 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 4.2. Пример последовательности запросов памяти 4 страница
|
|
- При использовании страничных и двухслойных сегментно-странпчных диспетчеров памяти мы можем отображать в чужие адресные пространства только объекты, выровненные на границу страницы и имеющие размер, кратный размеру страницы.
- Мы не можем избавиться от супервизора. В данном случае это должен быть модуль, ответственный за формирование мандата и размещение отображенного модуля в адресном пространстве задачи, получающей мандат.
Первая проблема является чисто технической — она приводит лишь к тому, что мы можем построить такую систему только на основе сегментного УУП, в котором размер сегмента задается с точностью до байта пли хотя бы до слова. Сегментированная память страдает от внешней фрагментации, но иногда такую цену стоит заплатить за повышение надежности.
Функции модуля, управляющего выдачей мандатов, оказываются слишком сложны для аппаратной и даже микропрограммной реализации. Этот модуль должен выполнять следующие функции.
- Убедиться в том, что передаваемый объект целиком входит в один сегмент исходного адресного пространства.
- Если объект состоит из нескольких сегментов, разумным образом обработать такую ситуацию. Для программной реализации может оказаться желательным умение объединить все элементы в один сегмент. Для аппаратной или микропрограммной реализации достаточно хотя бы уметь сгенерировать соответствующее исключение.
- Сформировать содержимое дескриптора сегмента для объекта и записать в него соответствующие права. Эта операция требует заполнения 4—5 битовых полей, и запись ее алгоритма на псевдокоде займет около десятка операторов. По сложности алгоритма одна только эта операция сравнима с наиболее сложными командами современных коммерческих CISC-процессоров, таких как VAX или транспьютер.
- Отметить в общесистемной базе данных, что на соответствующую область физической памяти существует две ссылки. Это нужно для того, чтобы процессы дефрагментации и управления виртуатьной памятью правильно обрабатывали перемещения сегмента по памяти и его перенос на диск, отмечая изменения физического адреса или признака присутствия во всех дескрипторах, ссылающихся на данный сегмент. Далее эта проблема будет обсуждаться подробнее.
- Найти свободную запись в таблице дескрипторов сегментов задачи-получателя. Эта операция аналогична строковым командам CISC-процессоров, которые считаются сложными командами.
- Разумным образом обработать ситуацию отсутствия такой записи.
- Записать сформированный дескриптор в таблицу.
Но еше больше проблем создает операция уничтожения мандата. Легко показать необходимость уничтожения мандата той же задачей, которая его создала.
Например, представим себе, что пользовательская программа передала какому-либо модулю мандат на запись в динамически выделенный буфер. Допустим также, что этот модуль вместо уничтожения мандата после передачи данных сохранил его — ведь наша система предполагает, что ни одному из модулей нельзя полностью доверять! Если мы вынуждены принимать в расчет такую возможность, то не можем ни повторно использовать такой буфер для других целей, ни даже возвратить память, занятую им системе, потому что не пользующийся нашим доверием модуль по-прежнему может сохранять право записи в него.
В свете этого возможность для задачи, выдавшей мандат, в одностороннем порядке прекращать его действие представляется жизненно необходимой. Отказ от этой возможности или ее ограничение приводит к тому, что задача. выдающая мандат, вынуждена доверять тем задачам, которым мандат был передан, т. е. можно не городить огород и вернуться к обычной двухуровневой или многоуровневой системе колец защиты.
Для прекращения действия мандата мы должны отыскать в нашей общесистемной базе данных все ссылки на интересующий нас объект и объявить не недействительными. При этом мы должны принять во внимание возможности многократной передачи мандата и повторной выдачи мандатов на отдельные части объекта. Аналогичную задачу нужно решать при перемещении объектов в памяти во время дефрагментации, сбросе на диск и поиске жертвы (см. разд. Поиск жертвы) для такого сброса.
Структура этой базы данных представляется нам совершенно непонятной, потому что она должна отвечать следующим требованиям.
- Обеспечивать быстрый поиск всех селекторов сегментов, ссылающихся на заданный байт или слово памяти.
- Обеспечивать быстрое и простое добавление новых селекторов, ссылающихся на произвольные части существующих сегментов.
