 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Экономических объектов 3 страница
|
|
Нормальное распределение обладает следующими важными свойствами:
- нормальная случайная величина S с математическим ожиданием á S ñ и стандартным отклонением s с вероятностью близкой к 1 попадает в интервал (правило трех сигм)
(á S ñ ‑ 3 s) £ S £ (á S ñ + 3 s);
- если случайная величина S распределена по нормальному закону с математическим ожиданием á S ñ и стандартным отклонением s, то
F (s) = Pr (S £ s) = Ф (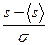 ), Pr (S > s) = 1 – Ф (),
), Pr (S > s) = 1 – Ф (),
где Ф – интеграл ошибок, определяемый (2.4.2) и (2.4.9).
Пример: некая фирма имеет среднюю доходность по своим акциям á S ñ = 15%, а стандартное отклонение s = 3,87%. Одномерные нормальные законы (плотность (2.4.9) и функция (2.4.2) распределения вероятности) показаны на рис. 2.4.3 и 2.4.4 соответственно.

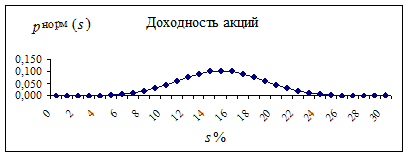
Рис. 2.4.3
Согласно правилу трех сигм, с вероятностью, близкой к 1, можно утверждать, что доходность по акциям фирмы будет лежать в диапазоне 15% ±11,61% (от 3,39% до 26,61%). При этом, вероятность попадания доходности в интервал 15% ±7,74% (á S ñ ± 2s) составит примерно 68%.
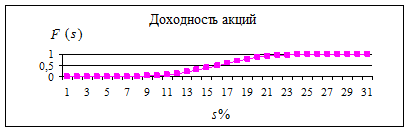 Рис. 2.4.4
Рис. 2.4.4
Произвольный закон.
Истинное распределение может описываться совершенно произвольным законом. Во многих случаях закон распределения неизвестен, и его необходимо оценивать. Пусть p *(S) – оценка истинной плотности распределений p ист(S). Будем искать такую оценку, которая обеспечивает минимизацию среднеквадратичной ошибки
СКО = ò.òò [ p *(S) – p ист(S)]2 d (N) S Þ min, (2.4.10)
где d (N) S = d S 1 d S 2 … d SN.
Разложим оценку p *(S) в ряд
p *(S) = 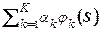 (2.4.11)
(2.4.11)
по системе ортонормированных функций j k (S). Ортонормированность означает
ò.òò j k (S) j m (S) d ( N ) S =  (2.4.12)
(2.4.12)
Подставив (2.4.11) в (2.4.10), получим
СКО = ò.òò [ 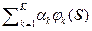 – p ист(S)]2 d (N) S. (2.4.13)
– p ист(S)]2 d (N) S. (2.4.13)
Необходимые условия минимума (2.4.13) заключаются в том, что
¶ СКО / ¶ ak = ò.òò [ – p ист(S)] j k (S) d (N) S = 0 для " k или
ak = ò.òò p ист(S) j k (S) d (N) S = (1 / M) 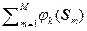 . (2.4.14)
. (2.4.14)
В (2.4.14) использована замена теоретического среднего значения функции j k (S) его эмпирическим средним (см. 2.4.20).
