 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 10.3. Более сложный драйвер контроллера гибкого диска 3 страница
|
|
- объема физической памяти;
- скорости канала обмена с диском,
- скорости центрального процессора;
- суммы рабочих наборов программ, исполняющихся в системе;
- интенсивности и характера обращений к диску.
При этом зависимость количества страничных отказов от объема памяти, доступной приложениям, имеет существенно нелинейный вид. Это же утверждение справедливо для связи между размером дискового кэша и соответствующей экономией обращений к диску. Таким образом, задача подбора оптимального размера кэша — это задача нелинейной оптимизации. Самое неприятное, что ключевой исходный параметр — характер обращений к диску — не количественный, а качественный; точнее сказать, его можно измерить лишь при помощи очень большого числа независимых количественных параметров.
Во многих ситуациях невозможно теоретически оценить положение оптимальной точки, и единственным способом оказывается эксперимент: прогон типичной для данной машины смеси заданий при различных объемах кэша. При этом нужно иметь возможность различать дисковую активность, связанную с обращениями к файлам и со страничным обменом. Большинство современных ОС предоставляют для этой цели различные инструменты системного мониторинга. Чаше, однако, объем кэша выставляется на глаз, а к дополнительной настройке прибегают, только если производительность оказывается слишком низкой.
Возникает вполне естественное желание возложить подбор размера кэша на саму систему, т. е. менять размер кэша динамически в зависимости от рабочей нагрузки. Кроме упрощения работы администратора, такое решение имеет еще одно большое преимущество: система начинает "автомагически" подстраиваться под изменения нагрузки.
Но далеко не все так просто. Если объем памяти в системе превосходит потребности прикладных программ, то динамический дисковый кэш может формироваться по очень простому "остаточному" принципу — все, что не пригодилось приложениям, отдается под кэш. Однако оперативная память до сих пор относительно дорога и представляет собой дефицитный ресурс, поэтому наибольший практический интерес представляет ситуация, когда памяти не хватает даже приложениям, не говоря уже о кэше. Тем не менее и в этой ситуации кэш некоторого объема бывает нужен.
Разумной политикой была бы подстройка кэша в зависимости от количества страничных отказов: если число отказов становится слишком большим, система уменьшает кэш; если же число отказов мало, а идут интенсивные обращения к диску, система увеличивает кэш. Получается саморегулирующаяся система с отрицательной обратной связью. Однако, если вдуматься, то видно, что вместо одной произвольной переменной (объема статического кэша) мы вынуждены ввести как минимум три:
- количество страничных отказов, которое считается слишком большим;
- количество отказов, которое считается достаточно малым;
- величину, на которую следует увеличить или уменьшить кэш в этих случаях.
На практике, часто также вводятся параметры, ограничивающие минимальный и максимальный размеры кэша.
Оптимальные значения этих переменных зависят практически от тех же самых параметров, что и объем статического кэша, но подбор значений экспериментальным путем оказывается значительно сложнее, потому что вместо одномерной нелинейной оптимизации мы вынуждены занимать трехмерной нелинейной оптимизацией.
Кроме того, читатель, знакомый с теорией управления, должен знать чт неудачный подбор параметров у системы с отрицательной обратной связь может приводить к колебательному процессу вместо саморегуляции, в дм куссиях USENET news приводились примеры развития таких колебаний динамическом кэше системы Windows NT при компиляции большого проекта в условиях недостатка памяти.
Вполне возможно, что низкая производительность Windows NT/2000/XP на машинах с небольшим количеством памяти объясняется вовсе не низким качеством реализации и даже не секретным сговором между фирмой Microsoft и производителями оперативной памяти, а просто плохо сбалансированным динамическим кэшем.
Спулинг
| Гигабайттебе в спул. Популярное ругательство |
Термин спулинг (spooling) не имеет общепринятого русского аналога. В соответствии с программистским фольклором, слово это происходит от аббревиатуры Simultaneous Peripherial Operation Off-Line. Эту фразу трудно дословно перевести на русский язык; имеется в виду метод работы с внешними устройствами вывода (реже — ввода) в многозадачной ОС или многомашинной среде, при котором задачам создается иллюзия одновременного доступа к устройству. При этом, однако, задачи не получают к устройству прямого доступа, а работают в режиме offline (без прямого подключения). Выводимые данные накапливаются системой, а затем выводятся на устройство так, чтобы вывод различных задач не смешивался.
Видно, что этот метод работы отчасти напоминает простую отложенную запись, но основная задача здесь не только и не столько повышение производительности, сколько разделение доступа к медленному внешнему устройству.
