 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Пример 8.3. Функция переключения контекста в ядре Linux/x86 3 страница
|
|
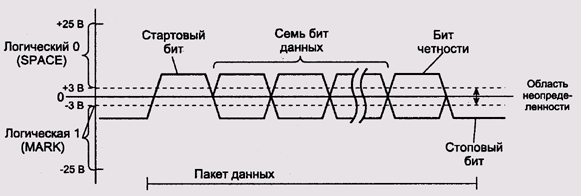
Рис. 9.9. Диаграмма напряжений RS232
Обмен данными осуществляется кадрами, состоящими из стартового бита, семи или восьми битов данных (младший бит передается первым), возможно — контрольного бита четности (см. разд. Контрольные суммы), и одного или двух стоповых битов. Игнорируя ошибки четности или вообще не проверяя четность, можно использовать этот бит для передачи данных, и получить, таким образом, девять битов данных в одном кадре.
Минимальная скорость передачи составляет 300 бит/с, последующие допустимые скорости получаются удвоением предыдущей— 600 бит/с, 1200, 2400 и т.д. Современные реализации RS232 поддерживают скорости 115 200 бит/с и более. Скорость и вариации формата кадра определяются настройками приемника и передатчика. Необходимо, чтобы у соединенных портом устройств эти настройки совпадали, однако протокол сам по себе не предоставляет средств для их согласования.
Кроме линий приема, передачи, нуля и питания спецификация RS232 предусматривает ряд дополнительных сигналов, в просторечии называемых модемными линиями— признак несущей, разрешение передачи данных (очисткой этого сигнала приемник может сигнализировать передатчику, что он не успевает обрабатывать поступающие данные) и др. Эти сигналы не должны обязательно поддерживаться всеми устройствами и используются, главным образом, акустическими модемами, откуда и происходит название. Полная спецификация при использовании 25-контактного разъема предусматривает также возможность синхронной передачи данных с отдельными стробирующими сигналами, но основная масса реализаций RS232 этого не поддерживает.
Протокол RS232 весьма прост и легко может быть реализован программными средствами с использованием двух бит порта ввода-вывода (пример 9.1) — впрочем, в этом случае потребуется еще внешняя микросхема приемопередатчика, преобразующая TTL-совместимые напряжения в диапазон напряжений RS232. Однако использующие этот протокол, применяются очень широко, и многие модели микроконтроллеров и практически все комплекты вспомогательных микросхем для микропроцессоров предлагают аппаратные реализации этого стандарта.
Пример 9.1. Программная имитация Р5232-совместимого последовательного порта, цит. по [www.atmel.com AVR305]
;**** APPLICATIONNOTEAVR305 ************************. *
;* Название: Полудуплексный программный UART
;* Версия: 1.20
;* Последнее обновление: 97.08.27
;* Целевое устройство: Все микроконтроллеры AVR. *
;* Адрес поддержки: [email protected]. *
;* Размер кода: 32 слова
;* Мин. Регистров: О
;* Макс. Регистров: 4.
;* Прерывания: Не используются
;* Описание
;* Этот пример содержит эффективный с точки зрения объема кода программный UART.
;* Программа-пример получает один символ и передает его назад.
.include "1200def.inc".***** определения контактов
.equ RxD =0 /Контакт приема PDO.equ TxD =1;Контакт передачи PD1
.*****
Глобальные регистровые переменные
.def bitcnt =R16;счетчик битов
.def temp =R17 промежуточный регистр
.def Txbyte =R18;Передаваемые данные
def Rxbyte =.<19 /Полученные данные.cseg
.org
0
* "putchar" *
* Эта подпрограмма передает байт из регистра "Txbyte"
* Количество стоповых битов определяется константой sb *
* Количество слов:14 включая возврат
* Количество циклов:Зависит от частоты передачи
* Мин. Регистров:Нет
* Макс. Регистров:2 (bitcnt,Txbyte)
* Указатели:Не используются
.equ sb =1;Кол-во стоповых битов (1, 2,...)
putchar: Idi bitcnt,9+sb;1+8+sb com Txbyte;Инвертировать все sec;Стартовый бит
putcharO: brcc putchar1;Если перенос установлен cbi PORTD,TxD; передать 'О' rjmp putchar2;иначе
putcharl: sbi PORTD,TxD; передать '!' пор
Putchar2: rcall UART_delay /Задержка в один бит real! UART_delay
Isr Txbyte /Получить следующий бит dec bitcnt /Если не все биты переданы brne putcharO; послать следующий;иначе
.Leu; возврат
* "getchar"
?