- Занимать не больше места, чем память, отведенная под сегменты.
Последнее требование непосредственно не следует из концепции взаимно недоверяющих подсистем, но диктуется простым здравым смыслом. Если мы и смиримся с двух- или более кратным увеличением потребностей в памяти, оправдывая его повышением надежности, нельзя забывать, что даже простой просмотр многомегабайтовых таблиц не может быть быстрым.
В системах, использующих страничные диспетчеры памяти, решить эти Проблемы намного проще, потому что минимальным квантом разделения Памяти является страница размером несколько килобайтов. Благодаря этому Мы смело можем связать с каждым разделяемым квантом несколько десятков байтов данных, обеспечивающих выполнение первых двух требований.
Если же минимальным квантом является байт или слово памяти, наши структуры данных окажутся во много раз больше распределяемой памяти.
Автор оставляет читателю возможность попробовать самостоятельно разработать соответствующую структуру данных. В качестве более сложного упражнения можно рекомендовать записать алгоритм работы с такой базой данных на псевдокоде, учитывая, что мы хотели бы иметь возможность реализовать этот алгоритм аппаратно или, по крайней мере, микропрограммно.
Дополнительным стимулом для читателя, решившего взяться за эту задачу, может служить тот факт, что разработчики фирмы Intel не смогли найти удовлетворительного решения.
Архитектура 1432
Автору известен только один процессор, пригодный для полноценной реализации взаимно недоверяющих подсистем: JAPX432 фирмы Intel. Вместо создания системной базы данных о множественных ссылках на объекты, специалисты фирмы Intel усложнили диспетчер памяти и соответственно алгоритм разрешения виртуальных адресов.
Виртуальный адрес в 1432 состоит из селектора объекта и смещения в этом объекте. Селектор объекта ссылается на таблицу доступа текущего домена. Домен представляет собой программный модуль вместе со всеми его статическими и динамическими данными (рис. 5.12). По идее разработчиков, домен соответствует замкнутому модулю языков высокого уровня, например пакету (package) языка Ada.
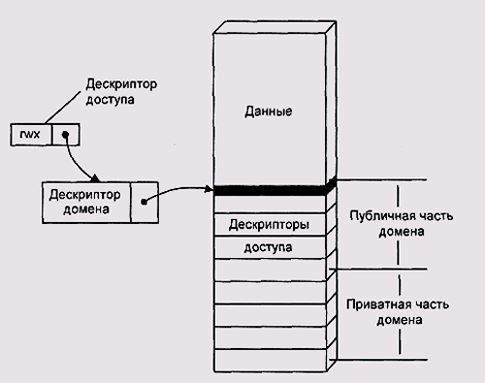
Рис. 5.12. Домен 1432
Элемент таблицы доступа состоит из прав доступа к объекту и указателя на таблицу объектов процесса. Элемент таблицы объектов может содержать непосредственную ссылку на область данных объекта — такой объект аналогичен сегменту в обычных диспетчерах памяти, однако обращение к нему происходит через два уровня косвенности. Иными словами, вместо
segment_table[seg].phys_address + offset
мы имеем
object_table[access_table[selector]].phys_address + offset.
Дополнительный уровень косвенности позволяет нам упростить отслеживание множественных ссылок на объект: вместо использования структуры данных, которую мы так и не сумели изобрести, мы можем следить только за дескриптором исходного объекта, поскольку все ссылки на объект через дескрипторы доступа вынуждены в итоге проходить через дескриптор объекта.
Более сложными сущностями являются уточнения — объекты, ссылающиеся на отдельные элементы других объектов (рис. 5.13). Вместо физического адреса и длины дескриптор такого объекта содержит селектор целевого сегмента, смещение уточнения в целевом объекте и его длину. При ссылке на уточнение диспетчер памяти сначала проверяет допустимость смещения, а затем повторяет полную процедуру разрешения адреса и проверки прав доступа для целевого объекта.
