 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Программа на языке ассемблера состоит из последовательности строк
|
|
Строка программы состоит из комбинации лексем, заканчивающихся символом возврата каретки “ – (CR) или перевод строки (LF)”.
Лексема – минимальная законченная конструкция, принадлежащая определённому классу и получающая после трансляции определенное значение.
Лексемы делятся на идентификаторы (метки или имена) и константы.
Имена, используемые в лексемах, делятся на ключевые слова, зарезервированные системой и имена, определяемые пользователем.
Ключевые слова включают имена РОН МП х86, мнемонические имена команд МП, имена директив, префиксов и операций в выражениях.
Строка программы может иметь вид:
Label directive comment-
или
Label: command comment-
где Label – метка, имя или идентификатор;
directive и command – соответственно директива и команда;
comment – комментарий.
Метка, упреждающая команду вместе с отделяющим ее знаком: может быть записана в отдельной строке. Комментарий является не транслируемой комбинацией любых символов, начинающихся знаком;. Наличие метки или комментария необязательно.
Команды ассемблера представляют мнемоническую запись соответствующей команды МП и определяют действие процессора. В отличие от них директивы (псевдооператоры) сообщают ассемблеру, какие действия ему нужно выполнить с командами и данными. Обозначение команд и данных могут быть записаны как прописными, так и строчными буквами (данная версия ассемблера не различает их).
3.2.2. Идентификаторы
Метка (имя определяется пользователем) – это идентификатор, сопровождающий директиву или команду. Метка состоит из ряда букв и цифр, начинающегося с буквы. Используются большие и маленькие буквы английского алфавита, а также знаки @, $, &. Все метки делятся:
- метки констант, например: FAT EQU 13;
- метки переменных, например: VALUE DB 4H;
- метки команд, например: MET: MOV AX, 10;
- метки сегментов, например: DAT SEGMENT;
- - - - - - - - - - -
- - - - - - - - - - -
DAT ENDS;
- метки процедур, например FUN PROC
- - - - - - -
FUN ENDP;
- метки макроопределения SHIFT MACRO.
.. ---------
SHIFT ENDM.
В каждом модуле данная метка может появиться только один раз. Каждой метке (имени) ассемблер присваивает уникальный адрес. Метка команды характеризуется двумя атрибутами: сегментом и смещением (seg: offset) и определяет адрес помеченной команды. Метка переменной характеризуется тремя атрибутами: сегментом, смещением и типом. Сегмент и смещение определяют начальный адрес ячейки памяти содержащей переменную. Тип определяет число байтов памяти, выделяемых под переменную.
3.2.3 Константы
Константы делятся на арифметические и символьные. Арифметические константы делятся на целые и действительные. Целые в свою очередь могут быть двоичными, состоящими из двоичных цифр, заканчивающихся буквой В, десятичными, восьмеричными (заканчиваются буквой О) и шестнадцатеричными (заканчиваются буквой Н).
Примеры представления констант:
30 – целая десятичная;
1ЕН – целая шестнадцатеричная;
1011В – целая двоичная;
3.27Е+3 – действительная;
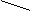 “*” – знаковая;
“*” – знаковая;
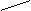 “HELLO” – цепная. Символьные константы.
“HELLO” – цепная. Символьные константы.
Символьные константы представляют собой один или несколько кодов ASCII, заключенные в кавычки.
3.2.4 Типы команд
Команды ассемблера делятся на команды без аргументов унарные (одноаргументные) и бинарные (двух аргументные) (см. табл.5).
Например:
WAIT
INT 21H
MOV AX, 38H.
В двух аргументных командах первый аргумент является приемником, а второй источником.
В начале исполнения программы распознаются только команды МП 8086 и сопроцессора 8087. Прием команд от иного МП требует использования директив выбора МП, например:. 80286,. 80287 и т.д.
3.2.5. Директивы
С помощью директив можно определять сегменты и процедуры, давать имена командам и элементам данных, резервировать рабочие области памяти и т.д. В отличие от команд большинство директив не генерирует объектного кода. Некоторые директивы имеют структурированный характер и должны использоваться с другими родственными директивами. К такой группе, в частности, относятся изучаемые нами сегментные и процедурные директивы.
3.2.5.1. Директивы определения простых переменных
Это директивы, имеющие вид:
label kind arg, arg, arg.
где label – метка (имя) переменной,
kind – название одной из указанных директив
DB – для байтовых переменных;
DW – для слов;
DD – для двойных слов;
DF – для утроенных слов;
DQ – для 4 слов;
DT – для 5 слов.
Kind определяет, сколько ячеек памяти ассемблер должен выделить переменной c именем label;
arg – выражение, либо знак вопроса -? (равнозначно неопределенности переменной) или имеет вид
count DUP (arg, arg,.... arg),
где
dup- директива повторений,
count – количество повторений списка аргументов в скобках.
