 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Упрощение модели и выбор уровней детализации
|
|
При разработке модели ВС основной проблемой является правильный выбор уровня детализации (см разд. 1). ВС можно представить в виде одного элемента или разбить на отдельные функциональные устройства, блоки, узлы, логические элементы или радиоэлементы. В вычислительной технике выделяется несколько уровней детализации или моделирования. В качестве систем на нижнем уровне рассматриваются логические элементы (схемы И, ИЛИ), элементами которых служат диоды, транзисторы, сопротивления и т.п. Следующий уровень – системами являются цифровые устройства: регистры, сумматоры, дешифраторы и другие комбинационные схемы, элементы которых - логические схемы. На следующем уровне детализации системами являются отдельные функциональные устройства - процессоры, накопители, терминалы, контроллеры и т.п.
Наиболее широко исследуется системный уровень, на котором в качестве системы рассматривается ВС, а ее элементами считаются функциональные устройства. К этому же уровню относятся системы телеобработки данных, многопроцессорные и многомашинные ВС. Но они могут быть выделены и в самостоятельный уровень в зависимости от целей моделирования. Более высокий уровень моделирования – сеть ЭВМ. В качестве элементов здесь выступают отдельные ЭВМ. Наивысший уровень моделирования – совокупность сетей ЭВМ.
Выбор уровня моделирования зависит от объекта и цели моделирования.
При схемотехническом анализе и синтезе ВС на системном уровне целесообразно детализировать систему, выделяя функционально завершенные, конструктивно самостоятельные средства: процессоры, устройства ввода-вывода, ВЗУ и т.п. В модель могут включаться устройства, не имеющие физической связи с основными(УПД и др.), а также люди – операторы ЭВМ. При моделировании на системном уровне под заявкой понимается требование на выполнение одной программы, одного цикла выполнения программы по запросам пользователя.
В соответствии с конкретизацией понятия заявки выбирается уровень детализации данных: бит, байт, слово и т.д.
При выборе уровня детализации следует рассматривать возможности разработки последовательности моделей. Вначале создается модель первого порядка сложности, адекватная исследуемой ВС только в первом приближении. На основе результатов ее исследования строится модель второго порядка сложности, которая обладает более глубоким уровнем детализации, большим числом составляющих и параметров. Эта модель может быть модификацией первой или полностью отличаться от нее.
Может быть создана модель третьего порядка сложности и т.д. до тех пор, пока не будет получена модель, наиболее пригодная для достижения поставленных целей. Такой итерационный принцип построения моделей целесообразен при проектировании новых ВС и предполагает продвижение по стратам сверху вниз.
Проводится и обратное исследование моделей – снизу вверх: для функционального устройства, у которого слабо изучены зависимости выходных характеристик от входных воздействий, сначала строятся модели его элементов, затем модель устройства, с помощью которой определяют зависимости, впоследствии используемые для построения модели более высокого порядка сложности.
После решения вопроса об уровне детализации необходимо рассмотреть возможность расчленения ВС на подсистемы и создания самостоятельных моделей отдельных подсистем. Например, при создании модели вычислительной сети целесообразнее сначала создать и исследовать модели отдельных машин, а затем – модель всей системы, причем в модель каждая машина включается в виде одного элемента. Задача декомпозиции в общем случае не является тривиальной. Разделение систем можно производить по функциональной обособленности подсистем или по минимуму функциональных связей. Например, можно расчленить две подсистемы, связанные прямой связью, но нельзя членить подсистемы, имеющие прямые и обратные связи. При декомпозиции должно быть сохранено основное свойство системы – ее целостность. Применение принципа декомпозиции позволяет распараллеливать процесс моделирования системы. Основным критерием при использовании принципов последовательности и декомпозиции моделей является сокращение времени исследования модели при уменьшении числа составляющих.
