 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Ресурс – это абстрактная структура, имеющая множество атрибутов, характеризующих способы доступа к ресурсу и его физическое представление в системе 2 страница
|
|
Для обслуживания свопинга страниц применяются дисциплины замещения FIFO, LFU и LRU, которые упоминались при описании сегментного распределения памяти. Как правило, используются дисциплины аппаратно зависимые LFU и LRU, однако в семействе операционных систем Windows для обеспечения аппаратной независимости используется неэффективная дисциплина FIFO. Для компенсации её недостатка используется приём "буферизация". Он заключается в предварительной пометке страницы, подлежащей выводу во внешнюю память или расформированию. Если при дальнейшей работе страница и дальше используется редко или кратковременно, то она выгружается или расформировывается. Если до момента расформирования или выгрузки страница вызывается, то она уходит в конец очереди FIFO, а на её место помещается следующий кандидат. Таким образом, в голове очереди FIFO практически постоянно находятся часто или длительно используемые страницы.
Недостаток оперативной памяти приводит к тому, что в ней удаётся разместить не все часто используемые страницы. Вследствие этого с высокой частотой возникают прерывания выполнения программ для выполнения свопинга страниц. Это вредное явление называется "пробуксовкой памяти". Оно снижает производительность вычислительной системы. Одним из средств борьбы с пробуксовкой памяти является наращивание оперативной памяти.
В операционных системах, поддерживающих пакетный режим работы, применяется метод "рабочего множества". Установлено, что в течение конечного интервала времени Т среднее количество активных (т.е. часто или длительно используемых) страниц значительно меньше общего числа страниц, которые требуются работающими программами. Это множество активных страниц называется рабочим множеством. Тогда планировщик должен планировать только такое количество задач, сумма рабочих множеств которых не превышала бы возможности вычислительной системы.
Основным достоинством страничной организации памяти является малая фрагментация оперативной памяти. Однако неизбежным недостатком её является разделение программы на страницы, не учитывающее логические связи между элементами программы. Этот недостаток вызывает повышенное по сравнению с сегментным разделением памяти количество прерываний на переходы между страницами, что существенно снижает производительность систем. Существенными оказываются и накладные расходы на обслуживание страниц.
Сегментно-страничный способ организации памяти (рис. 2.4) предусматривает существование в виртуальном адресе элемента программы трёх компонент: номера сегмента, номера страницы в сегменте и номера ячейки памяти в странице. Если пренебречь разными размерами сегментов, то можно говорить о трехмерной модели адресного пространства, координатами которого являются номер сегмента, номер страницы и индекс ячейки памяти (рис. 2.4,а).
Операционная система ведёт таблицу дескрипторов сегментов текущей задачи и таблицу страниц сегмента задачи. При запуске программы в регистр дескрипторов сегментов записывается адрес таблицы дескрипторов сегментов. Вычисление физического адреса элемента программы осуществляется в три этапа:
вычисление адреса дескриптора сегмента как суммы адреса таблицы дескрипторов и номера сегмента;
вычисление адреса дескриптора страницы как суммы адреса начала сегмента и номера страницы;
вычисление адреса элемента программы как результата конкатенации адреса страницы и индекса элемента программы.
Очевидны большой расход памяти на таблицы дескрипторов сегментов и страниц и большие затраты времени на вычисление адреса, т.к. процедура вычисления адреса включает в себя две операции сложения и одну конкатенации. Преимуществами этого метода распределения памяти является практическое отсутствие её дефрагментации и низкое число прерываний выполнения программы на свопинг сегментов и страниц.
В целях уменьшения затрат времени на доступ к данным применяется кэширование по ассоциативному принципу. Ассоциативный принцип предусматривает замену результатов просмотра двух таблиц одним тегом, помещаемым в специальную ячейку кэш-памяти. Этот тег содержит адрес элемента программы в кэш-памяти. Поле тегов часто называют аргументом, а поле с данными – функцией.
