 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Операции над процессами и связанные с ними понятия
|
|
Процесс не может самостоятельно перейти из одного состояния в другое. Этот переход возможен только в результате операций над процессом, которые осуществляет ОС.
Количество таких операций совпадает с количеством стрелок, представленных на модели состояний процесса.
Операции удобно объединить в три пары:
· рождение – завершение процесса
· приостановка процесса (перевод из состояния исполнение в состояние готовность) – запуск процесса (перевод из состояния готовность в состояние исполнение)
· блокирование (перевод из состояния исполнение в состояние ожидание) – разблокирование (перевод из состояния ожидание в состояние готовность)
Далее будет рассмотрена еще одна операция, не имеющая парной: изменение приоритета процесса.
Операции создание и завершение процесса являются одноразовыми (т.к. применяются не более одного раза).
Все остальные операции, связанные с изменением состояния процессов, являются многоразовыми.
Одноразовые операции
ОС создает процессы динамически. Инициатором может быть как процесс пользователя (за счет системного вызова), так и процесс, который необходим самой ОС.
Кроме того, инициатором нового процесса может выступать и существующий процесс. В подобном случае говорят о процессе-родителе и процессе-ребенке.
Каждый из процессов-детей может в свою очередь порождать новые процессы. Формируется при этом генеалогический лес процессов.
Цифры здесь являются идентификационным номером процесса. Поскольку процессы рождаются и умирают, то нумерация не является последовательной. Отметим, что в существующем дереве процессов отдельные ветки являются процессами пользователя, а другие процессами самой ОС.
При рождении процесса система заводит новый PCB с состоянием процесса. Рождение и начинает его заполнять. Новый процесс получает собственный уникальный идентификационный номер.
Для хранения номеров отводится ограниченное количество разрядов. Это значит, что количество одновременно присутствующих в системе процессов должно быть ограничено. После завершения какого-либо процесса его освободившийся идентификационный номер может быть повторно использован для идентификации другого процесса.
При возникновении процесса-ребенка ему требуются определенные ресурсы. Есть два подхода к их выделению:
1. Процесс-ребенок может получить в свое распоряжение некоторую часть родительских ресурсов. В этом случае он будет разделять эти ресурсы с процессом-родителем и с процессами-детьми того же родителя. Такое разделение будет осуществляться на основе определенных правил.
2. Процесс-ребенок может получить свои ресурсы непосредственно от ОС. При этом информация о выделенных ресурсах нового процесса заносится в блок PCB.
После получения ресурсов процесс-ребенок в свое распоряжение должен получить программный код, который будет выполняться в его адресном пространстве; значение исходных данных, также внесенное в адресное пространство. Кроме этого, должен быть установлен его программный счетчик. В этом случае также возможны два решения:
· в первом случае процесс-ребенок становится дубликатом процесса-родителя по регистровому и пользовательскому контекстам. В этом случае должен быть механизм, определяющий, кто из процессов двойников является родителем.
· во втором случае процесс-ребенок загружается новой программой из какого-либо файла
Таким образом, с учетом первого способа можно констатировать, что для одной пользовательской программы могут существовать несколько процессов (родительских и детских).
Возможность замены пользовательского контекста процесса по ходу его работы (т.е. загрузки для исполнения новой программы) приводит к тому, что в рамках одного и того же процесса может последовательно выполняться несколько различных программ.
После того, как процесс наделен содержанием, в PCB дописывается оставшаяся информация, и состояние нового процесса меняется на готовность.
Поясним, как себя могут вести процессы-родители после рождения процессов-детей. Процесс-родитель может продолжать свое выполнение, а может ожидать завершения работы некоторых или всех своих детей.
После того как процесс завершил свою работу, ОС переводит его в состояние завершение. При этом все ресурсы, которые ранее были выделены для процесса, освобождаются. И все записи об этих ресурсах в PCB уничтожаются. При этом сам PCB не уничтожается, а остается в системе еще некоторое время. Это необходимо для того, чтобы была возможность запросить у ОС причины, по которым процесс был завершен (например, при отладке программы) и, кроме того, для получения определенной статической информации о работе процессов.
Подобная информация сохраняется в PCB отработавшего процесса до запроса процесса-родителя или до конца его деятельности, после чего все следы завершившегося процесса окончательно исчезают из системы.
Следует заметить, что в ряде ОС гибель процесса-родителя приводит к завершению работы всех его детей. В других (Unix) процессы-дети продолжают свое существование и после окончания работы процессов-родителей.
Для того чтобы структура генеалогического леса процессов оставалась целостной, необходимо обеспечить своевременное изменение информации в PCB блоках процессов-детей.
Как правило, «осиротевшие» процессы «усыновляются» одним из системных процессов, который порождается при старте ОС и функционирует все время, пока она работает.
Многоразовые операции:
Одноразовые операции приводят к изменению количества процессов, находящихся под управлением ОС, и всегда связаны с выделением или освобождением определенных ресурсов.
Многоразовые операции не приводят к изменению количества процессов в ОС и не обязаны быть связанными с выделением или освобождением ресурсов.