Чаще всего спулинг применяется для работы с печатающими устройствами, а для промежуточного хранения данных используется диск. Многие почтовые системы применяют механизм, аналогичный спулингу: если получатель не готов принять письмо, или линия связи с получателем занята, либо вообще разорвана, предназначенное к отправке письмо помещается в очередь. Затем, когда соединение будет установлено, письмо отправляется.
Классический спулинг реализован в ОС семейства Unix. В этих ОС вывод задания на печать осуществляется командой lpr. Эта команда копирует предназначенные для печати данные в каталог /usr/spoo!/lp, возможно, пропуская их при этом через программу-фильтр. Каждая порция данных помешается в отдельный файл. Имена файлов генерируются так, чтобы имя каждого вновь созданного файла было "больше" предыдущего при сравнении ASCII-колов. За счет этого файлы образуют очередь.
Системный процесс-демон (daemon) ipd (или lpshed в Unix System V) периодически просматривает каталог. Если там что-то появилось, а печатающее устройство свободно, демон копирует появившийся файл на устройство. По окончании копирования он удаляет файл, тем или иным способом уведомляет пользователя об окончании операции (в системах семейства Unix чаще всего используется электронная почта) и вновь просматривает каталог. Если там по-прежнему что-то есть, демон выбирает первый по порядку запрос и также копирует его на устройство.
Тот же механизм используется почтовой системой Unix- программой sendmail, только вместо каталога /usr/spool/lp используется /usr/spool/mail.
Этот механизм очень прост, но имеет один специфический недостаток: демон не может непосредственно ожидать появления файлов в каталоге, как можно было бы ожидать установки семафора или другого флага синхронизации. Если бы демон непрерывно сканировал каталог, это создавало бы слишком большую и бесполезную нагрузку системы. Поэтому демон пробуждается через фиксированные интервалы времени; если за это время ничего в очереди не появилось, демон засыпает вновь. Такой подход также очень прост, но увеличивает время прохождения запросов: запрос начинает исполняться не сразу же после установки, а лишь после того, как демон в очередной раз проснется.
В OS/2 и Win32 спулинг организован отчасти похожим образом с той разницей, что установка запроса в очередь может происходить не только командой PRINT, но и простым копированием данных на псевдоустройство LPT[1-9|. В отличие от систем семейства Unix как программа PRINT, так и псевдоустройства портов активизируют процесс спулинга непосредственно при установке запроса. Графические драйверы печатающих устройств в этих системах также используют спул вместо прямого обращения к физическому порту.
Novell Netware предоставляет специальный механизм для организации спулинга — очереди запросов. Элементы очереди в этом случае также хранятся на диске, но прикладные программы вместо просмотра каталога могут пользоваться системными функциями GetNextMessage и PutMessage. Вызов GetNextMessage блокируется, если очередь пуста; таким образом, нет необходимости ожидать пробуждения демона или специальным образом активизировать его — демон сам пробуждается при появлении запроса. Любопытно, что почтовая система Mercury Mail для Novell Netware может использовать для промежуточного хранения почты как очередь запросов, так и выделенный каталог в зависимости от конфигурации.
Глава 11. Файловые системы
- Файловые системы
- Файлы сточки зрения пользователя
- Монтирование файловых систем
- Формат имен файлов
- Операции над файлами
- Тип файла
- Простые файловые системы
- "Сложные" файловые системы
- Устойчивость ФС к сбоям
- Устойчивость к сбоям питания
- Восстановление ФС после сбоя
- Файловые системы с регистрацией намерений
- Устойчивость ФС к сбоям диска
- Драйверы файловых систем
Файловые системы
Одним из первых внешних устройств после клавиатуры и телевизора, которые перечисляются в любом руководстве по персональным компьютерам для начинающих, является магнитный диск. Вообще говоря, вместо магнитного диска в наше время может использоваться и какая-то другая энергонезависимая память, например, флэш или файловьш сервер, но наличие такой памяти является очень важным. Ведь вы же не будете набирать вашу программу каждый раз при новом включении компьютера. Правда, на 16-разрядных машинах такое еще было возможным; автору доводилось слышать легенды о людях, которые могли по памяти набрать на консольном мониторе PDP-11 тетрис. Впрочем, для современных прикладных программ, размеры загрузочных модулей которых измеряются сотнями мегабайтен, это невозможно.
Понятно также, что недостаточно иметь возможность просто запомнить программу и данные. Ведь вы можете работать с несколькими программами, или над несколькими проектами одновременно. Ясно, что записывать на бумажке, в какое место вашей энергонезависимой памяти вы что-то сохранили, по меньшей мере неудобно. Поэтому естественно желание создать специализированную программу, которая будет как-то структурировать сохраненные данные. Именно эту работу по структурированию пользовательских данных берет на себя модуль ОС, называемый файловым менеджером. Дисковые операционные системы (ДОС) состоят по сути только из файлового менеджера и загрузчика бинарных модулей.
