 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Глава 3. Количественная оценка информации 12 страница
|
|
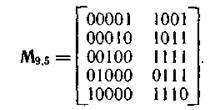
Однако можно построить код минимальной разрядности, заменив в (n, k) -коде j первых информационных символов нулями и исключив их из кодовых комбинаций. Код уже не будет циклическим, поскольку циклический сдвиг одной разрешенной кодовой комбинации не всегда приводит к другой разрешенной комбинации того же кода. Получаемый таким путем линейный (n — j, k — j)-код называют укороченным циклическим кодом. Минимальное расстояние этого кода не менее, чем минимальное кодовое расстояние (n, k)-кода, из которого он получен. Матрица укороченного кода получается из образующей матрицы (n, k)-кода исключением j строк и столбцов, соответствующих старшим разрядам. Например, образующая матрица кода (9,5), полученная из матрицы кода (15,11), имеет вид
§ 6.8 ТЕХНИЧЕСКИЕ СРЕДСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДЛЯ ЦИКЛИЧЕСКИХ КОДОВ
Линейные переключательные схемы. Основу кодирующих и декодирующих устройств циклических кодов составляют регистры сдвига с обратными связями, позволяющие осуществлять как умножение, так и деление многочленов с приведением коэффициентов по модулю два. Такие регистры также называют многотактными линейными переключательными схемами и линейными кодовыми фильтрами Хаффмена. Они состоят из ячеек памяти, сумматоров по модулю два и устройств умножения на коэффициенты многочленов множителя или делителя. В случае двоичных кодов для умножения на коэффициент, равный 1, требуется только наличие связи в схеме. Если коэффициент равен 0, то связь отсутствует. Сдвиг информации в регистре осуществляется импульсами, поступающими с генератора продвигающих импульсов, который на схеме, как правило, не указывается. На вход устройств поступают только коэффициенты многочленов, причем начиная с коэффициента при переменной в старшей степени.
 На рис. 6.10 представлена схема, выполняющая умножение произвольного (например, информационного) многочлена а(х)g(x) = а0+а1х+...+ak-1*xk-1 на некоторый фиксированный (например, образующий) многочлен g(х)=g0+g1 +...+gn-k*xn-k. Произведение этих многочленов равно
На рис. 6.10 представлена схема, выполняющая умножение произвольного (например, информационного) многочлена а(х)g(x) = а0+а1х+...+ak-1*xk-1 на некоторый фиксированный (например, образующий) многочлен g(х)=g0+g1 +...+gn-k*xn-k. Произведение этих многочленов равно
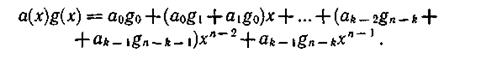
Предполагаем, что первоначально ячейки памяти находятся в нулевом состоянии и что за коэффициентами множимого следует n — k нулей.
На первом такте на вход схемы поступает первый коэффициент ak-1 многочлена а(х) и на выходе появляется первый коэффициент произведения, равный аk-1,gn-k. На следующем такте на выход поступит сумма ak-2 gn-k+ak-1gn-k-1, т.е. второй коэффициент произведения, и т. д. На n-м такте все ячейки, кроме последней, будут в нулевом состоянии и на выходе получим последний коэффициент a0g0.
Используется также схема умножения многочленов при поступлении множимого младшим разрядом вперед (рис. 6.11).
 На рис. 6.12 представлена схема, выполняющая деление произвольного многочлена [например, многочлена ι
На рис. 6.12 представлена схема, выполняющая деление произвольного многочлена [например, многочлена ι  ] на некоторый фиксированный (например, образующий) многочлен g(x) = g0+g1x+...+gn-k*xn-k. Обратные связи регистра соответствуют виду многочлена g(x). Количество включаемых в него сумматоров равно числу отличных от нуля коэффициентов g(x), уменьшенному на единицу. Это объясняется тем, что сумматор сложения коэффициентов старших разрядов многочленов делимого и делителя в регистр не включается, так как результат сложения заранее известен (он равен 0).
] на некоторый фиксированный (например, образующий) многочлен g(x) = g0+g1x+...+gn-k*xn-k. Обратные связи регистра соответствуют виду многочлена g(x). Количество включаемых в него сумматоров равно числу отличных от нуля коэффициентов g(x), уменьшенному на единицу. Это объясняется тем, что сумматор сложения коэффициентов старших разрядов многочленов делимого и делителя в регистр не включается, так как результат сложения заранее известен (он равен 0).
За первые n — k тактов коэффициенты многочлена-делимого заполняют регистр, причем коэффициент при x в старшей степени достигает крайней правой ячейки. На следующем такте «единица» делимого, выходящая из крайней ячейки регистра, по цепи обратной связи подается к сумматорам по модулю два, что равносильно вычитанию многочлена-делителя из многочлена-делимого. Если в результате предыдущей операции коэффициент при старшей степени x у остатка оказался равным нулю, то на следующем такте делитель не вычитается. Коэффициенты делимого только сдвигаются вперед по регистру на один разряд, что находится в полном соответствии с тем, как это делается при делении многочленов столбиком.
