 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Аналитические системы
|
|
В экономике широко применяются аналитические системы, основанные на OLAP-машинах. OLAP (on-line analytical processing) – средство оперативного анализа хранилищ данных. В правовой информатике с помощью OLAP-технологий можно анализировать определенный срез статистических данных, находящихся в хранилище. Скажем, уровень преступности зависит от целого ряда факторов. Срез показывает влияние одного из факторов – например, уровня образования, – на криминогенность обстановки.
В юридической практике более актуальны i2 системы, позволяющие строить связи, выявляя цепочки связанных между собой людей или событий. В этом случае основными понятиями модели являются «объект» и «связь». Подобного рода информация большей частью не может быть агрегирована, что делает традиционные средства представления информации в виде экранных форм и таблиц малопригодными. На первый план выходят визуальные средства анализа и такие графические представления данных как диаграммы связей (рис. 12), диаграммы последовательности событий (рис. 13)и диаграммы транзакций.

Рисунок 12. Диаграмма связей.
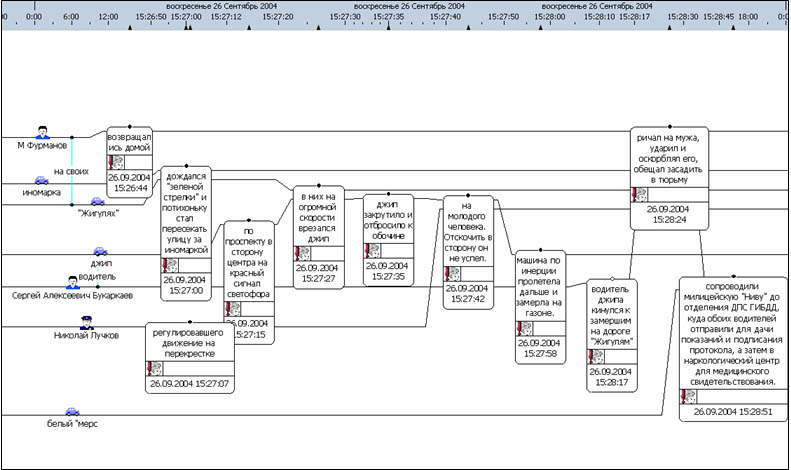
Рисунок 13. Диаграмма последовательности событий
Другой весьма существенной особенностью построения аналитических систем, связанных с безопасностью, является способ формирования хранилища данных. В случае финансовых аналитических систем источником данных, как правило, являются информационные системы, работающие в рамках одной и той же организации. При этом число объектов, подлежащих идентификации при загрузке хранилища по сравнению с объемом данных об этих объектах относительно невелико. Количество подобных объектов обычно исчисляется несколькими сотнями или тысячами.
Совершенно иная ситуация наблюдается в аналитических системах безопасности. Объектом исследования является физическое или юридическое лицо. Количество таких объектов в хранилище исчисляется десятками миллионов. Данные в систему поступают из совершенно не связанных между собой источников, таких как интернет, базы данных различных государственных ведомств. Естественно, ни о каком согласованном способе идентификации объектов между подобными источниками данных не может быть и речи. Объем дублирующих данных по одному и тому же объекту чрезвычайно велик.
Информация в таких системах часто не подлежит агрегированию. Но даже в тех случаях, когда данные могут быть агрегированы, их анализ зачастую не представляет интереса, поскольку предметом поиска являются достаточно редкие на фоне стандартного поведения факты. Задача стоит, без преувеличения, в отыскании иголки в стоге сена.
Например, борьба с отмыванием нелегальных доходов предполагает поиск в огромном потоке вполне легальных финансовых операций отдельных случаев отмывания денег. Основной поток операций носит легальный характер, и если изучать агрегированные данные, то обнаружить нарушения вряд ли удастся: при усреднении их доля станет незаметной. Подобные проблемы стоят и во множестве других сфер деятельности: выявление фактов мошенничества в страховом бизнесе, принятие решения об открытии кредитной линии банком и т.п. Общим для этих случаев является поиск в массиве данных, хотя и относительно редких, но важных событий, в той или иной мере обладающих устойчивыми характерными признаками.
Дата публикования: 2014-11-03; Прочитано: 426 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
