 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Критерий стохастической независимости Аббе
|
|
Если выборка xi, i =  принадлежит нормальной генеральной совокупности, то для выяснения вопроса о ее случайности предпочтительнее воспользоваться критерием квадратов последовательных разностей (критерий Аббе) /1/.
принадлежит нормальной генеральной совокупности, то для выяснения вопроса о ее случайности предпочтительнее воспользоваться критерием квадратов последовательных разностей (критерий Аббе) /1/.
 Критерий Аббе позволяет обнаружить систематическое смещение среднего в ходе выборочного обследования.
Критерий Аббе позволяет обнаружить систематическое смещение среднего в ходе выборочного обследования.
1-й шаг. Формулирование основной и альтернативной гипотез:
Н0: элементы выборки xi, i = являются стохастически независимыми,
H1: элементы выборки не являются стохастически независимыми.
2-й шаг. Задание уровня значимости a.
3-й шаг. Формирование критической статистики
 кр = кр =  , ,
| (54) |
где
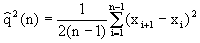 , ,
| (55) |
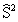 – несмещенная оценка дисперсии выборки.
– несмещенная оценка дисперсии выборки.
При n Ј 60 предельное распределение критической статистики 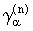 затабулировано и представлено в таблицах критических точек распределения Аббе /13/ для различных значений a.
затабулировано и представлено в таблицах критических точек распределения Аббе /13/ для различных значений a.
4-й шаг. Определение нижней критической точки осуществляется двумя способами (критерий Аббе – односторонний).
Если n > 60, то
кр.н =  , ,
| (56) |
где  – квантиль стандартного нормального распределения.
– квантиль стандартного нормального распределения.
При n £ 60 кр.н находится по статистическим таблицам /13, табл. 1.9/.
5-й шаг. Вычисление расчетного значения критической статистики
расч =  .
.
Если расч > кр.н, то гипотеза о стохастической независимости элементов выборки принимается. В противном случае элементы выборки нельзя считать случайными и независимыми.
15. Критерии проверки гипотезы о согласии эмпирического и теоретического распределений. Критерии согласия c2 – Пирсона и Колмогорова-Смирнова. Применимость критериев.
Критерий согласия c 2-Пирсона
Критерий согласия c2-Пирсона позволяет осуществлять проверку гипотезы о согласии, когда параметры модели неизвестны /1, 11, 15/.
Неизвестные параметры модели могут быть заменены в модели их оценками, полученными по выборке, например по методу моментов или методу максимального правдоподобия.
Критерий согласия c2-Пирсона применим при n ³ 200 и требует группирования выборки. При этом число интервалов группирования должно удовлетворять условию L ³ 8, а количество попаданий в каждый интервал mj должно быть не менее 7-10. В противном случае соседние интервалы необходимо объединить в один, не забывая при этом скорректировать L.
Рассмотрим последовательность критерия согласия c2–Пирсона.
1-й шаг. Формирование основной и альтернативной гипотез
Н0:  = Fmod(Х;
= Fmod(Х;  ),
),
Н1: ¹ Fmod(Х; ).
2-й шаг. Задание уровня значимости a.
3-й шаг. Формирование критической статистики
кр. =  , ,
| (57) |
где mj ,  – количество попаданий в каждый j-ый интервал группирования, pj – теоретическая вероятность попадания в j-ый интервал
– количество попаданий в каждый j-ый интервал группирования, pj – теоретическая вероятность попадания в j-ый интервал
pj = Fmod(хj+1;  ) - Fmod(хj; ). ) - Fmod(хj; ).
| (58) |
Здесь хj+1 и хj – соответственно верхняя и нижняя границы текущего интервала группирования.
Предельное распределение статистики кр при n®¥ имеет вид
  , ,
| (59) |
где S – количество параметров модельного распределения, согласие с которым проверяется, а c2( кр; L - S -1) – функция хи-квадрат распределения с (L - S - 1) числом степеней свободы.
4-й шаг. Определение верхней и нижней критических точек по таблице процентных точек c2-распределения:
кр.в. = c2a/2×100% (L - S - 1),
кр.н. = c2(1-a/2)×100% (L - S - 1).
5-й шаг. Определение расчетного значения критической статистики
| расч = .
| (60) |
Если выполняется условие
| c2(1-a/2) ×100% (L - S - 1) < расч < c2a/2×100% (L - S - 1),
| (61) |
то гипотеза о согласии Н0 верна с ошибкой первого рода a. В противном случае гипотеза Н0 отвергается.
Отвержение гипотезы Н0 при расч. < c2a/2×100% (L - S - 1) на первый взгляд противоречит здравому смыслу /1/. Однако, надо отметить, что расч как статистика также является случайной величиной со своей дисперсией. А значит, одинаково неправдоподобными можно считать как слишком большие, так и слишком малые расч.
Причинами возникновения слишком малых расч могут быть как неудачный выбор Fmod(Х; ) (например, при искусственном завышении числа параметров модели), так и некорректное проведение эксперимента при деформировании выборки, например, стремление "подогнать" искусственно эмпирические данные под результат. Критерий согласия c 2-Пирсона
Критерий согласия c2-Пирсона позволяет осуществлять проверку гипотезы о согласии, когда параметры модели неизвестны /1, 11, 15/.
Неизвестные параметры модели могут быть заменены в модели их оценками, полученными по выборке, например по методу моментов или методу максимального правдоподобия.
Критерий согласия c2-Пирсона применим при n ³ 200 и требует группирования выборки. При этом число интервалов группирования должно удовлетворять условию L ³ 8, а количество попаданий в каждый интервал mj должно быть не менее 7-10. В противном случае соседние интервалы необходимо объединить в один, не забывая при этом скорректировать L.
Рассмотрим последовательность критерия согласия c2–Пирсона.
1-й шаг. Формирование основной и альтернативной гипотез
Н0: = Fmod(Х; ),
Н1: ¹ Fmod(Х; ).
2-й шаг. Задание уровня значимости a.
3-й шаг. Формирование критической статистики
| кр. = ,
| (57) |
где mj , – количество попаданий в каждый j-ый интервал группирования, pj – теоретическая вероятность попадания в j-ый интервал
| pj = Fmod(хj+1; ) - Fmod(хj; ).
| (58) |
Здесь хj+1 и хj – соответственно верхняя и нижняя границы текущего интервала группирования.
Предельное распределение статистики кр при n®¥ имеет вид
| ,
| (59) |
где S – количество параметров модельного распределения, согласие с которым проверяется, а c2( кр; L - S -1) – функция хи-квадрат распределения с (L - S - 1) числом степеней свободы.
4-й шаг. Определение верхней и нижней критических точек по таблице процентных точек c2-распределения:
кр.в. = c2a/2×100% (L - S - 1),
кр.н. = c2(1-a/2)×100% (L - S - 1).
5-й шаг. Определение расчетного значения критической статистики
| расч = .
| (60) |
Если выполняется условие
| c2(1-a/2) ×100% (L - S - 1) < расч < c2a/2×100% (L - S - 1),
| (61) |
то гипотеза о согласии Н0 верна с ошибкой первого рода a. В противном случае гипотеза Н0 отвергается.
Отвержение гипотезы Н0 при расч. < c2a/2×100% (L - S - 1) на первый взгляд противоречит здравому смыслу /1/. Однако, надо отметить, что расч как статистика также является случайной величиной со своей дисперсией. А значит, одинаково неправдоподобными можно считать как слишком большие, так и слишком малые расч.
Причинами возникновения слишком малых расч могут быть как неудачный выбор Fmod(Х; ) (например, при искусственном завышении числа параметров модели), так и некорректное проведение эксперимента при деформировании выборки, например, стремление "подогнать" искусственно эмпирические данные под результат.
Критерий согласия Колмогорова–Смирнова
Критерий согласия Колмогорова–Смирнова позволяет проверить гипотезу о согласии при небольшом объеме выборки, когда Fmod известна полностью, т.е. известны и параметры модели /1, 6, 12, 15/.
Рассмотрим последовательность критерия.
1-й шаг. Формирование основной и альтернативной гипотез
Н0: = Fmod(Х; ),
Н1: ¹ Fmod(Х; ).
2-й шаг. Задание уровня значимости a.
3-й шаг. Формирование критической статистики.
В критерии Колмогорова–Смирнова для введения меры отклонения эмпирического и модельного распределений используются статистики вида:
 ; ; 
| (62) |
Статистики вида  и
и 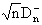 являются статистиками Колмогорова и Смирнова соответственно. При этом
являются статистиками Колмогорова и Смирнова соответственно. При этом
 .
.
Известны точные распределения статистик Dn, D+n и D-n /13/. Для практических целей обычно достаточно статистики Dn.
Поэтому в качестве кр. воспользуемся функцией вида
кр =  . .
| (63) |
А.Н. Колмогоров показал, что если функция Fmod(Х; ) непрерывна, то распределение кр имеет пределом функцию
 , ,
| (64) |
получившую название функции Колмогорова и не зависящую от вида функции Fmod(Х; ).
Однако, если Fmod(Х; ) задана с точностью до неизвестных параметров , и они оцениваются по выборке /1/, то предельное распределение статистики  уже зависит от Fmod(Х; ). При этом статистика кр будет зависеть только от формы распределения Fmod(Х; ). Если в модельном распределении есть только параметры сдвига и масштаба, то применимость критерия Колмогорова–Смирнова корректна.
уже зависит от Fmod(Х; ). При этом статистика кр будет зависеть только от формы распределения Fmod(Х; ). Если в модельном распределении есть только параметры сдвига и масштаба, то применимость критерия Колмогорова–Смирнова корректна.
4-й шаг. Из определения функции распределения следует, что при достаточно большом n и любом кр > 0 вероятность того, что примет значение не меньше кр, будет иметь вид

