 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Тест Голдфелда—Квандта
|
|
Вероятно, наиболее популярным формальным критерием является критерий, предложенный С. Голдфелдом и Р. Квандтом (Goldfeld, Quandt, 1956). При проведении проверки по этому критерию предполагается, что стандартное отклонение (σi) распределения вероятностей ui пропорционально значению х в этом наблюдении. Предполагается также, что случайный член распределен нормально и не подвержен автокорреляции.
Все n наблюдений в выборке упорядочиваются по величине х, после чего оцениваются отдельные регрессии для первых n ' и для последних n ' наблюдений; средние (n — 2 n) наблюдений отбрасываются. Если предположение относительно природы гетероскедастичности верно, то дисперсия u в последних n' наблюдениях будет больше, чем в первых n ' и это будет отражено в сумме квадратов остатков в двух указанных «частных» регрессиях. Обозначая суммы квадратов остатков в регрессиях для первых n ' последних n ' наблюдений соответственно через ESS1 и ESS2, рассчитаем отношение ESS2/ESS1, которое имеет F-распределение с (n '— k — 1) и (n '— k — 1) степенями свободы, где k — число объясняющих переменных в регрессионном уравнении. Мощность критерия за висит от выбора n ' по отношению к n. Основываясь на результатах некоторых проведенных ими экспериментов, С. Голдфелд и Р. Квандт утверждают, что n ' должно составлять порядка 11, когда n = 30, и порядка 22, когда n = 60. Если в модели имеется более одной объясняющей переменной, то наблюдения должны упорядочиваться по той из них, которая, как предполагается, связана с σ i, и n ' должно быть больше, чем k + 1 (где k — число объясняющих переменных).
Метод Голдфелда— Квандта может также использоваться для проверки на гетероскедастичность при предположении, что σ i обратно пропорционально xi. При этом используется та же процедура, что и описанная выше, но тестовой статистикой теперь является показатель ESS1/ESS2, который вновь имеет F-распределение с (n '— k —1) и (n '— k —1) степенями свободы.
Тест Глейзера
Тест Глейзера позволяет несколько более тщательно рассмотреть характер гетероскедастичности. Мы снимаем предположение о том, что σ i пропорционально хi, и хотим проверить, может ли быть более подходящей какая-либо другая функциональная форма, например
 (8.4)
(8.4)
Чтобы использовать данный метод, следует оценить регрессионную зависимость у от х с помощью обычного МНК, а затем вычислить абсолютные вели чины остатков |  | по функции (8.4) для данного значения у. Можно построить несколько таких функций, изменяя значение у. В каждом случае нулевая гипотеза об отсутствии гетероскедастичности будет отклонена, если оценка β значимо отличается от нуля. Если при оценивании более чем одной функции получается значимая оценка β, то ориентиром при определении характера гетероскедастичности может служить наилучшая из них.
| по функции (8.4) для данного значения у. Можно построить несколько таких функций, изменяя значение у. В каждом случае нулевая гипотеза об отсутствии гетероскедастичности будет отклонена, если оценка β значимо отличается от нуля. Если при оценивании более чем одной функции получается значимая оценка β, то ориентиром при определении характера гетероскедастичности может служить наилучшая из них.
4. Что можно сделать в случае гетероскедастичности?