2.1.2. Преобразование алгоритмов
При представлении алгоритма функционирования ВС целесообразно общий поток поступающих в систему заявок разделить на однородные потоки по характеру технологического процесса обработки данных, и, в первую очередь, последовательности использования ресурсов ВС по обслуживанию заявок, т.е. маршрута заявки. Дополнительно могут использоваться и другие критерии: интенсивность поступления заявок в систему, приоритеты и т.д.
Маршрут заявки определяется программой пользователя, программами систем управления вводом-выводом. Если в процессе моделирования имитируются все имеющиеся программы в чистом виде шаг за шагом - это будет натурный эксперимент. Для построения модели необходимо вместо программ использовать алгоритмы с той или иной степенью детализации.
При выборе уровня детализации алгоритма следует выделить операции обработки, ввода-вывода, команды перехода, обращения к другим программам, в том числе о операционной системе.
Наиболее сложная часть преобразования и представления алгоритма - определение трудоемкости выполнения отдельных блоков и вероятностей разветвления алгоритма.
При работе реальных программ условия переходов определяются на основе предшествующей обработки данных. При имитационном моделировании обработка данных не производится, а только отмечается факт обработки и фиксируется ее длительность. Поэтому в алгоритме для всех точек разветвления задаются вероятности перехода по каждому из возможных направлений. Необходимые для этого данные получают путем анализа программ и данных, или проводят экспертную оценку алгоритмов.
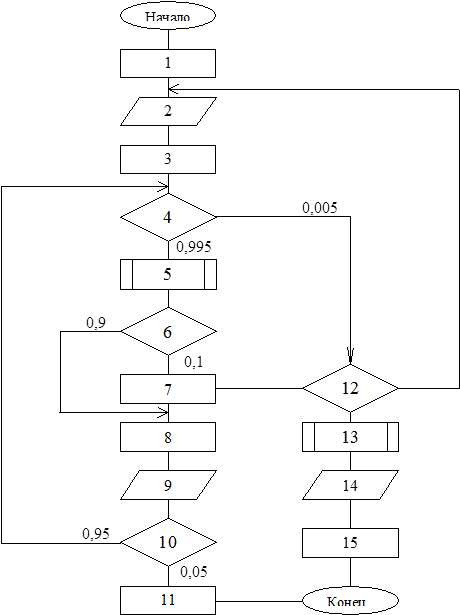
На этапе упрощения алгоритма укрупняют с целью уменьшения числа блоков, т.е. числа моделируемых операций. Упрощение выполняется путем исключения второстепенных блоков, включения вызываемой подпрограммы в соответствующий блок обработки данных, замены циклически повторяемых участков с известным числом повторений одним блоком обработки с пропорциональным увеличением длительности обслуживания, объединением в одной операции нескольких обращений к одному и тому же устройству ввода-вывода, исключением из алгоритма операций, длительность которых много меньше по сравнению с другими. В качестве примера рассмотрим алгоритм на рис. 2.1.
Так как вероятность перехода от блока 4 к блокам 12-15 мала, можно пренебречь этими блоками, включая и блок 4. В блоке вызова подпрограммы 5 учитывается трудоемкость выполнения подпрограммы, и проводится замена его блоком процессорной обработки, если нет ввода-вывода. Если трудоемкость выполнения блока 7 значительно меньше трудоемкости выполнения других блоков, то блоки 6 и 7 можно исключить с учетом небольшой вероятности выполнения блока 7.
В противном случае блоки 5-8 можно заменить одним блоком с известной трудоемкостью. С помощью блока 10 организован цикл из 19 повторений (0.95:0.05), его можно исключить, увеличив в 19 раз трудоемкость полученного ранее интегрального блока и блока 9. Затем можно слить интегральный блок и блок 3. Если можно пренебречь трудоемкостями выполнения начального и конечного блоков (1 и 11), то получится простой алгоритм: ввод исходных данных(блок 2), обработка и вывод результатов (модифицированный блок 9). Такой алгоритм вполне пригоден для представления ВС в виде сети массового обслуживания.
Подобные преобразования должны быть проведены для всех алгоритмов, включенных в модель.
