 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 10.3. Более сложный драйвер контроллера гибкого диска 1 страница
|
|
/* Обработчики прерываний в зависимости от состояния */ void schedule_seek (fdd__struct *fdd)
if (!motor_speed_pk (fdd)) {
fdd->handler = schedule_seek;
retry_spinup (); }
if (fdd->current_track!= CALCULATEJTRACK (fdd->f ile)) fdd->handler = schedule_command; seek_head(fdd, CALCULATE_TRACK (f ile) }; } else
/* Мы уже на нужной дорожке */ schedule operation (fdd);
void schedule_operation(fdd_struct *fdd) {
if (fdd->current_track!= CALCULATEJTRACK(fdd->file)) { fdd->handler = schedule_operation; retry_seek(fdd); return; }
switch(fdd->operation) (case FDD_WRITE:
fdd->handler = handle_dma_write_interrupt; setup_fdd_dma(fdd->fdd_buffer+fdd->bytes__xfered, fdd->copy_size)
I issue_write_coromand (fdd); break; case FDD_READ:
fdd->handler = handle_dma_read_interrupt;
setup_fdd_dma (fdd->fdd_buf fer-t-fdd->bytes_xfered, fdd->copy_size)
issue_read_command (fdd);
break; /* Здесь же мы должны обрабатывать другие команды,
требующие предварительного SEEK */
void handle_dma_write_interrupt (fdd_struct *fdd)
(/* Увеличить fdd->bytes_xfered на количество фактически
переданных символов * /
if (буфер полон/пуст)
/* Здесь мы не можем передавать данные из пользовательского
адресного пространства. Надо будить основную нить * /
wake_up_interruptible (&fdd->fdd_wait_queue); else {
fdd->handler = handle__dma__write_interrupt;
setup_fdd__dma (fdd->fdd_buf fer+fdd->bytes_xfered, fdd->copy_size)
issue_write_corranand(fdd);
/* Основная нить драйвера */
static int fdd_write (struct inode * inode, struct file * file,
char * buf, int count) (
/* Получить идентификатор устройства: */ unsigned int minor = MINOR (inode->i_rdev); /* Обратите внимание, что почти все переменные основной нити
"переехали" в описатель состояния устройства */ /* Найти блок переменных состояния устройства */ struct fdd struct *fdd = &fdd table [minor];
fdd->total_bytes_written = 0; fdd->operation = FDD_WRITE;
do { fdd->copy_size = (count <= FDD_BUFFER_SIZE?
count: FDD_BOFFER_SIZE);
/* Передать данные из пользовательского контекста */ memcpy_fromfs(fdd->fdd_buffer, buf, copy_size);
if (!motor_5peed_ok()) (
fdd->handler = schedule_seek;
turn_motor_on(fdd); } else
schedule_seek(fdd);
current->timeout = jiffies + FDD_INTERRUPT__TIMEOUT; inte.rruptible_sleep_on(&fdd->fdd_wait_queue); if (current->signal & ~current->blocked) { if (fdd->total_bytes_written+fdd->bytes__written)'
return fdd->total_bytes_written+fdd->bytes_written; else
return -EINTR; /* Ничего не было записано,
системный вызов был прерван, требуется повторная попытка */
fdd->total_bytes_written += fdd->bytes_written; fdd~>buf += fdd->bytes_written; count -= fdd->bytes_written;
} while (count > 0); return total bytes written;
static struct tq_struct floppy_tq;
/* Обработчик прерывания */ static void fdd interrupt(int irq)
truct fdcl struct *fdd = &fdd_table [fdd_irq [irq] ];
Af (fdd->ha!,;;ier!= NULL) {
void (Chandler)(int irq, fdd_struct * fdd);
f]_0ppy_tq. routine = (void *)(void *) fdd->handler;
floppy tq.parameter = (void *)fdd;
fdd->handler=NULL;
queue_task(sfloppy_tq, &tq_immediate); } else
{ /* He наше прерывание? */
}
}
Видно, что теперь наш драйвер представляет собой последовательность функций, вызываемых обработчиком прерываний. Обратите внимание, что если мы торопимся, очередную функцию можно вызывать и непосредственно в обработчике, а не создавать для нее fork-процесс посредством queue_task. Но самое главное, на что нам следует обратить внимание — последовательность этих функций не задана жестко: каждая из функций сама определяет, какую операцию вызывать следующей. В том числе, она может решить, что следующая операция может состоять в вызове той же самой функции. В примере 10.3 мы используем эту возможность для простой обработки ошибок: повтора операции, которая не получилась.