тогда  . .
| (65) |
Значение кр.в при заданном a можно найти с помощью таблицы функции Колмогорова–Смирнова (65).
Нижняя критическая граница в критерии Колмогорова не используется.
5-й шаг. расч определяется из выражения (63) подстановкой значений n и Dn для конкретных эмпирических данных. Если выполняется условие
расч < кр.в,
то гипотеза о согласии эмпирического распределения и модельного принимается.
Критерий согласия Колмогорова–Смирнова может использоваться и при большом объеме выборки. Для этого необходимо выборку представить в группированном виде и значения и Fmod(Х; ) определять на границах интервалов группирования.
16. Задачи корреляционного анализа. Типы измерителей статистической связи. Постановка задачи корреляционного анализа.
- выбор подходящего измерителя связи с учетом специфики и природы анализируемых переменных;
- точечное или интервальное оценивание измерителя связи по выборочным данным, полученным в результате эксперимента;
- проверка гипотезы о значимости (статистически значимом отличии значения корреляционной характеристики от нуля) анализируемого измерителя связи;
- анализ структуры связей между компонентами многомерного признака.
Все это задачи корреляционного анализа. В качестве измерителей степени тесноты парных связей между количественными переменными могут использоваться индекс корреляции, коэффициент корреляции (иногда используют термин “коэффициент корреляции Пирсона”), корреляционное отношение, частный коэффициент корреляции, применяемый для исследования частных или “очищенных” связей, освобожденных от опосредованного одновременного влияния на исследуемую парную связь других переменных.
Если статистическая информация о многомерном признаке представлена не в количественной, а в порядковой шкале, то измерение парных связей осуществляется посредствомранговых выборочных измерителей связи – коэффициентов корреляции Кендалла и Спирмэна.
Измерение степени тесноты множественной связи между количественными переменными возможно с помощью множественного коэффициента корреляции (иликоэффициента детерминации), а между порядковыми переменными – с помощью коэффициента конкордации.
При таком многообразии измерителей статистической связи важной становится задача выбора адекватного ее измерителя.
Применимость того или иного измерителя определяется как формой представления исходной статистической информации (количественные или порядковые признаки), так и формой связи (линейная, нелинейная). От грамотного выбора адекватного измерителя связи зависит достоверность статистических выводов, распространяемых на исследуемую многомерную генеральную совокупность.
Предварительный анализ структуры связи между компонентами исследуемого многомерного признака, представленного выборкой из генеральной совокупности, осуществляют с помощью корреляционных полей.
17. Понятие тесноты статистической связи между количественными переменными. Парный коэффициент корреляции.
Анализ статистических связей между количественными переменными
Оценивание парных статистических связей
Коэффициент корреляции. Свойства коэффициента корреляции
Пусть исследуется парная зависимость между случайными компонентами X и Y двумерного признака. Предположим, что в результате эксперимента получена выборка из двумерной нормальной генеральной совокупности. Степень тесноты статистической связи между двумя исследуемыми компонентами может быть измерена с помощью выборочного коэффициента корреляции /2,14/.