Понятие файла вводится в самом начале любого курса компьютерного ликбеза, но мало в каком курсе дается внятное определение этого понятия. Слово файл (file) дословно переводится с английского как папка или подшивка, но такой перевод почти не добавляет ясности. Одно из наилучших определений, известных автору, звучит так: "Файл — это совокупность данных, доступ к которой осуществляется по ее имени".
файл, таким образом, противопоставляется другим объектам, доступ к которым осуществляется по их адресу, например, записям внутри файла или блокам на диске.
Примечание
ОС семейства Unix трактуют понятие файла более широко — там файлом называется любой объект, имеющий имя в файловой системе. Однако файлы, не являющиеся совокупностями данных (каталоги, внешние устройства, псевдоустройства, именованные программные каналы, семафоры Xenix), часто называют не простыми файлами, а "специальными".
Из разд. Запоминающие устройства прямого доступа нам известно, что магнитный диск или другое устройство памяти (кроме, пожалуй, файлового сервера) чаще всего организует доступ к данным не по их именам, а все-таки по адресам, например, по номеру сектора, дорожки и поверхности диска. Поэтому, если система хочет предоставлять доступ по именам, она должна хранить таблицу преобразования имен в адреса — директорию (directory), или, как чаще говорят по-русски, каталог. В каталоге хранится имя файла и другая информация о файле, такая, как его размер и местоположение на диске. Как правило, хранят также дату создания файла, дату его последней модификации, а в многопользовательских системах — идентификатор хозяина этого файла и права доступа к нему для других пользователей. Во многих файловых системах эта информация хранится не в самом каталоге, а в специальной структуре данных иноде, метафайле и т. д. В этом случае запись в каталоге содержит только имя и указатель на управляющую структуру файла.
Большинство современных операционных систем позволяет делать вложенные каталоги — файлы, которые сами являются каталогами. В таких системах файл задается полным или путевым именем (path name), состоящим из цепочки имен вложенных каталогов и имени файла в последней из них.
Совокупность каталогов и системных структур данных, отслеживающих размещение файлов на диске и свободное дисковое пространство, называется файловой системой (ФС). Иногда на диске размещается только одна файловая система. Современные ОС часто позволяют размещать на одном физическом диске несколько файловых систем, выделяя каждой из них фиксированную часть диска. Такие части диска называются разделами (partition) или слайсами (slice). Обычно разбиение диска на части производится на уровне драйвера диска, поэтому общее название частей — логические диски. С другой стороны, ряд файловых систем может занимать несколько дисков.
Файлы с точки зрения пользователя
Прежде, чем рассматривать структуры файловых систем, давайте сначал выясним, какие же операции над файлами и их именами обычно предоставляются. По аналогии с адресным пространством, иногда употребляют термин пространство имен, характеризующее совокупность всех допустимых имен файлов. Структура пространства имен зависит как от операционной так и от файловой системы. Структура каталогов ФС накладывает ограничения на длину имен файлов и символы, которые могут употребляться в именах. ОС может устанавливать собственное ограничение на длину имени файла.
Как правило, ограничения на длину имени на уровне ОС обусловлены требованием совместимости со старым программным обеспечением: если в спецификациях системных вызовов сказано, что имя файла не может содержать более 12 символов, разработчики программного обеспечения будут выделять под буфер для хранения имени файла именно столько места. Такая программа без перекомпиляции не сможет работать с именами файлов большей длины и с каталогами, содержащими такие имена.
Монтирование файловых систем
Прежде чем ОС сможет использовать файловую систему, она должна выполнить над этой системой операцию, называемую монтированием (mount). В общем случае операция монтирования включает следующие шаги.
- Проверку типа монтируемой ФС.
- Проверку целостности ФС.
- Считывание системных структур данных и инициализацию соответствующего модуля файлового менеджера (драйвера файловой системы).
- В некоторых случаях — модификацию ФС с тем, чтобы указать, что она уже смонтирована. При этом устанавливается так называемый флаг загрязнения (dirty flag). Смысл этой операции будет объяснен и разд. Устойчивость ФС к сбоям.
- Включение новой файловой системы в общее пространство имен (рис. 11.1). В различных системах это делается различными способами.
Многие пользователи MS/DR DOS никогда не сталкивались с понятием монтирования. Дело в том, что эта система (как и многие другие ДОС, например RT-11) выполняет упрощенную процедуру монтирования при каждом обращении к файлу. Упрощения состоят в пропуске шагов 1 и 2 и отсутствии шага 4 (ФС MS/DR DOS устойчива к сбоям).