 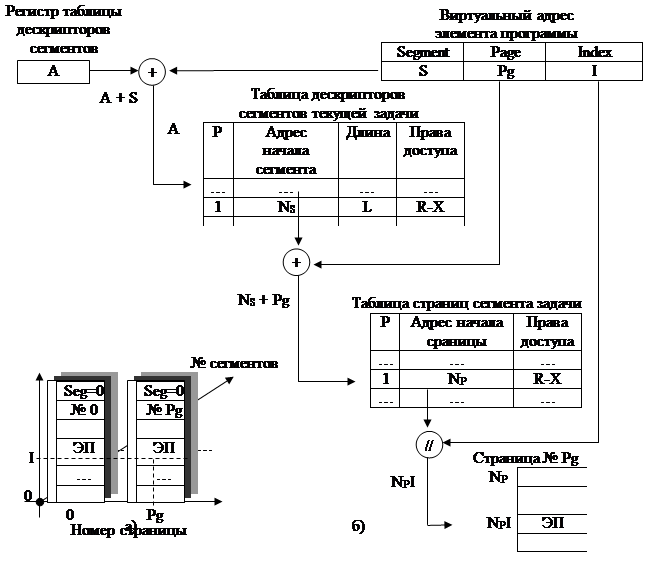 |
Рис. 2.4. Трёхмерная модель адресного пространства (а) и схема адресации (б)
при страничной организация памяти
В заключение изложенного следует отметить, что сегментно-страничная организация памяти является самой дорогой и в настоящее время используется, в основном, в высокопроизводительных вычислительных системах.
Контрольные вопросы:
Что такое символьные имена?
Что такое логическое адресное пространство?
Что такое виртуальное адресное пространство?
Что такое физическое адресное пространство?
Какую функцию при определении физического адреса данных и команд выполняет система программирования?
Какую функцию при определении физического адреса данных и команд выполняет операционная система?
Какую особенность имеют программы при полной тождественности виртуального адресного пространства и физической памяти?
Какую особенность имеют программы при полной идентичности виртуального адресного пространства и пространства имён программы?
Как происходит определение физического адреса по базовому адресу и смещению при загрузке программы?
Как физический адрес определятся при выполнении программы, если загрузчик программы не участвует в его определении?
Что такое простое непрерывное распределение памяти?
Какие недостатки имеет простое непрерывное распределение памяти?
Что такое распределение памяти с перекрытием?
Что такое оверлейные модули?
Что такое распределение памяти статическими разделами?
Какие недостатки имеет распределение памяти статическими разделами?
Что такое свопинг разделов?
Что такое фрагментация памяти?
Что такое распределение памяти с динамическими разделами?
Какой недостаток имеет распределение памяти с динамическими разделами?
Какими способами планировщик памяти выделяет раздел при появлении новой задачи?
Как происходит распределение памяти при её сегментной организации7
Какие недостатки имеет сегментная организация памяти?
Что такое таблица сегментов, какой она имеет формат и в каких целях она ведётся операционной системой?
Какой формат имеет логический адрес при сегментной организации памяти?
Как при сегментной организации памяти вычисляется физический адрес?
Какие дисциплины используются при свопинге сегментов?
Каковы недостатки сегментного способа организации памяти?
Что такое страница памяти?
Какой формат имеет логический адрес при страничной организации памяти?
Как распределяется память при её страничной организации?
Что такое таблица страниц? Каков её формат? В каких целях она ведётся?
Как определяется физический адрес при страничной организации памяти?
Каковы недостатки страничной организации памяти?
Что такое сегментно-страничная организация памяти?
Какой формат имеет логический адрес при сегментно-страничной организации памяти?
Как определяется физический адрес при сегментно-страничной организации памяти?
Опишите двумерную модель памяти?
Опишите трёхмерную модель памяти. При каких упрощениях возможно говорить о трёхмерной модели памяти?
3. УПРАВЛЕНИЕ ПРОЦЕССАМИ
3.1. Реализация последовательного процесса
в операционной системе
Запуск программы порождает процесс и вместе с ним описатель (дескриптор) процесса. Супервизор организует дескрипторы в очереди (например, входную очередь и очереди процессов, находящихся в состоянии готовности, ожидания и выполнения) и отображает изменение состояния процесса перемещением дескриптора из одной очереди в другую. Для состояний ожидания обычно ведётся столько очередей, сколько имеется ресурсов, могущих вызвать состояние ожидания. Порядок дескрипторов в очереди определяется хронологией их появления в очереди и приоритетом процесса. Число дескрипторов в системе может быть фиксированным или генерироваться в момент запуска операционной системы или динамически изменяющимся.