Для того чтобы понять, что же у нас получилось, какие возможности нам открывает такая архитектура и как ими пользоваться, нам следует сделать экскурс в одну из важных областей теории программирования.
Введение в конечные автоматы
Конечный автомат (в современной англоязычной литературе используется также более выразительное, на взгляд автора, обозначение, не имеющее хорошего русского эквивалента — state machine, дословно переводимое как машина состояний) представляет собой устройство, имеющее внутреннюю память (переменные состояния), а также набор входов и выходов. Объем внутренней памяти у конечных автоматов, как следует из названия, конечен. Автоматы с неограниченным объемом внутренней памяти называются бесконечными автоматами, нереализуемы и используются только в теоретических Построениях (Минский 1971].
Однако некоторые разновидности теоретически бесконечных автоматов — например, стековые — могут быть реализованы в форме автоматов с практически неограниченной памятью — например, достаточно глубоким стеком — и находят практическое применение, например при синтаксическом анализе языков со вложенными структурами [Кормен/Лейзерсон/Ривест 2000].
Работа автомата состоит в том, что он анализирует состояния своих входов, и, в зависимости от значений входов и своего внутреннего состояния, изменяет значения выходов и внутреннее состояние. Правила, в со ответствии с которыми происходит изменение, описываются таблицей или диаграммой переходов. Диаграмма переходов представляет собой граф, вершины которого соответствуют допустимым состояниям внутренних переменных автомата, а ребра — допустимым переходам между ними. Переходы между вершинами направленные: наличие перехода из А в В не означает, что существует переход из В в А. Наличие перехода в обоих направлениях символизируется двумя ребрами, соединяющими одну пару вершин. Такой граф называется ориентированным [Кормен/Лейзерсон/Ривест 2000]. Таблица переходов может рассматриваться как матричное представление диаграммы переходов.
Блок-схемы (рис. 10.5) являются обычным способом визуализации графов переходов и используются для описания алгоритмов с 60-х годов. Любой алгоритм, исполняющийся на фон-неймановском компьютере с конечным объемом памяти (а также любой физически исполнимый алгоритм), может быть описан как конечный автомат и изображен в виде блок-схемы.
У конечных автоматов с ограниченным числом допустимых значений входов, граф переходов всегда конечен, хотя и может содержать циклы (замкнутые пути) и контуры (совокупности различных путей, приводящих к одной и той же вершине). Понятно, что для автомата с графом, содержащим циклы, невозможно гарантировать финитности — завершения работы за конечное время. Как известно, задача доказательства финитности алгоритма, хотя и решена во многих частных случаях, в общем случае алгоритмически неразрешима [Минский 1971].
Применительно к драйверам внешних устройств, циклический граф может соответствовать повторным попыткам выполнения операции после ее не-'удачи. Понятно, что на практике количество таких попыток следует ограничивать. Самый простой способ такого ограничения — введение счетчика попыток. Формально после этого состояния с различными значениями счетчика превращаются в наборы состояний, а граф переходов становится ациклическим (рис. 10.6), но для достаточно большого количества повторений опять-таки необозримым, поэтому на практике часто используют сокращенную блок-схему, в которой состояния с разными значениями счетчика цикла изображаются как одно состояние.

