 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Интеграция информационных систем
|
|
| Интеграция информационных систем | Интеллектуальный поиск |
| Корпоративные порталы | Решения для совместной работы |
| Электронные формы |
Интеграция – это процесс объединения и совместной работы информационных систем и программных приложений.
Среди основных подходов к ведению интеграции информационных систем следует отметить следующие:
1. «Лоскутная» интеграция – «стихийная» интеграция систем при отсутствии единой инфраструктуры. Данный подход приводит к низкой надежности и высокой энтропии взаимодействия систем, потому что:
o отсутствует возможность формализации и единая среда исполнения бизнес-процессов;
o осуществляется привязка к конкретным типам интерфейсов и источников данных.
2. На основе системы электронного документооборота – используется единая информационная система для решения всех задач организации, что влечет за собой следующие проблемы:
o нестабильная работа системы при серьезной нагрузке;
o ограниченные механизмы автоматизации процессов;
o работает с данными определенного и часто закрытого формата;
o часто отсутствуют открытые интерфейсы и протоколы взаимодействия с системой;
o накладывает серьезные ограничения на развитие информационной инфраструктуры.
3. При помощи единой интеграционной шины ESB и сервера бизнес-процессов заказчик может избежать всех вышеперечисленных проблем и получить в своё распоряжение следующие преимущества:
o высокая степень стандартизации и неограниченная расширяемость;
o готовая инфраструктура интеграции;
o встроенные средства разработки и выполнения процессов;
o возможность моделирования и оценки ключевых параметров производительности;
o поддержка версий процесса и возможность изменить логику его работы «на лету» без остановки среды исполнения.
Первым этапом интеграции систем является создание требований к результатам интеграции, которое включает в себя следующие шаги:
· Формулирование бизнес-требований и правил интеграции систем
· Соблюдение эксплуатационных требований:
o открытые стандарты взаимодействия информационных систем;
o сквозное управление и мониторинг;
o единый подход к развитию инфраструктуры;
o широкий набор средств для работы с интеграционными компонентами, входящими в технологическую платформу.
В качестве технологических платформ нацеленных на решение задач интеграции наша компания предлагает внедрение:
· IBM Business Process Manager – средство автоматизации процессов интеграции;
· IBM WebSphere ILOG JRules – средство создания бизнес-правил;
· IBM WebSphere MQ – платформа, предназначенная для обеспечения гарантированной доставки сообщений.
· IBM WebSphere Service Registry and Repository – система регистрации сервисов систем.
Общая архитектура предлагаемого решения включает в себя такие подсистемы, как:
· Подсистема автоматизации регламентов, предназначена для автоматизации процессов интеграции.
· Подсистема доставки сообщений, предназначена для решения проблемы гарантированной доставки сообщений и распределения нагрузки в пиковые моменты эксплуатации системы.
· Подсистема управления сервисами – позволяет заказчику собственными силами регистрировать новые информационные системы в интеграционной среде.
· Подсистема управления бизнес-правилами – обеспечивает создание и изменение большого количества сложных интеграционных процессов со сложными аналитическими условиями выполнения.
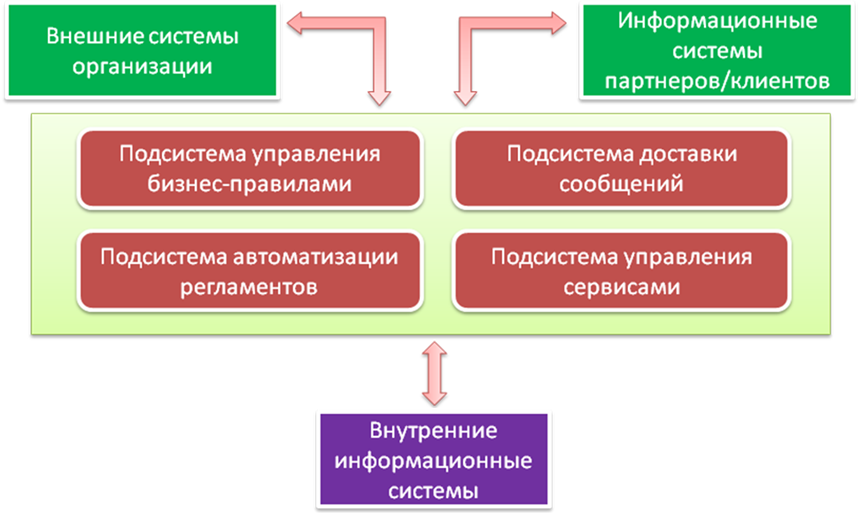
Способы интеграции информационных систем
Большинство корпоративных информационных систем в процессе своей эксплуатации нуждаются в тех или иных структурных изменениях, диктуемых необходимостью адаптации к изменяющимся условиям и требованиям бизнеса. Зачастую новые требования могут быть удовлетворены при дополнении или замене в бизнес-процессах некоторых процедур другими. Для выполнения новых процедур могут быть приобретены или использованы уже имеющиеся на предприятии прикладные программы, однако они, как правило, предназначены для автономного применения или для исполнения в иной программно-аппартной среде. Для их совместного функционирования необходимы разработка и применение соответствующих интеграционных технологий.
