 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Теоремы Шеннона
|
|
При передаче сообщений по каналам связи всегда возникают помехи, приводящие к искажению принимаемых сигналов. Исключение помех при передаче сообщений является очень серьезной теоретической и практической задачей. Её значимость только возрастает в связи с повсеместным внедрением компьютерных телекоммуникаций. Все естественные человеческие языки обладают большой избыточностью, что позволяет сообщениям, составленным из знаков таких языков, иметь заметную помехоустойчивость.
Избыточность могла бы быть использована и при передаче кодированных сообщений в технических системах. Самый простой способ повышение избыточности – передача текста сообщения несколько раз в одном сеансе связи. Однако большая избыточность приводит к большим временным затратам при передаче информации и требует большого объема памяти. К настоящему времени вопрос об эффективности кодирования изучен достаточно полно.
Пусть задан алфавит  , состоящий из конечного числа букв, конечная последовательность символов
, состоящий из конечного числа букв, конечная последовательность символов  из
из  называется словом, а множество всех непустых слов в алфавите обозначим через
называется словом, а множество всех непустых слов в алфавите обозначим через  . Аналогично для алфавита
. Аналогично для алфавита  слово обозначим
слово обозначим  , а множество всех непустых слов
, а множество всех непустых слов  .
.
Рассмотрим соответствие между буквами алфавита и словами алфавита  :
:  . Это соответствие называется схемой алфавитного кодирования и обозначается
. Это соответствие называется схемой алфавитного кодирования и обозначается  . Алфавитное кодирование определяется следующим образом: каждому слову
. Алфавитное кодирование определяется следующим образом: каждому слову  ставится в соответствие слово
ставится в соответствие слово  , называемое кодом слова
, называемое кодом слова 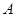 . Слова
. Слова  называются элементарными кодами. Ограничением задачи передачи кодов является отсутствие помех. Требуется оценить минимальную среднюю длину кодовой комбинации.
называются элементарными кодами. Ограничением задачи передачи кодов является отсутствие помех. Требуется оценить минимальную среднюю длину кодовой комбинации.
При разработке различных систем кодирования данных получены теоретические результаты, позволяющие получить сообщение с минимальной длиной кодов. Два положения из теории эффективности кодирования известны как теоремы Шеннона.
Первая теорема говорит о существовании системы эффективного кодирования дискретных сообщений, у которой среднее число двоичных символов (букв алфавита ) на один сообщения (букву алфавита ) асимптотически стремиться к энтропии источника сообщения, т. е. кодирование в пределе не имеет избыточности.
Рассмотрим вновь пример 1 из раздела 1.11, закодировав рассмотренное сообщение по алгоритму Фэно*. В таблице 1.12 приведены коды букв в сообщении (слова ), длина кода  , вероятности букв сообщения
, вероятности букв сообщения  величины
величины 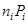 и
и 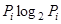 .
.
Таблица 1.12
| Но- мер | Бук- ва | Код |
|
|
|
|
| ж | 0.0294 | 0.1470 | -0.1496 | |||
| и | 0.1176 | 0.3528 | -0.3632 | |||
| л | 0.0883 | 0.3532 | -0.3092 | |||
| - | 0.0294 | 0.1470 | -0.1496 | |||
| б | 0.0883 | 0.3532 | -0.3092 | |||
| ы | 0.0294 | 0.1470 | -0.1496 | |||
| пробел | 0.1176 | 0.3528 | -0.3632 | |||
| а | 0.0294 | 0.1470 | -0.1496 | |||
| у | 0.0589 | 0.2356 | -0.2406 | |||
| ш | 0.0294 | 0.1470 | -0.1496 | |||
| к | 0.1176 | 0.3528 | -0.3632 | |||
| с | 0.0294 | 0.1470 | -0.1496 | |||
| е | 0.0589 | 0.2356 | -0.2406 | |||
| р | 0.0294 | 0.1470 | -0.1496 | |||
| н | 0.0294 | 0.1470 | -0.1496 |
Продолжение таблицы 1.12
| Но- мер | Бук- ва | Код |
|
|
|
|
| ь | 0.0294 | 0.1470 | -0.1496 | |||
| й | 0.0294 | 0.1470 | -0.1496 | |||
| о | 0.0294 | 0.1470 | -0.1496 | |||
| з | 0.0294 | 0.1470 | -0.1496 | |||

| 
| 
|
Математическое ожидание количества символов из алфавита при кодировании равно 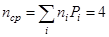 . Этому среднему числу символов соответствует максимальная энтропия
. Этому среднему числу символов соответствует максимальная энтропия  . Для обеспечения передачи информации, содержащейся в сообщении, должно выполняться условие
. Для обеспечения передачи информации, содержащейся в сообщении, должно выполняться условие 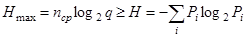 . В этом случае закодированное сообщение имеет избыточность. Коэффициент избыточности определяется следующим образом:
. В этом случае закодированное сообщение имеет избыточность. Коэффициент избыточности определяется следующим образом:
 , (1.12.1)
, (1.12.1)
 . В нашем случае
. В нашем случае  , т. е. код практически не имеет избыточности. Видно, что среднее число двоичных символов стремится к энтропии сообщения.
, т. е. код практически не имеет избыточности. Видно, что среднее число двоичных символов стремится к энтропии сообщения.
Вторая теорема Шеннона устанавливает принципы помехоустойчивого кодирования. Оказывается, что даже при наличии помех в канале связи всегда можно найти такую систему кодирования, при которой сообщение будет передано с заданной достоверностью. Основная идея всех таких кодов такова: для исправления возможных ошибок вместе с основным сообщением нежно передавать какую-то дополнительную информацию. Для реализации контроля возможных ошибок используются так называемые самокорректирующие коды, а по каналу связи вместе с 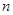 символами основного сообщения передаются ещё
символами основного сообщения передаются ещё  дополнительных символов, обеспечивающих избыточность кодирования и позволяющих противодействовать помехам.
дополнительных символов, обеспечивающих избыточность кодирования и позволяющих противодействовать помехам.
Дата публикования: 2014-11-04; Прочитано: 288 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
