 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Принципы экономного кодирования. Цель сжатия данных и типы систем сжатия
|
|
Кодирование источника сообщений производиться с целью сокращения объема информации и повышения скорости ее передачи или сокращения полосы частот, требуемых для передачи. Такое к одирование называют экономным, безызбыточным, или эффективным кодированием, а также сжатием данных.
Самым простым способом представления или задания кодов являются кодовые таблицы, ставящие в соответствие сообщениям li соответствующие им коды (табл. 8.2).
| Буква li | Число li | Код с основанием 10 | Код с основанием 4 | Код с основанием 2 |
| А | ||||
| Б | ||||
| В | ||||
| Г | ||||
| Д | ||||
| Е | ||||
| Ж | ||||
| З |
Таблица 8.2 Способ представления кодов
Другим наглядным и удобным способом описания кодов является их представление в виде кодового дерева (рис. 8.3).
Корень
Узлы
 0 1
Вершина
0 1 0 1
0 1 0 1 0 1 0 1
А Б В Г Д Е Ж З
1 2 3 4 5 6 7 8
Рис. 4.
0 1
Вершина
0 1 0 1
0 1 0 1 0 1 0 1
А Б В Г Д Е Ж З
1 2 3 4 5 6 7 8
Рис. 4.
|
Рис. 8.3 Кодовое дерево для равномерного кодирования
Для того, чтобы построить кодовое дерево для данного кода, начиная с некоторой точки - корня кодового дерева - проводятся ветви - 0 или 1. На вершинах кодового дерева находятся буквы алфавита источника, причем каждой букве соответствуют своя вершина и свой путь от корня к вершине. К примеру, букве А соответствует код 000, букве В – 010, букве Е – 101 и т.д.
Код, полученный с использованием кодового дерева, изображенного на рис. 8.3, является равномерным трехразрядным кодом.
Равномерные коды очень широко используются в силу своей простоты и удобства процедур кодирования-декодирования: каждой букве – одинаковое число бит; принял заданное число бит – ищи в кодовой таблице соответствующую букву.
Наряду с равномерными кодами могут применяться и неравномерные коды, когда каждая буква из алфавита источника кодируется различным числом символов, к примеру, А - 10, Б – 110, В – 1110 и т.д.
Кодовое дерево для неравномерного кодирования может выглядеть, например, так, как показано на рис. 8.4.
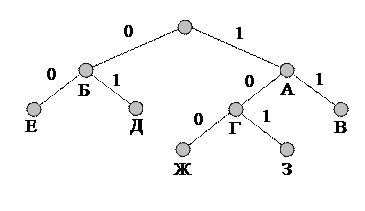 |
Рис. 8.4 Кодовое дерево для неравномерного кодирования
При использовании этого кода буква А будет кодироваться, как 1, Б - как 0, В – как 11 и т.д. Однако можно заметить, что, закодировав, к примеру, текст АББА = 1001, мы не сможем его однозначно декодировать, поскольку такой же код дают фразы: ЖА = 1001, АЕА = 1001 и ГД = 1001. Такие коды, не обеспечивающие однозначного декодирования, называются приводимыми, или непрефиксными, кодами и не могут на практике применяться без специальных разделяющих символов. Примером применения такого типа кодов может служить азбука Морзе, в которой кроме точек и тире есть специальные символы разделения букв и слов. Но это уже не двоичный код.
Однако можно построить неравномерные неприводимые коды, допускающие однозначное декодирование. Для этого необходимо, чтобы всем буквам алфавита соответствовали лишь вершины кодового дерева, например, такого, как показано на рис. 8.5. Здесь ни одна кодовая комбинация не является началом другой, более длинной, поэтому неоднозначности декодирования не будет. Такие неравномерные коды называются префиксными.

Рис. 8.5. Кодовое дерево для префиксного кодирования
Прием и декодирование неравномерных кодов - процедура гораздо более сложная, нежели для равномерных. При этом усложняется аппаратура декодирования и синхронизации, поскольку поступление элементов сообщения (букв) становится нерегулярным. Так, к примеру, приняв первый 0, декодер должен посмотреть в кодовую таблицу и выяснить, какой букве соответствует принятая последовательность. Поскольку такой буквы нет, он должен ждать прихода следующего символа. Если следующим символом будет 1, тогда декодирование первой буквы завершится – это будет Б, если же вторым принятым символом снова будет 0, придется ждать третьего символа и т.д.
Зачем же используются неравномерные коды, если они столь неудобны?
Рассмотрим пример кодирования сообщений li из алфавита объемом Nl = 8 с помощью произвольного n -разрядного двоичного кода.