ДОС, как правило, помещают в пространство имен все доступные блочные устройства, не выполняя полной процедуры монтирования. Если какое-то из этих устройств не содержит ФС известного типа, то система будет возмущаться при обращениях к такому устройству, но не удалит его из списка доступных ФС. А иногда даже не будет возмущаться — попробуйте поставить в дисковод машины под управлением MS/DR DOS-дискету, не содержащую файловой системы (например, созданную программой tar) и в командной строке набрать DIR А:. Скорее всего, вы увидите несколько экранов мусора, но ни одного сообщения об ошибке!
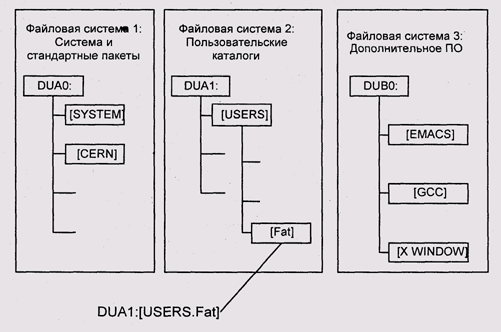
Рис. 11.1. Пространство имен ОС с несколькими ФС
Если мы монтируем ФС, размещенную на удаленной машине (файловом сервере), то шаги 1 и 2 заменяются на установление соединения этим сервером. В системах семейства СР/М при работе с файловыми серверами Novell Netware монтирование серверных файловых систем производится командой MAP, а с файловыми серверами, поддерживающими протокол SMB, — командой NET USE.
Обычно имя файла в подмонтированной файловой системе имеет вид 'ИМЯ_ФС:\имена\каталогов\имя.файла'. При этом вместо разделителей ':' и '/' могут использоваться другие символы.
Имена файловых систем в RT-11, RSX-11, VMS
В RT-11, RSX-11 и VMS в качестве имени файловой системы используется имя физического устройства, на котором размещена ФС. Если применяется DECNet, перед именем устройства можно поместить имя узла сети, на котором это устройство находится. Полное имя файла в VMS выглядит так: DUAO-lUSERS.FAT_BROTHER.WORKJtest.exe. При этом DUAO означает дисковое устройство 0, присоединенное к дисковому контроллеру A: Disk Unit д [device #] О, [USERS.FAT_BROTHER.WORK] означает каталог WORK в каталп FAT_BROTHER в каталоге USERS.
Имена файловых систем в ОС семейства СР/М
В системах семейств СР/М имена файловых систем обозначаются буквами ла тинского алфавита, а сами файловые системы часто почему-то называются "драйвами". При некотором желании можно использовать в качестве имен фг также символы '[' и ']'. Устройства А: и В: — это всегда приводы гибких дисков устройство С: — обычно первый жесткий диск, или первый раздел на первом жестком диске.
Автора всегда интересовал вопрос: "Что будет делать пользователь, когда у него кончатся доступные буквы алфавита?" При использовании только локальных дисков такая ситуация кажется маловероятной, но при подключении к нескольким файловым серверам количество используемых файловых систем резко возрастает...
В OS/2 и Windows for Workgroups эта проблема решена использованием так называемых UNC-имен, задающих имя файла в виде \\NODE\SHARE\ PATH\FILE.NAM (рис. 11.2), где NODE — имя сетевого узла, SHARE — имя разделяемого ресурса на этом узле (это может быть не только разделяемый каталог, но и принтер, а в OS/2 также и модем), a PATH\FILE.NAM — путь к файлу относительно разделяемого каталога. К сожалению, далеко не все старые (и даже многие не очень уж старые) программы понимают такие имена. Например, даже стандартный командный процессор системы Windows NT не может исполнить команду cd \\NODE\SHARE\DIR (проверялось на NT 4.0 sp4-6, 2000 sp 1 и ХР).
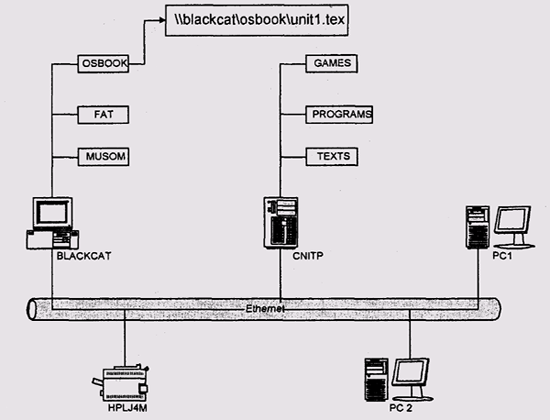
Рис. 11.2. UNC-имена
Структура пространства имен в Unix
В операционных системах семейства Unix смонтированные ФС выглядят как каталоги единого дерева (строго говоря, структура каталогов в UNIX не обязана являться деревом; но об этом см. разд. Cложные файловые системы), Это дерево начинается с корневого каталога, выделенной ФС, называемой корневой (root). Администратор системы может подмонтировать новую ФС к любому каталогу, находящемуся на любом уровне дерева (рис. 11.3). Такой каталог после этого называют точкой монтирования, но это выражение отражает только текущее состояние каталога. После того как мы размонтируем ФС, мы сможем использовать этот каталог как обычный, и наоборот, мы можем сделать точкой монтировки любой каталог.
