 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 4.2. Пример последовательности запросов памяти 2 страница
|
|
/* Если некоторые фрагменты этого блока свободны, включить этот фрагмент в список фрагментов после первого свободного фрагмента этого блока. */
next = (struct list *) ptr;
next->next = prev->next;
next->prev = prev;
prev->next = next;
if (next->next!= NULL) next->next->prev = next;
++_heapinfо[block].busy.info.frag.nfree;
else
/* В этом блоке нет свободных фрагментов, поэтому включить этот фрагмент в список фрагментов и анонсировать, что это первый свободный фрагмент в этом блоке. */
prev = (struct list *) ptr;
_heapinfo [block].busy. info. frag. nfree = 1;
_heapinfo [block].busy. info. frag. first = (unsigned long int)
((unsigned long int) ((char *) ptr - (char *) NULL) % BLOCKSIZE» type); prev->next = _fraghead[type].next; prev->prev = &_fraghead[type]; prev->prev->next = prev; if (prev->next!= NULL)
prev->next->prev = prev;
break;
/* Вернуть память в кучу. */ void
_ libc_free (ptr) _ ptr_t ptr; {
register struct alignlist *1;
if (ptr == NULL) return;
for (1 = _aligned_blocks; 1!= NULL; 1 = l->next) if (l->aligned == ptr)
{
l->aligned = NULL;
/* Пометить элемент списка как свободный. */
ptr = l->exact;
break;
if (_ free_hook!= NULL) (* _ free_hook) (ptr);
else
_free_internal (ptr);
#include <gnu-stabs. h>
#ifdef elf_alias
elf_alias (free, cfree);
#endif
К основным недостаткам этого алгоритма относится невозможность оценки времени поиска подходящего блока, что делает его неприемлемым для задач реального времени. Для этих задач требуется алгоритм, который способен за фиксированное (желательно, небольшое) время либо найти подходящий блок памяти, либо дать обоснованный ответ о том, что подходящего блока не существует.
Проще всего решить эту задачу, если нам требуются блоки нескольких фиксированных размеров (рис. 4.10). Мы объединяем блоки каждого размера в свой список. Если в списке блоков требуемого размера ничего нет, мы смотрим в список блоков большего размера. Если там что-то есть, мы разрезаем этот блок на части, одну отдаем запрашивающей программе, а вторую... Правда, если размеры требуемых блоков не кратны друг другу, что мы будем делать с остатком?
Для решения этой проблемы нам необходимо ввести какое-либо ограничение на размеры выделяемых блоков. Например, можно потребовать, чтобы эти размеры равнялись числам Фибоначчи (последовательность целых чисел, в которой Fi+1 = Fi + Fi-1. В этом случае, если нам нужно Fi байт, а в наличии есть только блок размера Fi+1, мы легко можем получить два блока — один требуемого размера, а другой — Fi-1, который тоже не пропадет. Да, любое ограничение на размер приведет к внутренней фрагментации, но так ли велика эта плата за гарантированное время поиска блока?
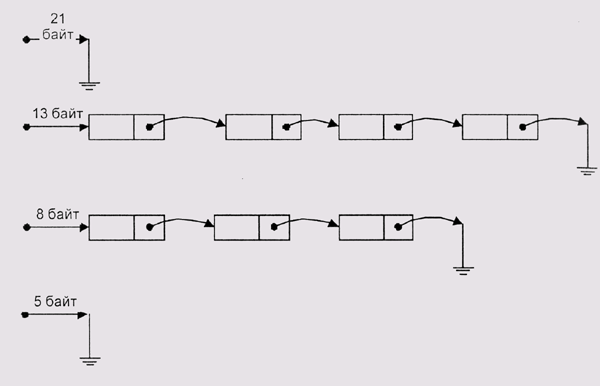
Рис. 4.10. Выделение блоков фиксированных размеров
На практике, числа Фибоначчи не используются. Одной из причин, по-видимому, является относительная сложность вычисления такого Fi, которое не меньше требуемого размера блока. Другая причина — сложность объединения свободных блоков со смежными адресами в блок большего размера. Зато широкое применение нашел алгоритм, который ограничивает последовательные размеры блоков более простой зависимостью — степенями числа 2: 512 байт, 1 Кбайт, 2 Кбайт и т. д. Такая стратегия называется алгоритмом близнецов (рис. 4.11).
Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Адрес блока-близнеца получается простым инвертированием соответствующего бита в адресе нашего блока. Нужно только проверить, свободен ли этот близнец. Если он свободен, то мы объединяем братьев в блок вдвое большего размера, и т. д. Даже в наихудшем случае время поиска не превышает О (log(Smax)-log(Smin)), где Smax и Smin обозначают, соответственно, максимальный и минимальный размеры используемых блоков. Это делает алгоритм близнецов трудно заменимым для ситуаций, в которых необходимо гарантированное время реакции — например, для
задач реального времени. Часто этот алгоритм или его варианты используются для выделения памяти внутри ядра ОС.
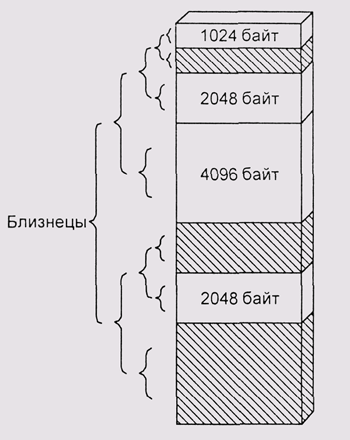
Рис. 4.11. Алгоритм близнецов
Существуют и более сложные варианты применения описанного выше подхода. Например, пул свободной памяти Novell Netware состоит из 4 очередей с шагом 16 байт (для блоков размерами 16, 32, 48, 64 байта), 3 очередей с шагом 64 байта (для блоков размерами 128, 192, 256 байт) и пятнадцати очередей с шагом 256 байт (от 512 байт до 4 Кбайт). При запросах большего размера выделяется целиком страница. Любопытно, что возможности работы в режиме реального времени, присущие этой изощренной стратегии, в Netware практически не используются.
Например, если драйвер сетевого интерфейса при получении очередного пакета данных обнаруживает, что у него нет свободных буферов для его приема, он не пытается выделить новый буфер стандартным алгоритмом. Вместо этого, драйвер просто игнорирует пришедшие данные, лишь увеличивая счетчик потерянных пакетов. Отдельный системный процесс следит за состоянием этого счетчика и только при превышении им некоторого порога за некоторый интервал времени выделяет драйверу новый буфер.
Подобный подход к пользовательским данным может показаться циничным, Но надо вспомнить, что при передаче данных по сети возможны и другие Причины потери пакетов, например порча данных из-за электромагнитных Помех. Поэтому все сетевые протоколы высокого уровня предусматривают средства пересылки пакетов в случае их потери, какими бы причинами эта потеря ни была вызвана. С другой стороны, в системах реального времени игнорирование данных, которые мы все равно не в состоянии принять и обработать, — довольно часто используемая, хотя и не всегда приемлемая стратегия.
Сборка мусора
| Что-то с памятью моей стало Р. Рождественский |
Явное освобождение динамически выделенной памяти применяется во многих системах программирования и потому привычно для большинства программистов, но оно имеет серьезный недостаток: если программист по какой-то причине не освобождает выделенные блоки, память будет теряться. Эта ошибка, называемая утечкой памяти (memory leak), особенно неприятна в программах, которые длительное время работают без перезапуска — подсистемах ядра ОС, постоянно запущенных сервисах или серверных приложениях. Дополнительная неприятность состоит в том, что медленные утечки могут привести к заметным потерям памяти лишь при многодневной или даже многомесячной непрерывной эксплуатации системы, поэтому их сложно обнаружить при тестировании.
Некоторые системы программирования используют специальный метод освобождения динамической памяти, называемый сборкой мусора (garbage collection). Этот метод состоит в том, что ненужные блоки памяти не освобождаются явным образом. Вместо этого используется некоторый более или менее изощренный алгоритм, следящий за тем, какие блоки еще нужны, а какие — уже нет.
Самый простой метод отличать используемые блоки от ненужных — считать, что блок, на который есть ссылка, нужен, а блок, на который ни одной ссылки не осталось, — не нужен. Для этого к каждому блоку присоединяют дескриптор, в котором подсчитывают количество ссылок на него. Каждая передача указателя на этот блок приводит к увеличению счетчика ссылок на 1, а каждое уничтожение объекта, содержавшего указатель, — к уменьшению.