Таким образом, оценкой истинной плотности распределения является
p *(S) = (1/M) 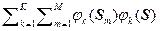 . (2.4.15)
. (2.4.15)
Оценка коэффициентов ak может быть получена рекуррентно. Так, если получена оценка (2.4.14) ak (M) по выборке объема M, то выражение для коэффициента при увеличении выборки на один объект имеет вид (см. 2.4.22)
ak (M +1) = [1/(M +1)] [ 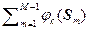 ] =
] =
= [1/(M +1)] [ M ak (M) + j k (S M + 1)]. (2.4.16)
Часто закон распределения приближают с помощью парзеновских окон (по имени Парзена)
p * M (S) = (1/ M) 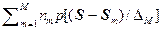 , (2.4.17)
, (2.4.17)
где функция окна p [(S – S m)/D M ] является некоторым распределением, центрированным в S m и обладающим шириной D M, зависящим от числа выборок M. Как правило, с ростом M ширина окна сужается. Величина nm соответствует количеству выборок, попавших в «точку» S m. При M @ 100 парзеновское приближение практически сходится к истинному распределению.
Статистики наблюдений, достаточные статистики.
Статистикой наблюдаемого состояния S называют среднюю величину á f ñ любой функции f [ S ] от наблюдений
á f ñ = ò.òò p ист(S) f [ S ] d (N) S. (2.4.18)
Нормальные законы распределения зависят лишь от статистик первого и второго порядка – средних значений á S ñ наблюдений и их ковариаций COV (дисперсий s 1, s 12…, s 1 n, s n, …)
á S ñ = ò.òò p нор(S) S d (N) S, (2.4.19)
COV = ò.òò p нор(S) (S – á S ñ)(S – á S ñ)+ d (N) S.
Выражение (2.4.19) определяет теоретическое среднее функции f [ S ], когда известна p ист(S), как непрерывная функция S. На практике обычно наблюдают множество (ансамбль) { S } = = { S 1, S 2, …, S m, …, S M } M различных значений или выборок (см. рис 2.4.2б) векторов состояний, которое порождает ансамбль { f [ S ]} = { f [ S 1], f [ S 2], …, f [ S m ], …, f [ S M ]} разнообразных значений выборочных функций этих состояний. Тогда эмпирическое или выборочное среднее значение функции f [ S ] определяется выражением
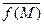 = (1/M)
= (1/M)  . (2.4.20)
. (2.4.20)
Например, эмпирические или выборочные значения среднего и ковариационной матрицы определяются выражениями
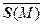 = (1/M)
= (1/M) 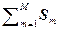 , (2.4.21)
, (2.4.21)
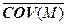 = [1/(M –1)]
= [1/(M –1)] 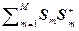 –
– 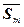 +.
+.
Оценка эмпирического или выборочного среднего значения функции f [ S ] может быть получена рекуррентно. Так, если получена оценка (2.4.20) по выборке объема M, то выражение для среднего при увеличении выборки на один объект имеет вид
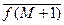 = [1/(M +1)] [ ] =
= [1/(M +1)] [ ] =
= [1/(M +1)] [ M 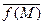 + f (S M +1)]. (2.4.22)
+ f (S M +1)]. (2.4.22)
Так, например, для среднего значения и ковариационной матрицы получим
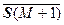 = [1/(M +1)] [ M + S M+ 1], (2.4.23)
= [1/(M +1)] [ M + S M+ 1], (2.4.23)
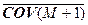 = [1/(M +1)] [ M +
= [1/(M +1)] [ M +
+ M + + S M+ 1 S + M+ 1] – [1/(M +1) 2 ] [ M +
+ S M+ 1] [ M + S M+ 1]+.
Естественно, что задавая различные функции fk [ S ], где k = 1, 2, …, K, возможно построить множество различных статистик. Однако только некоторые из них позволяют достаточно полно, как и сама плотность распределения p ист(S), описать случайные наблюдения. Такие статистики называют достаточными статистиками. Для нормально распределенных случайных наблюдений их средние значения и ковариационные матрицы (дисперсии) являются достаточными статистиками.