Рис. 10.5. Блок-схема драйвера
Анализ полной или сокращенной блок-схемы алгоритма методами теории графов, хотя и не может однозначно дать ответ на вопрос о его финитности, может оказать значительную помощь в оценке алгоритма, в том числе и в поиске "узких" с точки зрения финитности мест. В [Кнут 2000) приводятся примеры такого анализа для некоторых простых алгоритмов.
Алгоритмы основной массы реально применяемых программ (особенно использующих переменные состояния большого объема) имеют совершенно Необозримые блок-схемы. Отчасти это обходится декомпозицией программного комплекса на отдельные модули с более обозримой функциональностью и алгоритмом, но все-таки далеко не для всех алгоритмов представление в виде конечного автомата естественно.
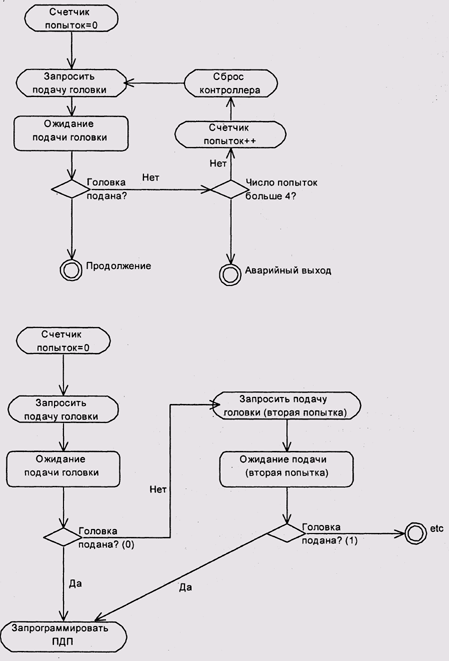
Рис. 10.6. Развертывание циклов в графе состояния
С другой стороны, ряд даже довольно сложных алгоритмов естественным образом описывается автоматами с небольшим числом состояний, которые могут быть закодированы одной скалярной переменной состояния или стеком таких переменных. Такие автоматы находят применение в самых разнообразных задачах: лексическом и синтаксическом разборе контекстно-свободных и многих типах контекстно-связанных языков [Кормен/ Пейзерсон/Ривест 2000 1, реализации сетевых протоколов, задачах корпоративного документооборота (Керн/Линд 2000] и др. В частности, легко понять, что обсуждаемый нами алгоритм драйвера относится именно к этой категории алгоритмов.
Два основных подхода к реализации конечных автоматов — это развернутые (unrolled) автоматы и автоматы общего вида. Примером развернутого конечного автомата является код основной нити примера 10.2. Понятно, что развертыванию поддаются только автоматы с весьма специфической — линейной или древовидной — структурой графа состояний, и если в процессе уточнения требований мы выясним, что структура автомата должна быт более сложной, нам придется полностью реорганизовать код.
Автомат общего вида выглядит несколько сложнее, но, научившись распознавать его конструкцию, легко разрабатывать такие программы по задан ной блок-схеме и, наоборот, восстанавливать граф состояний по коду программы. Главным преимуществом грамотно реализованного конечного автомата является легкость модификации: если граф переходов измените нам надо будет изменить код только тех узлов, которые затронуты изменением.
Примеры реализации конечных автоматов такого типа на процедурном языке программирования приводятся во многих учебниках программированию например [Грогоно 1982). Чаще всего реализация состоит из цикла, условием выхода из которого является достижение автоматом финального состояния, и размещенного в теле цикла оператора вычислимого перехода с переменной состояния в качестве селектора. Конечный автомат, похожий на эту классическую реализацию, приведен в примере 10.4.
