 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
ВВЕДЕНИЕ 7 страница. Макропроцессор, кроме раскрытия макросов, обычно предоставляет также директивы условной компиляции — в зависимости от условий
|
|
Макропроцессор, кроме раскрытия макросов, обычно предоставляет также директивы условной компиляции — в зависимости от условий, те или иные участки кода могут передаваться компилятору или нет. Условия, конечно же, должны быть известны уже на этапе компиляции. Например, в зависимости от типа целевого процессора одна и та же конструкция может реализоваться как в одну команду, так и эмулирующей программой. В зависимости от используемой операционной системы могут применяться разные системные вызовы (это чаще случается при программировании на языках высокого уровня), или в зависимости от значений параметров макроопределения, макрос может порождать совсем разный код.
Макросредства есть не только в ассемблерах, но и во многих языках высокого уровня (ЯВУ). Наиболее известен препроцессор языка С. В действительности, многие средства, предоставляемые языками, претендующими на большую, чем у С, "высокоуровневость" (что бы под этим ни подразумевалось), также реализуются по принципу макрообработки, т. е. при помощи текстовых подстановок и компиляции результата: шаблоны (template) C++, параметризованные типы Ada и т. д.
Умелое использование макропроцессора облегчает чтение кода и увеличивает возможности его повторного использования в различных ситуациях. Злоупотребление же макросредствами (как, впрочем, и многими другими мощными и выразительными языковыми конструкциями) или просто бестолковое их применение может приводить к совершенно непонятному коду и трудно диагностируемым ошибкам, поэтому многие теоретики программирования выступали за полный отказ от использования макропроцессоров.
Современные методы оптимизации в языках высокого уровня — проверка константных условий, разворачивание циклов, inlme-функции — часто стирают различия между макрообработкой и собственно компиляцией.
Кроме избавления программиста от необходимости запоминать коды команд, ассемблер выполняет еще одну, пожалуй, даже более важную функцию: он позволяет снабжать символическими именами (метками) или (символами) команды или ячейки памяти, предназначенные для данных. Значение этой возможности для практического программирования трудно переоценить.
Рассмотрим простой пример из жизни: мы написали программу, которая содержит команду перехода (бывают и программы, которые ни одной команды перехода не содержат, но это вырожденный случай). Затем, в процессе тестирования этой программы или уточнения спецификаций мы поняли, что между командой перехода и точкой, в которую переход совершается, необходимо вставить еще два десятка команд. Для вставки необходимо пересчитать адрес перехода. На практике, вставка даже одной только инструкции часто затрагивает и приводит к необходимости пересчитывать адреса множества команд перехода, поэтому возможность автоматизировать этот процесс крайне важна.
Важное применение меток — организация ссылок между модулями в программах, собираемых из нескольких раздельно компилируемых файлов. Изменение объема кода или данных в любом из модулей приводит к необходимости пересчета адресов во всех остальных модулях. В современных программах, собираемых из сотен отдельных файлов и содержащих тысячи индивидуально адресуемых объектов, выполнять такой пересчет вручную невозможно. Способы автоматического решения этой задачи обсуждаются в разд. Сборка программ.
Фаза сопоставления символов с реальными адресами присутствует и при компиляции языков высокого уровня — компилятор генерирует символы не только для переменных, процедур и меток, которые могут быть использованы в операторе goto, но и для реализации "структурных" условных операторов и циклов. Нередко в описании компилятора эту фазу так и называют — ассемблирование.
Многие компиляторы как старые, так и современные, например, популярный компилятор GNU С, даже не выполняют фазу ассемблирования самостоятельно, а вместо этого генерируют текст на языке ассемблера и вызывают внешний ассемблер. Средства межпроцессного взаимодействия современных ОС позволяют передавать этот промежуточный текст, не создавая промежуточного файла, поэтому для конечного пользователя эта деталь реализации часто оказывается незаметной.