Как только система может выделить процессу все запрошенные им ресурсы, дескриптор процесса перемещается в очередь процессов, находящихся в состоянии готовности, и процесс ожидает очереди на выполнение. Как только завершается (или прерывается) выполняющийся процесс, управление передаётся процессу, стоящему первым в очереди на выполнение, и процесс начинает выполняться до прерывания или полного завершения. Если процесс завершён, то супервизор изымает дескриптор процесса из всех очередей. Если процесс прерван, то его дескриптор опять помещается в очередь процессов, находящихся в состоянии ожидания и выполнение процессов продолжается в порядке очерёдности.
Таким образом, при управлении процессами операционная система выполняет следующие основные функции:
создание и удаление задач в обобщающем смысле слова (это и процесс, и поток выполнения, т.к. они при управлении задачами не имеют существенных различий);
планирование процессов;
диспетчеризация задач;
синхронизация задач и обеспечение их средствами коммуникаций.
3.2. Планирование и диспетчеризация процессов и задач
Процессорное время является главным ресурсом вычислительной системы. Вполне естественна необходимость распорядиться им наиболее эффективно. А эффективность использования процессора в мультипрограммных и мультизадачных системах зависит от того, насколько рационально подобраны задачи с точки зрения минимизации конкурирования процессов и задач за доступ к имеющимся в системе ресурсам и от эффективности переключения процессора с выполнения одной задачи на выполнение другой.
При переключениях задач велика роль дескрипторов задач как информационных структур, сохраняющих контекст задачи на время прерывания её выполнения. В архитектуре современных мощных микропроцессоров предусмотрена поддержка хранения дескрипторов задач. С точки зрения надёжности работы это самое лучшее на сегодня решение. Однако, оказалось, что более эффективным является применение программных механизмов, которые применяются чаще, чем аппаратные.
Подбор процессов в целях минимизации их конкурирования за ресурсы называется планированием вычислительных процессов. Планирование процессов занимается планировщик задач, являющийся блоком супервизора. Планирование процессов осуществляется раз в минуту и реже.
Актуальность долгосрочного планирования процессов с развитием вычислительных систем снизилась. И, наоборот, возросла актуальность краткосрочного (динамического) планирования процессов и задач, которое приходится осуществлять практически при появлении каждого события. Динамическое планирование принято называть диспетчеризацией задач. Диспетчеризацию задач осуществляет другой блок супервизора – диспетчер задач. Диспетчер запускается раз 30 – 100 мс.
Планировщик процессов выбирает из входной очереди процессов такие процессы, чтобы образовалась мультипрограммная смесь, т.е. смесь процессов, ориентированных на использование разных ресурсов. Диспетчер решает, какая из задач готовых к выполнению должна быть передана на выполнение.
И долгосрочное и динамическое планирование осуществляются на основании ряда принципов, которые называют "стратегия планирования" (или "стратегия обслуживания") и "дисциплина обслуживания".
Стратегия планирования основана на следующих основных принципах:
по возможности заканчивать вычислительные процессы в том же порядке, в котором они были начаты;
отдавать предпочтение более коротким вычислительным задачам;
предоставлять всем процессам пользователей одинаковое время ожидания.
В стратегии планирования используется понятие "задача переднего плана" (foreground task). Этот термин родился из предположения "параллельная работа одного пользователя со множеством задач маловероятна". Поэтому из множества задач одного пользователя самый высокий приоритет имеет текущая задача, т.е. задача с которой он работает в текущий момент времени. В то же время для обеспечения нормальной работы коммуникационных процессов задачи ввода-вывода и управления должны иметь более высокий приоритет, чем задачи пользователя.
В широко распространённой системе Windows имеется возможность переключения стратегий обслуживания. В них по умолчанию установлена стратегия предоставления процессора задаче переднего плана. Однако, открыв окно "Система: Свойства" можно изменить стратегию. Например, в Windows 2000 можно выбрать "Оптимизировать быстродействие приложений", а в Windows XP – "Обеспечить наивысшее быстродействие".
