыми и сетевыми устройствами, с которыми система обменивается большими объемами данных (а сетевые устройства еще и могут генерировать данные неожиданно). Проблема управления дисковыми буферами подробнее обсуждается в разд. Дисковый кэш.
В большинстве современных вычислительных систем общего назначения накладные расходы, обусловленные буферизацией запросов, относительно невелики или по крайней мере считаются приемлемыми. Но в системах реального времени и/или встраиваемых контроллерах, где время и объем оперативной памяти жестко ограничены, эти расходы оказываются серьезным фактором.
Если же вместо системных буферов используется отображение данных в системное адресное пространство (системы с открытой памятью можно считать вырожденным случаем такого отображения), то ситуация усложняется. Пользовательская задача должна иметь возможность узнать о физическом окончании записи, потому что только после этого буфер действительно свободен. Фактически, программа должна самостоятельно реализовать много-буферную схему или искать другие выходы.
Во-вторых, программа должна дождаться окончания операции, чтобы узнать, успешно ли она закончилась. Часть ошибок, например, попытку записи на устройство, физически не способное выполнить такую операцию, можно отловить еще во время предобработки, однако аппаратные проблемы могут быть обнаружены только на фазе исполнения запроса.
Многие системы, реализующие отложенную запись, при обнаружении аппаратной ошибки просто устанавливают флаг ошибки в блоке управления устройством. Программа предобработки, обнаружив этот флаг, отказывается исполнять следующий запрос. Таким образом, прикладная программа считает ошибочно завершившийся запрос успешно выполнившимся и обнаруживает ошибку лишь при одной из следующих попыток записи, что не совсем правильно.
Иногда эту проблему можно игнорировать. Например, если программа встречает одну ошибку при записи, то все исполнение программы считается неуспешным и на этом заканчивается. Однако во многих случаях, например, задачах управления промышленным или исследовательским оборудованием, программе необходимо знать результат завершения операции, поэтому простая отложенная запись оказывается совершенно неприемлемой.
Так или иначе, ОС, реализующая асинхронное исполнение запросов ввода-вывода, должна иметь средства сообщить пользовательской программе о физическом окончании операции и результате этой операции.
Синхронный и асинхронный ввод-вывод в RSX-11 и VMS
Например, в системах RSX-11 и VAX/VMS фирмы DEC для синхронизации используется флаг локального события (local event flag). Как говорилось в разд. Семафоры, флаг события в этих системах представляет собой аналог двоичных семафоров Дейкстры, но с ним также может быть ассоциирована процедура AST. Системный вызов ввода-вывода в этих ОС называется QIC (Queue Input/Output [Request] — установить в очередь запрос ввода-вывода) и имеет две формы: асинхронную QIO и синхронную QIOW (Queue Input/Output and Wait— установить запрос и ждать [завершения]). С точки зрения подсистемы ввода-вывода эти вызовы ничем не отличаются, просто при запросе QIO ожидание конца запроса выполняется пользовательской программой "вручную", а при QIOW выделение флага события и ожидание его установки делается системными процедурами пред- и постобработки.
В ряде систем реального времени, например, в OS-9 и RT-11, используются аналогичные механизмы.
Напротив, большинство современных ОС общего назначения не связываются с асинхронными вызовами и предоставляют прикладной программе чисто синхронный интерфейс, тем самым вынуждая ее ожидать конца операции.
Возможно, это объясняется идейным влиянием ОС Unix. Набор операций ввода-вывода, реализованных в этой ОС, стал общепризнанным стандартом де-факто и основой для нескольких официальных стандартов. Например, набор операций ввода-вывода в MS DOS является прямой копией Unix; кроме того, эти операции входят в стандарт ANSI на системные библиотеки языка С и стандарт POSIX.
Современные системы семейства Unix разрешают программисту выбирать между отложенной записью по принципу Fire And Forget (выстрелил и забыл) и полностью синхронной, используя вызов fcntl с соответствующим кодом операции.
Если все-таки нужен более детальный контроль над порядком обработки запросов, разработчикам предлагается самостоятельно имитировать асинхронный обмен, создавая для каждого асинхронно исполняемого запроса свою нить. Эта нить тем или иным способом сообщает основной нити о завершении операции. Для этого чаще всего используются штатные средства межпоточного взаимодействия — семафоры и др. Грамотное использование нитей позволяет создавать интерактивные приложения с очень высоким субъективным временем реакции, но за это приходится платить усложнением логики программы. В Windows NT/2000/XP существует средство оргащ, зации асинхронного ввода-вывода — так называемые порты завершения (операции) (completion ports). Однако это средство не поддерживается в Windows 95, поэтому большинство разработчиков избегают использования портов завершения.
Синхронная модель ввода-вывода проста в реализации и использовании и, как показал опыт систем семейства Unix и его идейных наследников, вполне адекватна большинству приложений общего назначения. Однако, как уже было показано, она не очень удобна (а иногда и просто непригодна) для задач реального времени. Следует также иметь в виду, что имитация асинхронного обмена при помощи нитей не всегда допустима: асинхронные запросы исполняются в том порядке, в котором они устанавливались в очередь, а порядок получения управления нитями в многозадачной среде не гарантирован. Поэтому, например, стандарт POSIX.4 требует поддержки наравне с нитями и средств асинхронного обмена с вызовом callback при завершении операции.