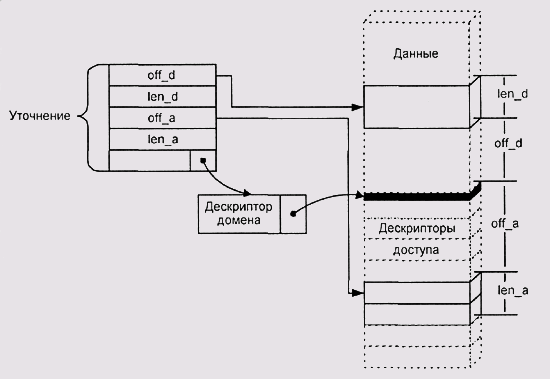
Рис. 5.13. Уточнение
Целевой объект также может оказаться уточнением, и диспетчер памяти будет повторять процедуру до тех пор, пока не дойдет до объекта, ссылающегося на физическую память. Более подробно этот механизм описан в работе [Органик 1987].
Уточнения позволяют решить проблему выдачи мандатов— мандат реализуется как уточнение исходного объекта (например, сегмента данных модуля в котором выделен буфер), а программе-получателю передается даже не само уточнение, а лишь дескриптор доступа к нему. Для прекращения действия мандата достаточно удалить дескриптор уточнения. После этого все переданные другим модулям дескрипторы доступа будут указывать в пустоту, т. е. станут недействительными. Задачи же перемещения в памяти и сброса объектов на диск решаются путем изменения физического адреса или признака п(в|рутствия целевого объекта; для этого не требуется прослеживать цепочку уточнений.
Однако накладные расходы, связанные с реализацией этого сложного механизма, оказались очень большими. Процессор i432 остался экспериментальным и не получил практического применения. Трудно сказать, какой из факторов оказался важнее: катастрофически низкая производительность системы (автору не удалось найти официальных заявлений фирмы Intel по этому поводу, но народная мудрость утверждает, что экспериментальные образцы i432 с тактовой частотой 20 МГц исполняли около 20 000 операций в секунду) или просто неспособность фирмы Intel довести чрезмерно сложный кристалл до массового промышленного производства. Так или иначе, едва ли не единственной практической пользой, извлеченной из этого амбициозного проекта, оказалось тестирование системы автоматизированного проектирования, использованной впоследствии при разработке процессора 80386 и сопутствующих микросхем.
После завершения проекта I432 других попыток полностью реализовать взаимно недоверяющие подсистемы не делалось — изготовители коммерческих систем, по-видимому, сочли эту идею непродуктивной, а исследовательским организациям проекты такого масштаба просто не по плечу
Сегменты, страницы и системные вызовы (продолжение)
Аппаратные схемы тонкого разделения доступа к адресному пространству не имели большого успеха не только из-за высоких накладных расходов, но и из-за того, что решали не совсем ту проблему, которая реально важна. Для повышения надежности системы в целом важно не обнаружение ошибок и даже не их локализация с точностью до модуля сама по себе, а возможность восстановления после их возникновения. Самые распространенные фатальные ошибки в программах — это ошибки работы с указателями и выход индекса за границы массива (в наш сетевой век ошибки второго типа более известны как "срыв буфера"). Эти ошибки не только часто встречаются, но и очень опасны, потому что восстановление после них практически невозможно. Ошибки работы с указателями еще можно попытаться устранить, искоренив само понятие указателя. Примерно этой логикой продиктован запрет на формирование указателей в машинах Burroughs, именно из этих соображений в Java и некоторых других интерпретируемых языках указателей вообще нет. Однако искоренить понятие индексируемого массива уже не так легко. д ошибки индексации присуши всем компилируемым языкам, начиная с Fortran и Algol 60. Вставка проверок на границы индекса перед каждой выборкой элемента массива создает накладные расходы, но тоже не решает проблемы: ошибка все равно обнаруживается не в момент совершения (в тот момент, когда мы вычислили неверный индекс), а позже, когда мы попытались его использовать. В момент индексации обычно уже невозможно понять, какой же элемент массива имелся в виду. Программе остается только нарисовать на экране какое-нибудь прощальное сообщение вроде "Unhandled Java Exception", и мирно завершить свой земной путь. Понятно, что реакция пользователя на подобное сообщение будет ничуть не более адекватной, чем на хрестоматийное "Ваша программа выполнила недопустимую операцию — General Protection Fault" (впрочем, кто знает, может быть, такая реакция и является самой адекватной?). Прогресс в решении этой проблемы лежит уже в сфере совершенствования технологий программирования, и вряд ли может быть обеспечен усложнением диспетчеров памяти. Уровень же надежности, обеспечиваемый современными ОС общего назначения с разделением памяти, по-видимому, оптимален в том смысле, что улучшения в сфере защиты памяти могут быть достигнуты лишь ценой значительных накладных расходов без принципиального повышения наработки на отказ.