Способы интеграции различают по нескольким признакам.
По степени обособленности взаимосвязей подсистем в интегрируемой системе (иначе по структуре интеграции) различают варианты "точка — точка" и "звезда" (интегрирующая среда).
В варианте "точка-точка" взаимодействие подсистем осуществляется по схеме полного графа, т.е. для каждой пары взаимодействующих подсистем создается специфическая для них интерфейсная связь, например, в виде конверторов данных с языка одной подсистемы на язык другой (такую схему применительно к сетям обычно обозначают peer-to-peer или p2p). Поскольку число таких дуплексных связей может доходить до N(N-1)/2, где N — число подсистем, то вариант "точка-точка" оказывается приемлемым только для малых N. Подключение к системе каждой новой подсистемы оказывается весьма трудоемким.
В варианте "звезда" (рис. 1) число связей уменьшается до N, интеграция осуществляется на основе общего для подсистем языка и/или программного обеспечения, являющегося промежуточной интегрирующей средой. В отличие от способа "точка-точка" теперь достаточно в каждой подсистеме иметь интерфейс только с метасредой. Интегрирующая среда характеризуется наличием центрального компонента, управляющего взаимодействием подсистем в рамках информационной системы в целом. Интегрирующая среда выполняет сценарии транзакций, функции взаимодействия приложений, протоколирование и мониторинг состояния, обмен сообщениями между подсистемами, алгоритмы маршрутизации и доставки сообщений и др.

|
Рис. 1.
В зависимости от объема и глубины перестройки интегрируемой информационной системы различают интеграцию инфраструктуры, данных, приложений и процессов.
Интеграция инфраструктуры основана на изменениях и унификации базовых инфраструктурных элементов информационной системы — аппаратной платформы, операционной системы, службы каталогов, сетевых средств а и т.п. Такая интеграция требует больших затрат и фактически приводит к получению новой трудномодифицируемой системы.
Широкое применение имеет интеграция данных. Она не затрагивает основных инфраструктурных аспектов, за исключением средств хранения данных, основными целями подобной интеграции является обеспечение синтаксического, а иногда и семантического единства данных, организация поиска и доступа к данным и т.д. Этот способ сравнительно легко реализуем, однако избежать серьезных изменений в используемых приложениях не удается.
Интеграция данных характерна для традиционных систем клиент-сервер. При этом основным системообразующим фактором при построении информационной системы является единая база данных коллективного доступа. Интегрирующей средой является СУБД со стандартным интерфейсом доступа к данным. Все функции прикладной обработки размещаются в клиентских программах. Связь через единую БД имеет место и в системах с трехзвенной архитектурой, в которых имеется несколько прикладных подсистем и сервер баз данных.
Однако интеграция данных также имеет определенные ограничения по сложности интегрируемой системы и возможностям ее развития. Сложности модификаций снижаются в случаях применения распределенных БД, но появляется проблема синхронизации данных.
Иногда от интеграции данных отличают интеграцию информации EII (Enterprise information integration) в корпоративных системах, осуществляемую из многочисленных систем в унифицированное, согласованное представление и используемую для изучения и обработки данных, необходимых для отчетности и принятия решений. EII является технологией извлечения ("вытягивания") информации (pull) в отличие от проталкивания (push) при интеграции данных.