Пример 10.4. Конечный автомат драйвера контроллера IDE/ATA для OS/2
VOID NEAR StartSM(NPACB npACB)
}
/* ------------------------------------------------ */
* Проверка счетчика использований АСВ*/
/* -------------------- */
/* Автомат реентрантен для каждого АСВ / *
/* ------------------------------------------------ */
DISABLE
npACB->UseCount++;
iff npACB->UseCount == 1)
{
do
{
ENABLE
do
{
npACB->Flags &= ~ACBF_WAITSTATE;
switch (npACB->State) {
case ACBS__START:
StartState(npACB);
break;
case ACBS_INTERRUPT:
InterruptState(npACB);
break;
case ACBS_DONE:
DoneState(npACB);
break;
case ACBS_SUSPEND:
SuspendState(npACB);
break;
case ACBS_RETRY:
RetryState(npACB);
break;
case ACBS_RESETCHECK:
ResetCheck(npACB);
break/case ACBS_ERROR:
ErrorState(npACB);
break;
while (!(npACB->Flags & ACBF WAITSTATE));
DISABLE
I
while (— npACB->UseCount);
Конечный автомат драйвера OS/2
Несмотря на простоту, пример 10.4 нуждается в комментариях. Параме! функции startSM — АСВ (Adapter Control Block — блок управления адаптере! так в OS/2 называется блок переменных состояния устройства). АСЗ содержит указатель на очередь запросов IORB (Input/Output Request Block — блок запроса на ввод/вывод) и скалярную переменную state, которая указывает, в како состоянии сейчас находится обработка первого запроса в очереди. По коду этого состояния определяется, какую функцию следует вызвать. В телах этк функций, в зависимости от результата операции, происходит установка следующего значения переменной состояния и, возможно, флага ACB_WAITSTATE.
Функция startSM (Start State Machine) вызывается как из функции обработн запросов, так и из обработчика прерывания. Поэтому перед входом в собс венно автомат и после выхода из него стоит код, использующий поле nрАСЕ >UseCount как флаговую переменную, чтобы не допустить одновременного входа в автомат из обоих возможных нитей исполнения. Обратите также внимание, что макросами ENABLE и DISABLE (запрет и разрешение прерываний окружена работа с флаговой переменной, но не сам автомат.
(В качестве упражнения читателю предлагается понять, как же обеспечиваете вызов функции interruptstate, если во время прерывания основной поте драйвера все еще находился в теле автомата.
Полный текст драйвера IDE/ATA для OS/2 включен в стандартную поставку DDK (Driver Development Kit— набор инструментов [для] разработчика драйверов), который может быть найден на сайте [www.ibm.com OS/2 DDK].
Построенный нами в примере 10.3 код внешне совсем не похож на приме 10.4, но, в действительности, также представляет собой конечный автомат в качестве переменной состояния используется переменная fdd->handier, в качестве дискретных значений этой переменной — указатели на функции обрабатывающие конкретные состояния.
Архитектура драйвера
Драйвер, таким образом, состоит из основной нити, обработчика прерывания, и, возможно, одной или нескольких высокоприоритетных нитей, создаваемых обработчиком. Все эти нити совместно (и, как правило, гарантируя взаимоисключение) исполняют более или менее сложный конечный автомат, состояния которого соответствуют этапам выполнения очередного запроса к устройству.
Как правило, первое состояние автомата обрабатывается основной нитью драйвера, а последующие — обработчиком прерываний. В финальном состоянии автомата мы сообщаем процессу, породившему запрос, что запрос отработан. В зависимости от протокола взаимодействия этого процесса основной нитью драйвера, такое сообщение может осуществляться как fork-процессом, так и пробуждением основной нити.
Драйвер IDE/ATA для Linux
В примере 10.5 приведена основная функция обработки запроса и функция об работки прерывания, используемая при записи нескольких секторов. Обе эти функции вызываются драйвером контроллера IDE/ATA, который представляет собой диспетчер запросов к подключенным к контроллеру устройствам.