Запуск процесса. Из числа процессов, находящихся в состоянии готовность для последующего исполнения должен быть выбран один. ОС делает это на основе определенных критериев и алгоритмов.
Для избранного процесса ОС обеспечивает наличие в оперативной памяти информации, необходимой для его дальнейшего выполнения.
Далее состояние процесса изменяется на исполнение, восстанавливаются значения регистров для данного процесса, и управление передается команде, на которую указывает счетчик команд процесса.
Все данные, необходимые для восстановления контекста, извлекаются из PCB процесса, над которым совершается операция.
Приостановка процесса. Работа процесса, находящегося в состоянии исполнение, должна быть приостановлена в результате какого-либо прерывания. Процессор автоматически сохраняет счетчик команд и, возможно, один или несколько регистров в стеке исполняемого процесса, а затем передает управление специальному адресу обработки данного прерывания.
На этом деятельность железа (hard ware) по обработке прерывания завершается.
По указанному адресу обычно располагается одна из частей ОС. Она сохраняет динамическую часть системного и регистрового контекстов процесса в его PCB, переводит процесс в состояние готовность и приступает к обработке прерывания, т.е. к выполнению определенных действий, связанных с возникшим прерыванием.
Блокирование процесса. Процесс блокируется, когда он не может продолжать работу, не дождавшись возникновения каких-либо событий в ВС. Для этого он обращается к ОС с помощью определенного системного вызова. После того как ОС обрабатывает системный вызов, процесс переводится из состояния исполнение в состояние ожидание.
Разблокирование процесса. После выполнения ожидаемого события процесс переводится в состояние готовность и становится в очередь.
Переключение контекста. Реально деятельность мультипрограммной ОС состоит из цепочек операций, выполняемых над различными процессами, и сопровождается переключением процессора с одного процесса на другой. При таком переходе ОС должна обеспечить смену контекста процесса. На это уходит определенное время, причем это непроизводственные затраты. Время переключения в различных машинах колеблется от 1 до 1000 микросекунд.
С целью снижения этих затрат вводят более мелкую единицу, чем процесс. В некоторых ОС эта единица называется потоком, а в других нитями.
Заключение. Понятие процесса характеризует некоторую совокупность набора исполняющихся команд, ассоциированных с ними ресурсов и текущего момента его выполнения (значение регистровой составляющей контекста), и все это под управлением ОС. В любой момент процесс полностью отлеживается своим контекстом, состоящим из регистровой, системной и пользовательской частей.
В ОС процессы представляются определенной структурой данных (PCB), отражающей содержание регистрового и системного контекста.
Процессы могут находиться в 5 основных состояниях: рождение, готовность, исполнение, ожидание, завершение. Из состояния в состояние процесс переводится ОС в результате выполнения над ним операций. ОС может выполнять над процессами следующие операции:
· создание и завершение процесса
· приостановка и запуск процесса
· блокирование и разблокирование процесса
· изменение приоритета процесса
Между операциями содержимое PCB не изменятся. Переключение контекста не имеет отношения к полезной работе. Время, затраченное на него, сокращает полезное время работы процессора.
Планирование процессов. Уровни планирования
Процессы – деятельность ОС. Одной из составляющих процессов являются ресурсы. Они ограничены. Поскольку процессов много, необходимо организовать координацию их использования. Кроме того, процессы – это деятельность, и, следовательно, у них должна быть определенная цель. С помощью предоставленных ресурсов и алгоритмов планирования эти цели должны быть достигнуты.
Потенциально алгоритмов может быть много, поэтому должны быть некоторые критерии для их выбора.
Далее будем рассматривать, каким образом осуществляется планирование исполнения процессов в мультипрограммных ВС.
Определенный уровень планирования осуществляется еще в пакетных системах, поскольку с помощью команд управления заданиями осуществляется планирование самих заданий с одной стороны и процессора с другой стороны.
Планированием заданий называется процедура выбора очередного задания для загрузки в машину, т.е. порождение соответствующего процессора.
Планирование использования процессора впервые было осуществлено в мультипрограммных ВС, поскольку в них может существовать несколько процессов, которые находятся в стадии готовность.
Необходима процедура выбора того процесса, который будет переведен из состояния готовность в состояние исполнение.
Принято планирование заданий рассматривать в качестве долгосрочного планирования процесса. Этот уровень планирования отвечает за порождение новых процессов в системе. Именно здесь определяется количество процессов, одновременно находящихся в системе (это количество ограничено и называется степенью мультипрограммирования). Если она поддерживается постоянной (в среднем), то новые процессы могут появляться только после завершения ранее загруженных. Поэтому долгосрочное планирование осуществляется достаточно редко, интервал времени между возникновением процессов может составлять от минуты до десятков минут.
Выбор того или иного процесса на исполнение определяет функционирование всей системы на достаточно длительный период. Поэтому этот уровень планирования и называется долгосрочным.
Существуют системы, в которых он может отсутствовать. Одним из средств разумной степени мультипрограммирования является ограничение количества пользователей в системе.