Деление заканчивается с приходом последнего символа многочлена-делимого. При этом разность будет иметь более низкую степень, чем делитель. Эта разность и есть остаток.
Отметим, что если в качестве многочлена-делителя выбран простой многочлен степени m = n — k, то, продолжая делить образовавшийся остаток при отключенном входе, будем получать в регистре по одному разу каждое из ненулевых m-разрядных двоичных чисел. Затем эта последовательность чисел повторяется.
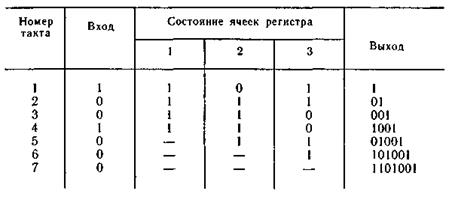
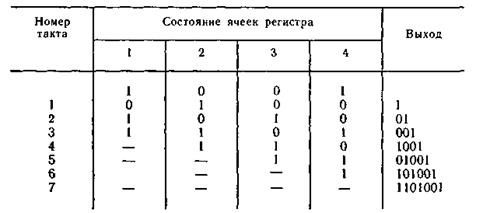
 Пример 6.15. Рассмотрим процесс деления многочлена а(х)хm= (x^3+1)x^3 на образующий многочлен g(x) = x^3 + + x^2 + 1. Схема для этого случая представлена на рис. 6.13, где 1, 2, 3 — ячейки регистра. Работа схемы поясняется табл. 6.14.
Пример 6.15. Рассмотрим процесс деления многочлена а(х)хm= (x^3+1)x^3 на образующий многочлен g(x) = x^3 + + x^2 + 1. Схема для этого случая представлена на рис. 6.13, где 1, 2, 3 — ячейки регистра. Работа схемы поясняется табл. 6.14.
Таблица 6.14

Вычисление остатка начинается с четвертого такта и заканчивается после седьмого такта. Последующие сдвиги приводят к образованию в регистре последовательности из семи различных ненулевых трехразрядных чисел. В дальнейшем эта последовательность чисел повторяется.
Рассмотренные выше схемы умножения и деления многочленов непосредственно в том виде, в каком они представлены на рис. 6.11, 6.12, в качестве кодирующих устройств циклических кодов на практике не применяются: первая — из-за того, что образующаяся кодовая комбинация в явном виде не содержит информационных символов, а вторая — из-за того, что между информационными и проверочными символами образуется разрыв в n — k разрядов.
Кодирующие устройства. Все известные кодирующие устройства для любых типов циклических кодов, выполненные на регистрах сдвига, можно свести к двум типам схем согласно рассмотренным ранее методам кодирования.
 Схемы первого типа вычисляют значения проверочных символов путем непосредственного деления многочлена а(х)хm на образующий многочлен g(x). Это делается с помощью регистра сдвига, содержащего n — k разрядов (рис. 6.14). Схема отличается от ранее рассмотренной тем, что коэффициенты кодируемого многочлена участвуют в обратной связи не через n — k сдвигов, а сразу с первого такта. Это позволяет устранить разрыв между информационными и проверочными символами
Схемы первого типа вычисляют значения проверочных символов путем непосредственного деления многочлена а(х)хm на образующий многочлен g(x). Это делается с помощью регистра сдвига, содержащего n — k разрядов (рис. 6.14). Схема отличается от ранее рассмотренной тем, что коэффициенты кодируемого многочлена участвуют в обратной связи не через n — k сдвигов, а сразу с первого такта. Это позволяет устранить разрыв между информационными и проверочными символами
В исходном состоянии ключ К1 находится в положении 1. Информационные символы одновременно поступают как в линию связи, так и в регистр сдвига, где за k тактов образуется остаток. Затем ключ Κ1 переходит в положение 2 и остаток поступает в линию связи.
Пример 6.16. Рассмотрим процесс деления многочлена а(х)хm = = (х3 + +1)x3 на многочлен g(x) = x3 + x2+ 1 за k тактов
Схема кодирующего устройства для заданного g(x) приведена на рис 6.15  Процесс формирования кодовой комбинации шаг за шагом представлен в табл. 6.15, где черточками отмечены освобождающиеся ячейки, занимаемые новыми информационными символами.
Процесс формирования кодовой комбинации шаг за шагом представлен в табл. 6.15, где черточками отмечены освобождающиеся ячейки, занимаемые новыми информационными символами.
Таблица 6.15.