Структура *hwgroup представляет собой блок переменных состояний контроллера устройства. Эта структура содержит также указатель на текущий запрос к устройству. Информации, содержащейся в этих структурах, достаточно, чтобы очередная функция конечного автомата драйвера узнала все, необходимое ей для выполнения очередного этапа запроса. В данном случае конечный автомат весьма прост и состоит из многократного вызова функции ide_multiwrite, копирующей в контроллер очередной блок данных. Условием завершения автомата служат ошибка контроллера либо завершение запроса. Функции ide__dma_read, ide_dma_write, ide_read и ide_write, исполняемые машиной состояний при обработке других запросов не приводятся.
Пример 10.5. Фрагменты драйвера диска IDE/ATA ОС Linux 2.2, перевод комментариев автора
/*
* ide_multwrite() передает приводу блок из не более, чем mcount
* секторов как часть многосекторной операции записи. *
* Возвращает 0 при успехе. *
* Обратите внимание, что мы можем быть вызваны из двух контекстов -
* контекста do_rw и контекста IRQ. IRQ (Interrupt Request,
* запрос прерывания)может произойти в любой
* момент после того, как мы выведем полное количество секторов,
* поэтому мы должны обновлять состояние _до_ того, как мы выведем
* последнюю часть данных! */
int ide_multwrite (ide_drive__t *drive, unsigned int mcount) {
ide_hwgroup_t *hwgroup= HWGROUP(drive);
'struct request *rq = &hwgroup->wrq;
do {
char *buffer;
int nsect = rq->current_nr_sectors;
if (nsect > mcount)
nsect = mcount; mcount -= nsect; buffer = rq->buffer;
rq->sector += nsect; rq->buffer += nsect «9; rq->nr_sectors -= nsect; rq->current nr sectors -= nsect;
/* Переходим ли мы к следующему bh после этого? */ if (!rq->current_nr_sectors) {
struct buffer_head *bh = rq->bh->b_reqnext;
/* Завершиться, если у нас кончились запросы V if (!bh) {
mcount = 0; } else (
rq->bh = bh;
rq->current_nr_sectors = bh->b_size» 9;
rq->buffer = bh->b_data;
/*
* Теперь мы все настроили, чтобы прерывание
* снова вызвало нас после последней передачи. */
idedisk_output_data(drive, buffer, nsect«7); } while (mcount);
return 0;
/*
* multwrite_intr() — обработчик прерывания многосекторной записи */
static ide_startstop_t multwrite_intr (ide_drive_t *drive) {
byte stat;
ir.t i;
ide_hwgroup_t *hwgroup = HWGROUP(drive);
struct request *rq = &hwgroup->wrq;
if (OK_STAT(stat=GET_STAT(),DRIVE_READY,drive->bad_wstat)) { if (stat & DRQ_STAT) { /*
* Привод требует данных. Помним что rq -
* копия запроса. */
if (rq->nr_sectors) {
if (ide_multwrite(drive, drive->mult_count))
return ide_stopped; «
ide_set__handler (drive, &multwrite_intr, WAIT_CMD, NULL); return ide_started; }
} else { /*
* Если копирование всех блоков завершилось,
* мы можем завершить исходный запрос. */
if (! rq->nr__sectors) { /* all done? */ rq = hwgroup->rq; for (i = rq->nr_sectors; i > 0;){ i -= rq->current_nr_sectors; ide_end_request(1, hwgroup); } return ide stopped;
return ide_stopped; /* Оригинальный код делал это здесь (?) */
! ьнешних
[return ide_errcr(drive, "multwrite_intr", stat);
/*
i do rw disk() передает команды READ и WRITE приводу,
* используя LBA если поддерживается, или CHS если нет, для адресации
* секторов. Функция do_rw_disk также передает специальные запросы.