Понятие достаточных статистик обычно формализуют следующим образом. Предполагают, что форма плотности распределения p (S ½ P) известна с точностью до некоторого вектора P структурных параметров. Тогда формальное определение достаточной статистики дает теорема факторизации, утверждающая, что статистика 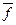 достаточна для оценки неизвестного вектора P структурных параметров тогда и только тогда, когда вероятность p (S ½ P) можно записать в виде произведения
достаточна для оценки неизвестного вектора P структурных параметров тогда и только тогда, когда вероятность p (S ½ P) можно записать в виде произведения
p (S ½ P) = h (S) g (, P), (2.4.24)
где h (S) и g (, P) являются независимыми функциями.
Многие наблюдения, плотности вероятностей которых не подчиняются нормальному закону, могут быть описаны статистиками второго порядка ‑ их средними значениями и ковариационными матрицами. Очевидно, что это возможно при достаточно хорошей аппроксимации (в смысле 2.4.13) истинных плотностей вероятностей p ист(S) нормальными плотностями p нор(S).
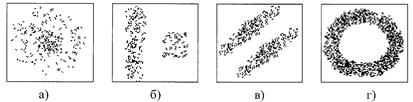
Однако встречаются случаи, когда такая аппроксимация принципиально невозможна. Так, на рис. 2.4.5 показаны четыре различных кластера данных, у которых одинаковые средние и матрицы ковариаций. Очевидно, что статистики второго порядка не в состоянии отобразить структуру приведенных наблюдений.
Рис. 2.4.5
2.5. Несмещенность, эффективность и состоятельность
статистических оценок. Расчет статистик.
Выборкой в статистике называют последовательность независимых одинаково распределенных случайных величин. Следует помнить, что любая из эмпирических оценок любой функции f [ S ] от наблюденийявляется случайной величиной. Все данные оценки производятся на конечном ряде выборок случайных величин (M = const), которые не исчерпывают их всевозможные значения, называемые генеральной совокупностью (M ® ¥). Поэтому будет всегда присутствовать ошибка, которую желательно свести к минимуму. Для этого используют некоторые критерии, которые позволяют минимизировать различия оценок функций, полученных для конечного ряда выборок и генеральной совокупности, т.е. и теоретического математического ожидания á f ñ.
Несмещенными называются такие оценки, математические ожидания которых равняются теоретическим математическим ожиданиям, полученным при использовании генеральной совокупности.
Например, выборочные среднее и ковариационная матрица (2.4.21) являются несмещенными оценками теоретических среднего и ковариационной матрицы.
Легко показать, что число несмещенных оценок бесконечно. Пусть, например, мы построим среднее значение величины функции f [ S ], используя ее выборочные значения { f [ S 1], f [ S 2], …, f [ S m ], …, f [ S M ]} и некоторый набор { l 1, l 2, …, lM } произвольных коэффициентов
= 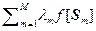 . (2.5.1)
. (2.5.1)
Спрашивается – равно ли теоретическому среднему á f ñ? Усредним обе части (2.5.1) по генеральной совокупности
á ñ = = á ñ =
= 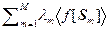 = á f ñ
= á f ñ 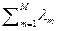 . (2.5.2)
. (2.5.2)
Из (2.5.2) видно, что если выполняется условие == 1, то выражение (2.5.1) определяет бесконечное число несмещенных оценок.
Эффективность. Найдем дисперсию выражения (2.5.1) при условии, что оценка несмещенная
Df ({ lm }) = á(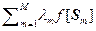 )2ñ – á ñ2 =
)2ñ – á ñ2 =
= á 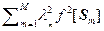 + 2
+ 2 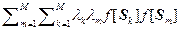 ñ –
ñ –
– á f ñ2 ()2 = á f 2ñ 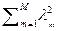 +
+
+ 2á f ñ2 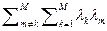 – á f ñ2 ()2 =
– á f ñ2 ()2 =
= [á f 2ñ – á f ñ2] . (2.5.3)
Очевидно, что несмещенное среднее будет иметь минимально возможную дисперсию
Df = [á f 2ñ – á f ñ2] / M = s f 2 / M, (2.5.4)
если все lm = 1/ M. С ростом M дисперсия оценки выборочного среднего будет стремится к нулю.
