 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Определение Data Mining
|
|
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно не справляется с возникшими проблемами. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (типа средней температуры пациентов в больнице, средней высоты дома на улице и т.п.).
В основу Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей.
Примеры заданий на такой поиск при использовании Data Mining приведены в таблице.
Таблица. Примеры формулировок задач при использовании методов OLAP и Data Mining
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих | Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании) | Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании |
| Какова средняя величина ежегодных покупок по украденной и не украденной кредитной карточке | Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными картами |
Сформулируем еще несколько вопросов, на которые способная дать ответ технология Data Mining:
· · Какие товары предлагать данному покупателю?
· · Какова вероятность того, что данный сектор потенциальных клиентов отреагирует на рекламную кампанию?
· · Можно ли выработать оптимальную стратегию игры на бирже?
· · Можно ли выдать кредит данному клиенту банка?
· · Какой диагноз поставить данному пациенту?
· · Как прогнозировать пиковые нагрузки в телефонных или энергетических сетях?
· · В чем причины брака в производственной продукции?
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющих так называемые скрытые знания (hidden knowledge). К обществу пришло понимание того, что сырые данные (raw data) содержат глубинные пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки.
Существует множество определений Data Mining, но в целом они совпадают в выделении 4-х основных признаков. Вот определение, которое дал Григорий Пиатецкий-Шапиро (G. Piatetsky-Shapiro, GTE Labs.), один из ведущих мировых экспертов в области Data Mining:
Data Mining - это процесс обнаружения в сырых данных
· · ранее неизвестных,
· · нетривиальных,
· · практически полезных,
· · доступных интерпретации знаний (закономерностей), необходимых для принятия решений в различных сферах человеческой деятельности.
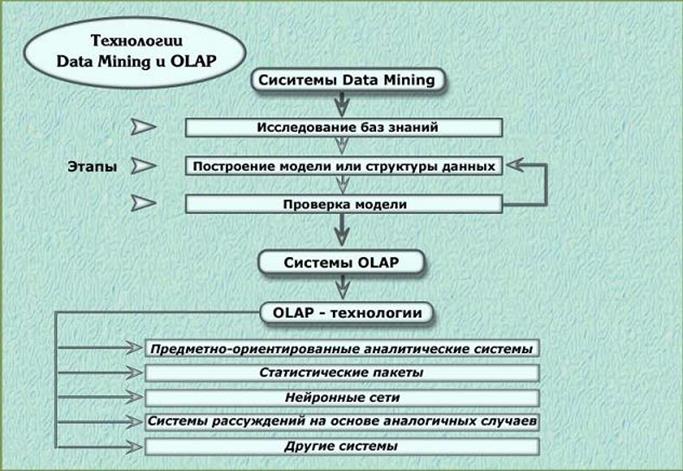
Нахождение скрытых закономерностей в данных, взаимосвязей между различными переменными в базах данных, моделирование и изучение сложных систем на основе истории их поведения - вот предмет и задачи Data Mining.
Результаты Data Mining - эмпирические модели, классификационные правила, выделенные кластеры и т.д. - можно затем инкорпорировать в существующие системы поддержки принятия решений и использовать их для прогноза будущих ситуаций.
Дата публикования: 2015-10-09; Прочитано: 864 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