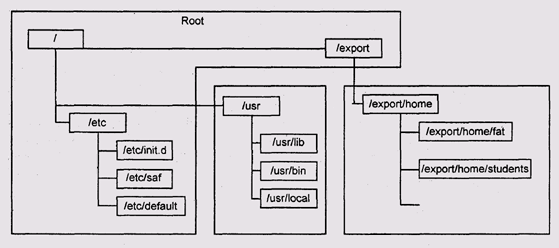
Рис. 11.3. Структура пространства имен в Unix
Такой подход имеет неочевидное, на первый взгляд, но серьезное преимущество перед раздельными пространствами имен для разных физических файловых систем. Преимущество состоит в том, что пространство имен оказывается не связанным с физическим размещением файлов. Следовательно, администратор может поддерживать неизменную структуру дерева каталогов, перемещая при этом отдельные ветви по дискам ради более эффективного использования дискового пространства или даже просто ради удобства администрирования.
По традиции все Unix-системы имеют примерно одинаковую структуру дерева каталогов: системные утилиты находятся в каталоге /bin, системные библиотеки — в каталоге /lib, конфигурационные файлы — в каталоге /etc и т. д. Например, база данных об именах пользователей всегда находится в файле /etc/passwd.
Точки монтирования реализованы и в некоторых ОС, не относящихся к семейству Unix. Так, свободно распространяемый продукт TVFS (Toronto Virtual File System) для OS/2 позволяет объединять несколько различных файловых систем (как локальных, так и сетевых) в один логический диск, монтируя реальные ФС в каталоги виртуальной. Аналогичная функциональность была реализована в Windows 2000, но почему-то только в поставке Advanced Server.
Формат имен файлов
В различных ФС допустимое имя файла может иметь различную длину ц нем могут использоваться различные наборы символов. Так, в RT-H и RSX-Ц имена файлов состоят из символов кодировки RADIX-50 и имеют длину 9 символов: 6 символов — собственно имя, а 3 — расширение. При этом имя имеет вид "ХХХХХХ.ХХХ", но символ '.' не является частью имени — это просто знак препинания. Предполагается, что расширение должно соответствовать типу данных, хранящихся в файле: SAV будет именем абсолютного загружаемого модуля, FOR — программы на Фортране, CRH - "файлом информации о системном крахе", как было написано в одном переволе руководства (попросту говоря, это посмертная выдача ОС, по которой можно попытаться понять причину аварии).
В СР/М и ее потомках MS DOS-DR DOS, а также в VMS имена файлов хранятся в 8-битной ASCII-кодировке, но почему-то разрешено использование только букв верхнего регистра, цифр и некоторых печатаемых символов. При этом в системах линии СР/М имя файла имеет 8 символов плюс 3 символа расширения, а в VMS как имя, так и расширение могут содержать более 32 символов. Все перечисленные системы используют нечувствительный к регистру букв поиск в каталогах: имена file.с, File.С и FILE.С считаются одним и тем же именем.
Ограничения на формат имени в MS DOS
Любопытно, что MS/DR DOS при поиске в каталоге переводят в верхний регистр имя, заданное пользователем, но оставляют без изменений имя, считанное из каталога. Строго говоря, это ошибка: если мы создадим имя файла, содержащее буквы нижнего регистра, то ни одна программа не сможет открыть или переименовать такой файл.
Автору довелось столкнуться с такой проблемой при попытке прочитать дискету, записанную ОС ТС (Экспериментальная UNIX-подобная ОС для Паскаль-машины N9000). Проблему удалось решить только при помощи шестнадца-теричного дискового редактора прямым редактированием имен в каталогах. Возможно, существует и более элегантное решение, но автору не удалось его найти.
Использовать конструкцию *.* бесполезно, потому что, в действительности, операции над файлами, заданными таким образом, состоят из двух операций: FindFirst/FindNext, которая возвращает [следующее] имя файла, соответствующее шаблону, и Open. FindFirst/FindNext возвращает недопустимое имя файла и Open не может использовать его. Программа CHKDSK не возражает против имен файлов в нижнем регистре. Строго говоря, это тоже ошибка. Все остальные способы, так или иначе, сводятся к прямой (в обход ДОС) модификации ФС.