Пусть σ i — стандартное отклонение случайного члена в наблюдении i. В том случае если бы было известно σi для каждого наблюдения, можно было бы устранить гетероскедастичность, разделив каждое наблюдение на соответствующее ему значение σ. Тогда случайный член в i -м наблюдении становится равным ui / σ i, и его теоретическая дисперсия представляется в виде:

что равняется: 
Это выражение переписывается как
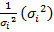
и, следовательно, оно равно единице. Таким образом, каждое наблюдение будет иметь случайный член, полученный из генеральной совокупности с единичной дисперсией, и модель будет гомоскедастичной. Теперь модель имеет вид:
 , (8.5) что может быть переписано как
, (8.5) что может быть переписано как
 , (8.6)
, (8.6)
где 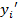 определяется как
определяется как 
 представляет собой
представляет собой 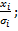
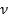 — новая переменная, i -е наблюдение которой равно
— новая переменная, i -е наблюдение которой равно  величина
величина  есть
есть  Следует отметить, что в данном уравнении не должно быть постоянного члена. Оценивая регрессионную зависимость у ' от и
Следует отметить, что в данном уравнении не должно быть постоянного члена. Оценивая регрессионную зависимость у ' от и  , мы получим эффективные оценки для α и β c несмещенными стандартными ошибками. Математическое доказательство того, что уравнение (8.6) даст более эффективные оценки, чем уравнение (8.1), выходит за рамки нашего курса, но здесь можно дать простое интуитивное объяснение. Наблюдения с наименьшими значениями σi будут наиболее полезными для определения истинной зависимости между у и х, поскольку величина случайного члена в них, как правило, наименьшая. Мы воспользуемся этим, оценивая так называемую взвешенную регрессию, придавая наибольшие веса наблюдениям самого «высокого качества», а наименьшие веса — соответственно, наблюдениям самого «низкого качества». Уравнение (8.6) можно рассматривать как «взвешенный» вариант уравнения (8.1), где значения у и х были умножены на величины 1/σi, которые, конечно, тем больше, чем меньше σi.
, мы получим эффективные оценки для α и β c несмещенными стандартными ошибками. Математическое доказательство того, что уравнение (8.6) даст более эффективные оценки, чем уравнение (8.1), выходит за рамки нашего курса, но здесь можно дать простое интуитивное объяснение. Наблюдения с наименьшими значениями σi будут наиболее полезными для определения истинной зависимости между у и х, поскольку величина случайного члена в них, как правило, наименьшая. Мы воспользуемся этим, оценивая так называемую взвешенную регрессию, придавая наибольшие веса наблюдениям самого «высокого качества», а наименьшие веса — соответственно, наблюдениям самого «низкого качества». Уравнение (8.6) можно рассматривать как «взвешенный» вариант уравнения (8.1), где значения у и х были умножены на величины 1/σi, которые, конечно, тем больше, чем меньше σi.
Препятствием для этой процедуры является то, что вам почти наверняка будут неизвестны фактические значения σi. Однако процедура будет применимой, если мы сможем подобрать некоторую величину, пропорциональную, по нашему мнению, σ в каждом наблюдении, и разделим на нее обе части уравнения.
Допустим, есть основания предположить, что некоторая величина z пропорциональна σi и  , где
, где  — некоторая константа. После деления на z уравнение принимает вид:
— некоторая константа. После деления на z уравнение принимает вид:
 (8.7)
(8.7)
Дисперсия случайного члена представлена как
 ,
,
что равно 1 / 2. Следовательно, эта величина постоянна для всех наблюдений, и проблема устранена.
Например, может оказаться целесообразным предположить, что σ приблизительно пропорционально х, как в критерии Голдфелда—Квандта. Если после этого мы разделим каждое наблюдение на соответствующее ему значение х, то уравнение (8.1) примет вид:
 (8.8)
(8.8)
и при этом, если повезет, новый случайный член u/ х будет иметь постоянную дисперсию. Затем мы оцениваем регрессионную зависимость у / х от 1/ х, включив в уравнение постоянный член. Коэффициент при 1/ х будет эффективной оценкой α, а постоянный член — эффективной оценкой β. В примере с расходами на образование, рассмотренном в предыдущем пункте, зависимой переменной будут государственные расходы на образование как доля ВВП, а объясняющей переменной — обратная к ВВП величина.
Иногда в нашем распоряжении может оказаться несколько переменных, каждую из которых можно использовать для масштабирования уравнения. В примере с расходами на образование альтернативной переменной является численность населения страны (Р). Разделив обе части уравнения (8.1) на эту величину, получаем:
 , (8.9)
, (8.9)
и мы снова надеемся на то, что случайный член u i / P i будет иметь постоянную дисперсию для всех наблюдений. Таким образом, теперь оценивается регрессионная зависимость государственных расходов на образование на душу населения от ВВП на душу населения и обратной величины от численности населения, причем на этот раз без постоянного члена.
На практике имеет смысл попробовать использовать несколько разных переменных для масштабирования наблюдений и сравнить затем результаты. Если каждый раз получаются сходные результаты и тесты не дают оснований отклонять нулевую гипотезу о гомоскедастичности, то проблему можно считать решенной.
Дата публикования: 2015-11-01; Прочитано: 1014 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