Впрочем, при наивной реализации такого подхода возникает специфическая проблема. Если у нас есть циклический список, на который нет ни одной ссылки извне, то все объекты в нем будут считаться используемыми, хотя они и являются мусором. Если мы по тем или иным причинам уверены, что кольца не возникают, метод подсчета ссылок вполне приемлем; если же мы используем графы произвольного вида, необходим более умный алгоритм.
Наиболее распространенной альтернативой подсчету ссылок является периодический просмотр всех ссылок, которые мы считаем "существующими' (чтобы под этим ни подразумевалось) (рис. 4.12). Если некоторые из указуемых объектов сами по себе могут содержать ссылки, мы вынуждены осуществлять просмотр рекурсивно. Проведя эту рекурсию до конца, мы можем быть уверены, что, то и только то, что мы просмотрели, является нужными данными, и с чистой совестью можем объявить все остальное мусором. Эта стратегия решает проблему кольцевых списков, но требует остановки всей остальной деятельности, которая может сопровождаться созданием или уничтожением ссылок.
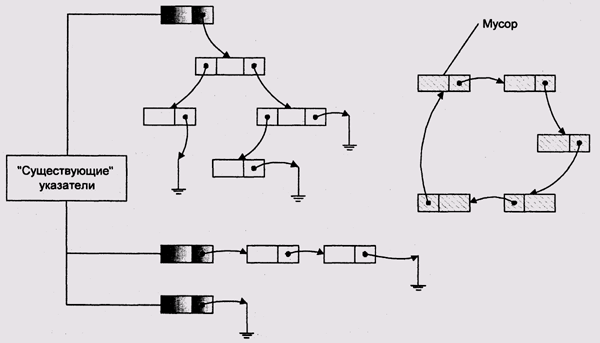
Рис. 4.12. Сборка мусора просмотром ссылок
Все методы сборки мусора, так или иначе, сводятся к поддержанию базы данных о том, какие объекты на кого ссылаются. Использование такой техники возможно практически только в интерпретируемых языках, таких, как Java, Smalltalk или Lisp, где с каждой операцией можно ассоциировать неограниченно большое количество действий.
Открытая память (продолжение)
Описанные выше алгоритмы распределения памяти используются не операционной системой, а библиотечными функциями, присоединенными к программе. Однако ОС, которая реализует одновременную загрузку (но не обязательно одновременное исполнение: MS DOS — типичный пример такой системы) нескольких задач, также должна использовать тот или иной алгоритм размещения памяти. Отчасти такие алгоритмы могут быть похожи на работу функции malloc. Однако режим работы ОС может вносить существенные упрощения в алгоритм.
Перемещать образ загруженного процесса по памяти невозможно: даже если его код был позиционно-независим и не подвергался перенастройке, сегмент данных может содержать (и почти наверняка содержит) указатели, которые при перемещении необходимо перенастроить. Поэтому при выгрузке задач из памяти перед нами в полный рост встает проблема внешней фрагментации (рис. 4.13).
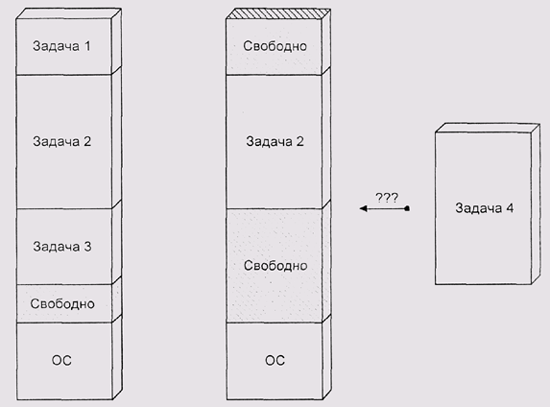
Рис. 4.13. Фрагментация при загрузке и выгрузке задач
Управление памятью в OS/360
В этой связи нельзя не упомянуть о поучительной истории, связанной с управлением памятью в системах линии IBM System 360. В этих машинах не было аппаратных средств управления памятью, и все программы разделяли общее виртуальное адресное пространство, совпадающее с физическим. Адресные ссылки в программе задавались 12-битовым смещением относительно базового регистра. В качестве базового регистра мог использоваться, в принципе, любой из 16 32-битовых регистров общего назначения. Предполагалось, что пользовательские программы не модифицируют базовый регистр, поэтому можно загружать их с различных адресов, просто перенастраивая значение этого регистра. Таким образом, была реализована одновременная загрузка многих прО" грамм в многозадачной системе OS/360.