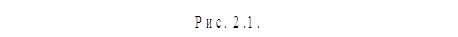
2.1.3. Построение модели рабочей нагрузки. Подбор параметров модели.
Рабочей нагрузкой ВС являются потоки требований (заявок) на выполнение различных программ. Модель рабочей нагрузки - это совокупность потоков заявок
S={S1,....,SM),
где М - число потоков, заявок.
Каждый i-ый поток характеризуется приоритетом К, правилами и параметрами для определения времен поступления заявок Тз, последовательностью В и величиной С использования ресурсов:
Si=(K,Tз,B,C), i= 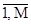
Приоритет указывает значимость заявки данного потока, а может указывать и степень срочности. Приоритет имеет разные значения по функциям ввода KВв , обработки КО, хранения КR, и вывода КВ или по видам ресурса одного класса; т.е.
K=(KВв, КО, КR, КВ).
Для определения момента поступления заявок в систему в модели потока указывают тип потока и соответствующие параметры: для детерминированного – период Tз или интенсивность l, для регулярного – расписание, для статистического – функцию распределения интервалов времени между заявками. Если поток нестационарный, функция распределения задается в виде случайного процесса:
Тз=F(tз,t).
По способу задания последовательности использования ресурсов, т.е. по маршрутам заявок, модели потоков разделяются на трассировочные и вероятностные. В трассировочных моделях последовательность использования ресурсов указывается в явном виде. Маршрут заявки полностью определяется алгоритмом обработки данных. В вероятностных моделях задаются вероятности перехода заявок к одному из следующих ресурсов или к завершению обработки:
B®[Pk,l],
где k - номер текущего (использованного) ресурса, l - номер очередного ресурса на маршруте обслуживания.
Модель потока заявок должна содержать алгоритмы и параметры, позволяющие определить величины использования каждого ресурса во времени и пространстве(для накопительных и коммуникационных подсистем):
C={Cj,i};Cj,i=(Aj,Vi,Si),
где Cj,i - параметры использования j-го ресурса для i-го потока. Aj - алгоритм определения величины использования; Vi={Vi1,...., Viq} - параметры i-го потока для определения трудоемкости обслуживания заявок; например, количество передаваемых или обрабатываемых данных, или число операций; Si= {Si1,...., Sis} - параметры i-го потока для определения степени использования (целиком или частично) для разделенных ресурсов и накопителей.
Параметры Vi и Si задаются часто как случайные величины или функции:
Vi=Fv(v,t); Si=Fs(s,t).
Все параметры модели потоков заявок определяются по результатам статистической обработки измерений или оценок экспериментальных рабочих нагрузок.
При составлении модели необходимо учитывать только те параметры, которые влияют на выходные характеристики системы.
Типичными для моделирования ВС на системном уровне являются количественные параметры, позволяющие вычислять время обслуживания i-ой заявки любого потока к-ым элементом Тik. Так как это время – случайная величина, оно задается функцией распределения для каждого потока по всем к элементам, обслуживающим заявки этого потока - {F(Tk)}. При заданных первичных параметрах элементов и потоков, являющихся исходными данными, время T ik может быть вычислено.
Например, если известны производительность процессора Рk и число операций для обслуживания заявки Nik, то
Tik= Nik/Pk.
Eсли известно количество операций разного типа для обслуживания заявки Nikg, то
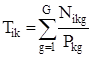 ,
,
где Pkg - производительность процессора по обслуживанию g-ых заявок.
Параметры Pk и Pkg - паспортные характеристики процессора, а Nik и Nikg - параметры потоков заявок.
Для задач статистического и экономического характера количественными параметрами являются: Vik- количество данных, обработанных k-ым процессором по i-ой заявке; Qk - время обслуживания k-ым процессором единицы данных; Tik1- составляющая времени обслуживания к-ым процессором i-ой заявки, независимая от количества обрабатываемых данных. Тогда
Tik= Vik*Qk+Tik1,
где, Qk – параметр процессора. Vk и Tkl – параметры потока.