* Эта подпрограмма получает один байт и возвращает его в "Rxbyte" *
* Кол-во слов:14 включая возврат
* Кол-во циклов:Зависит от скорости приема
* Мин. Регистров:Нет
* Макс. Регистров:2 (bitcnt,Rxbyte)
* Указатели:Не используются
getchar: Idi bitcnt,9;8 бит данных + 1 столовый
*
getcharl: sbic PIND,RxD;Ждать стартового бита rjmp getcharl
rcall UART_delay;задержка в 0.5 бита
getchar2: rcall UART_delay /задержка в один бит rcall UART__delay
clc /очистить перенос
sbic PIND,RxD;если вход RX = 1
sec
dec bitcnt;Если бит столовый breq getcharS; возврат
/иначе
ror Rxbyte; сдвинуть бит в Rxbyte rjmp getchar2; получить следующий
getcharS: ret
I "UART_delay"
*
I Эта подпрограмма задержки генерирует требуемую задержку между битами
* при передаче и приеме байтов. Полное время исполнения определяется I константой "Ь":
*3*Ь + 7 cycles (включая rcall и ret)
*
f Кол-во слов:4 включая возврат
* Мин. Регистров:Нет
* Макс. Регистров:1 (temp)
* Указатели:Не используются
Допустимые значения Ь:
1 MHz crystal: 9600 bps - b=14 19200 bps - b=5 28800 bps - b=2
2 MHz crystal: 19200 bps - b=14 28800 bps - b=8 57600 bps - b=2
4 MHz crystal: 19200 bps - b=31 28800 bps - b=19 57600 bps - b=8 115200 bps - b=2
•equ ь =31;19200 bps @ 4 MHz crystal
UART_delay: Idi temp,b uART_delayl: dec temp Brne UART delayl
ret
;***** Исполнение программы начинается здесь;***** Тестовая программа
reset: sbi PORTD,TxD;Установить контакты порта sbi DDRD,TxD
Idi Txbyte,12 /Очистить терминал rcall putchar
forever: rcall getchar mov Txbyte,Rxbyte
rcall putchar;Воспроизвести полученный символ
rjmp forever
USART микроконтроллера PIC
В качестве примера аппаратной реализации последовательного порта, которую, помимо других вариантов использования, мЪжно применить и для реализации RS232, давайте рассмотрим устройство USART (Universal Synchronous Asynchronous Receiver Transmitter), включенное в состав ряда моделей микроконтроллеров PIC фирмы Microchip [www.microchip.com PICMicro].
USART может использоваться либо как полнодуплексный асинхронный порт с форматом кадра, совместимым с RS232, либо как полудуплексный синхронный стробируемый порт. Устройство состоит из приемника (receiver), передатчика (transmitter) и генератора тактовой частоты (baud rate generator) (рис. 9.10).
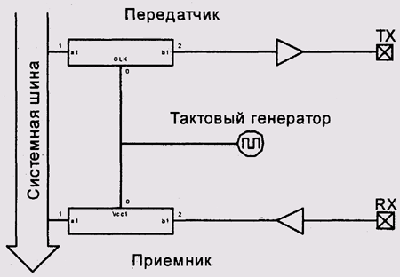
Рис. 9.10. Структура USART микроконтроллера PIC
Генератор тактовой частоты представляет собой двоичный счетчик, уменьшаемый на единицу на каждом такте центрального процессора. Когда счетчик доходит до нуля, генерируется один такт и счетчик инициализируется исходным значением. Фактически, генератор представляет собой делитель тактовой частоты процессора в заданном отношении. Документ [www.microchip.com PICMicro] содержит таблицу, по которой можно рассчитать коэффициент деления, чтобы из типичных тактовых частот процессора получить (иногда с определенной ошибкой) стандартные частоты RS232.
Счетчик генератора тактовой частоты программно недоступен, а начальное значение этого счетчика (оно же коэффициент деления) задается 8-разрядным регистром SPBRG. USART использует одну и ту же тактовую частоту и для приемника, и для передатчика. При синхронной работе в режиме ведомого встроенный генератор тактовой частоты не используется вообще.
Приемник и передатчик во многом аналогичны по структуре и имеют по два программно-доступных 8-разрядных регистра. Первый регистр называется регистром управления и статуса (status and control register), а второй — регистром данных. Значения битов управляющих регистров приемника и передатчика приведены в табл. 9.1 и 9.2. И приемник, и передатчик имеют также программно-недоступный сдвиговый регистр, называемый TSR (Transmit Shift Register) у передатчика и RSR (Receive Shift Register) у приемника.
При передаче значение регистра данных передатчика помещается в сдвиговый регистр и возможно расширяется девятым битом, который берется из бита TX9D управляющего регистра. Значение младшего бита выставляется на выходе ТХ микроконтроллера. Затем на каждом такте генератора регистр сдвигается на один бит — в результате получается последовательная передача бит кадра с заданной скоростью (рис. 9.11). Когда биты кончаются, передатчик устанавливает бит TRMT управляющего регистра и, если это требуется, генерирует прерывание по завершении передачи.