Компиляторы, имеющие встроенный ассемблер, такие, как Microsoft C/C++ или Watcom, часто могут генерировать ассемблерное представление порождаемого кода. Это бывает полезно при отладке или написании подпрограмм на ассемблере, которые должны взаимодействовать с откомпилированным кодом.
Многопроходное ассемблирование
При ассемблировании с использованием меток возникает специфическая проблема: команды могут ссылаться на метки, определенные как до, так и после них по тексту программы. Следовательно, операндом команды может оказаться метка, которая еще не определена. Адрес, соответствующий этой метке, еще неизвестен, поэтому мы должны будем, так или иначе, вернуться к ссылающейся на нее команде и записать адрес. Эта же проблема возникает и при компиляции ЯВУ: предварительное определение переменных и процедур указывает тип переменной и количество и типы параметров процедуры, но не их размещение в памяти, а именно оно нас и интересует при генерации кода.
Две техники решения этой проблемы называются одно- и двухпроходным ассемблированием [Баррон 1974].
При двухпроходном ассемблировании, на первом проходе мы определяем адреса всех описанных в программе символов и сохраняем их в промежуточной таблице. На втором проходе мы осуществляем собственно ассемблирование — генерацию кода и расстановку адресов. Если адресное поле имеет переменную длину, определение адреса метки может привести к изменению длины ссылающегося на нее кода, поэтому на таких архитектурах оказывается целесообразным трех- и более проходное ассемблирование. При однопроходном ассемблировании, мы запоминаем все точки, из которых происходят ссылки вперед, и, определив адрес символа, возвращаемся к этим точкам и записываем в них адрес. При однопроходном ассемблировании целесообразно хранить код, в котором еще не все метки расставлены, в оперативной памяти, поэтому в старых компьютерах двухпроходные ассемблеры были широко распространены. Впрочем, современные многопроходные ассемблеры также хранят промежуточные представления программы в памяти, поэтому количество проходов в конкретной реализации ассемблера представляет разве что теоретический интерес.
Глава 3. Загрузка программ
Загрузка программ
- Абсолютная загрузка
- Разделы памяти
- Относительная загрузка
- Базовая адресация
- Позиционно-независимый код
- Оверлеи (перекрытия)
- Сборка программ
- Объектные библиотеки
- Сборка в момент загрузки
- Динамические библиотеки
- Загрузка самой ОС
Загрузка программ
Выяснив, что представляет собой программа, давайте рассмотрим процедуру ее загрузки в оперативную память компьютера (многие из обсуждаемых далее концепций, впрочем, в известной мере применимы и к прошивке программы в ПЗУ).
Для начала предположим, что программа была заранее собрана в некий единый самодостаточный объект, называемый загрузочным или загружаемым модулем. В ряде операционных систем программа собирается в момент загрузки из большого числа отдельных модулей, содержащих ссылки друг на друга, но об этом ниже.
Для того чтобы не путаться, давайте будем называть программой ту часть загрузочного модуля, которая содержит исполняемый код. Результат загрузки программы в память будем называть процессом или, если нам надо отличать загруженную программу от процесса ее исполнения, образом процесса. К образу процесса иногда причисляют не только код и данные процесса (подвергнутые преобразованию как в процессе загрузки, так и в процессе работы программы), но и системные структуры данных, связанные с этим процессом. В старой литературе процесс часто называют задачей.
В системах с виртуальной памятью каждому процессу обычно выделяется свое адресное пространство, поэтому мы иногда будем употреблять термин процесс и в этом смысле. Впрочем, во многих системах значительная часть эдресных пространств разных процессов перекрывается — это используется Для реализации разделяемого кода и данных.
В рамках одного процесса может исполняться один или несколько потоков или нитей управления. Это понятие будет подробнее разбираться в главе 8.
Некоторые системы предоставляют и более крупные структурные единицы, Чем процесс. Например, в системах семейства Unix существуют группы процессов, которые используются для реализации логического объединенияют не только код и данные процесса (подвергнутые преобразованию как в процессе загрузки, так и в процессе работы программы), но и системные структуры данных, связанные с этим процессом. В старой литературе процесс часто называют задачей.