Для терминалов и накопителей время передачи данных определяется количеством передаваемых данных Vik и скоростью обмена Sk:
Tcik= Vik/Sk
Если требуется учитывать время установки в требуемый режим, то следует задавать и Tsik - время установки к-го устройства по i-ой заявке:
Tik=Tcik+Tsik.
К количественным параметрам накопителей относится также емкость.
Основным количественным параметром потока заявок является интенсивность 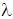 . Это обязательный параметр для всех моделей и средств моделирования. Кроме основных параметров при моделировании задаются и вспомогательные параметры: количество генерируемых заявок за время моделирования, количество заявок в системе, время пребывания заявок в системе или в очереди.
. Это обязательный параметр для всех моделей и средств моделирования. Кроме основных параметров при моделировании задаются и вспомогательные параметры: количество генерируемых заявок за время моделирования, количество заявок в системе, время пребывания заявок в системе или в очереди.
При моделировании ВС используются такие функциональные параметры, к которым относятся дисциплины обслуживания и ожидания, а также дисциплина маршрутизации, т.е. правила, определяющие последовательность использования заявками обслуживающих элементов.
2.2. Обобщенные алгоритмы имитационного моделирования
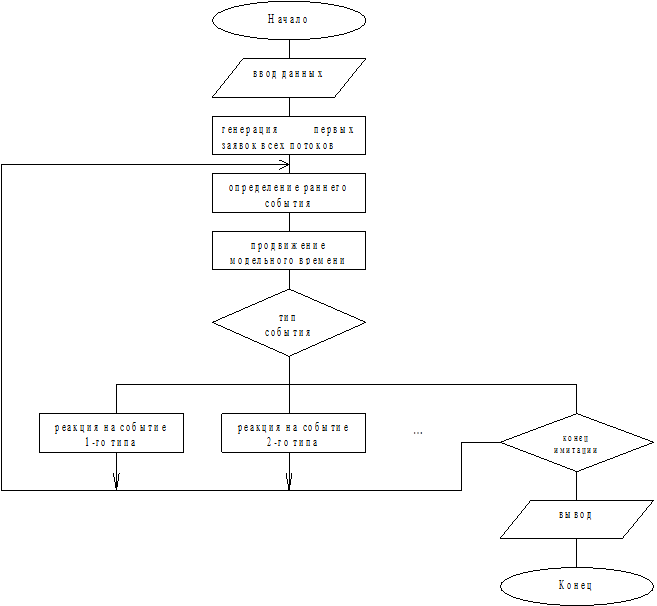
Для проведения имитационного моделирования используются два алгоритма, называемые обобщенными алгоритмами имитационного моделирования: моделирование по принципу ”d z ” и моделирование по принципу ”d t ”(см 1.3.5).
Алгоритм моделирования по принципу “d z ”состоит в следующем:
1) определяется событие с минимальным временем - наиболее раннее событие;
2) модельному времени присваивается значение времени наступления наиболее раннего события;
3) определяется тип события;
4) в зависимости от типа события предпринимаются действия (загрузка устройств и продвижение заявок) и вычисляются моменты наступления будущих событий; эти действия-реакция модели на события;
5) перечисленные действия повторяются до истечения времени моделирования Tm.
В процессе моделирования производятся измерения и статистическая обработка значений выходных характеристик. Обобщенная схема алгоритма моделирования по принципу особых состояний приведена на рис.2.2.
Вначале производится инициализация моделируемой программы – подготавливаются массивы, вводятся и размещаются в оперативной памяти входные данные, настраивается ДСЧ, затем генерируются первые заявки по каждому потоку - определяются моменты их поступления.
Далее в цикле определяется момент наступления более раннего события и до этого момента смещается модельное время и т.д. Такой цикл повторяется до конца моделирования, после чего завершается обработка статистики и выводятся результаты.