Однако после загрузки программу уже нельзя было перемещать по памяти: например, при вызове подпрограммы адрес возврата сохраняется в виде абсолютного 24-битовог.о адреса (в System 360 под адрес отводилось 32-разрядное слово, но использовались только 24 младших бита адреса. В System 370 адрес стал 31-разрядным) и при возврате базовый регистр не применяется. Аналогично, базовый регистр не используется при ссылках на блоки параметров и сами параметры подпрограмм языка FORTRAN (в этом языке все параметры передаются по ссылке), при работе с указателями в PL/I и т. д. Перемещение программы, даже с перенастройкой базового регистра, нарушило бы все такие ссылки.
Разработчики фирмы IBM вскоре осознали пользу перемещения программ после их загрузки и попытались как-то решить эту проблему. Очень любопытный документ "Preparing to Rollin-Rollout Guideline" (Руководство по подготовке [программы] к вкатыванию и выкатыванию; к сожалению, автору не удалось найти полного текста этого документа) описывает действия, которые программа должна была бы предпринять после перемещения. Фактически программа должна была найти в своем сегменте данных все абсолютные адреса и сама перенастроить их.
Естественно, никто из разработчиков компиляторов и прикладного программного обеспечения не собирался следовать этому руководству. В результате, проблема перемещения программ в OS/360 не была решена вплоть до появления машин System 370 со страничным или странично-сегментным диспетчером памяти и ОС MVS.
В данном случае проблема фрагментации особенно остра, так как типичный образ процесса занимает значительную часть всего доступного ОЗУ. Если при выделении небольших блоков мы еще можем рассчитывать на "закон больших чисел" и прочие статистические закономерности, то самый простой сценарий загрузки трех процессов различного размера может привести нас к неразрешимой ситуации (см. рис. 4.13).
Разделы памяти (см. разд. Разделы памяти) отчасти позволяют решить проблему внешней фрагментации, устанавливая, что процесс должен либо использовать раздел Целиком, либо не использовать его вовсе. Как и все ограничения на размер единицы выделения памяти, это решение загоняет проблему внутрь, переводя внешнюю фрагментацию во внутреннюю. Поэтому некоторые системы предлагают другие способы наложения ограничения на порядок загрузки и выгрузки задач.
Управление памятью в MS DOS
Так, например, процедура управления памятью MS DOS рассчитана на случай, когда программы выгружаются из памяти только в порядке, обратном тому, в каком они туда загружались (на практике, они могут выгружаться и в другом порядке, но это явно запрещено в документации и часто приводит к проблемам). Это позволяет свести управление памятью к стековой дисциплине.
Каждой программе в MS DOS отводится блок памяти. С каждым таким блоком ассоциирован дескриптор, называемый МСВ — Memory Control Block (рис. 4.14). Этот дескриптор содержит размер блока, идентификатор программы, которой принадлежит этот блок, и признак того, является ли данный блок
последним в цепочке. Нужно отметить, что программе всегда принадлежит несколько блоков, но это уже несущественные детали. Другая малосущественная деталь та, что размер сегментов и их адреса отсчитываются в параграфах размером 16 байт. Знакомые с архитектурой процессора 8086 должны вспомнить, что адрес МСВ в этом случае будет состоять только из сегментной части с нулевым смещением.
После запуска corn-файл получает сегмент размером 64Кбайт, а ехе — всю доступную память. Обычно ехе-модули сразу после запуска освобождают ненужную им память и устанавливают brklevel на конец своего сегмента, а потом увеличивают brklevel и наращивают сегмент по мере необходимости.
Естественно, что наращивать сегмент можно только за счет следующего за ним в цепочке МСВ, и MS DOS разрешит делать это только в случае, если этот сегмент не принадлежит никакой программе.
При запуске программы DOS берет последний сегмент в цепочке и загружает туда программу, если этот сегмент достаточно велик. Если он недостаточно велик, DOS говорит: "Недостаточно памяти" и отказывается загружать программу. При завершении программы DOS освобождает все блоки, принадлежавшие программе. При этом соседние блоки объединяются. Пока программы, действительно, завершаются в порядке, обратном тому, в котором они запускались, — все вполне нормально. Другое дело, что в реальной жизни возможны отклонения от этой схемы. Например, предполагается, что TSR-программы (Terminate, but Stay Resident - Завершиться и остаться резидентно (в памяти)) никогда не пытаются по-настоящему завершиться и выгрузиться. Тем не менее, любой уважающий себя хакер считает своим долгом сделать резидентную программу выгружаемой. У некоторых хакеров она в результате выбрасывает при выгрузке все резиденты, которые заняли память после нее. Другой пример — отладчики обычно загружают программу в обход обычной DOS-овской функции LOAD & EXECUTE, а при завершении отлаживаемой программы сами освобождают занимаемую ею память.