*/
static ide_startstop__t do_rw_disk (ide_drive_t *drive, struct request *rq, unsigned long block)
{ if (IDE_CONTROL_REG)
OUT_BYTE (drive->ctl, IDE_CONTROL_REG); OUT_BYTE (rq->nr_sectors, IDE_NSECTOR_REG); if (drive->select.b.lba) (
OUT_BYTE (block, IDE_SECTOR_REG);
OUT_BYTE (block»=8, IDE_LCYL_REG);
OUT_BYTE (block»=8, I DE_HC YL_REG);
OUT_BYTE(((block»8) &0x0f) I drive->select. all, IDE_SELECT_REG); } else f
unsigned int sect, head, cyl, track;
track = block / drive->sect;
sect = block % drive->sect + 1;
ODT^BYTE (sect, IDE__SECTOR_REG);
head = track % drive->head;
cyl = track / drive->head;
OUT__BYTE (cyl, IDE_LCYL_REG);
OUT_BYTE (cyl»8, IDE_HCYL_REG);
OUT_BYTE (head I drive->select.all, IDE_SELECT_REG);
if (rq->cmd == READ) { ^#ifdef CONFIG_BLK_DEV_IDEDMA
if (drive- >using_dma &&! (HWIF (drive) ->dmaproc (ide_dma_read, drive))
return ide_started; #endif /* CONFIG_BLK_DEV_IDEDMA */
ide_set_handler (drive, iread_intr, WAIT_CMD, NULL); OUT_BYTE(drive->mult_count? WIN_MULTREAD: WIN_READ, IDE COMMAND REG);
''—-^
return ide started;
if (rq->cmd == WRITE) (
ide_startstop_t startstop; lifdef CONFIG_BLK_DEV_IDEDMA
if (drive->using_drna &&!(HWIF(drive)->dmaproc(ide dma^write,
drive)))
return ide_started; lendif /* CONFIG_BLK_DEV_IDEDMA */
OUT_BYTE(drive->mult_COUnt? WIN_MULTWRITE: WIN_WRITE,
IDE_COMMAND_REG); if (ide_wait_stat(Sstartstop, drive, DATA_READY, drive->bad_wstat,
WAIT^DRQ)) (printk(KERN_ERR "%s: no DRQ after issuing %s\n", drive->na:r.e,
drive->mult_count? "MULTWRITE": "WRITE"); return startstop;
if (!drive->unmask)
__cli(); /* только локальное ЦПУ */
if (drive->mult_count) (
ide_hwgroup_t *hwgroup = HWGROUP(drive);
/*
* Эта часть выглядит некрасиво, потому что мы ДОЛЖНЫ установить
* обработчик перёд выводом первого блока данных.
* Если мы обнаруживаем ошибку (испорченный список буферов)
* в ide_multiwrite(),
* нам необходимо удалить обработчик и таймер перед возвратом.
* К счастью, это НИКОГДА не происходит (правильно?).
* Кажется, кроме случаев, когда мы получаем ошибку... */
hwgroup->wrq = *rq; /* scratchpad */
ide_set_handler (drive, &multwrite_intr, WAIT__CMD, NULL);
if (ide_multwrite(drive, drive->mult_count)) {
unsigned long flags;
spin_lock_irqsave (&io__request_lock, flags);
hwgroup->handler = NULL;
del_timer(&hwgroup->timer);
spin unlock_irqrestore(&io_request_lock, flags);
return ide_stopped;
Глава 10. Драйверы внешних
} else {
ide_set_handler (drive, &write_intr, WAIT_CMD, NULL); idedisk_output_data(drive, rq->buffer, SECTOR_WORDS);
}
i return ide_started;
)
i'-printk (KERN_ERR "%s: bad command: %d\n", drive->name, rq->cmd)
ide_end_request(0, HWGROUP(drive)); return ide_stopped;
Запросы к драйверу
Обработку запроса можно разделить на три фазы: предобработку, исполнение запроса и постобработку. Пользовательская программа запрашивает операцию, исполняя соответствующий системный вызов. В ОС семейства Unix это может быть, например, системный вызов write (int file, void * buffer, size_t size).