К категории краткосрочного планирования процессов отводят планирование использования процессора. Необходимость такого планирования возникает, например, при обращении исполняющегося процесса к устройствам ввода-вывода или при завершении кванта времени, выделенного для данного процесса.
Осуществляется краткосрочное планирование не реже одного раза в 100 милисекунд. Отсюда и название уровня планирования: краткосрочное.
В ряде случаев целесообразно переместить частично выполнившийся процесс из ОЗУ на диск, а потом, при определенных условиях, вернуть его обратно. Такая процедура называется свопингом (swapping, «перекачка»).
Свопингом необходимо управлять. Этот вид управления процессами называется среднесрочным.
Критерии планирования и требования к алгоритмам
Понятно, что могут существовать различные алгоритмы планирования. И хотелось бы, чтобы они были универсальны, но реально этого не происходит. Чаще всего тот или иной алгоритм подходит к определенному классу задач (с одной стороны), а с другой зависит от поставленных целей при планировании.
К числу таких целей можно отнести следующие:
¾ справедливость (не должно быть ситуации, когда один процесс постоянно занимает процессор)
¾ эффективность (идеально процессор должен быть занят на 100%, реально – 40-90%)
¾ сокращение полного времени выполнения
¾ сокращение времени ожидания в состоянии готовность
¾ сокращение времени отклика (в интерактивных системах)
Независимо от поставленных целей планирования желательно также, чтобы алгоритмы обладали следующими свойствами:
· были предсказуемыми (одно и то же задание должно выполняться приблизительно за одно и то же время)
· были связаны с минимальными накладными расходами (например, при переключении контекста)
· равномерно загружали ресурсы в ВС (предпочтение тем процессам, которые буду занимать малоиспользуемые ресурсы)
· обладали масштабируемостью (при увеличении «нагрузки» не должны резко терять работоспособность)
Многие из приведенных выше целей и свойств алгоритмов являются противоречивыми. Улучшая работу алгоритма с точки зрения одного критерия, мы его ухудшаем с точки зрения другого. Приспосабливая алгоритм под один класс задач, мы тем самым дискриминируем задачи другого класса.
Параметры планирования
При планирование ОС опирается на два класса параметров объекта. Первый класс отражает статистические параметры, второй – динамические. Статистические параметры не изменяются в ходе функционирования ОС. Динамические постоянно изменяются.
К статическим параметрам ВС можно отнести предельные значения ее ресурсов:
· размер ОЗУ
· максимальное количество памяти на диске для осуществления свопинга
· количество подключенных устройств ввода-вывода
Динамические параметры системы отслеживают количество свободных ресурсов на данный момент.
К статическим параметрам процессов относятся характеристики, как правило, присущие заданиям уже на этапе загрузки:
¾ каким пользователем запущен процесс или сформировано задание
¾ насколько важной является поставленная задача, т.е. каков приоритет ее выполнения
¾ сколько процессорного времени запрошено пользователем для решения задачи
¾ каково соотношение процессорного времени и времени, необходимого для осуществления операций ввода-вывода
¾ какие ресурсы ВС (ОЗУ, устройства ввода-вывода, специальные библиотеки и системные программы и т.д.) и в каком количестве необходимы заданию.
Алгоритмы долгосрочного планирования используют в своей работе статические и динамические параметры ВС и статические параметры процессов (динамические параметры процессов на этапе загрузки заданий еще неизвестны).
Алгоритмы краткосрочного и среднесрочного планирования дополнительно учитывают и динамические характеристики процессов.
Для среднесрочного планирования в качестве таких характеристик может использоваться следующая информация:
¾ сколько времени прошло с момента выгрузки процесса на диск или его загрузки в ОЗУ
¾ сколько ОЗУ занимает процесс
¾ сколько процессорного времени уже предоставлено процессу
Для краткосрочного планирования нам понадобится ввести еще два динамических параметра.
Деятельность любого процесса можно представить как последовательность циклов использования процессора (CPU-burst) и ожидания завершения операций ввода-вывода (I/O burst).
Вытесняющее и невытесняющее планирование
Процесс планирования осуществляется частью ОС, называемой планировщиком. Он может принимать решения о выборе для исполнения нового процесса из числа находящихся в состоянии готовность в следующих 4 случаях:
1. когда процесс переводится из состояния исполнение в состояние закончил исполнение
2. когда процесс переводится из состояния исполнение в состояние ожидание
3. когда процесс переводится из состояния исполнение в состояние готовность (например, после прерывания от таймера)
4. когда процесс переводится из состояния ожидание в состояние готовность (завершилась операция ввода-вывода или произошло другое событие)
В случаях 1и 2 процесс, находящийся в состоянии исполнение не может дальше исполняться и ОС вынуждена осуществлять планирование, выбирая новый процесс для выполнения.
В случаях 3 и 4 планирование может как проводиться, так и не проводиться. Планировщик не вынужден обязательно принимать решение о выборе процесса для выполнения. Процесс, находящийся в состоянии исполнение может просто продолжить свою работу.
