 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Анализ лучших практик в области систем интеллектуального анализа
|
|
Технологии Data Mining представляют собой мощный аппарат современной бизнес-аналитики и исследования данных для обнаружения скрытых закономерностей и построение предсказательных моделей. Data Mining переводится как "добыча" или "раскопка данных" и основывается не на умозрительных рассуждениях, а на реальных данных.
Иногда этот термин ошибочно используют для обозначения инструментов, позволяющих по-новому представить (отобразить) информацию, однако на самом деле эти инструменты призваны помочь в выявлении скрытых (неочевидных) закономерностей, моделей, составления прогнозов. Они основаны на сканировании и статистической обработке огромных массивов данных и в конечном итоге призваны облегчить принятие правильных и обоснованных стратегических решений благодаря анализу различных вариантов развития событий. В качестве инструментов используются нейронные сети, деревья решений.
Data Mining - мультидисциплинарная область, возникшая и развивающаяся на базе таких наук, как прикладная статистика, распознавание образов, искусственный интеллект, теория баз данных и др. (см. рис. 6.)[25].
Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро (Gregory Piatetsky-Shapiro) - один из основателей этого направления(1989 год): «Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности».
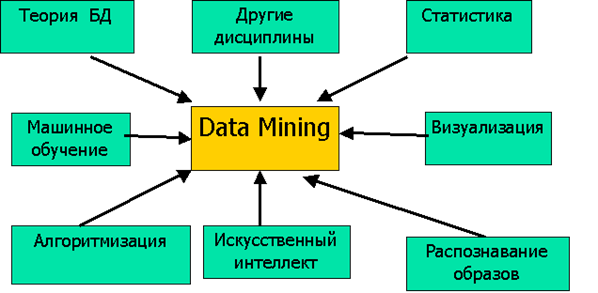
Рисунок 6. Data Mining как мультидисциплинарная область
Суть и цель технологии Data Mining можно охарактеризовать так: это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидные закономерности - это такие закономерности, которые нельзя обнаружить стандартными методами обработки информации или экспертным путем.
Объективные - обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным.
Полезность на практике - полученные данные будут иметь практическое применение.
Data Mining - это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для использования.

Рис. 6. Схема применения Data Mining
· Problem Definition - Постановка задачи: классификация данных, сегментация, построение предсказательных моделей, прогнозирование.
· Data Gathering and Preparation - Сбор и подготовка данных, чистка, верификация, удаление повторных записей.
· Model Building - Построение модели, оценка точности.
· Knowledge Deployment - Применение модели для решения поставленной задачи.
Data Mining применяется для реализации масштабных аналитических проектов в бизнесе, маркетинге, интернете, телекоммуникациях, промышленности, геологии, медицине, фармацевтике и других областях.
Одной из разновидностей методов Data Mining является технология Text Mining.
Text Mining - процесс извлечения информации из текстовых данных на основе обнаружения в них закономерностей. Этот анализ, как правило, включает этапы структурирования исходного текста (обычно путем синтаксического анализа, добавления одних лингвистических структур и удаления других с последующей вставкой результатов в базу данных), поиска закономерностей в данных, а также оценивания и интерпретации результатов [13].
В междисциплинарном смысле Text Mining лежит на стыке поиска информации, Data Mining, машинного самообучения, статистики и компьютерной лингвистики. Такая технология глубинного анализа текстов способна «просеивать» большие объемы неструктурированной информации и выявлять из них только самое значимое, чтобы человеку не приходилось самому тратить время на добычу необходимой информации (ценных знаний) «вручную».
Техt Mining подразумевает процесс структурирования вводных текстовых данных, извлечение шаблонов из уже структурированных данных, и финальную оценку и интерпретацию полученных результатов.
Анализ текстов включает в себя извлечение информации и лингвистический анализ для выявления частоты вхождений различных слов, выявление шаблонов, расставление тэгов и аннотирование, техники Data Mining, в том числе анализ связей и ассоциаций, визуализацию и прогностический анализ. В конечном счете, общая цель всего этого состоит в том, чтобы превратить текст в данные, доступные для анализа.
Примером наиболее частого использования Text Mining может послужить сканирование набора документов, составленных на естественных языках, чтобы либо составить модель для прогностической классификации, либо упростить с помощью обнаруженной информации поиск по базам данных. По сути, анализ текстов и TextMining - это набор лингвистических, статистических техник, а также техник машинного самообучения, которые способны моделировать и структурировать информационный контент и текстовые источники в целях бизнес-аналитики, анализа данных, исследований.
