 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Иерархическая БД
|
|
В иерархической БД существует упорядоченность элементов в записи, один элемент считается главным, остальные – подчиненными. Данные в записи упорядочены в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться лишь последовательным «спуском» со ступеньки на ступеньку. Поиск какого-либо элемента данных в такой системе может оказаться довольно трудоемким из-за необходимости последовательно проходить несколько предшествующих иерархических уровней. Иерархическую БД образует каталог файлов, хранимых на диске; дерево каталогов, доступное для просмотра в Norton Commander, – наглядная демонстрация структуры такой БД и поиска в ней нужного элемента (при работе в операционной системе MS-DOS). Такой же базой данных является родовое генеалогическое дерево.
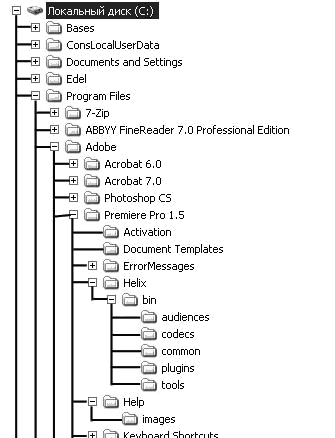
А)
Б)
Рисунок 12.1. Иерархическая модель базы данных
Сетевая БД
Эта база данных отличается большей гибкостью, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требует обязательного прохождения всех предшествующих ступеней.
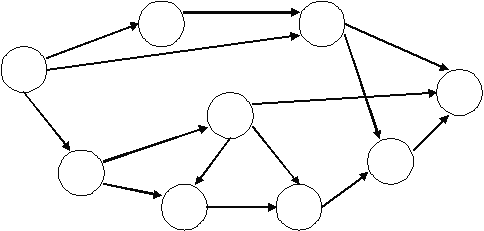
Рисунок 12.2. Сетевая модель базы данных
Реляционная БД
Наиболее распространенным способом организации данных является третий, к которому можно свести как иерархический, так и сетевой – реляционный (англ. relation – отношение, связь). В реляционной БД под записью понимается строка прямоугольной таблицы. Элементы записи образуют столбцы этой таблицы (поля). Все элементы в столбце имеют одинаковый тип (числовой, символьный), а каждый столбец – неповторяющееся имя. Одинаковые строки в таблице отсутствуют. Преимущество таких БД – наглядность и понятность организации данных, скорость поиска нужной информации. Примером реляционной БД служит таблица на странице классного журнала, в которой записью является строка с данными о конкретном ученике, а имена полей (столбцов) указывают, какие данные о каждом ученике должны быть записаны в ячейках таблицы.

Рисунок 12.3. Реляционная модель базы данных
Совокупность БД и программы СУБД образует информационно-поисковую систему, называемую банком данных.
1. По технологии обработки данных базы данных делятся на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная Система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Этот способ использования баз данных часто применяют в локальных сетях ПК. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
2. По способу доступа к данным базы данных делятся на базы данных с локальным доступом и базы данных с удаленным (сетевым доступом). Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры таких систем: файл-сервер; клиент-сервер.
Файл-сервер
Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность такой информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Схема обработки информации по принципу файл-сервер изображена на рисунке.
Клиент-сервер
В отличие от предыдущей системы, центральная машина (сервер базы данных), помимо хранения централизованной базы данных, должна обеспечивать выполнение основного объема обработки данных. Запрос на использование данных, выдаваемый клиентом (рабочей станцией), приводит к поиску и извлечению данных на сервере. Извлеченные данные транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL.
Дата публикования: 2015-11-01; Прочитано: 1777 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