Кроме того, любопытных эффектов можно достичь, попытавшись создать файл с именем, содержащим русские буквы.
Наибольшим либерализмом в смысле имен отличаются ОС семейства Unix, в которых имя файла может состоять из любых символов кодировки ASCII, кроме символов '\000' и V, например, из восьми символов перевода каретки. При этом '\000' является ограничителем имени, а V — разделителем между именем каталога и именем файла. Никакого разделения на имя и расширение нет, и хотя имена файлов с программой на языке С заканчиваются ".с", а объектных модулей — ".о", точка здесь является частью имени. Вы можете создать файл с именем "gcc-2.5.8.tar.gz". В UNIX SVR3 длина имени файла ограничена 14 символами, а в BSD UNIX, Linux и SVR4— только длиной блока на диске, т. е. 512 байтами или более. При этом нулевой символ считается концом имени в каталоге.
Возможность использовать в именах неалфавитные символы типа перевода каретки или ASCII EOT (End Of Transmission) кажется опасным излишеством. На самом деле:
- это не излишество а, скорее, упрощение — из процедур, работающих с именами, удалена проверка символа на "допустимость";
- оно не столь уж опасно: такой файл всегда можно переименовать.
В некоторых случаях процесс набора имени файла в командной строке превращается в нетривиальное упражнение, потому что shell (командный процессор) рассматривает многие неалфавитные символы как команды. Но надо отметить, что, правильно используя кавычки и символ '\', пользователь может передать команде аргумент, содержащий любые символы ASCII, кроме \000".
Длинные имена файлов в ОС семейства СР/М
В последнее время в ОС стало модным поддерживать длинные имена файлов. Отчасти это, возможно, связано с тем, что производители ПО для персональных компьютеров осознали, что системы семейства Unix являются потенциально опасными конкурентами, а длинные имена файлов традиционно считаются одним из преимуществ этого семейства.
Например, OS/2, использующая файловую систему HPFS (High Performance File System — высокопроизводительная файловая система), поддерживает имена файлов длиной до 256 символов, содержащие печатаемые символы и пробелы. Точка считается частью имени, как и в UNIX, и можно создавать имена, содержащие несколько точек. Аналогичную структуру имеют имена в NTFS, используемой в Windows NT/2000/XP, VFAT (реализация файловой системы FAT16, используемая в Windows 95/98/ME) и FAT32.
Описанные ОС при поиске файла приводят к одному регистру все алфавитные символы в имени. С одной стороны, это означает дополнительное Удобство для пользователя — при наборе имени не нужно заботиться о регистре букв, с другой — пользователь не может создать в одном каталоге файлы "text.txt" и "Text.txt". Из-за этого, например, нельзя использовать принятое в UNIX соглашение о том, что файл на языке С имеет расширение "с", а на языке C++ — "С".
Главная же проблема, возникающая при работе с нечувствительными «п гистру именами, — это преобразование регистра в именах, использующи национальные алфавиты: русский, греческий, японскую слоговую азбуку т. д. Файловая система, поддерживающая такие имена, должна учитыват языковые настройки ОС, что создает много сложностей, в том числе и при считывании удаляемых носителей, записанных в одной стране, где-нибудь за границей. В системах семейства Win32 эта проблема решена за счет хранения имен в формате Unicode.
Некоторые ОС, например, RSX-11 и VMS, поддерживают также номер версии файла. В каталоге может существовать несколько версий файла с одним именем; если номер версии при открытии файла не задается, то открывается последняя версия.
Версии файла очень удобны при разработке любых объектов, от программ или печатных плат до книг: если вам не понравились изменения, внесенные вами в последнюю версию, вы всегда можете откатиться назад. Ныне функцию хранения предыдущих версий изменяемых файлов и управляемого отката к ним реализуют специальные приложения, системы управления версиями (version control system) (RCS, CVS и др.).
Операции над файлами
Большинство современных ОС рассматривают файл как неструктурированную последовательность байтов переменной длины. В стандарте POSIX над файлом определены следующие операции.