Приемник имеет несколько более сложное устройство. Значение входа RX анализируется не один раз за каждый такт генератора, а 16 раз и усредняется — благодаря этому значительно увеличивается помехоустойчивость (рис. 9.12). Кроме того, приемник USART имеет скрытый буферный регистр, в который помещается значение принятого байта, если регистр данных приемника еще не был прочитан с момента последнего приема (рис. 9.13).
Таблица 9.1. Описание битов управляющего регистра передатчика USART
| Бит | Описание |
| CSRC: Clock SouRCe — выбор источника тактовой частоты при асинхронном режиме игнорируется, при синхронном режиме: 1 = режим ведущего (USART генерирует стробовый сигнал) 0 = режим ведомого (стробовый сигнал генерирует другое устройство) | |
| ТХ9: передавать 9 бит 1 = передавать 9 бит 0 = передавать 8 бит | |
| TXEN: Transmission ENabled — разрешить передачу 1 = передача разрешена 0 = передача запрещена | |
| SYNC: бит выбора режима USART 1 = синхронный режим 0 = асинхронный режим | |
| Не используется. Читается как О | |
| BRGH: Baud Rate Generator High — переключение режимов работы тактового генератора | |
| TRMT: бит состояния сдвигового регистра передатчика 1 = TSR пуст 0 = TSR содержит данные (идет передача) | |
| TX9D: девятый бит передаваемых данных (может использоваться как бит четности) |
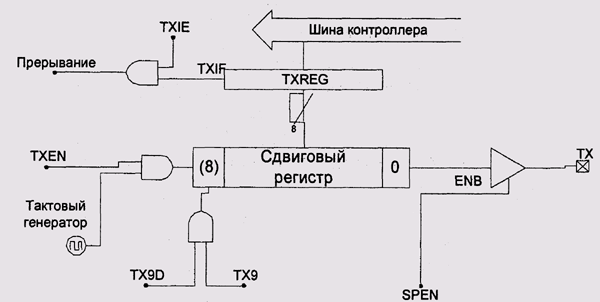
Рис. 9.11. Принципиальная схема передатчика USART

Рис. 9.12. Временная диаграмма работы приемника USART
Таблица 9.2. Описание битов управляющего регистра приемника USART
| Бит | Описание |
| SPEN: Serial Port Enable — включить последовательный порт 1 = последовательный порт включен 0 = последовательный порт выключен | |
| RX9: разрешение приема 9 бит 1 = выбран прием 9 бит 0 = выбран прием 8 бит | |
| SREN: Single Receive ENable — бит одиночного приема Асинхронный режим — не используется. Синхронный режим (ведущий): 1 = одиночный прием разрешен; 0 = одиночный прием запрещен. Этот бит очищается после завершения приема. Синхронный режим (ведомый) — не используется | |
| CREN: Continuous Receive ENable — бит непрерывного приема. Асинхронный режим: 1 = прием разрешен; 0 = прием запрещен. Синхронный режим: 1 = непрерывный прием разрешен; 0 = непрерывный прием запрещен | |
| Не используется. Читается как 0 | |
| FERR: Framing ERRor — ошибка кадра 1 = ошибка кадра 0 = нет ошибки кадра | |
| OERR: Overrun ERRor — ошибка переполнения буфера 1 = переполнение буфера приема 0 = нет ошибки переполнения | |
| RX9D: девятый бит принятых данных. Может использоваться как бит четности |
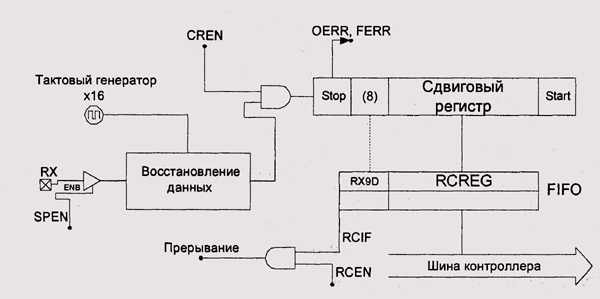
Рис. 9.13. Принципиальная схема приемника USART
Приемники большинства современных аппаратных реализаций RS232 имеют буферные регистры. Так, последовательные порты подавляющего большинства современных IBM PC-совместимых компьютеров основаны на микросхеме National Semiconductor PC16552 [NS PC16552D] и имеют буферы объемом 16 байт (у оригинальной IBM PC были небуферизованные порты).
Помимо освобождения центрального процессора от исполнения работы сдвиговых регистров, аппаратная реализация RS232 позволяет заменить ожидание данных в режиме опроса на работу по прерываниям, что во многих случаях тоже весьма полезно. Многопортовые адаптеры, используемые, например, для организации модемных пулов интернет-провайдеров, часто могут передавать данные в режиме ПДП.