В системе - оригинале может одновременно протекать несколько процессов обслуживания. При моделировании на однопроцессорной ВС эта ситуация разрешается путем псевдопараллельной имитации нескольких процессов, т.е. последовательно в установленном порядке реализуются реакции на все одновременно возникшие ситуации без продвижения модельного времени.
|
При моделировании по принципу “d t ”, как и в предыдущем случае, вначале инициализируется программа, в частности, вводятся значения t i(t 0), i=1,2...m, устанавливается модельное время t = t 0=0.
Основная операция моделирования выполняется в цикле. Функционирование системы определяется по последней смене состояний Zi(t). Для этого дается приращение D t модельного времени и по вектору текущих состояний определяются новые состояния Zi(t +D t), которые становятся текущими. Для определения новых состояний используются необходимые математические формулы. Такой цикл продолжается, пока текущее модельное время меньше заданного времени Tm. Блок схема алгоритма моделирования приведена на рис. 2.3.

Рис. 2.3.
По ходу имитации измеряются, фиксируются и обрабатываются требуемые выходные характеристики. При t >=Tm завершается обработка измерений и выводятся результаты моделирования.
При моделировании стохастической системы вместо новых состояний вычисляются распределения вероятностей для возможных состояний, которые определяются по результатам случайных испытаний. В результате проведения имитационного моделирования получается одна из возможных реализаций случайного многомерного процесса в заданном интервале времени (t 0,Tкm).
Моделирующий алгоритм по принципу “d t ” охватывает более широкий круг систем. Однако, при его реализации возникают проблемы с определением приращения модельного времени D t.
Для моделирования ВС на системном уровне в основном применяется принцип особых состояний.
2.3 Проведение имитационного эксперимента
2.3.1. Фиксация и обработка результатов
Имитация – это эксперимент, который осуществляется при максимальном приближении к реальным условиям с учетом влияния различных случайных воздействий. В силу этого выходные характеристики модели носят случайный характер. На практике, исследуя случайные явления, эксперимент проводят насколько раз, а затем проводят статистическую обработку его результатов. Аналогичная ситуация имеет место и при имитации на ЭВМ. Ее повторяют многократно, получая всякий раз одну из возможных реализаций процесса. Количество реализаций, которое необходимо провести, рассчитывается по специальным правилам.
Для получения оценок характеристик применяются формулы математической статистики, приведенные к такому виду, когда для подсчета оценок требуется минимальное количество ячеек памяти. При этом, например, вероятность события оценивается относительной частотой наступления его в N реализациях: 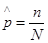 , где n - число наступлений событий. Очевидно, что для определения
, где n - число наступлений событий. Очевидно, что для определения 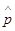 требуется всего две ячейки памяти: в одной суммируется n по принципу n=n+1, а в другой аналогично считается N.
требуется всего две ячейки памяти: в одной суммируется n по принципу n=n+1, а в другой аналогично считается N.
Таким же методом строятся распределения случайных величин. При этом область определения случайной величины разбивается на подинтервалы одинаковой длины. Для каждого подинтервала отводится ячейка, где накапливаются значения 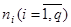 - количество попаданий случайной величины в i-ый интервал. Тогда относительная частота попадания в i-ый интервал определяется следующим образом:
- количество попаданий случайной величины в i-ый интервал. Тогда относительная частота попадания в i-ый интервал определяется следующим образом:  . По значениям
. По значениям 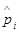 строится гистограмма, являющаяся аналогом плотности вероятности.
строится гистограмма, являющаяся аналогом плотности вероятности.
Для оценки среднего значения случайной величины X используется выборочное среднее:
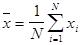 ,
,
а в качестве оценки дисперсии - выборочная дисперсия:
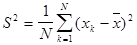 .
.
Формула вычисления дисперсии в целях экономии памяти приводится к следующему виду:
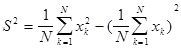 .
.
Аналогично при определении оценки корреляционного момента Kxy двух случайных величин X и Y следует воспользоваться не обычной формулой
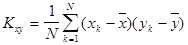 ,
,
а приведенной
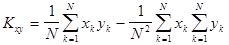 .
