 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Табличные языки запросов. Работа с вычисляемыми полями. Использование агрегирующих функций
|
|
В современных СУБД широко используются табличные языки запросов. Наиболее распространенным среди них является язык QBE (Query-By-Example - запрос по примеру). Язык QBE предназначен для работы в интерактивном режиме и ориентирован на конечного пользователя. Язык QBE реализован во многих современных СУБД, например в dBase IV и более старших версиях этой системы, Paradox, Access и др. Конкретные реализации этого языка несколько отличаются друг от друга, но все они построены по единому принципу.
Суть подхода, воплощенного в языке QBE, заключается в следующем. В окне формирования запроса выделяются две зоны. В первой из них высвечивается «скелет» (образ, форма, структура) одной или нескольких таблиц, данные из которых будут участвовать в запросе. В качестве исходных для запроса могут указываться не только базовые таблицы, но и другие запросы.
Во второй зоне («скелете» запроса табличной формы) пользователь задает условия запроса. В этой зоне пользователь определяет, какие поля участвуют в формировании запроса, а также условия отбора и некоторые другие характеристики запроса. Например, если пользователю необходимо получить все записи с заданным значением конкретного атрибута, то в соответствующем столбце «скелета» указывается это значение.
При создании запросов часто возникает необходимость не только использовать имеющиеся поля таблиц, но и создавать на их основе другие поля, которые называются вычисляемыми. Например, если в таблице какого-либо магазина имеется поле цены на товар и поле количества этого товара, то, исходя из этого, можно создать вычисляемое поле, в котором будет подсчитываться общая стоимость для каждого товара путем перемножения значений цены и количества. Другими словами, в вычисляемом поле могут использоваться арифметические операторы.
При статистическом анализе баз данных необходимо получать такую информацию, как общее количество записей, наибольшее и наименьшее значения заданного поля записи, усредненное значение поля и т. д. Данная задача выполняется с помощью запросов, содержащих так называемые агрегирующие функции.
Агрегирующие функции производят вычисление одного «собирающего» значения (суммы, среднего, максимального, минимального значения и т. п.) для заданных групп строк таблицы. Группы строк определяются различными значениями заданного поля (полей) таблицы. Разбиение на группы выполняется с помощью предложения group by.
Рассмотрим перечень агрегирующих функций.
- count определяет количество записей данного поля в группе строк.
- sum вычисляет арифметическую сумму всех выбранных значений данного поля.
- avg рассчитывает арифметическое среднее (усреднение) всех выбранных значений данного поля.
- max находит наибольшее из всех выбранных значений данного поля.
- min находит наименьшее из всех выбранных значений данного поля.
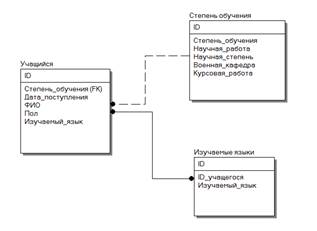
3. Задача. Построить модель в ERWin
 Билет №3
Билет №3
Дата публикования: 2015-10-09; Прочитано: 1386 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