Шины
Описанные в предыдущем разделе порты передачи данных соединяют друг с другом два устройства. Однако часто оказывается целесообразно подключить к одному порту передачи данных несколько устройств, причем необязательно однотипных. Каждая передаваемая по такому порту порция данных обязана сопровождаться указанием, какому из подключенных устройств она предназначена — адресом или селектором устройства. Такие многоточечные порты называются шинами (bus) (рис. 9.14). Как и двухточечные порты передачи данных, шины бывают синхронные и асинхронные, а также последовательные и параллельные. При описании шин термины "синхронный" и "асинхронный" используют в ином значении, чем при описании портов. Асинхронными называют шины, в которых ведомое устройство не выставляет (или не обязано выставлять) сигнал завершения операции, а синхронными, соответственно, шины, где ведомый обязан это делать.

Рис. 9.14. Шина
Подключение N устройств двухточечными портами требует, чтобы центральный процессор имел N приемопередатчиков, использование же многоточечного порта позволяет обойтись одним. В частности, за счет этого Удается уменьшить количество выводов микросхемы процессора или периферийного контроллера. Кроме того, при удачном размещении устройств Можно получить значительный выигрыш в общей длине проводов и, таким образом, например, уменьшить количество проводников на печатной плате. Во многих случаях это приводит к столь значительному снижению общей стоимости системы, что оказывается целесообразным смириться с усложнением протокола передачи данных и другими недостатками, присущими шинной архитектуре.
Основной недостаток шин состоит в том, что в каждый момент времени только одно устройство на шине может передавать данные. Если у двухточечных портов часто оказывается целесообразным реализовать полподуплексный обмен данными при помощи двух комплектов линий (один прием, другой на передачу, как в описанном выше RS232), то в случае шинной топологии это невозможно. Поэтому шины бывают только полудуплексные или симплексные.
Невозможность параллельно осуществлять обмен с двумя устройствами может привести к падению производительности по сравнению с собственным портом обмена данными у каждого устройства. Если устройства не занимают пропускную способность каналов передачи полностью, проигрыш оказывается не так уж велик. Благодаря этому шины широко используются даже в ситуациях, когда только одно устройство имеет возможность инициировать обмены данными.
Если передачу данных могут инициировать несколько устройств (как, например, в случае системной шины с несколькими процессорами и/или контроллерами ПДП), шинная топология оказывается наиболее естественным выбором. Такая конфигурация требует решения еще одной проблемы: обеспечения арбитража доступа к шине со стороны возможных инициаторов обмена — задатчиков шины (рис. 9.15). Методы арбитража отличаются большим разнообразием.

Рис. 9.15. Шина с несколькими задатчиками
Разрешение коллизий в I2С
Синхронная последовательная шина I2С (Inter-Integrated Circuit — [протокол соединения] между интегральными схемами) широко применяется для соединения цифровых микросхем во встраиваемых приложениях [Paret-Fenger 1997]. Шина состоит из двух линий, строба и данных (рис. 9.16). Предполагается, что все подключенные к шине устройства имеют общие шины питания и нуля. Хотя бы одно из устройств шины должно быть ведущим (master).
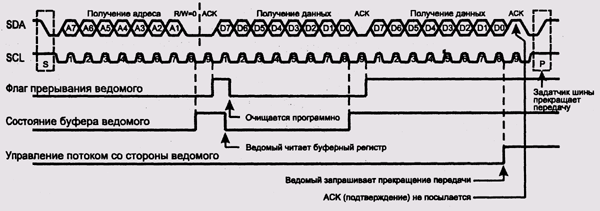
Рис. 9.16. Временная диаграмма шины I2С
Ведущее устройство генерирует стробовый сигнал и инициирует все передачи данных по шине. Частота строба может составлять 100 или 400 кГц или 1 МГц. Все передачи начинаются с того, что ведущий передает адрес целевого устройства. В зависимости от конфигурации адрес может состоять из семи или десяти бит. Восьмой или, соответственно, одиннадцатый бит адреса содержит указание на тип запроса: чтение или запись. Услышав свой адрес, ведомое устройство генерирует на линии стробового сигнала импульс подтверждения.
Импульса подтверждения может не последовать не только при отсутствии устройства с таким адресом, но и, например, если соответствующее устройство не готово принять или передать данные.
Если подтверждение все-таки последовало, начинается передача данных. Данные состоят из восьми бит. Если запрос был на чтение, данные передает ведомое устройство, если на запись — ведущее.
Спецификации I2С допускают конфигурацию с несколькими ведущими. Чтобы избежать конфликтов, ведущее устройство генерирует стробовый сигнал только во время инициируемых им передач данных, в остальное же время тихо слушает линию и может, при запросе другого ведущего, стать ведомым.