Интеграция приложений (EAI — Enterprise Application Integration) основана на использовании сервисов — общеупотребительных прикладных и системных функций, реализованных в виде серверных программ со стандартным API. В виде сервисов реализуются разнообразные функции прикладной обработки, контроля безопасности данных, файлового доступа и т.п. Интеграция приложений характеризуется не только наличием конвертации языков, но и более сложным управлением потоками данных.
Интеграция приложений возможна путем удаленного вызова процедур (рис. 2) или обмена сообщениями.

|
Рис. 2.
Как и в случае интеграции данных, в технологиях EAI можно выделить варианты взаимодействия по схеме p2p и интеграционной шины.
Для варианта p2p на базе языка XML разработан специальный язык обмена сообщениями WS-CDL (Web Services Choreography Description Language). С его помощью формируются запросы и ответы взаимодействующих приложений. Поскольку вариант p2p является структурой "точка-точка", то он удобен только при малом числе связываемых приложений
Интеграционная шина (называемая также интеграционным сервером) представлет собой общую для связываемых компонентов среду передачи и обработки сообщений (рис. 1). С помощью шины осуществляется асинхронный обмен сообщениями и реализуется интеграция независимых приложений без или с минимальными доработками существующих систем. В отличие от варианта p2p, где за логику взаимодействия отвечала одна из интегрируемых систем, в данном варианте интеграцию обеспечивает интеграционная шина. Такой подход позволяет легче интегрировать новые системы, а также изменять логику интеграции, приводя ее в соответствие с бизнес-логикой процесса.
Примерами интегрирующей среды являются монитор транзакций, брокер ORB в технологии CORBA или другое программное обеспечение промежуточного слоя. Архитектура системы обычно является трехзвенной, n-звенной или компонентно-ориентированной. В интеграционном сервере возможна та или иная обработка данных, например, определение подсистемы-партнера может быть результатом анализа содержательной части сообщений.
Развитие интеграции приложений привело к появлению сервис-ориентированной архитектуры систем. Сервис-ориентированная архитектура SOA (Service Oriented Architecture) – это архитектура программной системы, обеспечивающей обнаружение и вызов сервисов с помощью не зависящего от платформы интерфейса.
Технология SOA, основанная на протоколе SOAP (Simple Object Access Protocol), — объектная технология, в которой объектами являются Web-службы (Web Services), а для представления обращений к Web-службам используется язык разметки XML. Термином "Сетевой сервис" или "Сетевая служба" в общем случае принято обозначать, во-первых, программное обеспечение, предоставляющее определенные услуги по обработке информации и/или доступу к ней и взаимодействующее с распределенными клиентскими приложениями через свой внешний интерфейс, во-вторых, собственно услуги и функции, выполняемые службой. Web-службой (Web-сервисом) называют сетевую службу (программный компонент), предоставляющую определенные услуги по обработке информации, объединяющую приложения, работающие на базе Web-технологий, использующую базовые средства Web, такие как XML и HTTP, и открытые стандарты (SOAP, WSDL и UDDI) в качестве Интернет-протоколов и взаимодействующую с распределенными клиентскими приложениями через свой внешний интерфейс
Интеграция процессов основана на организации сквозных процессов, в которых на отдельных этапах процесса задействованы те или иные приложения. Здесь не подразумевается существенное изменение отдельных приложений. При этом обработка данных на отдельных этапах может производиться в различных приложениях, а функции организации процесса и связи различных подсистем реализует специализированная подсистема. Для реализации этого способа интеграции приложений обычно применяют технологии WorkFlow.
Программное обеспечение интеграции часто объединяют под названием программ промежуточного слоя. Ведущие компании, занимающиеся корпоративными информационными системами, разрабатывают комплексные интегрирующие пакеты. К ним, в частности, относятся IBM WebSphere, Microsoft BizTalk Server, Oracle 10g, SAP Netweaver. Так, в BizTalk Server реализованы функции подготовки и транспортировки документов, документооборота.
К лингвистическому обеспечению интеграции автоматизированных систем относятся инвариантные к приложениям языки. Наиболее известными являются Express (из стандартов STEP), формат EDIFACT и язык разметки XML. Для описания бизнес-процессов разработан язык BPEL, основанный на XML. Для поддержки семантической согласованности данных используют язык описания метаданных RDFS и языки представления онтологий приложений, такие как OWL, также основанные на XML.