Автор в свое время занимался прохождением некоторой программы под управлением отладчика. Честно говоря, речь шла о взломе некоторой игрушки... Эта программа производила какую-то инициализацию, а потом вызывала функцию DOS LOAD & EXECUTE. Я об этом не знал и, естественно, попал внутрь новой программы, которую и должен был взламывать.
После нескольких нажатий комбинаций клавиш <CTRL>+<Break> я наконец-то вернулся в отладчик, но при каком-то очень странном состоянии программы. Покопавшись в программе с помощью отладчика в течение некоторого времени и убедившись, что она не хочет приходить в нормальное состояние, я вышел из отладчика и увидел следующую картину: системе доступно около 100 Кбайт в то время, как сумма длин свободных блоков памяти более 300 Кбайт, а размер наибольшего свободного блока около 200 Кбайт. Отладчик выходя, освободил свою память и память отлаживаемой программы, но не освободил память, выделенную новому загруженному модулю. В результате посредине памяти ос-тался никому не нужный блок изрядного размера, помеченный как используемый (рис. 4.15). Самым обидным было то, что DOS не пыталась загрузить ни одну программу в память под этим блоком, хотя там было гораздо больше места, чем над ним.

Рис. 4.14. Управление памятью в MS DOS
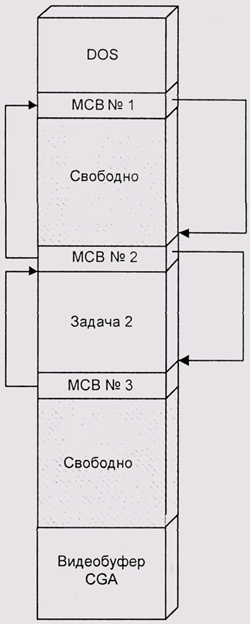
Рис. 4.15. Нарушения стекового порядка загрузки и выгрузки в MS DOS
В системах с открытой памятью невозможны эффективные средства разделения доступа. Любая программная проверка прав доступа может быть легко обойдена прямым вызовом "защищаемых" модулей ядра. Даже криптографические средства не обеспечивают достаточно эффективной защиты, потому что можно "посадить" в память троянскую программу, которая будет анализировать код программы шифрования и считывать значение ключа.
В заключение можно сказать, что основными проблемами многопроцессных систем без диспетчера памяти являются следующие.
- Проблема выделения дополнительной памяти задаче, которая загружалась непоследней.
- Проблема освобождения памяти после завершения задачи — точнее, возникающая при этом фрагментация свободной памяти.
- Низкая надежность. Ошибка в одной из программ может привести к порче кода или данных других программ или самой системы.
- Проблемы безопасности.
В системах с динамической сборкой первые две проблемы не так остры, потому что память выделяется и освобождается небольшими кусочками, по блоку на каждый объектный модуль, и код программы обычно не занимает непрерывного пространства. Соответственно такие системы часто разрешают и данным программы занимать несмежные области памяти.
Такой подход используется многими системами с открытой памятью — AmigaDOS, Oberon, системами программирования для транспьютера и т. д. Проблема фрагментации при этом не снимается полностью, однако для создания катастрофической фрагментации не достаточно двух загрузок задач и одной выгрузки, а требуется довольно длительная работа, сопровождающаяся интенсивным выделением и освобождением памяти.
В системе MacOS был предложен достаточно оригинальный метод борьбы с фрагментацией, заслуживающий отдельного обсуждения
Управление памятью в MacOS и Win16
В этих системах предполагается, что пользовательские программы не сохраняют указателей на динамически выделенные блоки памяти. Вместо этого каждый такой блок идентифицируется целочисленным дескриптором или "ручкой" (handle) (рис. 4.16). Когда программа непосредственно обращается к данным в блоке, она выполняет системный вызов GiobaiLock (запереть). Этот вызов возвращает текущий адрес блока. Пока программа не исполнит вызов GiobaiUniock (отпереть), система не пытается изменить адрес блока. Если же блок не заперт, система считает себя вправе передвигать его по памяти или даже сбрасывать на диск (рис. 4.17).