В системах с виртуальной памятью каждому процессу обычно выделяется свое адресное пространство, поэтому мы иногда будем употреблять термин процесс и в этом смысле. Впрочем, во многих системах значительная часть эдресных пространств разных процессов перекрывается — это используется Для реализации разделяемого кода и данных.
В рамках одного процесса может исполняться один или несколько потоков или нитей управления. Это понятие будет подробнее разбираться в главе 8.
Некоторые системы предоставляют и более крупные структурные единицы, чем процесс. Например, в системах семейства Unix существуют группы процессов, которые используются для реализации логического объединения процессов в задания (job). Ряд систем имеют также понятие сессии — совокупности всех заданий, которые пользователь запустил в рамках одного сеанса работы. Впрочем, соответствующие концепции часто плохо определены, а их смысл сильно меняется от одной ОС к другой, поэтому мы практически не будем обсуждать эти понятия.
В более старых системах и в старой литературе называют результат загрузки задачей, а процессами — отдельные нити управления.
Однако в наиболее распространенных ныне ОС семейств Unix и Win32, принято задачу называть процессом, а процесс — нитью (tread).
Этой терминологии мы и будем придерживаться, кроме тех случаев, когда будем обсуждать примеры из жизни ОС, в которой принята иная терминология.
Создание процессов в Unix
В системах семейства Unix новые процессы создаются системным вызовом fork. Этот вызов создает два процесса, образы которых в первый момент полностью идентичны, у них различается только значение, возвращенное вызовом fork. Типичная программа, использующая этот вызов, выглядит так, как представлено в примере 3.1.
При этом каждый из процессов имеет свою копию всех локальных и статических переменных. На процессорах со страничным диспетчером памяти физического копирования не происходит. Изначально оба процесса используют одни и те же страницы памяти, а дублируются только те из них, которые были изменены. На системах, не имеющих страничного или сегментного диспетчера памяти, fork требует копирования адресных пространств, что приводит к большим накладным расходам, да и просто не всегда возможно.
Если мы хотим запустить другую программу, то мы должны исполнить системный вызов из семейства exec. Вызовы этого семейства различаются только способом передачи параметров. Все они прекращают исполнение текущего образа процесса и создают новый процесс с новым виртуальным адресным пространством, но с тем же идентификатором процесса. При этом у нового процесса будет тот же приоритет, будут открыты те же файлы (это часто используется), и он унаследует ряд других важных характеристик.
Несколько неожиданное, но тем не менее верное описание действия exec — это замена образа процесса в рамках того же самого процесса.
Запуск другой программы в UNIX выглядит примерно так, как представлено в примере 3.2.
Программа в примере 3.2 запускает командный интерпретатор /bin/sh, известный как Bourne shell, приказывает ему исполнить команду Is -1 и перенаправляет стандартный вывод этой команды в файл ls.log.
Техника программирования, основанная на fork/exec, несколько отличается от принятой во многих других современных системах, в том числе Win32, где при создании нового процесса мы сразу же указываем программу, которую он будет исполнять.
Пример 3.1. Создание процесса в системах семейства Unix
;nt pid; /* Идентификатор порожденного процесса */
switch(pid = fork())
I
case 0: /* Порожденный процесс */
break; case -1: /Ошибка */
perror("Cannot fork");
extt(l); default: /* Родительский процесс */
/* Здесь мы можем ссылаться на порожденный процесс,
* используя значение pid */
Пример 3.2. Создание процесса и замена программы в системах семейства Unix
int pid; /* Идентификатор порожденного процесса */
switch (pid = fork ())
{
case 0: /* Порожденный процесс */
dup2(l, open("Is.log", 0_WRONLY I 0_CREAT)); /* Перенаправить открытый файл #1 * (stdout) в файл Is.log */
execl("/bin/sh", "sh", "-c", "Is", "-1", 0);
/* Сюда мы попадаем только при ошибке! */
/* fall through */ case -1: /* Ошибка */
perror("Cannot fork or exec");
exit(1); default: /* Родительский процесс */
/* Здесь мы можем ссылаться на порожденный
* процесс, используя значение pid */
}
Но вернемся к способам загрузки программ.