Если в ОС планирование осуществляется только в вынужденных ситуациях, говорят, что имеет место невытесняющее планирование.
Если планировщик принимает и вынужденные, и невынужденные решения, говорят о невытесняющем планировании.
Термин «вытесняющее планирование» возник потому, что исполняющийся процесс может быть вытеснен из состояния исполнение другим процессом.
Невытесняющее планирование проще организовано и минимум затрат на переключение контекста, но существует реальная опасность «полного захвата» процессора исполняющимся процессом (зацикливание). Выход в подобной ситуации: перезагрузка всей системы.
Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме процесс может быть приостановлен в любой момент исполнения.
Алгоритм планирования процессов First-Come, First-Served (FCFS)
Реально существует множество разнообразных алгоритмов планирования. Каждый из них эффективен для определенного класса задач.
Существуют алгоритмы, которые можно применять на различных уровнях планирования.
Далее мы будем рассматривать алгоритмы применимо к кратковременному планированию First-Come, First-Served (FCFS).
Логика этого алгоритма проста: первый пришел, первый обслужен. Этот алгоритм предполагает, что существует очередь процессов, готовых к исполнению. Если возникает новый процесс, то он помещается в конец этой очереди. Подобный тип очереди называет FIFO – сокращенно (первым вошел, первым вышел).
Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Это значит, что процесс, получивший в свое распоряжение процессор, занимает его до истечения текущего CPU-burst. После этого для выполнения выбирается новый процесс из начала очереди.
Алгоритм легко реализуется, но имеет много недостатков.
Рассмотрим следующий пример: имеется очередь из процессов в состоянии готовность – р0, р1, р2. Пусть известны времена их очередных CPU burst. Для упрощения анализа введем следующее предположение:
1. Вся деятельность процессов ограничивается использованием только одного промежутка CPU-burst.
2. Процессы не совершают операции ввода-вывода
3. Время переключения контекста мало, и будем им пренебрегать
Первым выполняется процесс р0, который получает процессор на все время своего CPU-burst, т.е. на 13 единиц времени. Этот процесс первый в очереди. После его окончания в состояние исполнение приводится процесс р1 (он второй в очереди). Занимает процессор на 4 единицы времени, в соответствии с его СPU-burst. После его окончания на исполнение передается последний процесс р2, который исполняется за одну единицу времени, в соответствии с его СPU-burst.
Время ожидания для процессов: р0 – 0 единиц времени, р1 – 13 единиц, р2 – 17 единиц. Среднее время ожидания процессов равно 10 единиц.
Полное время выполнения для процесса: р0 = 13 единиц, р1 = 17 единиц, р2 = 18 единиц. Среднее полное время выполнения всех процессов равно 16 единиц.
Изменим ситуацию в очереди, короткие процессы впереди: р2, р1, р0.
Время ожидания для процессов: р0 – 5 единиц времени, р1 – 1 единица, р2 – 0 единиц. Среднее время ожидания процессов равно 2 единиц. Это в 5 раз меньше!, чем в предыдущем случае.
Полное время выполнения для процесса: р0 = 18 единиц, р1 = 5 единиц, р2 = 1 единица. Среднее полное время выполнения всех процессов равно 8 единиц. Почти в два раза меньше, чем при первой расстановке процессов.
Как видно, среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от положения процессов в очереди.
Возможна ситуация, когда впереди находится процесс с очень большой длительностью, тогда более кратковременные процессы могут долго ждать своего исполнения.
В силу этого, алгоритм FCFS практически неприменим для систем разделения времени. Поскольку слишком большим получается среднее время отклика в интерактивных процессах.
Алгоритм планирования процессов Round Robin (RR)
Отмеченные недостатки устраняются в следующем алгоритме: Round Robin (RR).
В целом он похож на предыдущий алгоритм, но дополнительно вводится механизм вытесняющего планирования.
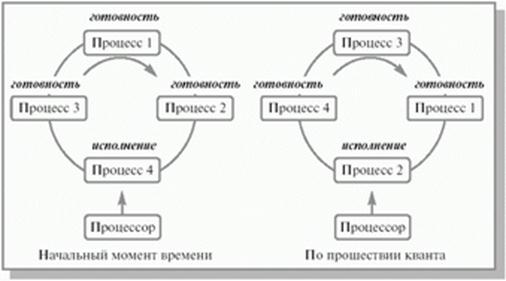
Как и прежде существует очередь готовых к исполнению процессов. Вводится дополнительное ограничение, которое названо квантом времени, в течении которого процесс может обслуживаться процессором в непрерывном режиме.
Квант времени может составлять 10-100 милисекунд. По завершению кванта работы по данному процессу в состояние исполнение переводится следующий в очереди процесс. За счет этого очередь приобретает цикличный характер.
Здесь показано, что обслуживается процесс, который находится возле процессора. Поскольку карусель вращается, то время такого обслуживания и будет соответствовать кванту времени. Как видно из рисунка, после того, как отработал процесс 4, на исполнение передан процесс 2.
Исполнение каждого из процессов осуществляется каждый раз только в рамках кванта времени.