Считается, что оценка выборочного среднего является эффективной, если ее дисперсия минимально возможна.
Приведенные примеры доказывают, что только выражение (2.4.20) дает несмещенную и эффективную оценку среднего значения функции f [ S ].
Состоятельными называются такие оценки, которые дают точные значения для больших выборок (M), независимо от входящих в них конкретных наблюдений.
Из предыдущих примеров видно, что выражение (2.4.20) дает состоятельную оценку среднего значения функции f [ S ].
Из выражения (2.5.4) видно, что при M ® ¥ дисперсия Df оценки выборочного среднего значения стремится к 0.
Однако при малых M оценки могут смещаться относительно теоретического среднего á f ñ. При этом состоятельная оценка может на малых выборках работать хуже, чем несостоятельная (например, иметь большую среднеквадратичную ошибку).
В экономике часто пользуются индексами в виде частного от деления одной величины на другую
Z (M)= X (M) / Y (M), (2.5.5)
где X (M) и Y (M) – величины, рассчитанные по данным выборки с размерностью M. Обычно невозможно сказать, что либо определенное о математическом ожидании величины Z. Вообще говоря, она не равна частному от деления  на
на  . Если, однако, X (M) и Y (M) стремятся к конечным величинам plim X и plim Y при больших M и plim Y не равен нулю, то величина Z будет стремится к
. Если, однако, X (M) и Y (M) стремятся к конечным величинам plim X и plim Y при больших M и plim Y не равен нулю, то величина Z будет стремится к
plim Z = plim X / plim Y. (2.5.6)
Выражение plimZ означает «предел по вероятности» и подчеркивает, что предел достигается в вероятностном смысле, когда для любых сколь угодно малых значений e и d можно найти такое большое M, при котором вероятность того, что Z отличается от plim Z больше, чем на e, будет меньшей d.
Следовательно, даже если нельзя сказать что-либо определенное о свойствах Z на малых выборках, иногда можно судить о ее состоятельности.
Расчет статистик второго порядка.
Правила расчета ковариаций.
Правило 1:
Если Y = V + W, то
cov (X, Y) = cov (X, V + W) = cov (X, V) + cov (X, W).
Правило 2:
Если Y = a Z, где a – константа, то cov (X, Y) = a cov (X, Z).
Правило 3:
Если Y = a, где a – константа, то cov (X, Y) = 0.
Пользуясь этими основными правилами, можно упрощать значительно более сложные выражения с ковариациями. Например, если Y = U + V + W, то пользуясь правилом 1 и разбив Y на две части (U и V + W), получим
cov (X, Y) = cov (X, U + V+W) = cov (X, U)+ cov (X, V+W) =
= cov (X, U) + cov (X, V) + cov (X, W).
Другой пример: Если Y = a + b Z, где a и b – константы, то, пользуясь последовательно правилами 1, 3, 2, получим
cov (X, Y) = cov (X,a)+ cov (X, bZ)=0+ cov (X, bZ)= bcov (X, Z).
Правила расчета дисперсий.
Правило 1:
Если Y = V + W, то var (Y) = var (V) + var (W) + 2 cov (V, W).
Правило 2:
Если Y = a Z, где a – константа, то var (Y) = a2 var (Z).
Правило 3:
Если Y = a, где a – константа, то var (Y) = 0.
Правило 4:
Если Y = Z + a, где a – константы, то var (Y) = var (Z).
Как следует из определения дисперсии var (X) = cov (X, X).
Правила расчета коэффициентов корреляций.
Теоретический и выборочный коэффициент корреляции случайных величин X и Y задаются выражениями
rXY = sXY / (s 2X s 2Y )1/2, (2.5.7)
rXY = cov (X, Y)/ [ var (X) var (Y)]1/2.