| (66) |
где 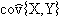 – оценка второго смешанного центрального момента случайной величины (X,Y).
– оценка второго смешанного центрального момента случайной величины (X,Y).
Формально коэффициент корреляции может быть вычислен для любой пары параметров многомерного признака. Однако он является адекватным измерителем степени тесноты лишь линейной статистической связи между анализируемыми признаками, независимо от тенденции связи. Необходимо отметить, что коэффициент корреляции имеет четкий смысл как характеристика степени тесноты связи только в случае совместной нормальной распределенности исследуемых случайных величин X и Y.
Свойства коэффициента корреляции. В общем случае коэффициент корреляции может принимать значения |r| 1. В частности, если |r| = 1 между исследуемыми признаками существует функциональная линейная зависимость. При r = -1 имеет место отрицательная линейная зависимость, при r = 1 – положительная. Если r = 0, то параметры X и Yнекоррелированы. Однако это вовсе не означает, что X и Y независимы, если априори допускается отклонение этой зависимости от линейной. Следовательно, некоррелированность не означает независимости исследуемой пары признаков. В то же время независимость всегда означает и некоррелированность X и Y. При r = 0 необходимо дополнительное статистическое исследование степени отклонения распределения рассматриваемых величин от нормального.
Коэффициент корреляции обладает свойством симметрии, т.е.
rX,Y = rY,X.
Для случая многомерного случайного признака  (р – размерность признака) статистический анализ всех парных связей может быть представлен корреляционной матрицей многомерного признака.
(р – размерность признака) статистический анализ всех парных связей может быть представлен корреляционной матрицей многомерного признака.
| x(1) | x(2) | ... | x(p) | |
| x(1) | 
| ... | 
| |
| x(2) | 
| ... | 
| |
| ... | ... | ... | ... | |
| x(p) | 
| 
| ... |
Запомните! Коэффициент корреляции как измеритель степени тесноты парной статистической связи имеет четкий смысл при линейной тенденции связи и совместной нормальной распределенности исследуемых пар параметров многомерного признака.
Парный коэффициент корреляции не учитывает опосредованного или совместного влияния других факторов.
18. Проверка гипотезы о статистической значимости линейной статистической связи. Интервальная оценка парного коэффициента корреляции.