Рассмотрим предыдущий пример с порядком процессов p0, p1, p2 и величиной кванта времени равной 4.
Выполнение этих процессов иллюстрируется таблицей.
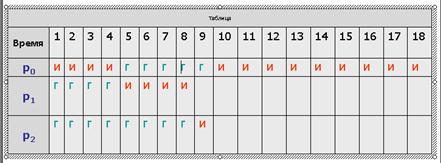
Обозначение "И" используется в ней для процесса, находящегося в состоянии Исполнение, обозначение "Г" – для процессов в состоянии Готовность, пустые ячейки соответствуют завершившимся процессам.
Состояния процессов показаны на протяжении соответствующей единицы времени, т. е. колонка с номером 1 соответствует промежутку времени от 0 до 1.
Первым для исполнения выбирается процесс p0. Продолжительность его CPU burst больше, чем величина кванта времени, и поэтому процесс исполняется до истечения кванта, т. е. в течение 4 единиц времени.
После этого он помещается в конец очереди готовых к исполнению процессов, которая принимает вид p1, p2, p0.
Следующим начинает выполняться процесс p1. Время его исполнения совпадает с величиной выделенного кванта, поэтому процесс работает до своего завершения.
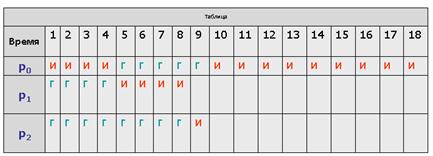
Теперь очередь процессов в состоянии готовность состоит из двух процессов, p2 и p0.
Процессор выделяется процессу p2.
Он завершается до истечения отпущенного ему процессорного времени, и очередные кванты отмеряются процессу p0 – единственному не закончившему к этому моменту свою работу.
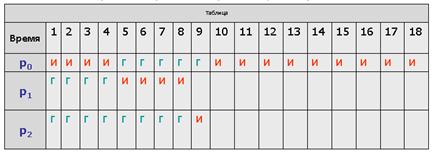
Время ожидания (количество символов "Г" в соответствующей строке) для процесса:
p0 составляет 5 единиц времени,
p1 составляет 4 единицы времени,
p2 составляет 8 единиц времени.
Среднее время ожидания получается равным
(5 + 4 + 8)/3 = 5,6(6) единицы времени.
Полное время выполнения (количество непустых столбцов в соответствующей строке) для процесса:
p0 составляет 18 единиц времени,
p1 составляет 8 единиц времени,
p2 составляет 9 единиц времени.
Среднее полное время выполнения оказывается равным
(18 + 8 + 9)/3 = 11,6(12) единиц времени.
Если аналогичным образом рассчитать показатели для обратного порядка процессов – p2, p1,p0, то увидим
что среднее время ожидания и среднее полное время выполнения не отличаются от соответствующих времен для алгоритма FCFS и составляют 2 и 8 единиц времени соответственно.
На производительность алгоритма RR сильно влияет величина кванта времени.
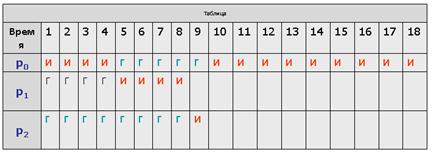
Рассмотрим тот же самый пример с порядком процессов p0, p1, p2 для величины кванта времени, равной 1 (см. табл.).
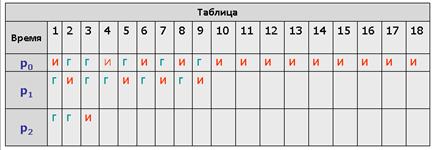
Время ожидания для процесса
p0 составит 5 единиц времени,
p1 составит тоже 5 единиц,
p2 составит 2 единицы.
Среднее время ожидания получается равным
(5 + 5 + 2)/3 = 4 единицам времени.
Среднее полное время исполнения составит
18 + 9 + 3)/3 = 10 единиц времени.
При очень больших величинах кванта времени, когда каждый процесс успевает завершить свой CPU burst до возникновения прерывания по времени, алгоритм RR вырождается в алгоритм FCFS.
При очень малых величинах создается иллюзия того, что каждый из n процессов работает на собственном виртуальном процессоре с производительностью ~ 1/n от производительности реального процессора
Правда, это справедливо лишь при теоретическом анализе при условии пренебрежения временами переключения контекста процессов.
В реальных условиях при слишком малой величине кванта времени и, соответственно, слишком частом переключении контекста накладные расходы на переключение резко снижают производительность системы.
Алгоритм планирования процессов Shortest-Job-First (невытесняющий)
При рассмотрении алгоритмов FCFS и RR мы видели, насколько существенным для них является порядок расположения процессов в очереди процессов, готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает.
Если бы мы знали время следующих CPU burst для процессов, находящихся в состоянии готовность, то могли бы выбрать для исполнения не процесс из начала очереди, а процесс с минимальной длительностью CPU burst. Если же таких процессов два или больше, то для выбора одного из них можно использовать уже известный нам алгоритм FCFS. Квантование времени при этом не применяется.