Абсолютная загрузка
Первый, самый простой, вариант состоит в том, что мы всегда будем загружать программу с одного и того же адреса. Это возможно в следующих случаях.
- Система может предоставить каждому процессу свое адресное пространство. Это возможно только на процессорах, осуществляющих трансляцию виртуального адреса в физический.
- Система может исполнять в каждый момент только один процесс. Так ведет себя СР/М, так же устроено большинство загрузочных мониторов для самодельных компьютеров. Похожим образом устроена система RT-11, но о ней чуть ниже.
Загрузочный файл, используемый при таком способе загрузки, называется абсолютным загрузочным модулем.
Начальное содержимое образа процесса формируется путем простого копирования модуля в память. В системе RT-11 такие файлы имеют расширение sav от saved — сохраненный.
Формат загрузочного модуля a.out
В системе UNIX на 32-разрядных машинах также используется абсолютная загрузка. Загружаемый файл формата a.out (современные версии Unix используют более сложный формат загружаемого модуля и более сложную схему загрузки, которая будет обсуждаться в разд. Разделяемые библиотеки) начинается с заголовка (рис. 3.1), который содержит:
• "магическое число" — признак того, что это именно загружаемый модуль, а не что-то другое;
• число TEXT_SIZE — длину области кода программы (TEXT);
• DATA_SIZE —длину области инициализованных данных программы (DATA);
• BSS_SIZE —длину области неинициализованных данных программы (BSS);
• стартовый адрес программы.
За заголовком следует содержимое областей TEXT и DATA. Затем может следовать отладочная информация. Она нужна символьным отладчикам, но самой программой не используется.
При загрузке система выделяет процессу TEXT_SIZE байтов виртуальной памяти, доступной для чтения/исполнения, и копирует туда содержимое сегмента TEXT. Затем отсчитывается DATA_SIZE байтов памяти, доступной для чтения/ записи, и туда копируется содержимое сегмента DATA. Затем отсчитывается
еще BSS_SIZE байтов памяти, доступной для чтения/записи, которые прописываются нулями.
Очистка выделяемой памяти нужна не столько для удобства программиста, сколько по соображениям безопасности: перед вновь загружаемым процессом эту память могли занимать (а при сколько-нибудь длительной работе системы почти наверняка занимали) другие процессы, которые могли использовать эту память для хранения важных и секретных данных, например паролей или ключей шифрования.
После этого выделяется пространство под стек, в стек помещаются позиционные аргументы и среда исполнения (environment), и управление передается на стартовый адрес. Процесс начинает исполняться.
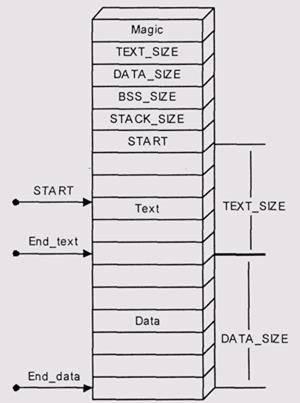
Рис. З.1. Загрузочный модуль a.out
Разделы памяти
Одним из способов обойти невозможность загружать более одной програм-Mbi при абсолютной загрузке являются разделы памяти. В наше время этот метод практически не применяется, но в машинах второго поколения использовался относительно широко и часто описывается в старой литературе.