19. Исследование нелинейной зависимости между количественными признаками. Корреляционное отношение.


20. Проверка гипотезы об отсутствии нелинейной корреляционной связи.


21. Ранговая корреляция. Методы ранговой корреляции.
Иногда при исследовании зависимостей имеет место ситуация, когда шкала количественного измерения степени проявления некоторого свойства (признака) отсутствует (неизвестна) или ее просто не может быть. Кроме того возможна ситуация, когда информация имеет условный характер и может быть использована только для ранжирования объектов.
Примерами таких процессов могут служить показатели эффективности функционирования различных социально-экономических систем, структура потребительского бюджета семьи, степень прогрессивности предлагаемого на конкурс проекта.
В подобных ситуациях вместо конкретных значений исследуемого признака используются его ранги.
Ранговая корреляция отражает статистическую связь между порядковыми переменными.
Исходный статистический материал представлен упорядочениями (ранжировками) n объектов по некоторым свойствам.
Методы ранговой корреляции основаны на использовании условной числовой метки, обозначающей место объекта в ряду всех анализируемых объектов, которые располагаются в порядке убывания исследуемого свойства. При этом под условной числовой меткой понимается ранг объекта по исследуемому признаку.
Последовательность рангов элементов вариационного ряда, указывающих на место объекта в ряду, называется ранжировкой.
Под ранговой корреляцией понимается статистическая связь между порядковыми переменными.
Существуют методы и измерители, позволяющие измерить и проанализировать статистическую парную и множественную связь между несколькими параметрами исследуемого многомерного объекта, если они представлены ранжировками.
22. Ранговые коэффициенты корреляции Спирмена и Кендалла.
Оценивание парных ранговых связей.
Ранговый коэффициент корреляции Спирмэна
Для измерения степени тесноты парной статистической связи между ранжировками К.Спирмэн в 1904 г. предложил показатель, который впоследствии получил название рангового коэффициента корреляции Спирмэна /2, 4, 12/
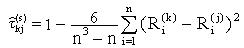
| (85) |
где Ri(k) и Ri(j) – i-е ранги соответственно параметров k и j. Выражение (85) справедливо при отсутствии в ранжировках групп объединенных рангов. Если такие группы есть, то  определяется из выражения
определяется из выражения