Разделяемые библиотеки
Ранее мы упоминали разделяемые библиотеки как одно из преимуществ страничных и сегментных диспетчеров памяти перед базовыми и банковыми. При базовой адресации образ каждого процесса должен занимать непрерывные области как в физическом, так и в логическом адресном пространстве. В этих условиях реализовать разделяемую библиотеку невозможно. Но и при использовании страничной адресации не все так просто.
Использование разделяемых библиотек и/или DLL (в данном случае разница между ними не принципиальна) предполагает ту или иную форму сборки в момент загрузки: исполняемый модуль имеет неразрешенные адресные ссылки и имена библиотек, которые ему нужны. При загрузке эти библиотеки подгружаются и ссылки разрешаются. Проблема здесь в том, что при Подгрузке библиотеки ее нужно переместить, перенастроив абсолютные адресные ссылки в ее коде и данных (см. главу 3). Если в разных процессах библиотека будет настроена на разные адреса, она уже не будет разделяемой (рис. 5.14)! Если разделяемые библиотеки могут иметь неразрешенные ссылки на другие библиотеки, проблема только усугубляется — к перемещаемым ссылкам добавляются еще и внешние.
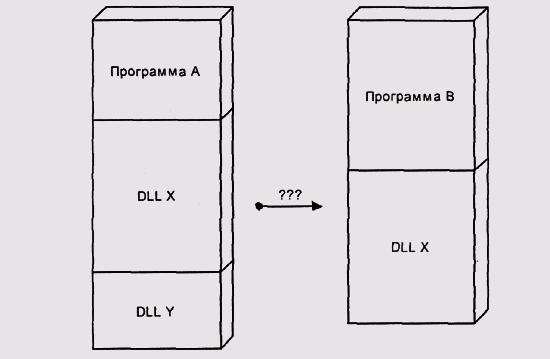
Рис. 5.14. Конфликтующие адреса отображения DLL
В старых системах семейства Unix, использовавших абсолютные загружаемые модули формата a.out, разделяемые библиотеки также поставлялись в формате абсолютных модулей, настроенных на фиксированные адреса. Каждая библиотека была настроена на СБОЙ адрес. Поставщик новых библиотек должен был согласовать этот адрес с разработчиками системы. Это было весьма непрактично, поэтому разделяемых библиотек было очень мало (особенно если не считать те, которые входили в поставку ОС).
Более приемлемое решение этой проблемы реализовано в OS/2 2.x и Win32 (обе эти архитектуры являются развитием систем с единым адресным пространством). Идея состоит в том, чтобы выделить область адресов под загрузку DLL и отображать эту область в адресные пространства всех процессов. Таким образом, все DLL, загруженные в системе, видны всем (рис. 5.15).
Очевидным недостатком такого решения (как, впрочем, и предыдущего) является неэффективное использование адресного пространства: при cколь-нибудь сложной смеси загруженных программ большей части процессов большинство библиотек будет просто не нужны. В те времена, когда эта архитектура разрабатывалась, это еще не казалось серьезной трудностью, но сейчас, когда многим приложениям становится тесно в 4 Гбайт и серверы с таким объемом оперативной памяти уже не редкость, это действительно может стать проблемой.