- int open(char * fname, int flags, mode_t mode)
Эта операция "открывает" файл, устанавливая соединение между программой и файлом. При этом программа получает "ручку" или дескриптор файла — целое число, идентифицирующее данное соединение. Фактически это индекс в системной таблице открытых файлов для данной задачи. Все остальные операции используют этот индекс для ссылки на файл. Параметр char * fname задает имя файла, int flags — это битовая маска, определяющая режим открытия файла. Файл может быть открыт только для чтения, только для записи и для чтения и записи; кроме того, можно открывать существующий файл, а можно пытаться создать новым файл нулевой длины. Необязательный третий параметр mode используется только при создании файла и задает атрибуты этого файла. - off_t lseek(int handle, off_t offset., int whence)
Эта операция перемещает указатель чтения/записи в файле. Параметр offset задает количество байтов, на которое нужно сместить указатель, а параметр whence — начало отсчета смещения. Предполагается, что смещение можно отсчитывать от начала файла (SEEK_SET), от его кониа (SEEK_END) и от текущего положения указателя (SEEK_CUR). Операция возвращает положение указателя, отсчитываемое от начала файла. Таким образом, вызов iseek (handle, о, SEEK_cuR) возвратит текущее положение указателя, не передвигая его. - int read(int handle, char * where, size__t howjnuch)
Операция чтения из файла. Указатель where задает буфер, куда нужно поместить прочитанные данные; третий параметр указывает, сколько данных надо считать. Система считывает требуемое число байтов из файла, начиная с указателя чтения/записи в этом файле, и перемещает указатель к концу считанной последовательности. Если файл кончился раньше, считывается столько данных, сколько оставалось до его конца. Операция возвращает количество считанных байтов. Если файл открывался только для записи, вызов read возвратит ошибку. - int write(int handle, char * what, size__t how_much)
Операция записи в файл. Указатель what задает начало буфера данных; третий параметр указывает, сколько данных надо записать. Система записывает требуемое число байтов в файл, начиная с указателя чтения/записи в этом файле, заменяя хранившиеся в этом месте данные, и перемещает указатель к концу записанного блока. Если файл кончился раньше, его длина увеличивается. Операция возвращает количество записанных байтов. Если файл открывался только для чтения, вызов write возвратит ошибку. - int ioctl (int handle, int cmd,....)
int fcntl(int handle, int cmd,...)
Дополнительные операции над файлом. Первоначально, по-видимому, предполагалось, что ioctl — это операции над самим файлом, a fcntl — это операции над дескриптором открытого файла, но потом историческое развитие несколько перемешало функции этих системных вызовов. Стандарт POS1X определяет некоторые операции как над дескриптором, например дублирование (в результате этой операции мы получаем два дескриптора, связанных с одним и тем же файлом), так и над самим файлом, например, операцию truncate — обрезать файл до заданной длины. В большинстве версий Unix операцию truncate можно использовать и для вырезания данных из середины файла. При считывании данных из такой вырезанной области считываются нули, а сама эта область не занимает физического места на диске.
Важной операцией является блокировка участков файла. Стандарт POSIX предлагает для этой цели библиотечную функцию, но в системах семейства Unix эта функция реализована через вызов fcntl.
Большинство реализаций стандарта POSIX предлагает и свои дополнительные операции. Так, в Unix SVR4 этими операциями можно устанавливать
синхронную или отложенную запись (Подробнее понятие отложены записи обсуждается в разд. Асинхронная модель ввода-вывода с точки зрения приложений) и т. д.
- caddr t mmap(cadclr t addr, size_t len, int prot, int flags, int handle, off_t
Отображение участка файла в виртуальное адресное пространство процесса. Параметр prot задает права доступа к отображенному участку: на чтение, запись и исполнение. Отображение может происходить на заданный виртуальный адрес, или же система может выбирать адрес для отображения сама.
Еще две операции выполняются уже не над файлом, а над его именем: это операции переименования и удаления файла. В некоторых системах, например в системах семейства Unix, файл может иметь несколько имен, и существует только системный вызов для удаления имени. Файл удаляется при удалении последнего имени.
Видно, что набор операций над файлом в этом стандарте очень похож на набор операций над внешним устройством. И то, и другое рассматривается как неструктурированный поток байтов. Для полноты картины следует сказать, что основное средство межпроцессной коммуникации в системах семейства Unix (труба) также представляет собой неструктурированный поток данных. Идея о том, что большинство актов передачи данных может быть сведено к байтовому потоку, довольно стара, но Unix была одной из первых систем, где эта идея была приближена к логическому завершению.
Примерно та же модель работы с файлами принята в СР/М, а набор файловых системных' вызовов MS DOS фактически скопирован с вызовов Unix v7. В свою очередь, OS/2 и Windows NT/2000/XP унаследовали принципы работы с файлами непосредственно от MS DOS.
В системах, не имеющих Unix в родословной, может использоваться несколько иная трактовка понятия файла. Чаще всего файл трактуется как набор записей (рис. 11.4). Обычно система поддерживает записи как постоянной длины, так и переменной. Например, текстовый файл интерпретируется как файл с записями переменной длины, а каждой строке текста соответствует одна запись. Такова модель работы с файлами в VMS и в ОС линии OS/360-MVS-z/OS фирмы IBM.