Пусть источник сообщения выдает некоторый текст с алфавитом от А до З и одинаковой вероятностью букв p ( li ) = 1/8.
Кодирующее устройство кодирует эти буквы равномерным трехразрядным кодом (см. табл. 8.2).
Определим основные информационные характеристики источника с таким алфавитом:
- энтропия источника 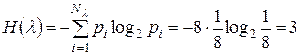 ;
;
- максимальная энтропия 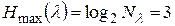 ;
;
- избыточность источника 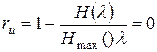 ;
;
- среднее число символов в коде 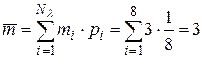 ;
;
- избыточность кода 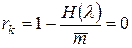 .
.
Таким образом, при кодировании сообщений с равновероятными буквами избыточность выбранного (равномерного) кода оказалась равной нулю.
Пусть теперь вероятности появления в тексте различных букв будут разными (табл. 8.3).
Таблица 8.3. Вероятности появления в тексте букв
| А | Б | В | Г | Д | Е | Ж | З |
| Ра =0.6 | Рб =0.2 | Рв =0.1 | Рг =0.04 | Рд =0.025 | Ре =0.015 | Рж =0.01 | Рз =0.01 |
Энтропия источника 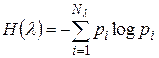 в этом случае, естественно, будет меньшей и составит
в этом случае, естественно, будет меньшей и составит 
Среднее число символов на одно сообщение при использовании того же равномерного трехразрядного кода
Избыточность кода в этом случае будет
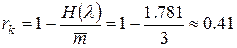 ,
,
довольно значительной величиной (в среднем 4 символа из 10 не несут никакой информации).
В связи с тем, что при кодировании неравновероятных сообщений равномерные коды обладают большой избыточностью, было предложено использовать неравномерные коды, длительность кодовых комбинаций которых была бы согласована с вероятностью выпадения различных букв.
Такое кодирование называется статистическим.
Неравномерный код при статистическом кодировании выбирают так, чтобы более вероятные буквы передавались с помощью более коротких комбинаций кода, менее вероятные - с помощью более длинных. В результате уменьшается средняя длина кодовой группы в сравнении со случаем равномерного кодирования.
Существуют два типа систем сжатия данных:
· системы сжатия без потерь информации (неразрушающее сжатие);
· системы сжатия с потерями информации (разрушающее сжатие).
В системах сжатия без потерь декодер восстанавливает данные источника абсолютно точно.
При решении задачи сжатия естественным является вопрос, насколько эффективна та или иная система сжатия. Поскольку, как мы уже отмечали, в основном используется только двоичное кодирование, то такой мерой может служить коэффициент сжатия 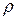 , определяемый как отношение
, определяемый как отношение
 , (8.6)
, (8.6)
где dim A -размер алфавита данных A (размер данных источника в битах), 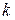 - размер сжатых данных в битах,
- размер сжатых данных в битах, 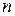 - длина последовательности данных из алфавита A.
- длина последовательности данных из алфавита A.
Таким образом, коэффициент сжатия 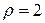 означает, что объем сжатых данных составляет половину от объема данных источника. Чем больше коэффициент сжатия , тем лучше работает система сжатия данных.
означает, что объем сжатых данных составляет половину от объема данных источника. Чем больше коэффициент сжатия , тем лучше работает система сжатия данных.
Наряду с коэффициентом сжатия эффективность системы сжатия может быть охарактеризована скоростью сжатия 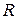 , определяемой как отношение
, определяемой как отношение
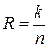 . (8.7)
. (8.7)
Скоростью сжатия измеряется "количество кодовых бит, приходящихся на отсчет данных источника". Система, имеющая больший коэффициент сжатия, обеспечивает меньшую скорость сжатия.
В системе сжатия с потерями (или с разрушением) кодирование производится таким образом, что декодер не в состоянии восстановить данные источника в первоначальном виде.
Разрушающий кодер характеризуется двумя параметрами - скоростью сжатия R и величиной искажений D, определяемых как
, (8.8)
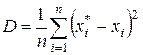 . (8.9)
. (8.9)
Параметр R характеризует скорость сжатия в битах на один отсчет источника, величина D является мерой среднеквадратического различия между сжатыми данными X* и исходными X.
Выбор системы неразрушающего или разрушающего сжатия зависит от типа данных, подлежащих сжатию. При сжатии текстовых данных, компьютерных программ, документов, чертежей и т.п. совершенно очевидно, что нужно применять неразрушающие методы, поскольку необходимо абсолютно точное восстановление исходной информации после ее сжатия. При сжатии речи, музыкальных данных и изображений, наоборот, чаще используется разрушающее сжатие. В общем случае разрушающее сжатие обеспечивает, как правило, существенно более высокие коэффициенты сжатия, нежели неразрушающее.