Предобработка выполняется модулем системы, который, как правило, исполняется в нити процесса, сформировавшей запрос, но имеет привилегии ядра. Фаза предобработки включает в себя.
- Проверку допустимости параметров. Пользователь должен иметь право выполнять запрошенную операцию над данным устройством, адрес буфера должен быть допустимым адресом пользовательского адресного пространства и т. д.
- Возможно, копирование или отображение данных из пользовательского адресного пространства в системное.
- Возможно, преобразование выводимых данных. Например, в системах семейства Unix при выводе на терминал система может заменять символ горизонтальной табуляции на соответствующее число пробелов (если терминал не поддерживает горизонтальную табуляцию) и преобразовывать символ перевода строки. Дело в том, что внутри системы в качестве разделителя строк используется символ новой строки '\n' (ASCII NL), а различные модели терминалов и принтеров могут использовать также '\r' (ASCII RET, возврат каретки) или последовательности '\r"\n' или '\n"\r'.
- Возможно, обращение к процедурам драйвера. Эти процедуры могут блокировать код и данные драйвера в физической памяти и выделять буферы для ПДП. Эти операции реализуются нереентерабельными сервисами ядра и не всегда могут быть выполнены драйвером во время обработки запроса.
- Передача запроса драйверу. Некоторые системы реализуют передачу запроса как простой вызов соответствующей функции драйвера, но чаще используются более сложные асинхронные механизмы, которые будет обсуждаться далее.
Выполнив запрос, драйвер активизирует программу постобработки, котопя анализирует результат операции, предпринимает те или иные действия по восстановлению в случае неудачи, копирует или отображает полученные данные в пользовательское адресное пространство и оповещает пользовательский процесс о завершении запроса.
Некоторые системы на этой фазе также ыыпроизводят преобразование введенных данных. В качестве примера можно вновь привести системы семейства Unix, которые при вводе с терминала выполняют трансляцию символа перевода строки и ряд других операций редактирования, например, стирание последнего введенного символа по запросу пользователя. Разбиение потока терминальных данных на строки в этих системах также происходит на фазе постобработки.
В той или иной форме эти три фазы обработки запроса ввода-вывода присутствуют во всех многопоточных и даже многих однопоточных системах.
Синхронный ввод-вывод
Самым простым механизмом вызова функций драйвера был бы косвенный вызов соответствующих процедур, составляющих тело драйвера, подобно тому, как это делается в MS DOS и ряде других однозадачных систем.
В системах семейства Unix драйвер последовательного устройства исполняется в рамках той нити, которая сформировала запрос, хотя и с привилегиями ядра. Ожидая реакции устройства, драйвер переводит процесс в состояние ожидания доступными ему примитивами работы с планировщиком. В примере 10.1 это interruptibie_sieep_on. В качестве параметра этой функции передается блок переменных состояния устройства, и в этом блоке сохраняется ссылка на контекст блокируемой нити.
Доступные прикладным программам функции драйвера исполняются в пользовательском контексте — в том смысле, что, хотя драйвер и работает в адресном пространстве ядра, но при его работе определено и пользовательское адресное пространство, поэтому он может пользоваться примитивами
Обмена данными С НИМ (в примере 10.1 это memcpy_from_fs).
Обработчик прерывания наоборот работает в контексте прерывания, когда пользовательское адресное пространство не определено. Поэтому, чтобы при обслуживании прерывания можно было получить доступ к пользовательским данным, основная нить драйвера вынуждена копировать их в буфер в адресном пространстве ядра.