Описанный алгоритм получил название "кратчайшая работа первой" или Shortest Job First (SJF).
SJF-алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим.
При невытесняющем SJF-планировании процессор предоставляется избранному процессу на все необходимое ему время, независимо от событий, происходящих в вычислительной системе.
Рассмотрим пример работы невытесняющего алгоритма SJF. Пусть в состоянии готовность находятся четыре процесса, p0, p1, p2 и p3, для которых известны времена их очередных CPU burst. Эти времена приведены в таблице.
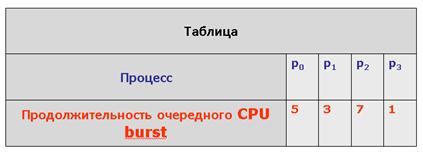
Как и прежде, будем полагать, что вся деятельность процессов ограничивается использованием только одного промежутка CPU burst, что процессы не совершают операций ввода-вывода и что временем переключения контекста можно пренебречь
При использовании невытесняющего алгоритма SJF первым для исполнения будет выбран процесс p3, имеющий наименьшее значение продолжительности очередного CPU burst. После его завершения для исполнения выбирается процесс p1, затем p0 и, наконец, p2.
Как мы видим, среднее время ожидания для алгоритма SJF составляет
(4 + 1 + 9 + 0)/4 = 3,5 единицы времени.
Для алгоритма FCFS при порядке процессов p0, p1, p2, p3 среднее время ожидания будет равняться
(0 + 5 + 8 + 15)/4 = 7 единицам времени,
т. е. будет в два раза больше, чем для алгоритма SJF.
Можно показать, что для заданного набора процессов (если в очереди не появляются новые процессы) алгоритм SJF является оптимальным с точки зрения минимизации среднего времени ожидания среди класса невытесняющих алгоритмов
Основную сложность при реализации алгоритма SJF представляет невозможность точного знания продолжительности очередного CPU burst для исполняющихся процессов.
В пакетных системах количество процессорного времени, необходимое заданию для выполнения, указывает пользователь при формировании задания. Мы можем брать эту величину для осуществления долгосрочного SJF-планирования.
Если пользователь укажет больше времени, чем ему нужно, он будет ждать результата дольше, чем мог бы, так как задание будет загружено в систему позже.
Если же он укажет меньшее количество времени, задача может не досчитаться до конца.
Таким образом, в пакетных системах решение задачи оценки времени использования процессора перекладывается на плечи пользователя.
При краткосрочном планировании мы можем делать только прогноз длительности следующего CPU burst, исходя из предыстории работы процесса
Алгоритм планирования процессов Shortest-Job-First (вытесняющий)
При вытесняющем SJF-планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса.
Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
Для рассмотрения примера вытесняющего SJF планирования мы возьмем ряд процессов p0, p1, p2 и p3 с различными временами CPU burst и различными моментами их появления в очереди процессов, готовых к исполнению (см. табл)
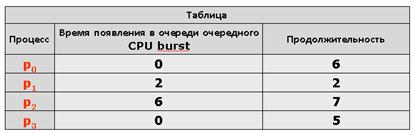
В начальный момент времени в состоянии готовность находятся только два процесса, p0 и p3. Меньшее время очередного CPU burst оказывается у процесса p3, поэтому он и выбирается для исполнения (см. табл.).
По прошествии 2 единиц времени в систему поступает процесс p1. Время его CPU burst меньше, чем остаток CPU burst у процесса p3, который вытесняется из состояния исполнение и переводится в состояние готовность.
По прошествии еще 2 единиц времени процесс p1 завершается, и для исполнения вновь выбирается процесс p3.
В момент времени t = 6 в очереди процессов, готовых к исполнению, появляется процесс p2, но поскольку ему для работы нужно 7 единиц времени, а процессу p3 осталось трудиться всего 1 единицу времени, то процесс p3 остается в состоянии исполнение.
После его завершения в момент времени t = 7 в очереди находятся процессы p0 и p2, из которых выбирается процесс p0. Наконец, последним получит возможность выполняться процесс p2.
Приоритетное планирование процессов (невытесняющий и вытесняющий вариант)
Приоритетное планирование
Алгоритм SJF представляет собой частный случай приоритетного планирования.
При приоритетном планировании каждому процессу присваивается определенное числовое значение – приоритет, в соответствии с которым ему выделяется процессор.
Процессы с одинаковыми приоритетами планируются в порядке FCFS.
Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс
Алгоритмы назначения приоритетов процессов могут опираться как на внутренние параметры, связанные с происходящим внутри вычислительной системы, так и на внешние по отношению к ней.
К внутренним параметрам относятся различные количественные и качественные характеристики процесса такие как: ограничения по времени использования процессора, требования к размеру памяти, число открытых файлов и используемых устройств ввода-вывода, отношение средних продолжительностей I/O burst к CPU burst и т. д.
Алгоритм SJF использует внутренние параметры.