"Ручки" представляют собой попытку создать программный аналог аппаратных диспетчеров памяти. Они позволяют решить проблему фрагментации и даже организовать некое подобие виртуальной памяти. Можно рассматривать их как средство организации оверлейных данных — поочередного отображения разных блоков данных на одни и те же адреса. Однако за это приходится платить очень дорогой ценой.
Использование "ручек" сильно усложняет программирование вообще и в особенности перенос ПО из систем, использующих линейное адресное пространство. Все указатели на динамические структуры данных в программе нужно заменить на "ручки", а каждое обращение к таким структурам необходимо окружить вызовами GlobalLock/GlobalUnlock.
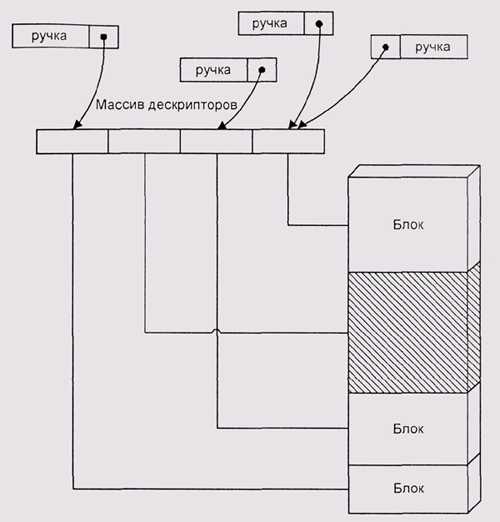
Рис. 4.16. Управление памятью с помощью "ручек"
Вызовы GlobalLock/GlobalUnlock:
- сами по себе увеличивают объем кода и время исполнения;
- мешают компиляторам выполнять оптимизацию, прежде всего не позволяют оптимально использовать регистры процессора, потому что далеко не все регистры сохраняются при вызовах;
- требуют разрыва конвейера команд и перезагрузки командного кэша; в современных суперскалярных процессорах это может приводить к падению производительности во много раз.
Попытки уменьшить число блокировок требуют определенных интеллектуальных усилий. Фактически, к обычному циклу разработки ПО: проектирование, выбор алгоритма, написание кода и его отладка — добавляются еще 16 фазы: микрооптимизация использования "ручек" и отладка оптимизированного кода. Последняя фаза оказывается, пожалуй, самой сложной и ответственной.
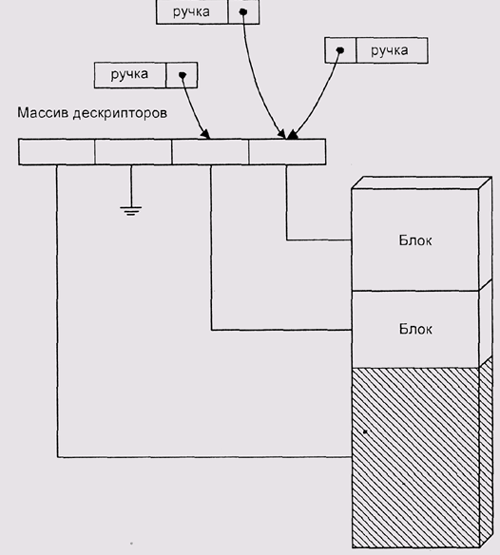
Рис. 4.17. Дефрагментация при управлении памятью с помощью "ручек"
Наиболее опасной ошибкой, возникающей на фазе микрооптимизации, является вынос указателя на динамическую структуру за пределы скобок GiobaiLock/ciobaiUniock. Эту ошибку очень сложно обнаружить при тестировании, так как она проявляется, только если система пыталась передвигать блоки в промежутках между обращениями. Иными словами, ошибка может проявлять или не проявлять себя в зависимости от набора приложений, исполняющихся в системе, и от характера деятельности этих приложений. В результате мы получаем то, чего больше всего боятся эксплуатационщики — систему, которая работает иногда. При переходе от Windows 3.x к Windows 95 наработка на отказ — даже при исполнении той же самой смеси приложений — резко возросла, так что система из работающей иногда превратилась в работающую как правило. По-видимому, это означает, что большая часть ошибок в приложениях Winl6 действительно относилась к ошибкам работы с "ручками".