| (86) |
где Т(k) и Т(j) – поправочные коэффициенты, которые могут быть найдены из

| (87) |
ni(k) – количество элементов в группе неразличимых рангов, а m(k) – число групп неразличимых рангов.
Нетрудно убедиться, что при совпадающих ранжировках R(k)i = R(j)i  а при противоположных
а при противоположных 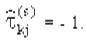 Во всех прочих случаях
Во всех прочих случаях  Если
Если  связь между компонентами отсутствует. Кроме того, очевидно, что ранговый коэффициент корреляции обладает свойством симметрии, т.е.
связь между компонентами отсутствует. Кроме того, очевидно, что ранговый коэффициент корреляции обладает свойством симметрии, т.е. 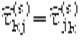 .
.
Пример:
Исследование зависимости между среднемесячными доходами на семью (в тыс. руб.) и расходами на покупку кондитерских изделий (в руб.) представлено таблицей.
Зависимость расходов семьи на покупку кондитерских изделий от среднемесячных доходов
| Доходы семьи (в тыс. руб.) U | 4.8 | 3.8 | 5.4 | 4.2 | 3.4 | 4.6 | 3.4 | 4.8 | 5.0 | 3.8 | 5.2 | 4.0 | 3.8 | 4.6 | 4.4 |
| Расходы на кондитерские изделия (в руб.), V |
Вычислим степень тесноты парной связи между доходами семьи и расходами на приобретение кондитерских изделий с помощью рангового коэффициента корреляции Спирмэна.
Составим вариационные ряды для U и V и расставим ранги.
Вариационный ряд для параметра U
| U | 3,4 | 3,4 | 3,8 | 3,8 | 3,8 | 4,0 | 4,2 | 4,4 | 4,6 | 4,6 | 4,8 | 4,8 | 5,0 | 5,2 | 5,4 |
| Ri(U) |
Вариационный ряд для параметра V
| V | |||||||||||||||
| Ri(V) |
В следующей таблице представлены ранжировки в соответствии с первоначальным положением элементов в исходной двумерной совокупности.
Ранжировки для параметров U и V
| Ri (U) | |||||||||||||||
| Ri(V) |
Поскольку в ранжировках есть группы объединенных рангов, то для вычисления необходимо воспользоваться выражениями (86) и (87).
Для ранжировки Ri(U) m(U) = 4, n1(U)= 2, n2(U) = 3, n3(U) = 2, n4(U) = 2.
Для ранжировки Ri(V) m(V) = 1, n1(V)= 3. Проведем вычисления
Т(U) = 1/12 [ (8 - 2) + (27 - 3) + (8 - 2) + (8 - 2) ] = 3.5,
Т(V) = 1/12 (27 - 3) = 2,

Следовательно можно предположить, что между доходами семьи и расходами на покупку кондитерских изделий существует сильная положительная связь.
Ранговый коэффициент корреляции Кендалла
Другим измерителем степени тесноты статистической связи между двумя ранжировками является ранговый коэффициент корреляции Кендалла /2, 4, 12/, определяемый выражением

| (88) |
где (Ri(k), Ri(j)) – минимальное число обменов последовательности Ri(j), необходимое для приведения ее к упорядочению, аналогичному Ri(k). Очевидно, что (Ri(k), Ri(j)) симметрична относительно своих аргументов.
При совпадающих ранжировках Ri(k) и Ri(j) обменов не будет, следовательно (Ri(k), Ri(j)) = 0 и 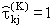 . Во всех других случаях для
. Во всех других случаях для  выполняется условие
выполняется условие  .
.
Выражение (88) справедливо при отсутствии в ранжировках групп объединенных рангов.
В противном случае необходимо воспользоваться формулой

| (89) |
где – оценка парного рангового коэффициента корреляции из выражения (88). Поправочные коэффициенты Т(k) и Т(j) определяются из выражения

| (90) |
где m(k) – количество групп объединенных рангов, ni(k) – количество элементов в группе. Свойства парного рангового коэффициента корреляции Кендалла аналогичны коэффициенту корреляции Спирмэна.
Необходимо заметить /2, 4, 12/, что вычисление является более трудоемким, чем . Статистические свойства рангового коэффициента корреляции Кендалла более исследованы. Кроме того, он обладает большими удобствами при его пересчете, если к n статистическим объектам добавляются новые. Между масштабами шкал, в которых измеряют и , нет простого соотношения. Но при умеренно больших n (n 10) и при условии, что абсолютные величины значений этих коэффициентов не слишком близки к единице, для них справедливо соотношение