В качестве внешних параметров могут выступать важность процесса для достижения каких-либо целей, стоимость оплаченного процессорного времени и другие политические факторы.
Высокий внешний приоритет может быть присвоен задаче лектора или того, кто заплатил $100 за работу в течение одного часа.
Планирование с использованием приоритетов может быть как вытесняющим, так и невытесняющим.
При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом.
В случае невытесняющего планирования он просто становится в начало очереди готовых процессов.
Давайте рассмотрим примеры использования различных режимов приоритетного планирования
Пусть в очередь процессов, находящихся в состоянии готовность, поступают те же процессы, что и в примере для вытесняющего алгоритма SJF, только им дополнительно еще присвоены приоритеты (см. табл.).
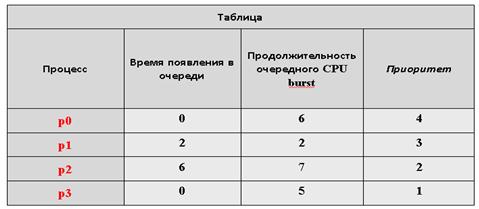
В вычислительных системах не существует определенного соглашения, какое значение приоритета – 1 или 4 считать более приоритетным.
Во избежание путаницы, во всех наших примерах мы будем предполагать, что большее значение соответствует меньшему приоритету, т. е. наиболее приоритетным в нашем примере является процесс p3, а наименее приоритетным – процесс p0.
Как будут вести себя процессы при использовании невытесняющего приоритетного планирования?
Первым для выполнения в момент времени t = 0 выбирается процесс p3, как обладающий наивысшим приоритетом.
После его завершения в момент времени t = 5 в очереди процессов, готовых к исполнению, окажутся два процесса p0 и p1.
Больший приоритет из них у процесса p1, он и начнет выполняться (см. табл.). Затем в момент времени t = 8 для исполнения будет избран процесс p2, и лишь потом – процесс p0.
Иным будет предоставление процессора процессам в случае вытесняющего приоритетного планирования (см. табл.).
Первым, как и в предыдущем случае, начнет исполняться процесс p3, а по его окончании – процесс p1. Однако в момент времени t = 6 он будет вытеснен процессом p2 и продолжит свое выполнение только в момент времени t = 13. Последним, как и раньше, будет исполняться процесс p0.
В рассмотренном выше примере приоритеты процессов с течением времени не изменялись. Такие приоритеты принято называть статическими.
Механизмы статической приоритетности легко реализовать, и они сопряжены с относительно небольшими издержками на выбор наиболее приоритетного процесса.
Однако статические приоритеты не реагируют на изменения ситуации в вычислительной системе, которые могут сделать желательной корректировку порядка исполнения процессов
Более гибкими являются динамические приоритеты процессов, изменяющие свои значения по ходу исполнения процессов.
Начальное значение динамического приоритета, присвоенное процессу, действует в течение лишь короткого периода времени, после чего ему назначается новое, более подходящее значение.
Изменение динамического приоритета процесса является единственной операцией над процессами, которую мы до сих пор не рассмотрели.
Как правило, изменение приоритета процессов проводится согласованно с совершением каких-либо других операций: при рождении нового процесса, при разблокировке или блокировании процесса, по истечении определенного кванта времени или по завершении процесса.
Примерами алгоритмов с динамическими приоритетами являются алгоритм SJF и алгоритм гарантированного планирования.
Схемы с динамической приоритетностью гораздо сложнее в реализации и связаны с большими издержками по сравнению со статическими схемами.
Однако их использование предполагает, что эти издержки оправдываются улучшением работы системы.
Главная проблема приоритетного планирования заключается в том, что при ненадлежащем выборе механизма назначения и изменения приоритетов низкоприоритетные процессы могут не запускаться неопределенно долгое время.
Обычно случается одно из двух. Или они все же дожидаются своей очереди на исполнение (в девять часов утра в воскресенье, когда все приличные программисты ложатся спать).
Или вычислительную систему приходится выключать, и они теряются (при остановке IBM 7094 в Массачусетском технологическом институте в 1973 году были найдены процессы, запущенные в 1967 году и ни разу с тех пор не исполнявшиеся).
Решение этой проблемы может быть достигнуто с помощью увеличения со временем значения приоритета процесса, находящегося в состоянии готовность.
Пусть изначально процессам присваиваются приоритеты от 128 до 255. Каждый раз по истечении определенного промежутка времени значения приоритетов готовых процессов уменьшаются на 1.
Процессу, побывавшему в состоянии исполнение, присваивается первоначальное значение приоритета. Даже такая грубая схема гарантирует, что любому процессу в разумные сроки будет предоставлено право на исполнение
Многоуровневые очереди в планировании процессов (без обратной связи и с обратной связью)
(Multilevel Queue)
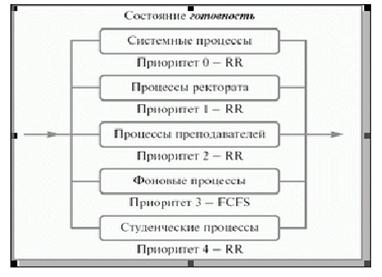
Для систем, в которых процессы могут быть легко рассортированы по разным группам, был разработан другой класс алгоритмов планирования. Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность
Этим очередям приписываются фиксированные приоритеты.