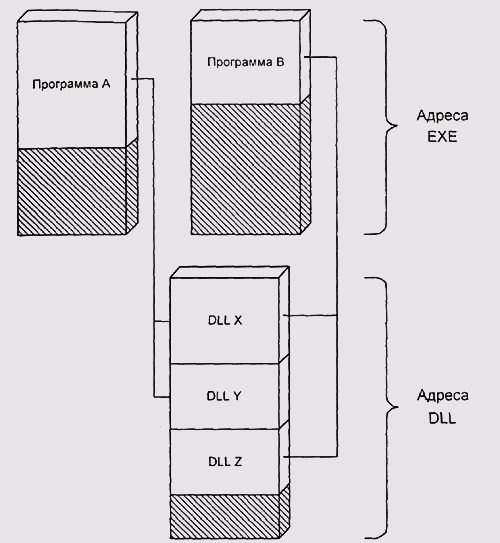
Рис. 5.15. Загрузка DLL в OS/2 и Win32
Менее очевидный, но более серьезный недостаток состоит в том, что эта архитектура не позволяет двум приложениям одновременно использовать Две разные, но одноименные DLL — например, две разные версии стандартной библиотеки языка С. Поэтому либо мы вынуждены требовать от всех разделяемых библиотек абсолютной (bug-fbr-bug) совместимости версий, либо честно признать, что далеко не каждая смесь прикладных программ будет работоспособна. Первый вариант нереалистичен, второй же создает значительные неудобства при эксплуатации, особенно если система интерактивная и многопользовательская.
Лишенное обоих недостатков решение предлагают современные системы семейства Unix, использующие загружаемые модули формата ELF. Впрочем, для реализации этого решения пришлось, ни много, ни мало, переделать компилятор и научить его генерировать позиционно-независимый код (см. разд. Позиционно-независимый код).
Разделяемые библиотеки формата ELF
Исполняемые модули формата ELF бывают двух типов: статические — полностью самодостаточные, не использующие разделяемых объектов, и динамические — содержащие ссылки на разделяемые объекты и неразрешенные символы. И статические, и динамические модули являются абсолютными. При создании образа процесса система начинает с того, что отображает старчески собранный исполняемый объект в адресное пространство. Статический модуль не нуждается ни в какой дополнительной настройке и может начать исполнение сразу после этого.
Для динамического же загрузочного модуля система загружает так называемый интерпретатор, или редактор связей времени исполнения (run-time linker), no умолчанию ld.so.1. Он исполняется в контексте процесса и осуществляет подгрузку разделяемых объектов и связывание их с кодом основного модуля и друге другом.
При подгрузке разделяемый объект также отображается в адресное пространство формируемого процесса. Отображается он не на какой-либо фиксированный адрес, а как получится, с одним лишь ограничением: сегменты объекта будут выровнены на границу страницы. Не гарантируется даже, что адреса сегментов будут одинаковы при последовательных запусках одной и той же программы.
Документ [HOWTO Library] без обиняков утверждает, что в разделяемых объектах можно использовать только код, компилированный с ключом -? рте. Документ [docs.sun.com 816-0559-10] менее категоричен:
"Если разделяемый объект строится из кода, который не является позиционно-независимым, текстовый сегмент скорее всего потребует большое количество перемещений во время исполнения. Хотя редактор связей и способен их обработать, возникающие вследствие этого накладные расходы могут вести к серьезному снижению производительности".
Как уже говорилось в разд. 3.5, используемый в разделяемых объектах код не является истинно позиционно-независимым: он содержит перемещаемые и даже настраиваемые адресные ссылки, такие, как статически инициализованные указатели и ссылки на процедуры других модулей. Но все эти ссылки размещены в сегменте данных. Используемые непосредственно в коде ссылки собраны в две таблицы, GOT (Global Offset Table, Глобальная таблица смещений) и PL Т (Procedure Linkage Table, Таблица процедурного связывания) (рис. 5.16). Каждый разделяемый модуль имеет свои собственные таблицы. Порожденный компилятором код определяет адреса этих таблиц, зная их смещение в разделяемом объекте относительно точки входа функции (см. примеры 3.7 и 5.1)

Рис. 5.16. Global Offset Table (Глобальная таблица смещений) и Procedure Linkage Table (Таблица процедурного связывания)
Пример 5.1. Типичный пролог функции, предназначенной для использования в разделяемом объекте
• text
•align 2,0x90
•globl _strerror
_strerror:
pushl %ebp; Стандартный пролог функции
movl %esp,%ebp
pushl %ebx
call L4
popl %ebx; Загрузка текущего адреса в регистр ЕВХ
acldl $_GLOBAL_OFFSET_TABLE_+ [. -L4 ], %ebx
Сегмент кода отображается с разделением его между всеми процессами, использующими объект (конечно, при условии, что он был компилирован с правильными ключами и не содержит перемещаемых адресов).