Из-за того, что сигнал распространяется по шине с конечной скоростью, да и внутренняя логика ведущих устройств срабатывает не мгновенно, возможна ситуация, когда два ведущих с небольшим интервалом попытаются захватить шину. Эта ситуация называется коллизией (collision — дословно, столкновение). Протоколы арбитража большинства других шин считают коллизией любую попытку двух устройств одновременно вести передачу. I2С предлагает более слабое определение коллизии — в соответствии со спецификациями этой шины, коллизия происходит, только когда ведущие пытаются выставить на шине данных разные значения. Таким образом, если два (или даже больше!) ведущих отправят один и тот же запрос одному и тому же ведомому, это не будет считаться коллизией!
Механизм арбитража, используемый I2С, отличается крайней простотой.Ведущий, пытающийся выставить на линии данных 1 в то время, как другой ведущий пытается выставить там же 0, считается проигравшим арбитраж. Он должен остановить передачу и дождаться, пока победитель завершит обмен и освободит шину.
Важно подчеркнуть, что протокол арбитража не может просто объявить обоим устройствам, что дескать, случилась коллизия — если оба устройства прeкратят передачу и, не предприняв более ничего, сделают вторую попытку, мы получим живую блокировку! Странное, на первый взгляд, определение коллизии принятое в I2С, дает победителю арбитража возможность продолжить передачу после обнаружения коллизии, исключая, таким образом, для него возможность повторной коллизии после повторной попытки передачи, и, соответственно, исключая опасность живой блокировки.
Видно, что спецификации I2С допускают ситуацию, когда два устройства пытаются установить на шине разные напряжения. Чтобы избежать при этом больших токов, стандарт устанавливает несколько необычный способ подключения устройств к шине (рис, 9.17). Устройство, пытающееся выставить 1, должно просто отключить свои выходные каскады — тогда через резистор Rp (для питания 5 В его сопротивление должно быть не менее 1,7 кОм) конденсатор Сb будет заряжен до напряжения питания. Только при попытке выставить ноль устройство должно пропускать через себя ток.

Рис. 9.17. Схема приемопередатчиков I2С
Необходимость обнаружения коллизий и арбитража накладывает ограничения на физический размер шины: сигналы распространяются по шине с конечной скоростью, а любые два конфликтующих устройства должны узнать коллизии за время, меньшее чем минимальный цикл передачи данных (цикл шины). Описанная выше шина 12С предназначена для низкоскоростной связи в пределах одной печатной платы, поэтому для нее эта проблема не актуальна, однако для локальных сетей, протяженность которых составляет сотни метров или даже километры, и для системных шин компьютеров с большим количеством процессоров и банков памяти это превращается в серьезную проблему. Кроме того, большое количество коллизий само по себе снижает производительность системы.
Один из основных путей решения этой проблемы упоминался в разд. Многопроцессорные архитектуры: замена шины центральным коммутатором, либо более или менее сложной сетью коммутаторов. Устройства соединяются с ближайшим коммутатором полнодуплексными двухточечными каналами, такие же каналы используются для соединения коммутаторов друг с другом, а все коллизии возникают и разрешаются только внутри коммутаторов.
Внутренняя шина коммутатора, как правило, имеет большую пропускную способность, чем внешние соединения — у многих практически используемых коммутаторов несколько внутренних шин, поэтому разрешение коллизии внутри коммутатора часто состоит в отправке данных другим путем (рис. 9.18).
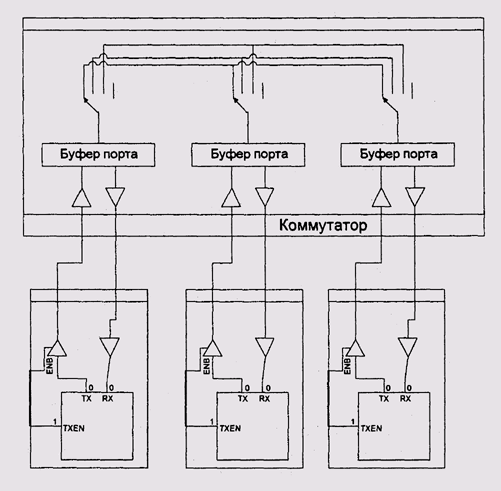
Рис. 9.18. Коммутатор с несколькими внутренними шинами
Таким образом, коммутируемая магистраль позволяет уменьшить производительности, порождаемые коллизиями, и повысить реальную пропускную способность магистрали. Однако коммутируемая магистраль значительно повышает общую стоимость системы и далеко не всегда оправдана этой точки зрения.
Применяются также гибридные топологии, когда все или некоторые устройства подключаются к коммутатору полудуплексным портом или коротки участком шины — при этом возможны локальные коллизии, но их гораздо меньше, чем при единой шине. Гибридная топология позволяет использовать устройства с одними и теми же приемопередатчиками как в обычной шинной, так и в коммутируемой топологии (рис. 9.19). В частности, именно такую гибридную топологию имеют описанные в разд. Многопроцессорные архитектуры многопроцессорные системы IBM NUMA-Q и SGI Origin — процессоры и память подключаются к локальной шине процессорного модуля, а сами модули соединяются коммутируемой сетью.