Синхронная модель драйвера очень проста в реализации, но имеет существенный недостаток, приведенный в примере 10.1, — драйвер нереентерабелен. Обращение двух нитей к одному устройству приведет к непредсказуемым последствиям (впрочем, для практических целей достаточно того, что среди возможных последствий числится нарушение целостности данных и последующая паника регистров на экране). Предсказуемость последствий обеспечивается включением в контекст устройства семафора, установкой этого семафора при входе в функцию foo_write и снятием его при выходе. Семафор имеет очередь ожидающих его процессов, и, таким образом, реентрантно (т. е. во время обработки предыдущего аналогичного запроса) приходящие запросы будут устанавливаться в очередь.
Альтернативный подход к организации ввода-вывода состоит в том, чтобы возложить работу по формированию очереди запросов не на драйвер, а на функцию предобработки запроса. При этом первый запрос к драйверу, какое-то время бывшему неактивным, может по-прежнему осуществляться в нити процесса, сформировавшего этот запрос, но все последующие запросы извлекаются из очереди fork-процессом драйвера при завершении предыдущего запроса. Такой подход называется асинхронным.
Примечание
Здесь возникает интересный вопрос: если запрос обрабатывается асинхронно, то обязана ли пользовательская программа ожидать окончания операции? Вообще говоря, не обязана, но этот вопрос подробнее будет обсуждаться в разд. Асинхронная модель ввода-вывода с точки зрения приложений.
Асинхронный ввод-вывод
В системах семейства Unix драйверы блочных устройств обязательно асинхронные. Кроме того, в современных версиях системы асинхронными драйверами являются драйверы потоковых устройств. Многие другие ОС, в том числе однозадачные (такие, как DEC RT-11), используют исключительно асинхронные драйверы.
Драйвер, использующий асинхронную архитектуру, обычно предоставляет вместо отдельных функций read, write, ioctl и т. д. единую функцию, которая в системах семейства Unix называется strategy, а мы будем называть стратегической функцией (рис. 10.7).
Запросы к драйверу в VMS
В операционной системе VAX/VMS драйвер получает запросы на ввод-вывод из очереди запросов. Элемент очереди называется IRP (lnput[Output] Request Packet — пакет запроса ввода-вывода). Обработав первый запрос в очереди, драйвер начинает обработку следующего. Операции над очередью запросов выполняются специальными командами процессора VAX и являются атомарными. Если очередь пуста, основная нить драйвера завершается. При появлении новых запросов система вновь запустит ее.
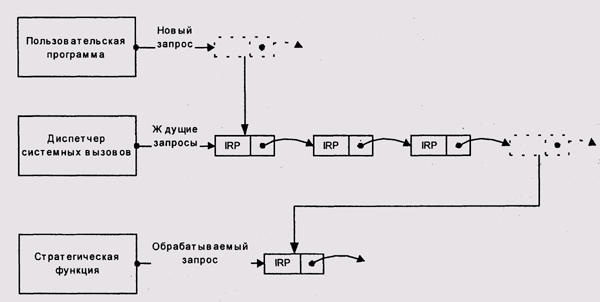
Рис. 10.7. Стратегическая функция и очередь запросов
IRP содержит:
- код операции (чтение, запись или код SPFUN— специальная функция, подобная ioctl в системах семейства Unix);
- адрес блока данных, которые должны быть записаны, или буфера, куда данные необходимо поместить;
- информацию, используемую при постобработке, в частности, идентификатор процесса, запросившего операцию.
В зависимости от кода операции драйвер запускает соответствующую подпрограмму. В VAX/VMS адрес подпрограммы выбирается из таблицы FDT (Function Definition Table). Подпрограмма инициирует операцию и приостанавливает процесс, давая системе возможность исполнить другие активные процессы. Затем, когда происходит прерывание, его обработчик инициирует fork-процесс, исполняющий следующие этапы этого запроса. Завершив один запрос, fork-процесс сообщает об этом процедурам постобработки (разбудив соответствующий процесс) и, если в очереди еще что-то осталось, начинает исполнение следующего запроса.
Дата публикования: 2014-11-18; Прочитано: 528 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