Не случайно фирма Microsoft полностью отказалась от управления памятью с помошью "ручек" в следующей версии MS Windows — Windows 95, в которой реализована почти полноценная виртуатьная память.
Мас OS версии 10, построенная на ядре BSD Unix, также имеет страничную виртуальную память и никогда не перемешает блоки памяти, адресуемые "ручками".
Системы с базовой виртуальной адресацией
Как уже говорилось, в системах с открытой памятью возникают большие сложности при организации многозадачной работы. Самым простым способом разрешения этих проблем оказалось предоставление каждому процессу своего виртуального адресного пространства. Простейшим методом организации различных адресных пространств является так называемая базовая адресация. По-видимому, это наиболее ранний способ виртуальной адресации (рис. 4.18).
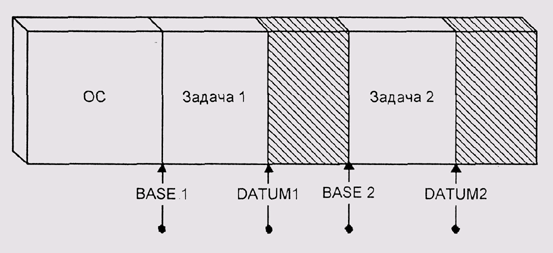
Рис. 4.18. Виртуальная память на основе базовой адресации
Вы можете заметить, что термин базовая адресация уже занят — мы называли таким образом адресацию по схеме reg[offset]. Метод, о котором сейчас идет речь, состоит в формировании адреса по той же схеме. Отличие состоит в том, что регистр, относительно которого происходит адресация, не доступен прикладной программе. Кроме того, его значение прибавляется Ко всем адресам, в том числе к "абсолютным" адресным ссылкам или переменным типа указатель. По существу, такая адресация является способом организации виртуального адресного пространства.
правило, машины, использующие базовую адресацию, имеют два региcтра. Один из регистров задает базу для адресов, второй устанавливает верхний предел. В системе IСL900/Одренок эти регистры называются соответственно BASE и DATUM. Если адрес выходит за границу, установленную значением DATUM, возникает исключительная ситуация (exception) ошибочной адресации. Как правило, это приводит к тому, что система принудительно завершает работу программы.
При помощи этих двух регистров мы сразу решаем две важные проблемы.
Во-первых, мы можем изолировать процессы друг от друга — ошибки в программе одного процесса не приводят к разрушению или повреждению образов других процессов или самой системы. Благодаря этому мы можем обеспечить защиту системы не только от ошибочных программ, но и от злонамеренных действий пользователей, направленных на разрушение системы или доступ к чужим данным.
Во-вторых, мы получаем возможность передвигать образы процессов по физической памяти так, что программа каждого из них не замечает перемещения. За счет этого мы решаем проблему фрагментации памяти и даем процессам возможность наращивать свое адресное пространство. Действительно, в системе с открытой памятью процесс может добавлять себе память только до тех пор, пока не доберется до начала образа следующего процесса. После этого мы должны либо говорить о том, что памяти нет, либо мириться с тем, что процесс может занимать несмежные области физического адресного пространства. Второе решение резко усложняет управление памятью как со стороны системы, так и со стороны процесса, и часто оказывается неприемлемым (подробнее связанные с этим проблемы обсуждаются в разд. Открытая память (продолжение)). В случае же базовой адресации мы можем просто сдвинуть мешающий нам образ вверх по физическим адресам (рис. 4.19).
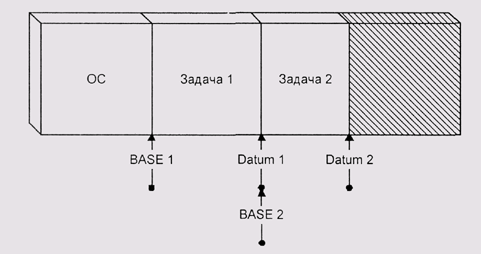
Рис. 4.19. Дефрагментация при использовании базовой адресации
Часто ОС, работающие на таких архитектурах, умеют сбрасывать на диск образы тех процессов, которые долго не получают управления. Это самая простая из форм своппинга (swapping — обмен) (русскоязычный термин "страничный обмен" довольно широко распространен, но в данном случае его использование было бы неверным, потому что обмену подвергаются не страницы, а целиком задачи).