Проверка статистически значимого отличия от нуля ранговых корреляционных характеристик может быть осуществлена при не слишком малых n (n 10) при заданном уровне значимости. Данный вопрос рассмотрен в /2, с.114/. Там же рассмотрена методика построения доверительных интервалов для и /2, с.116/.
ПРИМЕР:
Исследование зависимости между среднемесячными доходами на семью (в тыс. руб.) и расходами на покупку кондитерских изделий (в руб.) представлено таблицей.
Зависимость расходов семьи на покупку кондитерских
изделий от среднемесячных доходов
| Доходы семьи (в тыс. руб.) U | 4.8 | 3.8 | 5.4 | 4.2 | 3.4 | 4.6 | 3.4 | 4.8 | 5.0 | 3.8 | 5.2 | 4.0 | 3.8 | 4.6 | 4.4 |
| Расходы на кондитерские изделия (в руб.), V |
Вычислим парную ранговую связь между доходами семьи и расходами на кондитерские изделия с помощью коэффициента корреляции Кендалла.
Воспользуемся ранжировками, полученными в предыдущем примере для вычисления (Ri(U), Ri(V)). Для этого ранжировку Ri(U) сформируем в порядке возрастания, а Ri(V) – в соответствии с ранжировкой Ri(U). Данные сведем в таблицу.
Ранжировки U и V
| Ri (U) | |||||||||||||||
| Ri (V) |
Вычисление (Ri (U), Ri (V)) осуществляем следующим образом. Сравниваем во второй ранжировке последовательно каждый элемент, начиная с первого, со всеми последующими. Если предыдущий элемент больше последующего, то необходим обмен между этими элементами и, следовательно, i,j= 1. В противном случае i,j= 0. Индексы i,j означают соответственно порядковые номера сравниваемых рангов в ранжировке Ri(V).
Анализ степени согласованности двух ранжировок дает следующие результаты (см. предыдущую таблицу).
1,2 = 1,3 =1,4 = … = 1,15 = 0,
2,3 = 2,5 = 2,6 = 2,7 = … = 2,15 = 0, 2,4 = 1,
3,4 = 3,5 = 1, 3,6 = 3,7 = … = 3,15 = 0,
4,5 = 4,6 = … = 4,15 = 0, 5,6 = 5,7 = … = 5,15 = 0,
6,7 = 6,8 = … = 6,15 = 0, 7,8 = 1,
7,9 = 7,10 = … = 7,15 = 0, 8,9 = 8,10 = … = 8,15 = 0, 9,10 = 1,
9,11= 9,12 = … = 9,15 = 0, 10,11 = … = 10,15 = 0,
11,12 = … = 11,15 = 0, 12,13 = 12,14 = 12,15 = 0,
13,14 = 13,15 = 0, 14,15 = 0.
Следовательно, (R(U)i, R(V)i) = 5.
Тогда из (88) найдем

Поправочные коэффициенты из (90) равны

Получим  из (89)
из (89)

23. Ложная корреляция и частный коэффициент корреляции.
Ложная корреляция – это корреляция, которая возникла не в результате прямого соотношения между оцениваемыми переменными, а в результате их связей с третьей переменной (или четвертой, или более), при которой нет никакой связи, объединяющей эти переменные.
Частный коэффициент корреляции
Иногда в практических ситуациях не удается интерпретировать на содержательном уровне выявленную парную связь между исследуемыми компонентами признака. Причину этого часто следует искать в опосредованном влиянии на исследуемые показатели некоторого третьего фактора /2/. Роль опосредованно влияющих факторов могут играть множество неучтенных показателей. Следовательно, необходимо введение измерителей статистической связи, которые были бы очищены от такого влияния.
В качестве измерителя степени тесноты связи между переменными Х и Y при фиксированных значениях других переменных используются частные (“очищенные”) коэффициенты корреляции.
Пусть имеется многомерный нормальный вектор X
X = {x(1), x(2),..., x(p)},
где x(i) – компоненты вектора, p – его размерность. Необходимо определить частный коэффициент корреляции rij между x(i) и x(j) компонентами вектора при фиксированном множестве переменных x(i,j), дополняющих пару x(i) и x(j).
При данных условиях

| (82) |
где Rij. – алгебраическое дополнение для элемента rij в определителе корреляционной матрицы R анализируемых признаков x(i), т.е. в определителе