Напротив, сегмент данных и таблицы GOT и PLT создаются в каждом образе заново и, если это необходимо, адресные ссылки в них подвергаются перемещению. По мере разрешения внешних ссылок, интерпретатор заполняет р|т объекта ссылками на символы, определенные в других объектах (подобный стиль работы с внешними ссылками широко распространен в байт-кодах интерпретируемых языков — см. разд. Сборка в момент звгрузки).
Сегмент данных разделяемого объекта, таким образом, соответствует тому что в OS/2 и Win32 называется приватным сегментом данных DLL: каждая задача, использующая объект, имеет свою копию этого сегмента. Аналога глобальному сегменту данных разделяемые библиотеки ELF не имеют — et%; это необходимо, код библиотеки может создать собственный сегмент разделяемой памяти, но в нем невозможно иметь статически инициализованные данные и для него никто не гарантирует отображения на одни и те же адреса разных процессов, поэтому в нем невозможно хранить указатели.
По умолчанию, интерпретатор осуществляет отложенное редактирование связей: если сегмент данных он полностью настраивает до передачи управления пользовательскому коду, то записи в PLT изначально указывают на специальную процедуру редактора связей. Будучи вызвана, эта процедура по стеку вызова или другими средствами определяет, какую же процедуру пытались вызвать на самом деле, и настраивает ее запись в PLT (рис. 5.17). В случае, когда большинство программ не вызывает большую часть функций, как это часто и бывает при использовании разделяемых библиотек, это дает определенный выигрыш в производительности.
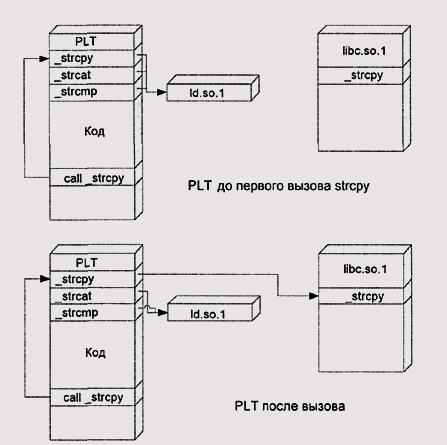
Рис. 5.17. Редактор связей времени исполнения
Пример 5.2. Структура PLT для процессора SPARC (цитируется по [docs.sun.com 816-0559-10])
Первые две (специальные) записи PLT до загрузки программы:
.PLT0:
un imp
unimp
unimp.PLTl:
unimp
unimp
unimp
Обычные записи PLT до загрузки программы:
.PLT101:
sethi (.-.PLT0),%gl
ba,a.PLTO
пор.PLT102:
sethi (.-.PLT0),%gl
ba,a.PLTO
nop
...
Специальные записи PLT после загрузки программы:
.PLT0:
save %sp,-64,°osp
call runtime-linker
пор
.PLT1:
.word identification
unimp
unimp
...
Обычные записи PLT после настройки:
PLT101:
sethi (.-.PLT0),%g1
sethi %hi(name1),%g1
jmpl %g1+%lo(namel),%g0
PLT102:
sethi (.-.PLT0),%g1
sethi %hi (name2),%g1
jmpl %g1+%lo(name2),%g0
Таким образом, каждая пользовательская задача, загруженная в Unix, имеет собственное адресное пространство с собственной структурой (рис. 5.18). Некоторые участки памяти у разных задач могут совпадать, и это позволяет сэкономить ресурсы за счет их разделения. Это существенно менее глубокое разделение, чем то, что достигается в Windows, но, как мы видели в разд. Динамические библиотеки более глубокое и принудительное разделение кода чревато серьезными проблемами.