.
2.3.2. Оценка числа реализаций при заданной точности
При имитационном моделировании для получения статистически достоверных результатов необходимо некоторое число N реализаций случайной величины X, причем, чем больше N, тем точнее оценки. Это число определяется либо предварительно и независимо от наблюдаемых результатов, либо в процессе моделирования с применением метода последовательного анализа.
Первый метод считается классическим, хотя он менее эффективен, чем второй. Сущность метода состоит в следующем. Предполагается, что задачей имитации является определение среднего значения случайной величины X.
Оценку среднего значения 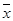 можно рассматривать как значение случайной величины:
можно рассматривать как значение случайной величины:
,
где xi - независимые одинаково распределенные случайные величины с неизвестным математическим ожиданием a и дисперсией 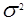 . Для достаточно больших N, пользуясь результатом центральной предельной теоремы, можно утверждать, что:
. Для достаточно больших N, пользуясь результатом центральной предельной теоремы, можно утверждать, что:
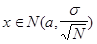 .
.
Тогда
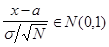 .
.
Задается надежность a и накладывается условие:
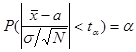 .
.
Величину ta легко определить по таблицам функций Лапласа. Тогда точность оценки удовлетворяет условию:
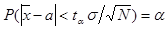 .
.
Так как точность решения e должна быть задана, получается:
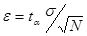 ,
,
откуда требуемое число реализаций:
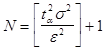 . (2.1)
. (2.1)
Если целью имитации является оценка вероятности, то число реализаций определяется аналогично. В качестве оценки неизвестной вероятности события p(A) используют величину:
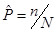 .
.
Вводя в рассмотрение величину Xi - число наступлений событий A в i-ой реализации, (Xi равно 0 с вероятностью 1–Р и равно 1 с вероятностью Р) можно получить
M[Xi]=Р; D[Xi]=Р(1–Р).
Легко показать, что 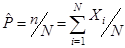 .
.
В силу центральной предельной теоремы для достаточно больших N
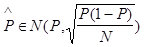 .
.
Тогда по заданной надежности a по таблицам функции Лапласа легко определить ta из условия 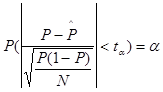 .
.
Отсюда
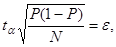
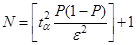 (2.2)
(2.2)
При использовании формул (2.1) и (2.2) для определения N требуется знать истинные значения 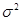 и Р, которые обычно неизвестны. Поэтому задаются произвольным числом реализаций, имитируют процесс и определяют оценки
и Р, которые обычно неизвестны. Поэтому задаются произвольным числом реализаций, имитируют процесс и определяют оценки 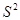 и
и 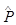 величин и Р. Далее, используя эти оценки, по формулам (2.1) и (2.2) определяется уточненное значение N. Аналогично определяется число реализаций, необходимое для обеспечения заданной точности любых других оценок: дисперсии, корреляции и т.д.
величин и Р. Далее, используя эти оценки, по формулам (2.1) и (2.2) определяется уточненное значение N. Аналогично определяется число реализаций, необходимое для обеспечения заданной точности любых других оценок: дисперсии, корреляции и т.д.
Второй путь определения числа реализаций базируется на использовании последовательного анализа. В этом случае после каждой реализации с помощью последовательного критерия Вальца принимается решение об окончании процесса или его продолжении. В общих чертах процедура сводится к сравнению совокупных результатов с некоторой допустимой областью значений, при которых эти результаты обеспечивают желаемый уровень значимости. В том случае, когда результаты попадают в допустимую область, процесс останавливается. Допустимая область значений находится с помощью последовательного критерия Вальца. При использовании последовательного анализа процесс получения результатов требует меньшего числа реализаций, чем при использовании классическом методе. Однако, при этом заранее неизвестно требуемое число реализаций.
Дата публикования: 2014-11-02; Прочитано: 1299 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