Для векторов X = (X1, X2, …, XM) и Y = (Y1, Y2, …, YM) часто используют выборочный коэффициент корреляции, определяющий косинусу угла между ними (см. рис. 2.5.1)
rXY = cosj = (å Mm= 1 Xm Ym) / (å Mm= 1 X 2m)1/2 (å Mm= 1 Y 2m)1/2.
(2.5.8)
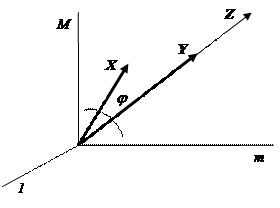 |
Рис. 2.5.1
Данный коэффициент совпадает с выборочным коэффициентом корреляции (2.5.7) для M выборок случайных величин X и Y, у которых á X ñ = á Y ñ = 0.
Коэффициент корреляции (2.5.8) в некоторой степени описывает меру связи между случайными величинами X и Y. Величина связи изменяется в пределах -1 £ rXY £ 1.
Однако мера связи (2.5.8) не вполне корректно выявляет «силу» связи. Так, например, из рис. 2.5.1 видно, что случайные величины X и Y, а также X и Z имеют одинаковые коэффициенты корреляции rXY = rXZ, хотя вектора X и Y «ближе» друг к другу, чем вектора X и Z.
Более правильно «силу» связи описывает модифицированный коэффициент корреляции
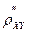 = 2cov (X, Y)/ [ var (X) + var (Y)] = (2.5.8)
= 2cov (X, Y)/ [ var (X) + var (Y)] = (2.5.8)
= (2 å Mm=1 Xm Ym) / [(å Mm= 1 X 2 m) + (å Mm= 1 Y 2 m)].
Из (2.5.8) видно, что ® 0 при удалении Y от X в направлении Z, что говорит об ослаблении связи случайных величины X и Y. Это не описывается коэффициентом rXY.
Расчет статистик высшего порядка.
Коэффициент асимметрии.
Коэффициент асимметрии (или скоса) Пирсона применяется для проверки репрезентативности однородной выборки. Репрезентативность означает насколько состоятельно выборка представляет генеральную совокупность.
Пусть, например, генеральная совокупность некоторой случайной величины X опиcывается нормальным законом. Произведено M выборок { X 1, X 2, …, Xm, …, XM } данной величины. Тогда коэффициент асимметрии определяется, как
SkX = 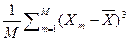 /
/ 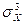 . (2.5.9)
. (2.5.9)
Если выборки однородны и репрезентативны, то коэффициент асимметри SkX близок к 0. В случае положительного / отрицательного значения коэффициента (положительного / отрицательного скоса), выборки представляют часть генеральной совокупности, расположенную справа / слева от ее среднего значения.
Некоторые статисты (В.В. Швырков) предлагают использовать для определения коэффициента асимметрии статистику более высокого порядка
SkX = 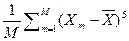 /
/ 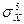 , (2.5.10)
, (2.5.10)
которая более правильно описывает «скошенные» данные.
Коэффициент эксцесса.
Данный коэффициент определяется выражением
eX = [ 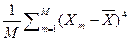 /
/ 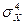 ] – 3.
] – 3.
Если значение эксцесса eX больше 0, выборочное распределение более остроконечно, чем нормальное. В случае отрицательного эксцесса, выборочное распределение более полого, чем нормальное. Равенство эксцесса 0 означает, что выборочные значения однородно и репрезентативно представляют нормальную генеральную совокупность данных.
2.6. Описание неопределенности с помощью нечетких
функций принадлежности.
Теоретический подход.
Многие неопределенности могут и не подчиняться нормальному или иным известным законам распределений. Типична ситуация, когда наблюдения «разбросаны» в некоторой ограниченной области W, а закон их распределения неизвестен. Такие наблюдения могут быть описаны нечеткой функцией m (S) принадлежности, нормированной на 1, т.е.
Дата публикования: 2014-11-18; Прочитано: 207 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