Выражение (82) при условии р = 3 будет иметь вид

| (83) |
Последовательно присоединяя к мешающим переменным все новые признаки из набора, можно получить рекуррентные соотношения для частных коэффициентов корреляции r12(3,4,…,k) порядка k (т.е. при k исключенных опосредованно влияющих параметров) по частным коэффициентам корреляции порядка k-2 (k = 1, 2, …, р-2)

| (84) |
Если условие нормальности вектора нарушается, то возникают проблемы, связанные с необходимостью учета фиксированного уровня значений мешающих переменных /2, с. 82-83/.
24. Множественная корреляция. Коэффициент конкордации.
Анализ множественных ранговых связей
Коэффициент конкордации
Свойства рассмотренных выше измерителей парных связей свидетельствует о том, что чем теснее связь, тем больше информации содержит одна переменная относительно другой. На практике бывает важно объяснить поведение одной переменной (отклика) поведением совокупности других. Для решения таких задач используются измерители степени тесноты множественной связи /2, 4. 12/.
Кендаллом был предложен показатель  , названный коэффициентом конкордации (согласованности), который вычисляется из выражения
, названный коэффициентом конкордации (согласованности), который вычисляется из выражения

| (91) |
где m – число одновременно анализируемых порядковых переменных, Ri(kj) – i-ый ранг отобранной для исследования порядковой переменной, kj,  – номер этой переменной в исследуемом многомерном признаке.
– номер этой переменной в исследуемом многомерном признаке.
Коэффициент конкордации обладает следующими свойствами:
- 0 1;
- =1 при условии, когда все m анализируемых упорядочений совпадают;
- коэффициент конкордации, вычисленный для двух переменных пропорционален парному ранговому коэффициенту корреляции Спирмэна
Выражение (91) справедливо для случая отсутствия групп объединенных рангов. Если это условие не выполняется, то вычисляется по формуле

| (92) |
где Т(kj) – поправочный коэффициент, который вводится для групп объединенных рангов и вычисляется из выражения (87).
25. Проверка гипотезы о статистической значимости выборочного коэффициента конкордации.
Для проверки статистической значимости выборочного значения коэффициента конкордации можно воспользоваться фактом приближенной 2(n-1) – распределенности величины m (n-1) /2/, которое справедливо в случае отсутствия связи в генеральной совокупности. Т.е. если окажется, что условие m (n-1) > 2100% (n-1) выполняется, то гипотеза об отсутствии ранговой множественной связи между компонентами многомерного признака должна быть отвергнута. Величина 2100% (n-1) - 100% – процентная точка 2-распределения и может быть найдена из таблицы приложения 3
ПРИМЕР
Для данных предыдушего примера проверим гипотезу о значимости ранговой множественной связи (коэффициента конкордации) при уровне значимости = 0.05. Воспользуемся логической схемой статистического критерия.
- Формулируем основную и альтернативную гипотезы
Н0: = 0,
Н1: 0.
- Задаем уровень значимости = 0.05.
- Выбираем вид критической статистики
кр = m (n – 1)
Известно, что в асимптотическом пределе и при слабой связи между компонентами распределения статистики, кр стремится к 2 -распределению с (n–1) числом степеней свободы.
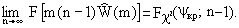
- Найдем верхнюю критическую точку
кр.в = 25% (17) = 27.587.
- Расчетное значение критической статистики получим, воспользовавшись данными предыдушего примера.
расч = 3(18-1)0.109 = 5.559.
Поскольку расч кр.в, то гипотеза об отсутствии множественной ранговой связи принимается. Следовательно, связь между стоимостью квартиры, ее удаленностью от районного центра и площадью в данном конкретном случае не является значимой.
Дата публикования: 2014-10-20; Прочитано: 1634 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
