 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Неравномерное кодирование для последовательности сообщений
|
|
Разумеется, если мы рассматриваем стационарный источник и его распределение вероятностей на буквах не меняется от буквы к букве, то любой из описанных выше способов может быть использован для кодирования отдельных сообщений источника. Во многих случаях именно такой подход используется на практике как самый простой и достаточно эффективный.
В то же время, можно выделить класс ситуаций, когда побуквенное кодирование заведомо неоптимально. Во-первых, из теоремы об энтропии на сообщение стационарного источника следует, что учет памяти источника потенциально может значительно повысить эффективность кодирования. Во-вторых, побуквенные методы затрачивают, как минимум 1 бит на сообщение, тогда как энтропия на сообщение может быть значительно меньше 1.
Итак, рассмотрим последовательность 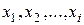 наблюдаемую на выходе дискретного стационарного источника, для которого известно вероятностное описание, т.е. можно вычислить все многомерные распределения вероятностей и по ним — энтропию
наблюдаемую на выходе дискретного стационарного источника, для которого известно вероятностное описание, т.е. можно вычислить все многомерные распределения вероятностей и по ним — энтропию  .
.
Пусть указан некий способ кодирования, который для любых  для каждой последовательности
для каждой последовательности  на выходе источника строит кодовое слово
на выходе источника строит кодовое слово  с длиной
с длиной  . Тогда средняя длина кода на сообщение для блоков длиной определяйся как
. Тогда средняя длина кода на сообщение для блоков длиной определяйся как
 бит/сообщение источника.
бит/сообщение источника.
Подбирая длину блоков, при которой средняя длина кода будет наименьшей, получаем следующее определение для средней длины, кода на сообщение:
 .
.
Здесь пишем нижнюю грань  вместо минимума, поскольку наименьшее значение скорости может достигаться при
вместо минимума, поскольку наименьшее значение скорости может достигаться при  .
.
Рассматриваемое кодирование называется  -кодированием (fixed to variable), поскольку блоки из фиксированного числа сообщений и кодируются кодовыми словами переменной длины. Наша задача — связать достижимые значения средней скорости -кодирования с характеристиками источника, в частности, с его энтропией . Начнем с обратной теоремы кодирования.
-кодированием (fixed to variable), поскольку блоки из фиксированного числа сообщений и кодируются кодовыми словами переменной длины. Наша задача — связать достижимые значения средней скорости -кодирования с характеристиками источника, в частности, с его энтропией . Начнем с обратной теоремы кодирования.
Теорема 8.4. Для дискретного стационарного источника с энтропией для любого -кодирования имеет место неравенство
 .
.
Теорема 8.5 (прямая теорема кодирования). Для дискретного стационарного источника с энтропией и для любого  существует такой способ неравномерного -кодирования, для которого
существует такой способ неравномерного -кодирования, для которого
 .
.
Итак, выбрав достаточно большую длину блоков п и применив к блокам побуквенное кодирование, мы получим кодирование со средней длиной
 ,
,
где  при .
при .
К сожалению, этот внешне оптимистический результат оказывается почти бесполезным при решении практических задач. Основное препятствие на пути его применения — это экспоненциальный рост сложности при увеличении длины блоков п. Поясним эту проблему следующим простым примером.
Предположим, что кодированию подлежат файлы, хранящиеся в памяти компьютера. Символы источника — байты и, значит, объем алфавита  . При кодировании последовательностей длиной п = 2 объем алфавита увеличивается до
. При кодировании последовательностей длиной п = 2 объем алфавита увеличивается до  . Далее при п = 3, 4,... объемы алфавита будут составлять
. Далее при п = 3, 4,... объемы алфавита будут составлять  ,
,  ,... Понятно, что работать с кодами таких размеров невозможно.
,... Понятно, что работать с кодами таких размеров невозможно.
Описываемый в следующем разделе метод арифметического кодирования позволяет эффективно кодировать блоки длины с избыточностью порядка  со сложностью, растущей только пропорционально квадрату длины блока . За счет пренебрежимо малого проигрыша в средней длине кода на сообщение сложность может быть сделана даже линейной по длине кода. Неудивительно, что арифметическое кодирование все шире применяется в разнообразных системах обработки информации.
со сложностью, растущей только пропорционально квадрату длины блока . За счет пренебрежимо малого проигрыша в средней длине кода на сообщение сложность может быть сделана даже линейной по длине кода. Неудивительно, что арифметическое кодирование все шире применяется в разнообразных системах обработки информации.
Дата публикования: 2015-09-17; Прочитано: 600 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