Для унификации способов обмена используют транспортные протоколы. В Web-технологиях общепризнанным является протокол HTTP. С его помощью описываются запросы и ответы при клиент-серверном взаимодействии. Для определения нужного сервера и организации связи в компонентно-ориентированной среде используют протоколы SOAP, UDDI и WSDL. При этом HTTP применяют в качестве транспортного средства для сообщений SOAP.
Список литературы
Дубина О. Обзор паттернов проектирования. — http://zeus.sai.msu.ru:7000/SE/project/pattern/p_4.shtml#5.2.1, 2005. 2. Understanding BizTalk Server 2004. — http://msdn2.microsoft.com/en-us/library/ms942195.aspx
Интеграция данных включает объединение данных, находящихся в различных источниках, и предоставление данных пользователям в унифицированном виде. Этот процесс становится существенным как в коммерческих задачах (когда двум похожим компаниям необходимо объединить их базы данных), так и в научных (комбинирование результатов исследования из различных биоинформационных репозиториев, для примера). Роль интеграции данных возрастает, когда увеличивается объём и необходимость совместного использования данных. Это стало фокусом обширной теоретической работы, а многочисленные проблемы остаются нерешёнными[ прояснить ].
Содержание
- 1 Уровни интеграции данных
- 2 Возникающие задачи
- 3 Архитектуры систем интеграции
- 3.1 Консолидация
- 3.2 Федерализация
- 3.3 Распространение данных
- 3.4 Сервисный подход
- 3.5 Кроме того
- 4 Проблемы интеграции информации
- 4.1 Типы несоответствия схем данных
- 4.2 Типы несоответствия собственно данных
- 5 Источники
- 6 См. также
Уровни интеграции данных[править | править вики-текст]
Системы интеграции данных могут обеспечивать интеграцию данных на физическом, логическом и семантическом уровне. Интеграция данных на физическом уровне с теоретической точки зрения является наиболее простой задачей и сводится к конверсии данных из различных источников в требуемый единый формат их физического представления. Интеграция данных на логическом уровне предусматривает возможность доступа к данным, содержащимся в различных источниках, в терминах единой глобальной схемы, которая описывает их совместное представление с учетом структурных и, возможно, поведенческих (при использовании объектных моделей) свойств данных. Семантические свойства данных при этом не учитываются. Поддержку единого представления данных с учетом их семантических свойств в контексте единой онтологии предметной области обеспечивает интеграция данных на семантическом уровне.[1]
Процессу интеграции препятствует неоднородность источников данных, в соответствии с уровнем интеграции. Так, при интеграции на физическом уровне в источниках данных могут использоваться различные форматы файлов. На логическом уровне интеграции может иметь место неоднородность используемых моделей данных для различных источников или различаются схемы данных, хотя используется одна и та же модель данных. Одни источники могут быть веб-сайтами, а другие — объектными базами данных и т. д. При интеграции на семантическом уровне различным источникам данных могут соответствовать различные онтологии. Например, возможен случай, когда каждый из источников представляет информационные ресурсы, моделирующие некоторый фрагмент предметной области, которому соответствует своя понятийная система, и эти фрагменты пересекаются.
Возникающие задачи[править | править вики-текст]
При создании системы интеграции возникает ряд задач, состав которых зависит от требований к ней и используемого подхода. К ним, в частности, относятся:
- Разработка архитектуры системы интеграции данных.
- Создание интегрирующей модели данных, являющейся основой единого пользовательского интерфейса в системе интеграции.
- Разработка методов отображения моделей данных и построение отображений в интегрирующую модель для конкретных моделей, поддерживаемых отдельными источниками данных.
- Интеграция метаданных, используемых в системе источников данных.
- Преодоление неоднородности источников данных.
- Разработка механизмов семантической интеграции источников данных.
Архитектуры систем интеграции[править | править вики-текст]
Консолидация[править | править вики-текст]
В случае консолидации данные извлекаются из источников, и помещаются в Хранилище данных. Процесс заполнения Хранилища состоит из трех фаз — извлечение, преобразование, загрузка (Extract, Transformation, Loading — ETL). Во многих случаях именно ETL понимают под термином «интеграция данных». Еще одна распространенная технология консолидации данных — управление содержанием корпорации (enterprise content management, сокр. ECM). Большинство решений ECM направлены на консолидацию и управление неструктурированными данными, такими как документы, отчеты и web-страницы.