Гибридная топология также позволяет снизить стоимость системы по сравнению с полностью коммутируемой сетью — коммутаторы можно устанавливать только в тех участках шины, где расстояния или большое количество коллизий становятся проблемой. В таких сетях часто используются двухпортовые коммутаторы, называемые мостами (bridge). Так же называются и адаптеры, используемые для соединения двух шин с разными протоколами.

Рис. 9.19. Гибридная топология
Во всех перечисленных случаях сохраняется логическая шинная топология: каждый потенциальный задатчик шины может обращаться по адресу к любому другому устройству, поэтому разработчикам программного обеспечения не всегда интересны детали реализации физического подключения устройств.
Шины (как физические, так и логические) находят широчайшее применение в вычислительной технике. В частности, один из важнейших сетевых протоколов канального уровня, Ethernet, начинал свою карьеру как последовательная шина с совмещением синхросигнала и данных, да и современные реализации этого протокола, хотя физически и представляют собой коммутируемую или, все реже и реже гибридную сеть, с логической точки зрения по-прежнему являются шиной.
Связь центральных процессоров с банками ОЗУ и внешними устройствами в подавляющем большинстве современных компьютеров осуществляется параллельными стробируемыми шинами.
В вычислительных системах общего назначения чаще всего используется топология с двумя или более шинами. Процессоры и память связаны системной шиной. К этой шине также присоединены один или несколько адаптеров периферийных шин, к которым и подключаются внешние устройства (рис. 9.20). Основное преимущество такого решения состоит в том, что одни и те же периферийные устройства могут использоваться в вычислительных системах с различными системными шинами. Высокоскоростные устройства, например дисковые адаптеры FC-AL у серверов или графические контроллеры у персональных компьютеров, иногда подсоединяются к системной шине непосредственно.
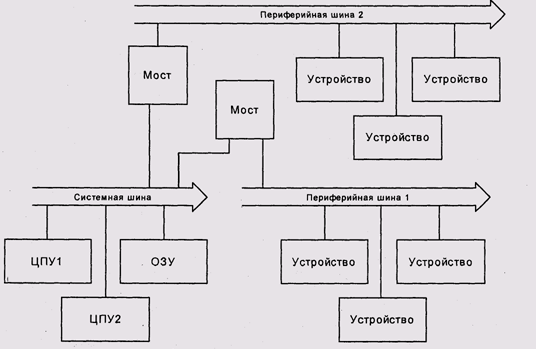
Рис. 9.20. Системная и периферийные шины
Шина PCI
Шина PC/ (Peripherial Component Interconnect), разработанная фирмой Intel в настоящее время используется в вычислительных системах разного уровня, начиная от персональных компьютеров с архитектурами х86 и PowerMac и заканчивая старшими моделями серверов Sun Fire. В конструктиве PCI исполняется множество различных периферийных устройств— сетевые карты, адаптеры SCS/, графические и звуковые карты, платы видеоввода и видеовывода и лр [PC Guide PCI].
PCI не рассчитана на использование в качестве системной шины. Напротив спецификации шины предполагают ее подключение к процессорам и памяти через специальное устройство, мост системной шины (host-to-PCI bridge) (рис. 9.21). Это позволяет использовать PCI в системах, основанных на различных процессорах, таких, как х86, Power, SPARC.
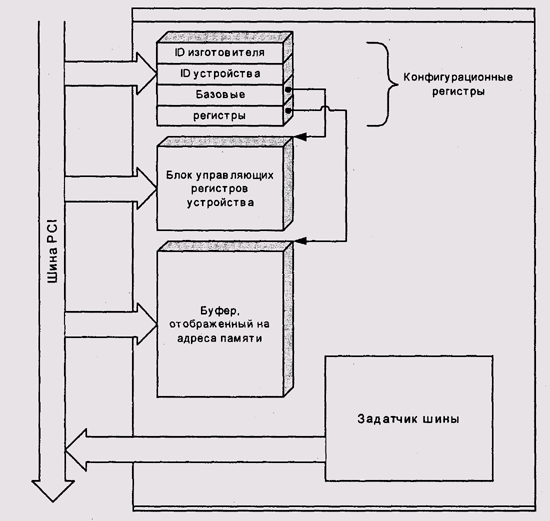
Рис. 9.21. Мост системной шины
PCI предусматривает как монтаж устройств на материнскую плату системы, так и их исполнение в виде плат расширения. Шина допускает подключение не более 4 устройств. По исходным спецификациям, не более трех из них может подключаться через внешние разъемы, однако это не мешает многим поставщикам оборудования изготавливать платы с четырьмя внешними разъемами без мостов. Предусмотренный стандартом способ обхода указанного ограничения состоит в установке в системе нескольких адаптеров PCI, через собственные мосты системной шины или через PCI-to-PCI bridge. Допустимы также мосты, подключающие другие периферийные шины, например ISA, USB и т. д (рис. 9.22).