Если директива DB, а приписываемыми данными являются символы, то можно произвести объединение последовательности символов в цепной литерал.
Примеры инициализации переменных:
Creet DB ‘H’ ’E’ ’L’ ’L’ ’O’ или
Creet DB ‘HELLO’ - одно и то же.
NUM DW 3,?, 4, 3,?, 4,?, 5 или
NUM DW 2 DUP (3,?, 4),?, 5 - одно и то же.
DD 10000 - переменная без имени.
3.2.5.2. Директивы идентификации постоянных величин
К ним относятся директивы EQU и = (равно). С помощью директивы EQU можно назначить имена символам, символьным литералам, числам и меткам, а с помощью директивы = назначить имена только числам.
Директива EQU имеет вид:
name EQU exp,
а директива =
name = exp,
где name – назначаемое имя постоянной величины;
exp – числовое значение.
Постоянная величина, идентифицируемая директивой EQU, не переопределяется. Это ограничение не касается постоянных величин, назначаемых посредством директивы =.
Примеры:
COUNT = 0;
FIX EQU 13;
NEXT EQU FIX+2;
CREET EQU ‘HELLO’;
COUNT=COUNT+1.
3.2.5.3. Директивы описания сегментов
Пространство памяти воспринимается процессором как группа сегментов, определяемых в самой программе. Начало сегмента отмечается директивой segment, конец – ends. Директива segment имеет общий вид:
lab segment align combine class
- - - -
lab ends,
где lab – имя сегмента;
Атрибуты сегмента:
align – определяет способ помещения сегмента в ОЗУ;
combine – определяет способ соединения нескольких сегментов, объединенных одной и той же меткой, но находящихся в разных исходных модулях, в один сегмент;
class – тип информации, хранящейся в данном сегменте.
Атрибуты директивы segment используются чаще всего в случае, когда исходные тексты содержатся в разных файлах, транслируются независимо друг от друга и объединяются в единую программу на стадии компоновки.
Директива вызывает образование сегмента с именем lab.
Допускаются следующие значения атрибутов:
Align - способы размещения сегмента в ОЗУ могут быть:
BYTE – размещение сегмента на границе байта;
WORD – размещение сегмента на границе слова;
DWORD – размещение сегмента на границе двойного слова;
PARA – размещение сегмента на границе параграфа (т.е. базовый адрес сегмента кратен 16), принят по умолчанию;
PAGE – размещение сегмента на границе страницы (базовый адрес кратен 256).
Combine - способы объединения сегментов:
PRIVATE – запрещается сочетание с сегментами иных модулей – принят по умолчанию;
PUBLIC – соединение сегментов таким способом, чтобы размер созданного сегмента был бы равен сумме его составляющих;
COMMON – такое соединение сегментов, чтобы первые байты сочетаемых сегментов перекрывались и имели один начальный адрес;
STACK – соединение сегментов, как и в случае PUBLIC, для образования стека;
MEMORY – соединение сегментов, как и в случае PUBLIC, с размещением в оперативной памяти, в конце загрузочного модуля;
AT exp – размещение сегмента, начиная с вычисленного сегментного адреса – константы exp.
Class -тип хранимой информации имеет вид символа, заключенного в скобках, или апострофы. Например: ‘DATA’, ’CODE’ и т.д.
Если в первом модуле появляется несколько сегментных директив с одной и той же меткой, то все они неявно объединяются в одну сегментную директиву.
Директива ASSUME. Используется совместно с директивой SEGMENT и может иметь один из следующих видов:
ASSUME reg: name, reg: name,...., reg: name
ASSUME reg: NOTHING
ASSUME NOTHING.
Здесь reg является одним из 4 сегментных регистров МП (CS, DS, SS, ES),
name – символическое имя сегмента или группы сегментов.
Для первого вида директивы ASSUME её выполнение означает, что в указанном сегментном регистре reg будет находиться базовый адрес name. Второй вид директивы не гарантирует, что во время выполнения программы в регистре reg находится базовый адрес сегмента. Третий вид директивы распространяет отсутствие гарантий нахождения базового адреса сегмента для всех четырех регистров.
Директива GROUP. Общий вид директивы:
name GROUP segname1, segname2,...., segnameК.
где name – имя группы сегментов, состоящих из сегментов с именами segname, указанных после слова GROUP.
Выполнение этой директивы приведет к такому размещению сегментов с указанными именами segname, что все они окажутся в одном смежном сегменте оперативной памяти размером не более 64Кбайт. Поэтому доступ ко всем командам и данным может быть реализован с помощью одного сегментного регистра (как в МП 8080).
Пример использования директив SEGMENT и ASSUME:
Дата публикования: 2015-11-01; Прочитано: 347 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