Идея метода состоит в том, что мы задаем несколько допустимых стартовых адресов для абсолютной загрузки. Каждый такой адрес определяет раздел памяти (рис. 3.2). Процесс может размещаться в одном разделе, или, если это необходимо — т. е. если образ процесса слишком велик — в нескольких Это позволяет загружать несколько процессов одновременно, сохраняя при этом преимущества абсолютной загрузки
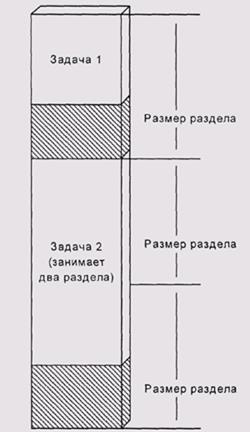
Рис. 3.2. Разделы памяти
Если мы не знаем, в какой из разделов пользователь вынужден будет загружать нашу программу, мы должны предоставить по отдельному загрузочному модулю на каждый из допустимых разделов. Понятно, что это не очень практично, поэтому разделы были вытеснены более удобными схемами управления памятью.
Относительная загрузка
Относительный способ загрузки состоит в том, что мы загружаем программу каждый раз с нового адреса. При этом мы должны настроить ее на новые адреса, а для этого нам надо вспомнить материал предыдущей главы и понять, что же именно в программе привязано к адресу загрузки.
При использовании в коде программы абсолютной адресации мы должны найти адресные поля всех команд, использующих такую адресацию, и пересчитать эти адресные поля с учетом реального адреса загрузки (рис. 3.3). Если в коде программы применялись косвенно-регистровый, базовый и ба-зово-индексный режимы адресации, следует найти те места, где в регистр загружается значение адреса (рис. 3.4).
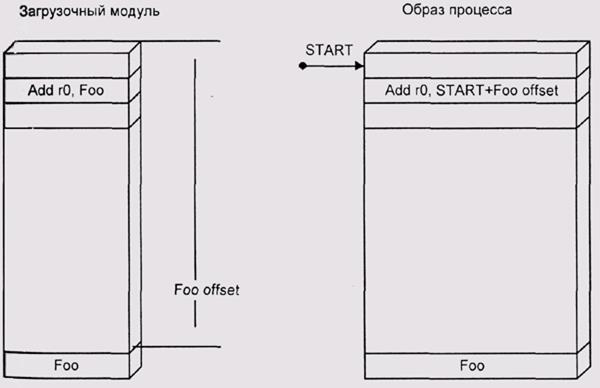
Рис. 3.3. Перемещение кода, использующего абсолютную адресацию

Рис. З.4. Перемещение кода, самостоятельно перезагружающего базовые регистры
Сложность здесь в том, что если абсолютные адресные поля можно найти анализом кодов команд (деассемблированием), то значение в адресный регистр может загружаться задолго до собственно адресации, причем, как мы видели в примерах кода для процессора SPARC, Формирование значения регистра может происходить и по частям. Без помощи программиста или компилятора (в этой главе мы не будем различать написанный на ассемблере или компилированный код, а того, кто генерировал код, будем называть программистом) решить вопрос о том, какая из команд загружает в регистр скалярное значение, а какая -будущий адрес или часть адреса, невозможно. Та же проблема возникает в случае, если мы используем в качестве указателя ячейку статически инициализованных данных (пример 3.3).
Пример 3.3. Примеры статически инициализованных указателей в С
int buf[20], *bufptr=buf;
char * message="No message defined yet\n";
void do_nothing_hook(int);
void (*hook)(int)=do_nothing_hook;
Довольно легко построить и пример кода, в котором адресация происходит вообще без явного использования каких-либо регистров, во всяком случае, без загрузки в них значений (пример 3.4).
Пример 3.4. Реализация косвенного перехода по адресу dst_seg:dst_offs
push dst seg; Это и будет ссылкой на абсолютный адрес
push dst_offs
retf
На практике содействие программиста загрузчику состоит в том, что программист старается без необходимости не использовать в адресных полях и в качестве значений адресных регистров произвольные значения (необходимость в этом может возникать при адресации системных структур данных или внешних устройств, расположенных по фиксированным адресам). Вместо этого, программист применяет ассемблерные символы, соответствующие адресам.