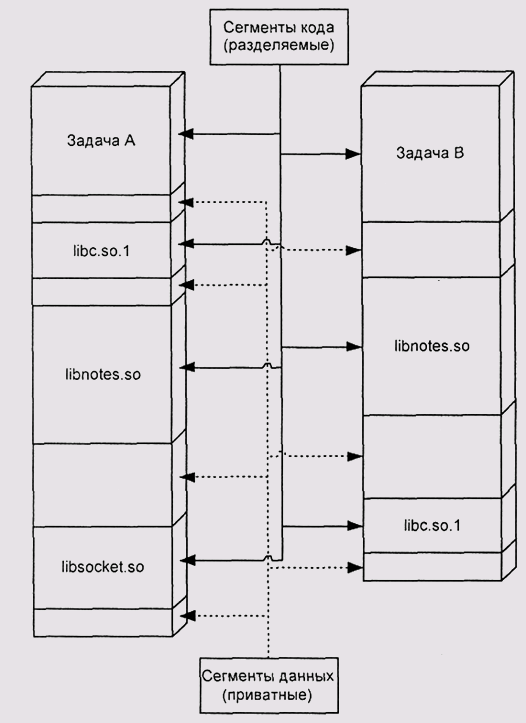
Рис. 5.18. Разделяемые библиотеки ELF
Разделяемые объекты ELF идентифицируются по имени файла. Исполняемый модуль может ссылаться на файл как по простому имени (например, libc.so.1), так и с указанием пути (/usr/lib/libc.so.1). При поиске файла по простому имени редактор связей ищет его в каталогах, указанных в переменной среды LD LIBRARY_PATH, в записи RPATH заголовка модуля и, наконец, в каталогах по умолчанию, перечисленных в конфигурационном файле /var/ld/ld.config (именно в таком порядке, [docs.sun.com 816-0559-10]). При формировании имен каталогов могут использоваться макроподстановки с использованием следующих переменных.
$ISALIST— список систем команд— полезно на процессорах, поддерживающих несколько систем команд, например х86 и 8086, SPARC 32 и SPARC 64.
$ORIGIN — каталог, из которого загружен модуль. Полезно для загрузки приложений, которые имеют собственные разделяемые объекты.
SOSNAME, $OSREL — название и версия операционной системы.
$PLATFORM— тип процессора. Полезно для приложений, которые содержат в поставке бинарные модули сразу для нескольких процессоров, сетевых установок таких приложений, или сетевой загрузки в гетерогенной среде.
Понятно, что задание простого имени предпочтительнее, так как дает администратору системы значительную свободу в размещении разделяемых библиотек. Впрочем, системный редактор связей Idd позволяет изменять имена внешних ссылок и RPATH в уже построенном модуле, в частности заменяя одни файловые пути на другие, путевые имена на простые и наоборот. Благодаря этому, поставщик приложений для ОС, основанных на формате ELF, имеет гораздо меньше возможностей испортить жизнь системному администратору, чем поставщик приложений для Windows.
По стандартному соглашению, имя библиотеки обязательно содержит и номер версии (в обоих примерах это 1). В соответствии с требованиями фирмы Sun номер версии меняется, только когда интерфейс библиотеки меняется на несовместимый — убираются функции, изменяется их семантика и т. д. Из менее очевидных соображений [docs.sun.com 816-0559-10] требуется менять номер версии и при добавлении функции или переменной: ведь вновь добавленный символ может конфликтовать по имени с символом какой-то другой библиотеки.
Исправление ошибок, т. е. нарушение "bug-for-bug compatibility", основанием для изменения номера версии фирма Sun не считает. Напротив, в Linux принято снабжать разделяемые библиотеки минимум двумя, а иногда и более номерами версий — старшая (major) версия изменяется по правилам, приблизительно соответствующим требованиям Sun, а младшие (minor) — после исправления отдельных ошибок и других мелких изменений.
Благодаря этому соглашению, в системе одновременно может быть установлено несколько версий одного и того же модуля, а пользовательские программы могут ссылаться именно на ту версию, с которой разрабатывались и на совместимость с которой тестировались. Администратор может управлять выбором именно той библиотеки, на которую ссылаются конкретные модули, либо изменяя ссылки в этих модулях при помощи Idd, либо используя символические связи.
