 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Логическая организация файлов
|
|
• Два подхода к логической организации файлов
Очевидно, что на самом нижнем уровне представления вся информация, касающаяся файла (и собственно данные, и управляющая информация), - не более чем совокупность байтов. Интерпретация (осмысление) этой совокупности на том или ином уровне (уровне устройства; ОС; приложения; пользователя) представляет собой уже соответствующий логический уровень.
Пользователем данные файла интерпретируются в соответствии с содержанием решаемой задачи. Эта интерпретация в той или иной степени отображается в программе - описании данных и операциях с ними, в частности, файловых операциях. Далее в зависимости от используемых операций уже операционная система понимает файл как имеющий (с ее точки зрения) некоторую структуру или как простую последовательность байтов. Хотя понятие «смысл данных» для каждого уровня свое, эти уровни интерпретации тесно связаны тем, какие осмысленные единицы выделил в данных файла пользователь и как он отобразил их в программе.
Все системные программы предназначены для решения своих специфических задач, поэтому в каждую из них заложено «понимание» своего формата данных (компилятор генерирует объектный модуль определенного формата как выходные данные; для редактора связей это формат входных данных; файловая система должна различать разные типы файлов и т.д.). Поэтому вопрос о структуре файлов относится прежде всего к обычным пользовательским файлам с произвольным с точки зрения ФС содержанием.
В первых ОС (OS 360, ОС малых машин) структурирование данных в файле поддерживалась файловой системой. Это означает, что программист на соответствующем языке ОС описывал желаемую структуру, а ОС создавала файл с соответствующей организацией (так, OS 360 поддерживала несколько типов файлов с достаточно сложной структурой). Развитием этого подхода стали системы управления базами данных.
В настоящее время наиболее популярна модель файла как неструктурированной (неинтерпретируемой) последовательности байтов. Эта модель является более гибкой и эффективной для работы ОС, например, с точки зрения обмена с внешними устройствами, с точки зрения разделения файла между приложениями и т.д.
Первый подход предполагает, что единица данных для обмена с внешним устройством также осмысленна и определяется программистом. Такая единица называется логической записью, и информация о том, что является такой записью, явно присутствует в программе или сообщается ОС на соответствующем языке. ОС должна обеспечивать доступ к отдельной записи как неделимой единице.
Способ доступа к записям файла определяет порядок их обработки (считывания - записи). Возможны два способа доступа:
· последовательный - доступной для обработки является запись, непосредственно следующая за обработанной; так, если была обработана 3-я запись, то доступной является только 4-я; чтобы получить доступ к 5-й, надо обработать (хотя бы пропустить) 4-ю;
· прямой - каждая запись имеет некоторый ключ; доступной для обработки является запись с заданным ключом, вне зависимости от того, какая запись была доступна перед этим; так, если ключом является номер записи и была обработана 3-я запись, то получить доступ к 5-й можно, указав ее номер в соответствующих операторах.
Способ доступа к записям и способ структурирования файла взаимосвязаны. Реально операционными системами поддерживается (или поддерживалось) небольшое число схем структурирования, три из которых приведены на рис. 4.3 - 4.5.
Возможен и последовательный, и прямой доступ по номеру записи, так как начальный адрес любой записи легко вычисляется исходя из ее номера и длины.
Для каждой записи задается ее длина. Возможен только последовательный доступ, так как вычислить адрес некоторой записи по ее номеру нельзя.

Рисунок 4.3 - Последовательная организация с записями фиксированной длины

Рисунок 4.4 - Последовательная организация с записями переменной длины
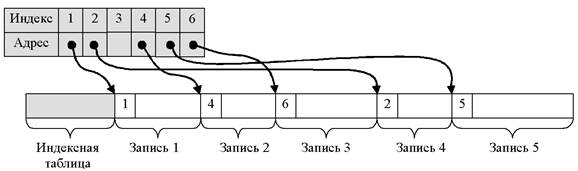
Рисунок 4.5 - Прямая организация. Индексированный файл
Записи имеют одно или более ключевых, или индексных, полей и могут быть расположены в произвольном порядке. Обращение происходит к записи с заданным ключом. Для быстрого поиска строится индексная таблица, содержащая упорядоченный список ключевых полей записей с сопоставленными им адресами записей в файле. Доступ осуществляется в два этапа: сначала по имени файла определяется адрес индексной таблицы, затем - собственно доступ.
Расширением этого способа организации является индексно-последовательная организация, когда адрес индексной таблицы указывает на группу записей, просматриваемых последовательно.
На уровне программирования способ доступа определяется операциями языка программирования.
Второй подход предполагает, что приложение полностью берет на себя интерпретацию содержимого файла, а обмен между оперативной и внешней памятью осуществляется последовательностями байтов заданной длины, начиная с заданной позиции. Такие неинтерпретированные последовательности обычно называются блоками (паскаль, Си). Структура блока никак не отображается в структуре файла.
Этот подход выигрывает не только с точки зрения эффективности работы ОС, но и с точки зрения программирования, если при проектировании ввода-вывода учесть некоторые моменты.
- В программе характеристики блока обязаны присутствовать, и в первую очередь надо определить, что именно будет выступать в качестве блока. Для корректной работы с файлом структура его содержимого должна быть известна, и в общем случае данные осмысленны. Поэтому в качестве блока как единицы обмена реально выбирается осмысленная совокупность данных, т.е. то, что в первом подходе представляло собой логическую запись.
- Практически в операциях прямого доступа в качестве ключа рассматривается номер записи. Тогда оптимальной оказывается схема рис. 4.3. Такая схема реальна для файлов во внутреннем представлении (т.е. в представлении согласно типу, описанному в программе). В этом случае все блоки будут иметь один и тот же смысл и в то же время одну и ту же длину.
-Для чтения данных во внешнем представлении, записанных в виде обычного текста, в программе должны быть использованы операторы, понимающие такой текст как последовательность, включающую числа, символы и строки. В паскале это означает описание файла как текстового (тип text) и соответствующий способ считывания его компонентов; в Си используется форматированный ввод (потоковый или файловый, с форматированием по умолчанию, либо явным заданием форматов).
Дата публикования: 2015-10-09; Прочитано: 1062 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