Дисковый кэш
Функции и принципы работы дискового кэша существенно отличаются от общих алгоритмов кэширования, обсуждавшихся в разд. Страничный обмен. Дело в том, что характер обращения к файлам обычно существенно отличается от обращений к областям кода и данных задачи. Например, компилятор С и макропроцессор ТЕХ рассматривают входные и выходные файлы как потоки данных. Входные файлы прочитываются строго последовательно и полностью, от начала до конца. Аналогично, выходные файлы полностью перезаписываются, и перезапись тоже происходит строго последовательно. Попытка выделить аналог рабочей области при таком характере обращений обречена на провал независимо от алгоритма, разве что рабочей областью будут считаться все входные и выходные файлы.
Тем не менее кэширование или, точнее, буферизация данных при работе с диском имеет смысл и во многих случаях может приводить к значительному повышению производительности системы. Если отсортировать механизмы повышения производительности в порядке их важности, мы получим следующий список.
- 1. Размещение в памяти структур файловой системы — каталогов, FAT пли таблицы инодов (эти понятия подробнее обсуждаются в главе И) и т. д. Это основной источник повышения производительности при использовании дисковых кэшей под MS/DR DOS.
- 2. Отложенная запись. Само по себе откладывание записи не повышает скорости обмена с диском, но позволяет более равномерно распределить по времени загрузку дискового контроллера.
- 3 Группировка запросов на запись. Система имеет пул буферов отложенной записи, который и называется дисковым кэшем. При поступлении запроса на запись, система выделяет буфер из этого пула и ставит его в очередь к драйверу. Если за время нахождения буфера в очереди в то же место на диске будет произведена еще одна запись, система может дописать данные в имеющийся буфер вместо установки в очередь второго запроса. Это значительно повышает скорость, если запись происходит массивами, не кратными размеру физического блока на диске.
- 4 Собственно кэширование. После того, как драйвер выполнил запрос, буфер не сразу используется повторно, поэтому какое-то время он содержит копию записанных или прочитанных данных. Если за это время произойдет обращение на чтение соответствующей области диска, система может отдать содержимое буфера вместо физического чтения.
- 5. Опережающее считывание. При последовательном обращении к данным чтение из какого-либо блока значительно повышает вероятность того, что следующий блок также будет считан. Теоретически опережающее чтение должно иметь тот же эффект, что и отложенная запись, т. е. обеспечивать более равномерную загрузку дискового канала и его работу параллельно с центральным процессором. На практике, однако, часто оказывается, что считанный с опережением блок оказывается никому не нужен, поэтому эффективность такого чтения заметно ниже, чем у отложенной записи.
- 6. Сортировка запросов по номеру блока на диске. По идее, такая сортировка должна приводить к уменьшению времени позиционирования головок чтения/записи (см. разд. Производительность жестких дисков). Кроме того, если очередь запросов будет отсортирована, это облегчит работу алгоритмам кэширования, которые производят поиск буферов по номеру блока.
Кэширование значительно повышает производительность дисковой подсистемы, но создает ряд проблем, причем некоторые из них довольно неприятного свойства.
Первая из проблем — та же, что и у отложенной записи. При использовании отложенной записи программа не знает, успешно ли завершилась физическая запись. При работе с дисками один из основных источников ошибок — физические ошибки диска. Однако многие современные файловые системы поддерживают так называемый hotfixing (горячую починку) — механизм, обеспечивающий динамическую замену "плохих" логических блоков на "хорошие", что в значительной мере компенсирует эту проблему.
Вторая проблема гораздо серьезнее и тоже свойственна всем механизмам отложенной записи: если в промежутке между запросом и физической записью произойдет сбой всей системы, то данные будут потеряны. Например, пользователь сохраняет отредактированный файл и. не дождавшись окончания физической записи, выключает питание — содержимое файла оказывается потеряно или повреждено. Другая ситуация, до боли знакомая всем пользователям DOS/Windows З.х/Windows 95: пользователь сохраняет файт и в это время система зависает — результат тот же. Аналогичного результата можно достичь, не вовремя достав дискету или другой удаляемый носите-ц, из привода (чтобы избежать этого, механика многих современных дисководов позволяет программно заблокировать носитель в приводе).
Очень забавно наблюдать, как пользователь, хотя бы раз имевший неприятный опыт общения с дисковым кэшем SMARTDRV, копирует данные с чужого компьютера на дискету. Перед тем, как извлечь ее из дисковода, он оглядывается на хозяина машины и с опаской спрашивает: "У тебя там никаких кэшей нет?". В эпоху MS DOS авторам доводилось наблюдать такое поведение у нескольких десятков людей.
Если откладывается запись не только пользовательских данных, но и модифицированных структур файловой системы, ситуация еще хуже: системный сбой может привести не только к потере данных, находившихся в кэше, но и к разрушению файловой системы, т. е. в худшем случае, к потере всех данных на диске.
Методы обеспечения целостности данных при системном сбое подробнее обсуждаются в разд. Устойчивость ФС к сбоям. Находившиеся в кэше данные при фатальном сбое гибнут всегда, но существуют способы избежать.повреждения системных структур данных на диске без отказа от использования отложенной записи.
Третья проблема, связанная с дисковым кэшем, — это выделение памяти под него. Уменьшение кэша приводит к снижению производительности дисковой подсистемы, увеличение же кэша отнимает память у пользовательских процессов. В системах с виртуальной памятью это может привести к увеличению дисковой активности за счет увеличения объема подкачки, что ведет к снижению как дисковой, так и общей производительности системы. Перед администратором системы встает нетривиальная задача: найти точку оптимума. Положение этой точки зависит от следующих параметров:
Дата публикования: 2014-11-18; Прочитано: 339 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