Технология глубинного анализа текста - Text Mining - это тот самый инструментарий, который позволяет анализировать большие объемы информации в поисках тенденций, шаблонов и взаимосвязей, способных помочь в принятии стратегических решений. Кроме того, Text Mining - это новый вид поиска, который в отличие от традиционных подходов не только находит списки документов, формально релевантных запросам, но и помогает ответить на вопрос: "Помоги мне понять смысл, разобраться с этой проблематикой".
Пример успешного применения логических возможностей Text Miner демонстрирует компания Compaq Computer Corp., которая в настоящее время тестирует Text Miner, анализируя более 2,5 гигабайт текстовых документов, полученных по e-mail и собранных представителями компании. Ранее обработать такие данные было практически невозможно. Программа Text Miner позволяет определять, насколько правдив тот или иной текстовый документ. Обнаружение лжи в документах производится путем анализа текста и выявления изменений стиля письма, которые могут возникать при попытке исказить или скрыть информацию. Для поиска таких изменений используется принцип, заключающийся в поиске аномалий и трендов среди записей баз данных без выяснения их смысла. При этом в Text Miner включен обширный набор документов различной степени правдивости, чья структура принимается в качестве шаблонов.
Интересен пример применения Text Miner в медицине: в одной из американских национальных здравоохранительных организаций было собрано свыше 10 тыс. врачебных записей о заболеваниях сердца, собранных из клиник по всей стране. Анализируя эти данные с помощью Text Miner, специалисты обнаружили некоторые административные нарушения в отчетности, а также смогли определить взаимосвязь между сердечно-сосудистыми заболеваниями и другими недугами, которые не были определены традиционными методами.
Еще один пример внедрения Text Mining: если в Google набрать запрос "классическая музыка", то поисковик выдаст ссылки на сайты, так или иначе касающиеся классической музыки. Если же искать "классическую музыку" через информационно - поисковуюсистему ( ИПС) с кластеризацией и систематизацией данных на основе Text Mining, то будет выдан тематически сортированный список композиций, которые можно тут же прослушать.
Другой пример - по запросу "Гарри Поттер" пользователь получит не просто набор ссылок, а отсортированный отчет, в котором часть ссылок будет лежать в графе "фильмы", другая часть - в колонке "книги", а третья - в колонке "рецензии".
Программа TextAnalyst от НПИЦ "МикроСистемы" является инструментом для анализа содержания текстов, смыслового поиска информации, формирования электронных архивов. Она также способна строить семантические деревья, но не по объектам, а по отдельным статьям, в результате чего создается смысловой портрет каждого текста на основе количества упоминаний и близости встречаемости различных значащих, по мнению программы, слов. В TextAnalyst есть также модуль, генерирующий реферат текстового документа. Программа не предназначена для потоковой обработки материалов СМИ, но может брать с диска файлы в формате txt и rtf и после анализа текста сохранять результаты в отдельном файле.(рис 7.) [18].

Рис. 7. Пример анализа текста в программе TextAnalyst
"Астарта". Компания Cognitive Technologies предлагает инструмент автоматизации аналитических исследований "Астарта". Он представляет собой экспертный рубрикатор, предназначенный для сбора, хранения и семантического анализа текстовых материалов. Под анализом здесь понимается автоматическое рубрицирование и группировка, а также интеллектуальная выборка информации по заданной теме [19].
Практические внедрения: Норильский никель, Газпромбанк, ФАПСИ (Федеральное агентство правительственной связи и информации при Президенте Российской Федерации). В частности на "Норильском никеле", где с ее помощью анализируется база патентной информации, содержащая более 100 тыс. документов. В "Астарте" есть подсистема, умеющая обрабатывать материалы из СМИ в потоковом режиме. С ее помощью аналитики "Норильского никеля" делают, например, выводы об изменениях интересов ведущих фирм в выбранных для наблюдения областях (рис. 8).
 Рис. 8. Пример анализа текста в программе "Астарта"
Рис. 8. Пример анализа текста в программе "Астарта"
- 4Talk
- ВКонтакте
- Одноклассники
- Google+
- Mail.ru
- Evernote
- В кругу Друзей
- Tumblr
- LiveJournal
- Pinme
- БобрДобр
- Blogger
- Digg
- Delicious
- Instapaper
- LiveInternet
- MySpace
- Readability
- Surfingbird
- StumbleUpon
- По почте
UPTOLIKE - модули социальной активности для вашего сайта.
Дата публикования: 2015-10-09; Прочитано: 2030 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