Каждое устройство на шине обязано иметь набор конфигурационных регистров, адресуемых географически (по номерам шины и разъема). Эти регистры содержат информацию об изготовителе и модели устройства. Кроме того, устройство может иметь до шести базовых адресных регистров, указывающих на связанные с устройством адресуемые объекты — блоки регистров ввода-вывода и отображенные на адреса ОЗУ буферы (рис. 9.23). Адреса этих объектов определяются динамически во время инициализации системы загрузочным монитором. Как правило, эти адреса также распределяются по географическому принципу.
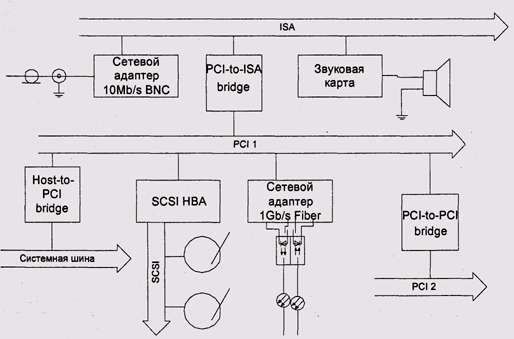
Рис. 9.22. Мосты PCI-to-PCI и PCI-to-ISA
Устройство может работать в пассивном режиме (передавая данные по запросам процессоров) или через ПДП в режиме задатчика шины. Во втором случае мост системной шины преобразует выставляемые устройством адреса PCI в адреса системной шины. Современные спецификации шины (т. н. PCI64) допускают 32-разрядную адресацию для регистров устройств и 32- или 64-битную адресацию для отображенных в память буферов и при работе по ПДП.
Шина SCSI
Среди других практически важных применений шин необходимо упомянуть стандарт SCS/ (Small Computer System Interface — системный интерфейс малых компьютеров), наиболее известный как интерфейс для подключения жестких дисков, но используемый для подключения широкого спектра высокоскоростных устройств (табл. 9.3), в том числе и не являющихся устройствами памяти, например, сканеров [Гук 2000].
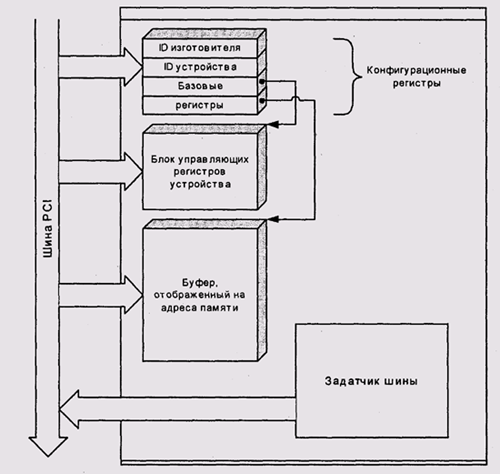
Рис. 9.23. Конфигурационные и рабочие регистры устройства PCI
Современные спецификации SCSI по структуре аналогичны спецификациям сетевых протоколов и состоят из трех уровней: команд, протокола и соединений. Уровень команд определяет формат и семантику команд и ответов на них, т. е. приблизительно соответствует тому, что в сетевых протоколах называется прикладным уровнем. Уровень протокола определяет способ передачи команд и ответов и соответствует канальному уровню сетевых протоколов. И, наконец, уровень соединений определяет физическую реализацию линий передачи данных (способ кодирования данных, допустимые токи и напряжения, конструкцию разъемов и т. д.), т. е. соответствует физическому уровню [ www.t10.org architecture, Friedhelm/Shmidt 1997]. Сетевой (в данном случае описывающий способ адресации устройств) и транспортный уровни в спецификациях SCSI также присутствуют, хотя и в рудиментарном виде.