Ассемблер при каждой ссылке на такой символ генерирует не только "заготовку" адреса в коде, но и запись в таблице перемещений (relocation table). Эта запись хранит место ссылки на такой символ в коде или данных. Если в ссылке используется только часть адреса, как в командах sethi %10, %hi(addr) процессора SPARC, или move ax, segment addr Процессора 8086, мы запоминаем и этот факт.
В качестве "заготовки" адреса обычно используется смешение адресуемого объекта от начала программы. При настройке программы на реальный адрес загрузки нам, таким образом, необходимо пройти по всем объектам, перечисленным в таблице перемещений, и переместить каждую из ссылок — сформировать из заготовки адрес.
Файл, содержащий таблицу перемещений, гораздо сложнее абсолютного загружаемого модуля и носит название относительного или перемещаемого загрузочного модуля. Именно такой формат имеют ехе-файлы в системе MS DOS (пример 3.5).
Пример 3.5. Заголовок ЕХЕ-файла MS DOS. Цитируется по WINT.H из поставки |; MS Visual C++ v6.0 (перевод комментариев автора)
#define IMAGE_DOS_SIGNATURE Ox4D5A // MZ
typedef struct _IMAGE_DOS_HEADER { // Заголовок DOS.EXE
WORD e_magic; // Магическое число (сигнатура)
WORD e_cblp; // Длина последней страницы файла в байтах
WORD e_cp; // Количество страниц в файле
WORD e_crlc; // Количество перемещений
WORD e_cparhdr; // Размер заголовка в параграфах
WORD ejrainalloc; // Минимальное количество дополнительных параграфов
ORD e_maxalloc; // Максимальное количество дополнительных параграфов
WORD e ss; // Начальное (относительное) значение SS
WORD e_sp; // Начальное значение SP
WORD e_csum; // Контрольная сумма
WORD e_ip; // Начальное значение IP
WORD e_cs; // Начальное (относительное) значение CS
WORD e_lfarlc;// Адрес таблицы перемещений в файле
WORD e_ovno;// Номер перекрытия
WORD e_res[4];// Зарезервировано
WORD e_oemid; // OEM идентификатор (для e_oeminfo)
WORD e_oeminfo;// Информация OEM; специфично для e_oemid
WORD e_res2[10];// Зарезервировано
LONG e_lfanew; }// Адрес следующего заголовка в файле
}IMAGE DOS HEADER, РIMAGE DOS HEADER;
Наиболее поучительна в этом отношении система RT-11, в которой существуют загружаемые модули обоих типов. Обычные программы имеют расширение sav, представляют собой абсолютные загружаемые модули и грузятся всегда с адреса 01000. Ниже этого магического адреса находятся векторы прерываний и стек программы. Сама операционная система вместе с драйверами размещается в верхних адресах памяти. Естественно, вы не можете загрузить одновременно два sav-файла.
Однако, если вам обязательно нужно исполнять одновременно две программы, вы можете собрать вторую из них в виде относительного модуля: файла с расширением rel. Такая программа будет загружаться в верхние адреса памяти, каждый раз разные, в зависимости от конфигурации ядра системы, количества загруженных драйверов устройств и других rel-модулей (рис. 3.5).

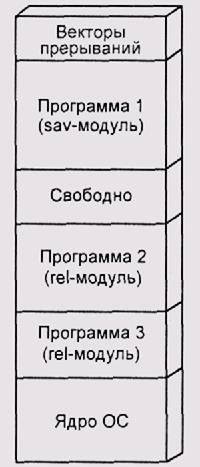
Рис. 3.5. Распределение памяти в RT-11 с одним загруженным sav-файлом и двумя rel-файлами
Базовая адресация
Впрочем, если уж мы полагаемся на содействие программиста, можно пойти в этом направлении дальше: мы объявляем один или несколько регистров процессора базовыми (несколько регистров могут использоваться для адресации различных сегментов программы, например, один — для кода, другой — для статических данных, третий — для стека) и договариваемся, что значения этих регистров программист принимает как данность и никогда сам не модифицирует, зато все адреса в программе он вычисляет на основе значений этих регистров (рис. 3.6).
