 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Мал. 2. Форма даних списку
|
|
I.8.3.Сортування записів списку.
Для забезпечення пошуку й аналізу даних у списках роблять упорядкування його записів за якими-небудь полями.
Операція перестановки записів у певному порядку називається сортуванням. В Excel сортування виконується командою Сортировка з меню Данные, яка дозволяє впорядковувати записи виділеного діапазону по даним одного, двох або трьох полів списку.
При сортуванні вважається, що кожний запис складається із двох частин: ключа й даних. Упорядкування даних проводиться у відповідності зі значенням ключа. Воно може бути або в зростаючому, або в убутному порядку його значень.
При багаторівневому сортуванні дані впорядковуються спочатку по першому ключу. Якщо при цьому утворяться групи записів з однаковими значенням у ключовому полі, то усередині кожної групи проводиться сортування по другому ключу, а потім усередині кожної підгрупи з відповідними значеннями другого ключа може виконуватися сортування по третьому ключу.
Якщо необхідно відсортувати весь список досить установити табличний курсор у будь-яку клітку списку (тобто немає необхідності виділяти весь список) і подати команду Сортировка.
I.8.4.Використання фільтра при обробці списку.
Відфільтрувати список - значить сховати всі записи за винятком тих, які задовольняють заданим умовам відбору. Excel надає для цього дві команди: Автофильтр для простих умов відбору, й Расширенный фильтр для більше складних критеріїв.
Перед використанням команди Автофильтр необхідно встановити курсор у будь-яку чарунку списку. Потім вибрати цю команду в підменю Фильтр з меню Данные. Excel виведе кнопки зі стрілками поруч із кожним заголовком стовпця. Щиглик на кнопці зі стрілкою поруч із заголовком стовпця розкриває список значень, які можна використати для умови відбору.

Мал. 3. Приклад використання автофільтру
Припустимо, що зі списку студентів, необхідно вибрати записи, що містять дані про студентів хімічного факультету. Для цього в списку автофільтра стовпця Факультет, що розкрився, досить вибрати хімічний (мал. 3).
В результаті
У цьому випадку використана тільки одна умова відбору.
У вікні «Пользовательский автофильтр» можна задати умови відбору із застосуванням будь-яких операторів порівняння. Для цього в списку, що розкрився, необхідно вибрати пункт Условие. З'явиться вікно діалогу «Пользовательский автофильтр» (малюнок 4).