Консолидация — однонаправленный процесс, то есть данные из нескольких источников сливаются в Хранилище, но не распространяются из него обратно в распределенную систему. Часто консолидированные данные служат основой для приложений бизнес-аналитики (Business Intelligence, BI), OLAP-приложений.
При использовании этого метода обычно существует некоторая задержка между моментом обновления информации в первичных системах и временем, когда данные изменения появляются в конечном месте хранения. Конечные места хранения данных, содержащие данные с большими временами отставания (например, более одного дня), создаются с помощью пакетных приложений интеграции данных, которые извлекают данные из первичных систем с определенными, заранее заданными интервалами. Конечные места хранения данных с небольшим отставанием обновляются с помощью оперативных приложений интеграции данных, которые постоянно отслеживают и передают изменения данных из первичных систем в конечные места хранения.
Федерализация[править | править вики-текст]
В федеративных БД физического перемещения данных не происходит: данные остаются у владельцев, доступ к ним осуществляется при необходимости (при выполнении запроса). Изначально федеративные БД предполагали создание в каждом из n узлов n-1 фрагментов кода, позволяющего обращаться к любому другому узлу. При этом федеративные БД отделяли от медиаторов[2].
При использовании медиатора создается общее представление (модель) данных. Медиатор — посредник, поддерживающий единый пользовательский интерфейса на основе глобального представления данных, содержащихся в источниках, а также поддержку отображения между глобальным и локальным представлениями данных. Пользовательский запрос, сформулированный в терминах единого интерфейса, декомпозируется на множество подзапросов, адресованных к нужным локальным источникам данных. На основе результатов их обработки синтезируется полный ответ на запрос. Используются две разновидности архитектуры с посредником — Global as View и Local as View.[1]
Отображение данных из источника в общую модель выполняется при каждом запросе специальной оболочкой (wrapper). Для этого необходима интерпретация запроса к отдельным источникам и последующее отображение полученных данных в единую модель. Сейчас этот способ также относят к федеративным БД.[3]
Интеграция корпоративной информации (Enterprise information integration, сокр. EII) — это пример технологии, которая поддерживает федеративный подход к интеграции данных.
Изучение и профилирование первичных данных, необходимые для федерализации, несильно отличаются от аналогичных процедур, требуемых для консолидации.
Распространение данных[править | править вики-текст]
Приложения распространения данных осуществляют копирование данных из одного места в другое. Эти приложения обычно работают в оперативном режиме и производят перемещение данных к местам назначения, то есть зависят от определенных событий. Обновления в первичной системе могут передаваться в конечную систему синхронно или асинхронно. Синхронная передача требует, чтобы обновления в обеих системах происходили во время одной и той же физической транзакции. Независимо от используемого типа синхронизации, метод распространения гарантирует доставку данных в систему назначения. Такая гарантия — это ключевой отличительный признак распространения данных. Большинство технологий синхронного распространения данных поддерживают двусторонний обмен данными между первичными и конечными системами. Примерами технологий, поддерживающих распространение данных, являются интеграция корпоративных приложений (Enterprise application integration, сокр. EAI) и тиражирование корпоративных данных (Еnterprise data replication, сокр. EDR). От федеративных БД этот способ отличает двустороннее распространение данных.[1]
Сервисный подход[править | править вики-текст]
Сервисно-ориентированная архитектура SOA (Service Oriented Architecture), успешно применяемая при интеграции приложений, применима и при интеграции данных. Данные также остаются у владельцев и даже местонахождение данных неизвестно. При запросе происходит обращение к определённым сервисам, которые связаны с источниками, где находится информация и ее конкретный адрес.
Интеграция данных объединяет информацию из нескольких источников таким образом, чтобы ее можно было показать клиенту в виде сервиса. Сервис — это не запрос в традиционном смысле обращения к данным, скорее, это извлечение некоторой бизнес-сущности (или сущностей), которое может быть выполнено сервисом интеграции через серию запросов и других сервисов. Подход SOA концентрируется, в первую очередь, на определении и совместном использовании в форме сервисов относительно ограниченного количества самых важных бизнес-функций в корпорации. Следовательно, сервис-ориентированные интерфейсы в довольно большой степени строятся на ограниченном количестве запросов на необходимую информацию, которую нужно представить потребителю.