Например, приоритет очереди системных процессов устанавливается выше, чем приоритет очередей пользовательских процессов.
А приоритет очереди процессов, запущенных студентами, ниже, чем для очереди процессов, запущенных преподавателями.
Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению
Внутри этих очередей для планирования могут применяться самые разные алгоритмы.
Так, например, для больших счетных процессов, не требующих взаимодействия с пользователем (фоновых процессов), может использоваться алгоритм FCFS, а для интерактивных процессов – алгоритм RR.
Подобный подход, получивший название многоуровневых очередей, повышает гибкость планирования: для процессов с различными характеристиками применяется наиболее подходящий им алгоритм
Многоуровневые очереди с обратной связью (Multilevel Feedback Queue)
Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи.
Здесь процесс не постоянно приписан к определенной очереди, а может мигрировать из одной очереди в другую в зависимости от своего поведения.
Для простоты рассмотрим ситуацию, когда процессы в состоянии готовность организованы в 4 очереди, как на рисунке
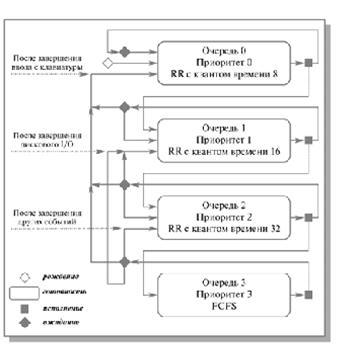
Рис. Схема миграции процессов в многоуровневых очередях планирования с обратной связью. Вытеснение процессов более приоритетными процессами и завершение процессов на схеме не показано
Планирование процессов между очередями осуществляется на основе вытесняющего приоритетного механизма. Чем выше на рисунке располагается очередь, тем выше ее приоритет.
Процессы в очереди 1 не могут исполняться, если в очереди 0 есть хотя бы один процесс.
Процессы в очереди 2 не будут выбраны для выполнения, пока есть хоть один процесс в очередях 0 и 1.
И наконец, процесс в очереди 3 может получить процессор в свое распоряжение только тогда, когда очереди 0, 1 и 2 пусты.
Если при работе процесса появляется другой процесс в какой-либо более приоритетной очереди, исполняющийся процесс вытесняется новым.
Планирование процессов внутри очередей 0–2 осуществляется с использованием алгоритма RR, планирование процессов в очереди 3 основывается на алгоритме FCFS.
Родившийся процесс поступает в очередь 0. При выборе на исполнение он получает в свое распоряжение квант времени размером 8 единиц. Если продолжительность его CPU burst меньше этого кванта времени, процесс остается в очереди 0. В противном случае он переходит в очередь 1.
Для процессов из очереди 1 квант времени имеет величину 16. Если процесс не укладывается в это время, он переходит в очередь 2. Если укладывается – остается в очереди 1.
В очереди 2 величина кванта времени составляет 32 единицы. Если для непрерывной работы процесса и этого мало, процесс поступает в очередь 3, для которой квантование времени не применяется и, при отсутствии готовых процессов в других очередях, может исполняться до окончания своего CPU burst.
Чем больше значение продолжительности CPU burst, тем в менее приоритетную очередь попадает процесс, но тем на большее процессорное время он может рассчитывать.
Таким образом, через некоторое время все процессы, требующие малого времени работы процессора, окажутся размещенными в высокоприоритетных очередях, а все процессы, требующие большого счета и с низкими запросами к времени отклика, – в низкоприоритетных
Миграция процессов в обратном направлении может осуществляться по различным принципам.
Например, после завершения ожидания ввода с клавиатуры процессы из очередей 1, 2 и 3 могут помещаться в очередь 0, после завершения дисковых операций ввода-вывода процессы из очередей 2 и 3 могут помещаться в очередь 1, а после завершения ожидания всех других событий – из очереди 3 в очередь 2.
Перемещение процессов из очередей с низкими приоритетами в очереди с высокими приоритетами позволяет более полно учитывать изменение поведения процессов с течением времени.
Многоуровневые очереди с обратной связью представляют собой наиболее общий подход к планированию процессов из числа подходов, рассмотренных нами.
Они наиболее трудны в реализации, но в то же время обладают наибольшей гибкостью.
Понятно, что существует много других разновидностей такого способа планирования, помимо варианта, приведенного выше. Для полного описания их конкретного воплощения необходимо указать:
· Количество очередей для процессов, находящихся в состоянии готовность.
· Алгоритм планирования, действующий между очередями.
· Алгоритмы планирования, действующие внутри очередей.
· Правила помещения родившегося процесса в одну из очередей.
· Правила перевода процессов из одной очереди в другую.
Изменяя какой-либо из перечисленных пунктов, мы можем существенно менять поведение вычислительной системы.
Дата публикования: 2014-11-04; Прочитано: 6169 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