Мал. 4. Вікно діалогу «Пользовательский автофильтр»
У вікні можна ввести одне або дві умови відбору й вибрати будь-який оператор порівняння. Припустимо, що зі списку потрібно вибрати записи, що містять дані про студентів, які народилися в 1979-1982 роках. Для цього необідно заповнити поля у вікні «Пользовательский автофильтр» як показано на малюнку 4.
Контрольні питання:
1. Що таке список?
2. Які засоби для заповнення списку ви знаєте?
3. Що таке фідфільтрувати список?
4. Як застосовується Автофільтр?
Лекція №7.
I.9 Апроксимація експериментальних даних
План лекції:
1. Інтерпретація експериментальних даних.
2. Наближення експериментальних даних аналітичною залежністю.
3. Графічна інтерпретація апроксимації.
4. Вибір найбільш відповідної лінії тренда для даних.
5. Апроксимація даних в середовищі Excel
I.9.1.Інтерпретація експериментальних даних
 |
Під експериментальними даними розуміється якийсь набір вимірювань, що є результатом досліду. Так, наприклад ви стоїте на виході з метро і рахуєте число людей, що проходять мимо вас за кожну хвилину. Допустимо, в результаті у вас вийшли наступні вимірювання: 45,23,55,87,53,48,61... Узагальнивши вимірювання у вигляді гістограми (Мал.1.), ви отримуєте деякий розподіл:
Мал. 1.
Для експериментатора може бути цікаво зрозуміти, чи не може даний розподіл бути описано деякою аналітичною формулою.
Інакше кажучи, визначити природу процесу: з якою вірогідністю можна чекати виходу певного числа людей в довільному вимірюванні, середнє число людей, що виходять з метро, найбільш вірогідне і так далі.
У вас може виникнути питання, навіщо такі складнощі, якщо всі ці питання можна зняти прямим вимірюванням. Тобто хай перед нами стоїть завдання визначити, скільки людей проходить за 8 годин через вихід за робочий день. Так, можна стояти все ці вісім годин і старанно записувати кожну окрему людину.
Проте аналізуючи результати півгодинного досвіду, в перебігу якого ви заміряли число чоловік за хвилину, ви маєте іншу можливість вирішити поставлену задачу. Допустимо, ви припускаєте, що даний розподіл (вірогідність виходу певного числа людей в хвилину) описується певною формулою, перевіряєте свою гіпотезу, переконуєтеся, що вона більш-менш достовірна. Формула дає вам середнє значення розподілу. Вам стало відоме середнє число людей в хвилину - досить помножити його на число хвилин у восьми годинниках для отримання результату. Більш того, ви також можете оцінити помилку ваших розрахунків, оскільки мається на увазі короткочасне (неповне) вимірювання, що очевидно містить деяку невизначеність результату порівняно з абсолютно точним вимірюванням, тобто формула також може дати точність оцінки, наприклад:
Число чоловік в хвилину = 47 ± 5;
де 5 - точність оцінки за хвилину, або приблизно 10%. З такою ж точністю можна буде визначити число людей за вісім годин:
Число чоловік за 8 годин = (47 ± 5)´(8´60) = 22560 ± 2400;
В деяких випадках апроксимацію даних називають " сплайном ". Дане найменування можна зустріти в таких популярних програмах, як Excel, в якому можна спробувати виконати згладжування (splain) залежності, наприклад поліномом ступеня від 2 до 6.
I.9.2.Наближення експериментальних даних аналітичною залежністю.
Апроксимація (від латинського "approximate" -"приближатися") - наближений вираз яких-небудь математичних об'єктів (наприклад, чисел або функцій) через інших простіші, зручніші в користуванні або просто відоміші. У наукових дослідженнях апроксимація застосовується для опису, аналізу, узагальнення і подальшого використання емпіричних результатів.
Як відомо, між величинами може існувати точний (функціональна) зв'язок, коли одному значенню аргументу відповідає одне певне значення, і менш точний (кореляційна) зв'язок, коли одному конкретному значенню аргументу відповідає наближене значення або деяка безліч значень функції, в тому або іншому ступені близьких один до одного. При веденні наукових досліджень, обробці результатів спостереження або експерименту зазвичай доводитися стикатися з другим варіантом. При вивченні кількісних залежностей різних показників, значення яких визначаються емпірично, як правило, є деяка їх вариабельность. Частково вона задається неоднорідністю самих об'єктів неживої, що вивчаються, і, особливо, живої природи, частково обуславливается погрішністю спостереження і кількісній обробці матеріалів. Останню складову не завжди вдається виключити повністю, можна лише мінімізувати її ретельним вибором адекватного методу дослідження і акуратністю роботи. Тому при виконанні будь-якої науково-дослідної роботи виникає проблема виявлення справжнього характеру залежності показників, що вивчаються, цій або іншому ступеню замаскованих неучтенностью вариабельности значень. Для цього і застосовується апроксимація - наближений опис кореляційної залежності змінних відповідним рівнянням функціональної залежності, що передає основну тенденцію залежності (або її "тренд").
При виборі апроксимації слід виходити з конкретного завдання дослідження. Зазвичай, чим простіше рівняння використовується для апроксимації, тим більше приблизний отримуваний опис залежності. Тому важливо прочитувати, наскільки істотні і чим обумовлені відхилення конкретних значень від отримуваного тренда. При описі залежності емпірично певних значень можна добитися і набагато більшої точності, використовуючи яке-небудь складніше, багатопараметричне рівняння. Проте немає ніякого сенсу прагнути з максимальною точністю передати випадкові відхилення величин в конкретних рядах емпіричних даних. Набагато важливіше уловити загальну закономірність, яка в даному випадку найлогічніше і з прийнятною точністю виражається саме двохпараметричним рівнянням степеневої функції. Таким чином, вибираючи метод апроксимації, дослідник завжди йде на компроміс: вирішує, в якому ступені в даному випадку доцільно і доречно "пожертвувати" деталями і, відповідно, наскільки узагальнено слід виразити залежність змінних, що зіставляються.
I.9.3.Графічна інтерпретація апроксимації.
З курсу математики відомо 3 способи завдання функціональних залежностей:
- аналітичний
- графічний
- табличний
Табличний спосіб зазвичай виникає в результаті эксперемента.
Недолік табличного задання функції полягає в тому, що знайдуться значення змінних які невизначені таблицею. Для відшукання таких значень визначають ту, що наближається до заданої функцію, званою аппроксмиющою, а дія заміни апроксимацією.
У інженерній діяльності часто виникає необхідність описати у вигляді функціональної залежності зв'язок між величинами, заданими табличний або у вигляді набору точок з координатами (xi,yi), i=0,1,2...n, де n - загальна кількість точок(Мал.3.). Як правило, ці табличні дані отримані експериментально і мають погрішності. При апроксимації бажано отримати відносно просту функціональну залежність (наприклад, поліном), яка дозволила б "згладити" експериментальні погрішності, набути проміжних і екстраполяційних значень функцій, що спочатку не містяться в початковій табличній інформації.
Взагалі апроксимація - це наближення. т. е треба знайти рівняння такої лінії, яка щонайкраще описує залежність у(х). Часто застосовується як критерій близькості отриманої функції до наявних даних сума квадратів відхилень теоретичних значень у від емпіричних (досвідчених), тоді можна застосувати метод найменших квадратів. подивися в пошукачі що це таке і формули для різних ліній сама. розрахунок зводиться до знаходження сум х, у, ху, х