Практика систем с неструктурированными файлами показала, что, хотя структурированные файлы часто бывают удобны для программиста, необязательно встраивать поддержку записей в ядро системы. Это вполне можно сделать и на уровне библиотек. К тому же структурированные файлы сами по себе не решают серьезной проблемы, полностью осознанной лишь в 80-е годы при разработке новых моделей взаимодействия человека с компьютером.
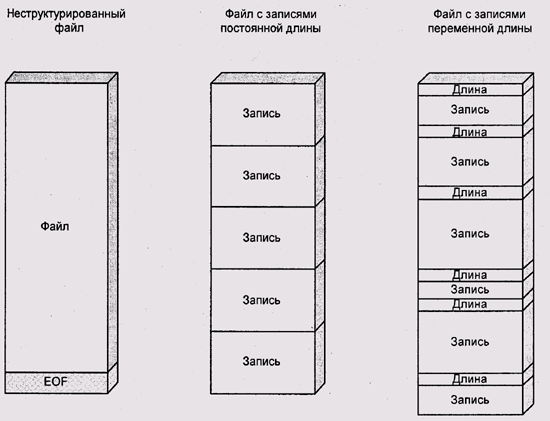
Рис. 11.4. Неструктурированный файл и файлы как наборы записей
Тип файла
Легко понять, что структурированные файлы предоставляют системе и программисту информацию о структуре хранящихся данных, но не дают никаких сведений о форме представления и смысле этих данных.
Например, с точки зрения системы исходный текст программы на языке С
и документ в формате LATEX совершенно идентичны: и то, и другое представляет собой текстовый файл (или, если угодно, файл с записями переменной длины). Однако, если мы попытаемся подать наш документ на вход С-компилятора, мы получим множество синтаксических ошибок и никакого Полезного результата.
Этот пример показывает, что во многих случаях желательно связать с файлом — неважно, структурированный ли это файл или байтовый поток — какую-то метаинформацию: в каком формате хранятся данные, какие операции над ними допустимы, а иногда и сведения о том, кому и зачем эти данные нужны.
По-видимому, наиболее общим решением этой проблемы был бы объектно-ориентированный подход, в котором файл данных рассматривается как объект, а допустимые операции — как методы этого объекта. Ни в одной из известных автору ОС эта идея в полной мере не реализована, но пользовательские интерфейсы многих современных ОС предоставляют возможность ассоциировать определенные действия с файлами различных типов.
Так, например Explorer — пользовательская оболочка Windows 95 и Windows NT 4.0 — позволяет связать ту или иную программу с файлами, имеющими определенное расширение, например, программу MS Word с файлами имеющими расширение DOC. Когда пользователь нажимает левую кнопку мыши на значке, представляющем такой файл, то автоматически запускается MS Word. Эти же ассоциации доступны и из командной строки — можно напечатать start Доклад. DOC, и опять-таки запустится MS Word.
Такое связывание очень просто в реализации и сделано не только в Explorer, но и в простых текстовых оболочках вроде Norton Commander. От ОС при этом требуется только дать возможность каким-то образом различать типы файлов.
Первые попытки ассоциировать с файлом признак типа были сделаны еще в 60-е годы. При этом идентификатор типа добавлялся к имени файла в виде короткой, но мнемонической последовательности символов — расширения (extension). В большинстве современных ОС расширение отделяется от имени символом ".", но проследить истоки этой традиции автору не удалось. При этом, например, файлы на языке С будут иметь расширение "с", на
C++ — "С", а документы в формате LATEX — "tex".
В ОС семейства Unix имя файла может содержать несколько символов ".", и, таким образом, файл может иметь несколько каскадированных расширений. Например, файл "main.С" — это программа на языке C++; "main.C.gz" — это программа на языке C++, упакованная архиватором GNU Zip с целью сэкономить место; "main.C.gz.crypt" — это программа, которую упаковали и потом зашифровали, чтобы никто посторонний не смог ее прочитать; наконец, "main.C.gz.crypt.uue" — это упакованная и зашифрованная программа, преобразованная в последовательность печатаемых символов кода ASCII, например, для пересылки по электронной почте.
В принципе, расширения являются вполне приемлемым и во многих отношениях даже очень удобным способом идентификации типа файла. Одно из удобств состоит в том, что для использования этого метода не нужно никаких или почти никаких усилий со стороны ОС: просто программы договариваются интерпретировать имя файла определенным образом.
Дата публикования: 2014-11-18; Прочитано: 407 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