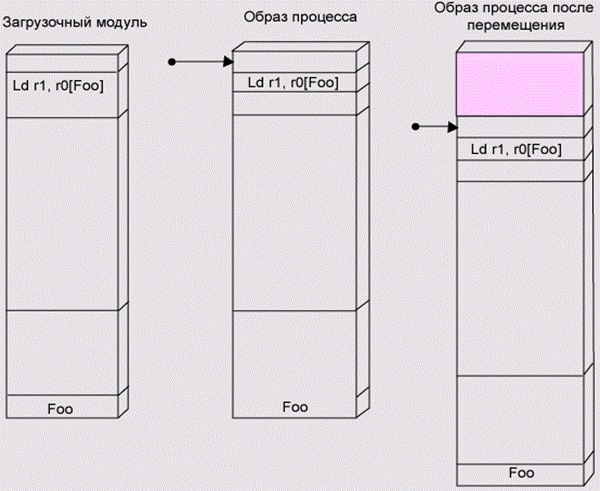
Рис. З.6. Перемещение кода, использующего базовую адресацию
В этом случае для перемещения программы нам нужно только изменить значения базовых регистров, и программа даже не узнает, что загружена с Другого адреса. Статически инициализованными указателями в этом случае пользоваться либо невозможно, либо необходимо всегда прибавлять к ним значения базовых регистров.
Именно так происходит загрузка corn-файлов в системе MS DOS. Система вьщеляет свободную память, настраивает для программы базовые регистры DS и CS, которые почему-то называются сегментными, и передает управление на стартовый адрес. Ничего больше делать не надо.
Позиционно-независимый код
За всеми этими разговорами мы чуть было не забыли о третьем способе формирования адреса в программе. Это относительная адресация, когда адрес получается сложением адресного поля команды и адреса самой этой команды — значения счетчика команд. Код, в котором используется только такая адресация, можно загружать с любого адреса без всякой перенастройки. Такой код называется позиционно-независимым (position-independent).
Позиционно-независимые программы очень удобны для загрузки, но, к сожалению, при их написании следует соблюдать довольно жесткие ограничения, накладываемые на используемые в программе методы адресации. Например, нельзя пользоваться статически инициализованными переменными указательного типа, нельзя делать на ассемблере фокусы, вроде того, который был приведен в примере 3.5, и т. д. Возникают сложности при сборке программы из нескольких модулей.
К тому же, на многих процессорах, например, на Intel 8080/8085 или многих современных RISC-процессорах, описанная выше реализация позиционно-независимого кода вообще невозможна, так как эти процессоры не поддерживают соответствующий режим адресации для данных. На процессорах гарвардской архитектуры адресовать данные относительно счетчика команд вообще невозможно — команды находятся в другом адресном пространстве.
Поэтому такой стиль программирования используют только в особых случаях. Например, многие вирусы для MS DOS и драйверы для RT-I1 написаны именно таким образом.
Любопытное наблюдение
В эпоху RT-11 хакеры писали драйверы. Сейчас они пишут вирусы. Еще любопытнее, что для некоторых персональных платформ, например, для Amiga, вирусов почти нет. Хакеры считают более интересным писать игры или демонстрационные программы для Amiga. Похоже, общение с IBM PC порождает у программиста какие-то агрессивные комплексы. Наблюдение это принадлежит не автору: см. [КомпьютерПресс 1993].
Позиционно-независимый код в современных Unix-системах
Компиляторы современных систем семейства UNIX — GNU С или стандартный С-компилятор UNIX SVR4 имеют ключ -f PIC (Position-Independent Code). Впрочем, код, порождаемый при использовании этого ключа, не является позиционно-независимым в указанном выше смысле: этот код все-таки содержит перемещаемые адресные ссылки. Задача состоит не в том, чтобы избавиться от таких ссылок полностью, а лишь в том, чтобы собрать все эти ссылки в одном месте и разместить их, по возможности, отдельно от кода. Какая от этого польза, мы поймем несколько позже, в разд. Разделяемые библиотеки, а сейчас обсудим технические приемы, используемые для решения этой задачи.