решив перечисленные выше проблемы, мы создаем другие, довольно неожиданные. Мы оговорили, что базовый регистр недоступен прикладным задачам. Но какой-то задаче он должен быть доступен! Каким же образом процессор узнает, исполняет ли он системную или прикладную задачу, и не сможет ли злонамеренная прикладная программа его убедить в том, что является системной?
Другая проблема состоит в том, что, если мы хотим предоставить прикладным программам возможность вызывать систему и передавать ей параметры, мы должны обеспечить процессы (как системные, так и прикладные) теми или иными механизмами доступа к адресным пространствам друг друга.
На самом деле, эти две проблемы тесно взаимосвязаны — например, если мы предоставим прикладной программе свободный доступ к системному адресному пространству, нам придется распрощаться с любыми надеждами на защиту от злонамеренных действий пользователей. Раз проблемы взаимосвязаны, то и решать их следует в комплексе.
Стандартное решение этого комплекса проблем состоит в следующем. Мы снабжаем процессор флагом, который указывает, исполняется системный или пользовательский процесс. Код пользовательского процесса не может манипулировать этим флагом, однако ему доступна специальная команда. В различных архитектурах эти специальные команды имеют разные мнемонические обозначения, далее мы будем называть эту команду SYSCALL. SYSCALL одновременно переключает флаг в положение "системный" и передает управление на определенный адрес в системном адресном пространстве. Процедура, находящаяся по этому адресу, называется диспетчером системных вызовов (рис. 4.20).
Возврат из системного вызова осуществляется другой специальной командой, назовем ее SYSRET. Эта команда передает управление на указанный адрес в указанном адресном пространстве и одновременно переводит флаг в состояние "пользователь". Необходимость выполнять эти две операции одной командой очевидна: если мы сначала сбросим флаг, мы потеряем возможность переключать адресные пространства, а если мы сначала передадим управление, никто не может нам гарантировать, что пользовательский код добровольно выйдет из системного режима.
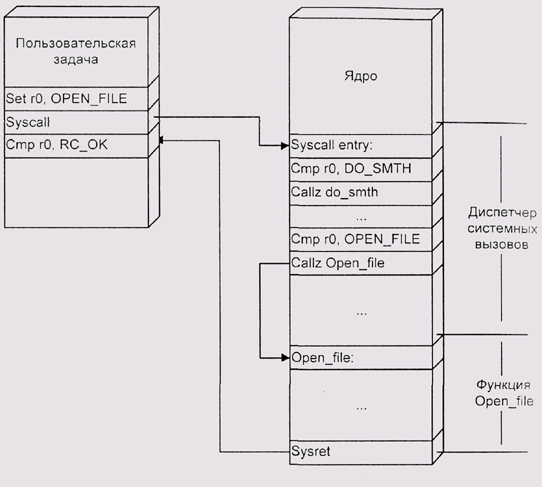
Рис. 4.20. Диспетчер системных вызовов
Протокол общения прикладной программы с системой состоит в следующем: программа помещает параметры вызова в оговоренное место — обычно в регистры общего назначения или в стек — и исполняет SYSCALL. Одним из параметров передается и код системного вызова. Диспетчер вызовов анализирует допустимость параметров и передает управление соответствующей процедуре ядра, которая и выполняет требуемую операцию (или не выполняет, если у пользователя не хватает полномочий). Затем процедура помещает в оговоренное место (чаще всего опять-таки в регистры или в пользовательский стек) возвращаемые значения и передает управление диспетчеру, или вызывает SYSRET самостоятельно.
Сложность возникает, когда ядру при исполнении вызова требуется доступ к пользовательскому адресному пространству. В простейшем случае, когда все параметры (как входные, так и выходные) размещаются в регистрах и преД' ставляют собой скалярные значения, проблемы нет, но большинство системных вызовов, особенно запросы обмена данными с внешними устройствами, в эту схему не укладываются.
В системах с базовой адресацией эту проблему обычно решают просто: "системном" режиме базовый и ограничительный регистры не используют-вообще, и ядро имеет полный доступ ко всей физической памяти, в том и к адресным пространствам всех пользовательских задач (рис. 4.21). решение приводит к тому, что, хотя система и защищена от ошибок пользовательских программах, пользовательские процессы оказываются совершенно не защищены от системы, а ядро — не защищено от самого себя. Ошибка в любом из системных модулей приводит к полной остановке работы.
Дата публикования: 2014-11-18; Прочитано: 446 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