Мал.3.
Ця функціональна (аналітична) залежність повинна з достатньою точністю відповідати початковій табличній залежності. Критерієм точності або достатньо "хорошого" наближення можуть служити декілька умов.
Позначимо через fі значення, обчислене з функціональної залежності для x=xі і що зіставляється з yі.
Одна з умов узгодження можна записати як
S = (fі-yі) ® min
тобто сума відхилень табличних і функціональних значень для однакових x=xі має бути мінімальною (метод середніх). Відхилення можуть мати різні знаки, тому достатня точність у ряді випадків не досягається.
Використання критерію S = |fі-yі| ® min, також не прийнятно, оскільки абсолютне значення не має похідної в точці мінімуму.
Враховуючи вищевикладене, використовують критерій найменших квадратів, тобто визначають таку функціональну залежність, при якій S = (fі-yі)2 ® min звертається в мінімум.
I.9.4.Вибір найбільш відповідної лінії тренда для даних
Лінія тренда - графічне представлення напряму зміни ряду даних. Лінії тренда дозволяють графічно відображати тенденції даних і прогнозувати дані. Використовування лінії тренда того або іншого вигляду визначається типом даних.
Лінія тренда найбільшою мірою наближається до представленої на діаграмі залежності, якщо значення R - квадрат - точність апроксимації рівне або близьке до 1. Значення R в квадраті - число від 0 до 1, яке відображає близькість значень лінії тренда до фактичних даних. Воно також називається квадратом змішаної кореляції. Лінія тренда найбільш відповідає дійсності, коли значення R в квадраті близько до 1. При апроксимації даних за допомогою лінії тренда значення R-квадрат розраховується автоматично. (При підборі лінії тренда до даних Excel автоматично розраховує значення критерію R2). Отриманий результат можна вивести на діаграмі.
Існує шість різних видів ліній тренда (апроксимація і згладжування), які можуть бути додані на діаграму Microsoft Excel. Спосіб слід вибирати залежно від типу даних.
Лінійна апроксимація — це пряма лінія, що щонайкраще описує набір даних. Вона застосовується в найпростіших випадках, коли точки даних розташовані близько до прямої. Кажучи іншими словами, лінійна апроксимація хороша для величини, яка збільшується або убуває з постійною швидкістю.
У наступному прикладі пряма лінія описує стабільне зростання продажів холодильників впродовж 13 років. Звернете увагу, що значення R-квадрат = 0,9036, тобто близько до одиниці, що свідчить про хороший збіг розрахункової лінії з даними.

Логарифмічна апроксимація добре описує величину, яка спочатку швидко росте або убуває, а потім поступово стабілізується. Описує як позитивні, так і негативні величини.
У наступному прикладі логарифмічна крива описує прогнозоване зростання популяції тварин, що мешкають в ареалі з фіксованими межами. Швидкість росту популяції падає із-за обмеженості їх життєвого простору. Крива досить добре описує дані, оскільки значення R-квадрат, рівне 0,9407, близько до одиниці.

Поліноміальна апроксимація використовується для опису величин, що поперемінно зростають і убувають. Вона корисна, наприклад, для аналізу великого набору даних про нестабільну величину. Ступінь полінома визначається кількістю екстремумів (максимумів і мінімумів) кривої. Поліном другого ступеня може описати тільки один максимум або мінімум. Поліном третього ступеня має один або два екстремуми. Поліном четвертого ступеня може мати не більше трьох екстремумів.
У наступному прикладі поліном другого ступеня (один максимум) описує залежність витрати бензину від швидкості автомобіля. Близьке до одиниці значення R-квадрат = 0,9474 свідчить про хороший збіг кривої з даними.