Код, генерируемый GNU С, использует базовую адресацию: в начале функции адрес точки ее входа помещается в один из регистров, и далее вся адресация других функций и данных осуществляется относительно этого регистра. На процессоре х86 используется регистр %ebx, а загрузка адреса осуществляется командами, вставляемыми в пролог каждой функции (пример 3.6).
На процессорах, где разрешен прямой доступ к счетчику команд, соответствующий код выглядит проще, но принцип сохраняется: компилятор занимает один регистр и благодаря этому упрощает работу загрузчику.
Как мы видим в примере 3.7, на самом деле адресация происходит не относительно точки входа в функцию, а относительно некоторого объекта, называемого GOT или GLOBAL_OFFSET_TABLE. Счетчик команд используется для вычисления адреса этой таблицы, а не сам по себе. Подробнее мы разберемся с логикой работы этого кода (и заодно с тем, что означает еще один непонятный символ — PLT) в разд. Разделяемые библиотеки.
Компилированный таким образом код предназначен в первую очередь для разделяемых библиотек формата ELF (Executable and Linking Format, формат исполняемых и собираемых [модулей], используемый большинством современных систем семейства Unix).
Пример 3.6. Получение адреса точки входа в позиционно-независимую подпрограмму
call L4
L4:
popl %ebx
Пример 3.7. Позиционно-независимый код, порождаемый компилятором GNU С
/* strerror.c (emx+gcc) — Copyright (с) 1990-1996 by Eberhard Mattes */
#include <stdlib.h>
#include <string.h>
#include <emx/thread.h>
char *strerror (int errnum)
{ (
if (errnum >= 0 && errnum < _sys_nerr)
return (char *)_sys_errlist [errnum];
else
{
static char msg[] = "Unknown error ";
#if defined (_ MT _)
struct _thread *tp = _thread ();
#define result (tp->_th_error)
#else
static char result [32];
#endif
memcpy (result, msg, sizeof (rasg) — 1);
_itoa (errnum, result + sizeof (msg) — 1, 10);
return result;
}
}
gcc -f PIC -S strerror.c
. file "strerror"
gcc2_compiled.:
_ gnu_compiled_c:
.data
_msg.2:
.ascii "Unknown error \0"
.Icomm _result.3,32
.text
.align 2, 0x90
. globl _strerror
__strerror:
pushl %ebp
movl %esp, %ebp
pushl %ebx
call L4
L4:
popl %ebx
addl $_GLOBAL_OFFSET_TABLE_+ [. -L4 ], %ebx
cmpl $0,8 (%ebp)
jl L2
movl _ sys_nerr@GOT (%ebx), %eax
movl 8 (%ebp), %edx
cmpl %edx, (%eax)
jle L2
movl 8(%ebp),%eax
movl %eax,%edx
leal 0(,%edx,4),%eax
movl __sys_errlist@GOT(%ebx), %edx
movl (%edx,%eax),%eax jmp LI
.align 2,0x90 jmp L3.align 2,0x90
L2:
pushl $14
leal _msg.2@GOTOFF(%ebx),%edx
movl %edx,%eax
pushl %eax
leal _result.3@GOTOFF(%ebx),%edx
movl %edx,%eax
pushl %eax
call _memcpy@PLT
addl $12,%esp
pushl $10
leal _result.3@GOTOFF(%ebx), %edx
leal 14(%edx),%eax
pushl %eax
movl 8(%ebp),%eax
pushl %eax
call __itoa@PLT
addl $12,%esp
leal _result.3@GOTOFF(%ebx),%edx
movl %edx,%eax
jmp LI
.align 2,0x90
L3:
LI:
movl -4 (%ebp),%ebx
leave
ret
Дата публикования: 2014-11-18; Прочитано: 324 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