В любом случае планировщик задач должен обеспечить нахождение в очереди задач на выполнение задач, ориентированных на использование разных ресурсов.
Дисциплин обслуживания (диспетчеризации) существует достаточно много (рис. 3.1). Прежде всего, они делятся на бесприоритетные и приоритетные. Бесприоритетные дисциплины не учитывают ни важность задач. Ни время их обслуживания. Приоритетные дисциплины предоставляют отдельным задачам право попасть на первоочередное обслуживание. Приоритет может быть постоянным и изменяемым (динамическим).







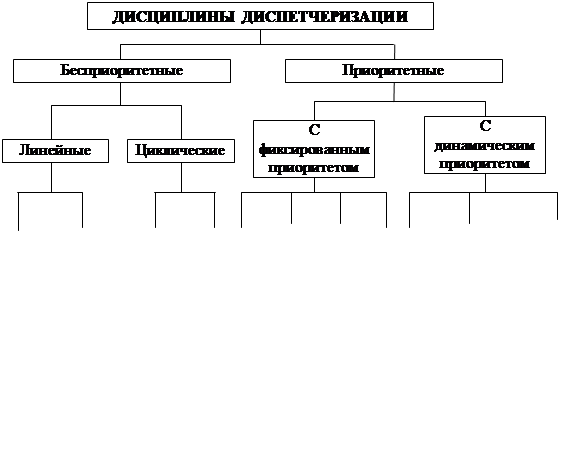
Рис. 3.1. Классификация дисциплин диспетчеризации
Наиболее просто реализуется дисциплина обслуживания в порядке очереди (FCFS – первым пришёл, первым обслужен).
Механизм прерывания выполняющихся процессов приводит к циклическим алгоритмам. В зависимости от способа обслуживания заблокированных задач различают вариант с одной общей очередью и с двумя параллельными очередями. В первом варианте заблокированная задача при её разблокировании ставится в конец общей очереди. Такой алгоритм можно отнести к бесприоритетным.
Во втором случае существует две параллельных очереди: очередь новых задач и очередь разблокированных задач. Разблокированные задачи выполняются перед новыми. Тем самым во втором варианте соблюдается первый принцип диспетчеризации. Эту дисциплину можно отнести уже к приоритетным дисциплинам. Она не требует перераспределения процессорного времени между задачами и относится к невытесняющим дисциплинам. Недостатком дисциплины является относительный рост времени ожидания выполнения коротких задач при росте загрузки вычислительной системы.
К циклическим приоритетным алгоритмам относится дисциплина SJN – следующей выполняется задача с наименьшим процессорным временем. Это требовало знания реально необходимого для выполнения задачи процессорного времени. Дисциплина предполагает наличие одной очереди задач, в которую ставятся на равных условиях и новые, и прерванные задачи. Таким образом короткие задачи вынуждены были ждать своей очереди наряду с прерванными, что является недостатком дисциплины.
От этого недостатка свободна дисциплина SRT (следующим выполняется задание, которому до полного выполнения необходимо меньше всех процессорного времени). Эта дисциплина относится также к циклическим приоритетным дисциплинам.
Последние три дисциплины хорошо применяются для пакетных режимов. Однако они создают две проблемы:
обеспечение задачам, с которыми работают пользователи, лучшего времени реакции, чем фоновым;
необходимость обеспечения гарантированного предоставления процессорного времени некоторым приложениям, выполняющимся без участия пользователя (например, программам получения электронной почты, использующие модем и коммутируемые линии).
Эти проблемы решает дисциплина RR (Round Robin), которая имеет и другое название: карусельная. Она использует циклический алгоритм с одной общей очередью задач на выполнение с предоставлением задачам процессорного времени квантами q. По истечении кванта времени задача снимается с процессора и ставится в конец очереди на равных условиях с вновь поступающими задачами. Величина кванта определяется на основании компромисса между приемлемым временем ожидания пользователями реакции системы на свои запросы и накладными расходами, вызванными слишком частыми переключениями между задачами при слишком малых квантах времени. В некоторых системах квант является фиксированной величиной, в некоторых можно указывать минимальное и максимальное значение кванта. В этом случае квант получает сначала минимальное значение, а в случае прерывания задачи, выделенный задаче квант увеличивается на некоторый шаг до тех пор пока он не станет достаточным для завершения задачи или не получит максимальное значение.