Ниже приведены ряд примеров, иллюстрирующих необходимость процедуры сжатия, простейшие методы экономного кодирования и эффективность сжатия данных.
Пример 1. Предположим, что источник генерирует цифровое изображение (кадр) размером 512*512 элементов, содержащее 256 цветов. Каждый цвет представляет собой число из множества {0,1,2… 255}. Математически это изображение представляет собой матрицу 512х512, каждый элемент которой принадлежит множеству {0,1,2… 255}. (Элементы изображения называют пикселами).
В свою очередь, каждый пиксел из множества {0,1,2… 255} может быть представлен в двоичной форме с использованием 8 бит. Таким образом, размер данных источника в битах составит 8х512х512= 221, или 2,1 Мегабита.
На жесткий диск объемом в 1 Гигабайт поместится примерно 5000 кадров изображения, если они не подвергаются сжатию (видеоролик длительностью примерно в пять минут). Если же это изображение подвергнуть сжатию с коэффициентом =10, то на этом же диске мы сможем сохранить уже почти часовой видеофильм!
Предположим далее, что мы хотим передать исходное изображение по телефонной линии, пропускная способность которой составляет 14000 бит/с. На это придется затратить 21000000 бит/14000 бит/с, или примерно 3 минуты. При сжатии же данных с коэффициентом = 40 на это уйдет всего 5 секунд.
Пример 2. В качестве данных источника, подлежащих сжатию, выберем фрагмент изображения размером 4х4 элемента и содержащее 4 цвета: R = "красный", O = "оранжевый", В = "синий", G = "зеленый" (табл.8.4).
Таблица 8.4. Фрагмент изображения размером 4х4
| R | R | O | В |
| R | O | O | В |
| O | O | В | G |
| В | В | В | G |
Просканируем это изображение по строкам и каждому из цветов присвоим соответствующую интенсивность, например, R = 3, O = 2, В = 1 и G=0, в результате чего получим вектор данных X=(3,3,2,1,3,2,2,1,2,2,1,0,1,1,1,0).
Для сжатия данных возьмем кодер, использующий следующую таблицу перекодирования данных источника в кодовые слова (табл.8.5).
Таблица 8.5. Перекодирование данных источника в кодовые слова
| Кодер | |
| Отсчет | Кодовое слово |
Используя таблицу кодирования, заменим каждый элемент вектора X соответствующей кодовой последовательностью из таблицы (так называемое кодирование без памяти). Сжатые данные (кодовое слово B (X))будут выглядеть следующим образом:
B (X) = (0 0 1 0 0 1 0 1 1 0 0 1 0 1 0 1 1 0 1 0 1 1 0 0 0 1 1 1 0 0 0).
Коэффициент сжатия при этом составит =32/31, или 1,03. Соответственно скорость сжатия R = 31/16 бит на отсчет.
Пример 3. Сравним два различных кодера, осуществляющих сжатие одного и того же вектора данных
X = ABRACADABRA.
Первый кодер - кодер без памяти, аналогичный рассмотренному в предыдущем примере (каждый элемент вектора X кодируется независимо от значений других элементов - кодер без памяти) (табл 8.6).
Таблица 8.6. Кодер без памяти
| Кодер 1 | |
| Символ | Кодовое слово |
| A | |
| B | |
| R | |
| C | |
| D |
Второй кодер при кодировании текущего символа учитывает значение предшествующего ему символа, таким образом, кодовое слово для текущего символа Aбудетразличным в сочетаниях RA, DA и CA(иными словами, код обладает памятью в один символ источника) (табл.8.7).
Таблица 8.7. Кодер с памятью
| Кодер 2 | |
| Символ, предыдущий символ | Кодовое слово |
| (A,-) | |
| (B,A) | |
| (C,A) | |
| (D,A) | |
| (A,R) | |
| (R,B) | |
| (A,C) | |
| (A,B) |
Кодовые слова, соответствующие вектору данных X = ABRACADABRA, при кодировании с использованием этих двух таблиц будут иметь вид:
B1 (X) = 01011001110011110101100,
B2 (X) = 10111011111011.
Таким образом, скорость сжатия при использовании кодера 1 (без памяти) составит 23/11 = 2,09 бита на символ данных, тогда как для кодера 2-13/11 = 1,18 бита на символ. Использование второго кодера, следовательно, является более предпочтительным, хотя он и более сложен.
Дата публикования: 2015-09-17; Прочитано: 1507 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