Степеневе наближення дає добрі результати, якщо залежність, яка міститься в даних, характеризується постійною швидкістю росту. Прикладом такої залежності може служити графік прискорення автомобіля. Якщо в даних є нульові або негативні значення, використання статечного наближення неможливе.
У наступному прикладі показана залежність пройденого автомобілем відстані, що розгониться, від часу. Відстань виражена в метрах, час — в секундах. Ці дані точно описуються степеневою залежністю, про що свідчить дуже близьке до одиниці значення R-квадрат, рівне 0,9923.

Експоненціальне наближення слід використовувати в тому випадку, якщо швидкість зміни даних безперервно зростає. Проте для даних, які містять нульові або негативні значення, цей вид наближення непридатний.
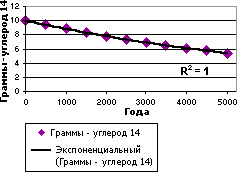
У наступному прикладі експоненціальна лінія тренда описує зміст радіоактивного вуглецю-14 залежно від віку органічного об'єкту. Значення R-квадрат рівне 1, що означає повний збіг кривої з даними, що апроксимуються.
Ковзаюче середнє. Використання як наближення ковзаючого середнього дозволяє згладити коливання даних і таким чином наочніше показати характер залежності. Така лінія тренда будується по певному числу точок (воно задається параметром Крок). Елементи даних усереднюються, і отриманий результат використовується як середнє значення для наближення. Так, якщо Крок дорівнює 2, перша точка згладжуючої кривої визначається як середнє значення перших двох елементів даних, друга крапка — як середнє наступних двох елементів і так далі.
У наступному прикладі показана залежність числа продажів впродовж 26 тижнів, отримана шляхом розрахунку ковзаючого середнього.

I.9.5.Апроксимація даних в середовищі Excel
Розглянемо поліноміальну апроксимацію. Це означає, що наше завдання полягає в тому, що, спираючись на початкові дані (функція і відрізок), необхідно знайти такий поліном, відхилення лінії якого від графіка початкової функції буде мінімальним.
Найбільш популярним методом поліноміальної апроксимації є метод найменших вадратів. У Excel він реалізується за допомогою діаграми і лінії тренда.
Розберемо даний метод в Excel.
Початкові дані:
| x | -1 | -0,848 | -0,414 | 0,235 | 1,765 | 2,414 | 2,848 | ||
| f(x) | 3,412 | 3,111 | 2,415 | 1,877 | 1,914 | 2,323 | 2,801 | 3,157 | 3,287 |
Введемо дані на робочий лист:

За допомогою Майстра діаграм будуємо точкову діаграму, виходячи з даних стовпців x і f(x).

Мал.3.
Тепер через контекстне меню на точках ряду вибираємо Додати лінію тренда:

Мал.3.
Вибираємо Тип - поліноміальну і степінь - 2:

і на вкладці Параметри встановлюємо необхідний прапорець для того, щоб показати рівняння на діаграмі

Отримуємо лінію тренду, її рівняння і значення коефіціїнта r2 = 0,9429.

Найбільш надійна лінія тренда, для якої значення R2 (коефіцієнт надійності) рівно або близько до 1.
Проводячи регресійний аналіз, Microsoft Excel обчислює для кожної точки квадрат різниці між прогнозованим значенням Y і фактичним значенням Y. Сума цих квадратів різниць називається залишковою сумою квадратів (ssresid). Потім Microsoft Excel підраховує загальну суму квадратів (sstotal). Якщо const = TRUE або значення const не вказано, загальна сума квадратів буде рівна сумі квадратів різниць дійсних значень Y і середніх значень Y. При const = FALSE загальна сума квадратів буде рівна сумі квадратівдійсних значень Y (без віднімання середнього значення Y з приватного значення Y). Після цього регресійну суму квадратів можна обчислити так: ssreg = sstotal - ssresid. Чимменше залишкова сума квадратів, тим більше значення коефіцієнта детермінованості r2, який показує, наскільки добре рівняння, отримане за допомогою регресійного аналізу, пояснює взаємозв'язки між змінними. Коефіцієнт r2 рівний ssreg/sstotal.
Контрольні питання:
1. Що таке експериментальні дані?
2. Наближення експериментальних даних аналітичною залежністю.
3. Графічна інтерпретація апроксимації.
4. Вибір найбільш відповідної лінії тренда для даних.
5. Апроксимація даних в середовищі Excel
Дата публикования: 2015-09-18; Прочитано: 931 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