 С помощью схем второго типа вычисляют значения проверочных символов как линейную комбинацию информационных символов, т. е они построены на использовании основного свойства систематических кодов Кодирующее устройство строится на основе k-разрядного регистра сдвига (рис 6.16) Выходы ячеек памяти подключаются к сумматору в цепи обратной связи в соответствии с видом генераторного многочлена
С помощью схем второго типа вычисляют значения проверочных символов как линейную комбинацию информационных символов, т. е они построены на использовании основного свойства систематических кодов Кодирующее устройство строится на основе k-разрядного регистра сдвига (рис 6.16) Выходы ячеек памяти подключаются к сумматору в цепи обратной связи в соответствии с видом генераторного многочлена
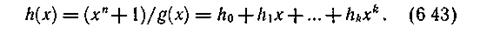
В исходном положении ключ Κ1 находится в положении 1. За первые k тактов поступающие на вход информационные символы заполняют все ячейки регистра. После этого ключ переводят в положение 2. На каждом из последующих тактов один из информационных символов выдается в канал связи и одновременно формируется проверочный символ, который записывается в последнюю ячейку регистра. Через n — k тактов процесс формирования проверочных символов заканчивается и ключ Κ1 снова переводится в положение 1.
В течение последующих k тактов содержимое регистра выдается в канал связи с одновременным заполнением ячеек новой последовательности информационных символов.
Пример 6.17. Рассмотрим процесс формирования кодовой комбинации с использованием генераторного многочлена для случая g(x) = = х3 + х2 + 1 и а(х) = =х3+1
Определяем генераторный многочлен.
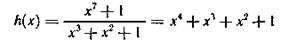
 Соответствующая h(x) схема кодирующего устройства приведена на рис. 6.17. Формирование кодовой комбинации поясняется табл. 6.16. Оно начинается после заполнения регистра информационными символами.
Соответствующая h(x) схема кодирующего устройства приведена на рис. 6.17. Формирование кодовой комбинации поясняется табл. 6.16. Оно начинается после заполнения регистра информационными символами.
Таблица 6.16
Декодирующие устройства. Декодирование комбинаций циклического кода можно проводить различными методами. Существуют методы, основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода.
Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f(x), соответствующего принятой комбинации, на образующий многочлен кода go(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Декодирующие устройства для кодов, обнаруживающих ошибки, по существу ничем не отличаются от схем кодирующих устройств. В них добавляется лишь буферный регистр для хранения принятого сообщения на время проведения операции деления. Если остатка не обнаружено (случай отсутствия ошибки), то
информация с буферного регистра считывается в дешифратор сообщения. Если остаток обнаружен (случай наличия ошибки), то информация в буферном регистре уничтожается и на передающую сторону посылается импульс запроса повторной передачи.
 В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 6.18.
В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 6.18.
Символы подлежащей декодированию кодовой комбинации, возможно, содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в n-разрядный буферный регистр сдвига и одновременно в схему деления, где за n тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистр второй аналогичной схемы деления.
Начиная с (n + 1)-го такта в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется новый остаток (синдром). Детектор ошибок, контролирующий состояния ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы («выделенные синдромы»), которые появляются в схеме деления, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. При последующем сдвиге детектор формирует сигнал «1», который, воздействуя на сумматор коррекции, исправляет искаженный символ.
Одновременно по цепи обратной связи с выхода детектора подается сигнал «1» на входной сумматор регистра второй схемы деления. Этот сигнал изменяет выделенный синдром так, чтобы он снова соответствовал более простому типу ошибки, которую еще подлежит исправить. Продолжая сдвиги, обнаружим и другие выделенные синдромы. После исправления последней ошибки все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Для декодирования кодовых комбинаций, разнесенных во времени, достаточно одной схемы деления, осуществляющей декодирование за 2n тактов.
Сложность детектора ошибок зависит от числа выделенных синдромом. Простейшие детекторы получаются при реализации кодов, рассчитанных на исправление единичных ошибок.
Выделенный синдром появляется в схеме деления раньше всего в случае, когда ошибка имеет место в старшем разряде кодовой комбинации, так как он первым достигает крайней правой ячейки буферного регистра. Поскольку неискаженная кодовая комбинация делится на g0(x) без остатка, то для определения выделенного синдрома достаточно разделить на g0(x) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на n-м такте, и является искомым выделенным синдромом.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки (опознаватели соответствующих векторов ошибок). Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В качестве схем деления в декодирующем устройстве могут быть использованы как схемы, определяющие остаток за n тактов (см. рис. 6.12), так и схемы, определяющие остаток за k тактов (рис. 6.14). При использовании схемы деления за k тактов векторам одиночных ошибок ξ(x) будут соответствовать другие остатки на n-м такте, являющиеся результатом деления на образующий многочлен кода векторов ξ(x)xm, а не ξ(x). Поэтому выделенные синдромы, а следовательно, и детекторы ошибок для указанных схем будут различны.
Пример 6.18. Рассмотрим процесс исправления единичной ошибки при использовании кода (7,4) с образующим многочленом g(x) = х3 + x2 + 1 и применении в декодирующем устройстве схем деления за n и k тактов.
Определим опознаватели ошибок и выделенный синдром для случая использования схемы деления за n тактов:
Дата публикования: 2015-11-01; Прочитано: 1084 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
