 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Прямая теорема неравномерного кодирования
|
|
Теорема 8.1. Для ансамбля 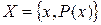 с энтропией
с энтропией 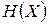 существует побуквенный неравномерный префиксный код со средней длиной кодовых слов
существует побуквенный неравномерный префиксный код со средней длиной кодовых слов
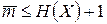 . (8.13)
. (8.13)
Обсудим полученную оценку длины кодовых слов. Мы знаем, что достижимая скорость кодирования примерно равна энтропии. Теорема гарантирует, что средняя длина слов хорошего кода отличается от энтропии не более чем на 1. Если энтропия велика, то проигрыш по сравнению с минимально достижимой скоростью можно считать небольшим. Но предположим, что 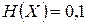 . Теорема гарантирует, что существует код со средней длиной кодовых слов не более 1,1 бита. Но нам хотелось бы затрачивать на передачу одного сообщение примерно в 10 раз меньше бит. Этот пример показывает, что либо теорема дает неточную оценку, либо побуквенное кодирование в этом случае не эффективно.
. Теорема гарантирует, что существует код со средней длиной кодовых слов не более 1,1 бита. Но нам хотелось бы затрачивать на передачу одного сообщение примерно в 10 раз меньше бит. Этот пример показывает, что либо теорема дает неточную оценку, либо побуквенное кодирование в этом случае не эффективно.
На этом же примере мы убедимся в том, что теорема достаточно точна и ее результат не может быть улучшен, если не использовать никакой дополнительной информации об источнике. Действительно, предположим, что дан двоичный источник Х= {0,1} с вероятностями букв 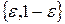 . Минимально достижимая длина кодовых слов наилучшего кода, очевидно, равна 1. Теорема говорит, что средняя длина кодовых слов не больше
. Минимально достижимая длина кодовых слов наилучшего кода, очевидно, равна 1. Теорема говорит, что средняя длина кодовых слов не больше 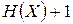 , т. е. стремится к 1 при
, т. е. стремится к 1 при 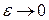 . Таким образом, для данного примера двоичного источника теорема верна.
. Таким образом, для данного примера двоичного источника теорема верна.
Достижение скоростей (затрат на передачу одной буквы источника), меньших 1, невозможно при побуквенном кодировании, поскольку длина кодового слова не может быть меньше 1. Однако переход к кодированию блоков сообщений решает эту проблему и позволяет сколь угодно близко подойти к теоретическому пределу, равному энтропии . Конструктивным решением данной задачи является арифметическое кодирование.
Дата публикования: 2015-09-17; Прочитано: 575 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