Страничный обмен
Подкачка, или свопинг (от англ, swapping — обмен) — это процесс выгрузки редко используемых областей виртуального адресного пространства программы на диск или другое устройство массовой памяти. Такая массовая память всегда намного дешевле оперативной, хотя и намного медленнее.
Во многих учебниках по ОС приводятся таблицы, аналогичные табл. 5.2.
Таблица 5.2. Сравнительные характеристики и стоимость различных типов памяти
| Тип памяти | Время доступа | Цена 1 Мбайта (цены 1995 г.) | Способ использования |
| Статическая память | 15 нc | $200 | Регистры, кэш-память |
| Динамическая память | 70 нc | $30 (4 Мбайт SIMM) | Основная память |
| Жесткие магнитные диски | 1-10 мс | $3 (1.2Gb HIDE) | Файловые системы, устройства свопинга |
| Магнитные ленты | Секунды | $0.025 (8mm Exabyte) | Устройства резервного копирования |
При разработке системы всегда есть желание сделать память как можно более быстрой. С другой стороны, потребности в памяти очень велики и постоянно растут.
Примечание
Существует эмпирическое наблюдение, что любой объем дисковой памяти будет полностью занят за две недели.
Очевидно, что система с десятками гигабайтов статического ОЗУ будет иметь стоимость, скажем так, совершенно не характерную для персонапь-ных систем, не говоря уже о габаритах, потребляемой мощности и прочем. К счастью, далеко не все, что хранится в памяти системы, используется одновременно. В каждый заданный момент исполняется только часть установленного в системе программного обеспечения, и работающие программы используют только часть данных.
Эмпирическое правило "80—20", часто наблюдаемое в коммерческих системах обработки транзакций, гласит, что 80% операций совершаются над 20% файла [Heising 1963]. В ряде работ, посвященных построению оптимизирующих компиляторов, ссылаются на правило "90-10" (90% времени исполняется 10% кода) — впрочем, есть серьезные основания сомневаться в том, что в данном случае соотношение именно таково [Кнут 2000, т. 3].
В действительности, удивительно большое количество функций распределения реальных дискретных величин (начиная от количества транзакций на строку таблицы и заканчивая распределением богатства людей или капитализации акционерных обществ) подчиняются закону Парето [Pareto 1897]:
Р = ck  -1,
-1,
где — число в диапазоне от 0 до 1, k — значение величины (в нашем случае — количество обращений к данной записи), р — количество записей, к которым происходит k обращений, с — нормализующий коэффициент (правило "80—20" соответствует = =log80/log20 = 0,1386) или его частному случаю, распределению Зипфа [Zipf 1949]:
р = c/ k.
Детальное обсуждение этого явления, к сожалению, не доходящее до глубинных его причин, приводится в [Кнут 200, т. 3]. Как один из результатов обсуждения предлагается концепция "самоорганизующегося файла" — для ускорения поиска в несортированном массиве предлагается передвигать записи ближе к началу массива. Если обращения к массиву распределены в соответствии с законом Зипфа, наиболее востребованные записи концентрируются в начале массива и поиск ускоряется в c/ ln N раз, где N — размер массива, а с — константа, зависящая от используемой стратегии перемещения элементов.
При произвольном доступе к данным (например, по указателям или по ключам хэш-таблицы) перемещение к началу массива не имеет столь благотворного эффекта — если только вся память имеет одну и ту же скорость доступа. Но мы видели, что разные типы запоминающих устройств резко различаются по этому параметру.
Это различие приводит нас к идее многослойной или многоуровневой памяти, когда в быстрой памяти хранятся часто используемые код или данные, а редко используемые постепенно мигрируют на более медленные устройства. В случае дисковой памяти такая миграция осуществляется вручную: администратор системы сбрасывает на ленты редко используемые данные и заполняет освободившееся место чем-то нужным. Для больших и сильно загруженных систем существуют специальные программы, которые определяют, что является малоценным, а что — нет. Управление миграцией из ОЗУ на диск иногда осуществляется пользователем, но часто это оказывается слишком утомительно. В случае миграции между кэш-памятью и ОЗУ Делать что-то вручную просто физически невозможно.
Дата публикования: 2014-11-18; Прочитано: 490 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