Имея соответствующие учетные данные системы безопасности, потребитель может осуществить выборку любых данных из источника через почти неограниченное количество различных запросов SQL. Но для этого потребитель должен иметь представление о модели источника данных и способе создания результата с использованием этой базовой модели. Чем сложнее модель источника данных, тем более сложной может оказаться эта задача.[4]
Кроме того[править | править вики-текст]
В [1] описан пример гибридного подхода.
Другая классификация методов приведена в [5].
Проблемы интеграции информации[править | править вики-текст]
Вне зависимости от выбранных технологии и метода интеграции данных, остаются вопросы, связанные с их смысловой интерпретацией и различиями в представлении одних и тех же вещей. Именно, приходится разрешать несоответствие схем данных [6] и несоответствие самих данных.
Типы несоответствия схем данных[править | править вики-текст]
- Конфликты неоднородности (используются различные модели данных для различных источников)
- Конфликты именования (в различных схемах используется различная терминология, что приводит к омонимии и синонимии в именовании)
- Семантические конфликты (выбраны различные уровни абстракции для моделирования подобных сущностей реального мира)
- Структурные конфликты (одни и те же сущности представляются в разных источниках разными структурами данных).
Структурные и семантические конфликты выливаются в следующие проблемы:
- Различие в типах данных. Некоторый домен в одном источнике может представляться числом, в другом — строкой фиксированной длины, в третьем — строкой переменной длины.
- Различие в единицах измерения. В одной БД указана величина в сантиметрах, в другой — в дюймах. В этом случае существует отображение 1:1.
- Различие в множестве допустимых значений. Один и тот же признак может определяться разными наборами констант. Например, выполнение задания одним источником может оцениваться по четырехбальной шкале(неудовлетворительно, удовлетворительно, хорошо, отлично), другим — по трехбальной (-,±,+), третьим — по стобальной. Отображение не является 1:1, оно может быть многозначным, может не иметь обратного, может зависеть от сторонних данных (например, 30 по математике соответствовать «удовлетворительно», а по русскому языку — «неудовлетворительно»).
- Различие «домен-отношение». Домен в одной БД (напр строковое значение) соответствует таблице в другой БД (записи из таблицы-справочника).
- Различие «домен — группа доменов». В одном источнике адрес записывается одной строкой, в другом — отдельные поля для улицы, дома, строения, квартиры.
- Различие «данные-схема». Данные одной БД соответствуют схеме (метаданным) другой. В одной БД «инженер» — значение атрибута «должность» отношения «работник», в другой «инженеры» — отношение, содержащее некоторых работников, в то время как «бухгалтеры» содержит других.
- Отсутствующие значения. В каком-то из источников может отсутствовать информация, имеющаяся в большинстве других.
Разрешение этих несоответствий часто выполняется вручную. Обзор автоматических методов разрешения несоответствия схем можно найти в [7].
Типы несоответствия собственно данных[править | править вики-текст]
- Различие формата данных. «ул. Бахрушина, 18-1» или «Бахрушина, д.18, стр.1»; «8(910)234-45-32» или «8-910-234-45-32»
- Различие в представлении значений. Например, некая организация может быть записана в отдельных источниках как «Новолипецкий металлургический комбинат», «НЛМК», «ОАО НЛМК».
- Потеря актуальности данных одним из источников. Например, смена фамилии при замужестве: в одной БД записана новая фамилия, в другой старая, и они не совпадают.
- Наличие ошибок операторского ввода (или ошибок распознавания бланков) в отдельных источниках данных. Сюда относятся механические опечатки, ошибки восприятия на слух сложнопроизносимых имен/названий, отсутствие единых стандартов транскрипции с иностранных языков.
- Намеренное внесение искажений с целью затруднить идентификацию сущностей.
Перечисленные различия приводят к дублированию записей при интеграции данных в одну БД. Разрешение перечисленных проблем и устранение дублирования записей вручную практически невозможно. Имеется множество методов для ее автоматического и полуавтоматического решения. По-русски задача не имеет устоявшегося термина (применяются «сопоставление записей», «вероятностное соединение», «нестрогое соединение», «нестрогое соответствие»). В зарубежных работах эта задача носит название Identity resolution, или Record linkage (есть и другие синонимы). Обзор методов можно найти в [8].
Источники[править | править вики-текст]
Дата публикования: 2014-10-18; Прочитано: 10856 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