Таблица 9.3. Типы устройств SCSI, возвращаемые командой INQUIRY, цит. по [www.t10.org commands]
| Код | Описание |
| 00h | Устройство прямого доступа (например, магнитный диск) |
| 01h | Устройство последовательного доступа (например, магнитная лента) |
| 02h | Печатающее устройство |
| 03h | Процессорное устройство |
| 04h | Устройство однократной записи (например, некоторые оптические диски) |
| 05h | CD-ROM |
| 06h | Сканер |
| 07h | Оптическое запоминающее устройство (например, некоторые оптические диски) |
| 08h | Устройство с автоматической заменой носителя (например, jukebox) |
| 09h | Коммуникационное устройство |
| 0Ah-0Bh | Определено ASC IT8 |
| 0Ch | Контроллер массива запоминающих устройств (например, RAID) |
| 0Dh | Устройство enclosure services (мост к шине другого типа) |
| 0Eh-1Eh | Зарезервировано |
| 1Fh | Неизвестный или неопределенный тип устройства |
На физическом уровне SCSI представляет собой параллельную шину с 8-ю или 16-ю (так называемая Wide SCSI) линиями передачи данных. Современные реализации стандарта обеспечивают скорости передачи данных до 160 Мбит/с. Стандартом SCSI III предусмотрены также реализации в виде последовательной шины IEEE 1394 или волоконно-оптических колец FC-AL (Fiber Channel Arbitrated Loop — волоконно-оптический канал [в виде] арбитрируемого кольца). Fiber Channel допускает объединение нескольких колец коммутаторами, подключение до 127 устройств, общую длину сети, измеряемую несколькими сотнями метров и скорости передачи до 1Гбит/с.
Обмен данными по шине происходит не байтами и даже не словами, а кадрами, которые могут содержать команды, информацию о состоянии устройства (sense data) или собственно данные. Формат кадров и способ разрешения коллизий зависит от используемого типа соединений — в этом смысле разделение уровня соединений и уровня протокола не реализовано в полной мере. Каждый кадр содержит адреса отправителя и получателя. Каждое устройство имеет собственный адрес, называемый SCSI target ID. У старых версий протокола этот адрес был 3-битным, допуская адресацию восьми устройств, у современной версии (Ultra-SCSI или SCSI III) адрес 4- или 5-битный. Адаптер, через который шина SCSI подключается к системной или периферийной шине компьютера — НВА (Host Bus Adapter— адаптер системной шины) — также считается устройством и обычно имеет ID, равный, в зависимости от разрядности адреса, 7, 15 или 127.
Устройство, имеющее один target ID, может содержать несколько логически устройств, идентифицируемых номерами логических устройств (LUN — Logjc Unit Number). Спецификации протокола предусматривают два байта для код рования LUN, но реальное число логических устройств, поддерживаемых практике, обычно невелико.
Устройства SCSI делятся на два типа: инициаторы (initiator) и целевые ройства (target). Инициатор посылает команды, а целевое устройство их полняет. Спецификация допускает, что в разных актах обмена данными инициатор может становиться целевым устройством и наоборот, но в пределах одной операции эти роли заданы однозначно. Как правило, НВА может выступать только в роли инициатора, а периферийные устройства — только в роли целевых.
Блоки команд — CDB (Command Descriptor Block — блок описания команды) — невелики по размеру и могут содержать 6, 8, 10, 12 или 16 байт. Различие в длине обусловлено размером используемых в команде адресов: 6-байтовая команда использует 21-битный адрес блока на устройстве и 8-битное поле для длины требуемого блока данных, 8-байтовая — 32-разрядный адрес и 16-битное поле длины, а более длинные команды— 32-разрядные адрес и длину. 16-байтовая форма команды содержит, кроме 32-разрядных адреса и длины, также и 32-битное поле параметра. Кроме того, команда обязательно содержит код операции и поле управления. Под код операции отводится байт. Старшие три бита этого байта кодируют формат SCB. Некоторые команды используют только один формат SCB, другие допускают применение различных форматов (обычно с адресами и полем длины различной разрядности). Кроме перечисленных в табл. 9.4, различные типы устройств имеют собственные команды.
Блоки данных, в отличие от команд, имеют практически неограниченную длину. Многие команды интерпретируют поле длины CDB как указанное в блоках. При размере блока 512 байт это позволяет передать за одну операцию до 2 Тбайт (1 Тбайт=1024 Гбайт) данных. На практике, пакет данных, передаваемых за одну операцию шины, ограничен размерами буферов устройств, поэтому запросы на передачу больших объемов данных обрабатываются в несколькр приемов. Команда может либо принимать, либо передавать данные. В качестве данных могут передаваться либо блоки параметров и ответов, либо собственно данные. Существование команд, способных и передавать, и принимать данные, явно запрещено спецификациями, поэтому в CDB предусмотрена только одна группа полей описания буфера. Впрочем, операция может исполняться в виде последовательности команд и поэтому может предусматривать двусторонний обмен данными.
Большинство команд требует от устройства более или менее длительных подготовительных операций (перемещения головки, перемотки ленты), поэтому передача данных не может следовать немедленно за командой. По этой причине большинство современных устройств поддерживает очереди команд. Чтобы связать команду с пришедшим на нее ответом, команды могут снабжаться тегом задачи. Устройство способно параллельно исполнять несколько задач, а в рамках одной задачи может быть исполнена последовательность команд.
Дата публикования: 2014-11-18; Прочитано: 667 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