Алгоритм с абсолютным приоритетом применяется в операционных системах реального времени и предусматривает возможность предоставления процессорного времени задаче с высшим приоритетом, а в случае равенства приоритетов процессор обрабатывает задачи в порядке очерёдности. В этом случае прервать выполнение задачи может только появление задачи с более высоким приоритетом. Эта идея при применении карусельной дисциплины реализуется назначением всем задач равных приоритетов и созданием одной пустой задачи с наивысшим приоритетом для осуществления переключения задач. Тогда все непустые задачи получат равное процессорное время, которое будет равномерно предоставлено всем задачам.
Карусельная дисциплина с учётом приоритетов реализуется за счёт создания нескольких очередей задач на выполнение. Процессорное время отдаётся задачам из очереди с самым высоким приоритетом. Если она пуста, то просматривается следующая очередь и т.д.
Операционные системы реального времени используют дисциплины с динамическими приоритетами, которые изменяются в зависимости от обстоятельств. Операционные системы реального времени применяются в системах управления технологическим оборудованием. В системах управления возможны ситуации прерывания задач с низким приоритетом вследствие недостатка вычислительных ресурсов. В ряде ситуаций потери от прерывания таких задач намного превышают потери от прерывания высокоприоритетных задач. В этих условиях целесообразно временно повышать приоритет указанных выше задач.
В некоторых операционных системах, в частности UNIX, уровни приоритетов задач рассчитываются достаточно часто и лежат в диапазоне 0 – 127, причём приоритеты в диапазоне 96 – 127 являются фиксированными, в диапазоне 66-95 – системными и в диапазоне 0 – 65 – приоритеты режима задач. Системные и задачные приоритеты являются динамическими.
В системах Windows NT/2000/XP диспетчер поддерживает 32 уровня приоритета, причём задачи делятся на два класса: задачи реального времени и переменного приоритета. Приоритеты задач реального времени находятся в диапазоне 16 –31, все остальные имеют динамически изменяемый приоритет в диапазоне 1 – 15. При прерывании задачи операционная система снижает приоритетна единицу, а при освобождении задачи из очереди ожидания.
В системе OS/2 имеется четыре класса приоритетов, меняющихся в пределах класса в диапазоне 0 – 31. Это обеспечивается наличием 128 очередей задач с разными приоритетами.
Классификация дисциплин обслуживания, показанная на рис. 2.1, основана на наличии или отсутствии приоритетов и способах их использования. Однако, имеется и другой признак классификации – наличие или отсутствие возможности отобрать процессор у выполняющейся задачи. Если этой возможности нет, то дисциплина обслуживания называется невытесняющей, в противном случае вытесняющей.
При разработке дисциплины диспетчеризации весьма актуальной является проблема гарантированного обслуживания[5]. Диспетчеризация на основе жёстких временных ограничений иногда приводит к более быстрому выполнению задач, которые реально в нём не нуждаются, за счёт других задач. Существует три способа обеспечения гарантированного обслуживания процесса:
выделение некоторой минимальной доли процессорного времени классу задач при наличии в классе хотя бы одного процесса, находящегося в состоянии готовности;
выделение некоторого минимального времени любому процессу, находящемуся в состоянии готовности;
выделение процессу такого количества процессорного времени, которое гарантирует завершение процесса к некоторому наперёд заданному сроку.
Применение описанных выше динамических приоритетов является одной из гарантий обслуживания процессов.
Для сравнения алгоритмов диспетчеризации применяется ряд критериев:
Загрузка центрального процессора (в среднем для персональных систем 2 – 3%, для серверов от 15 – 40% до 90 – 100%);
Пропускная способность центрального процессора, измеряется количеством процессов, выполняемым за единицу времени;
Время оборота – время, затраченное на выполнение процесса с момента его появления до момента исчезновения;
Время ожидания – время нахождения процесса в очереди готовых процессов;
Время отклика (для интерактивных программ) – время, прошедшее от момента попадания процесса во входную очередь до момента первого обращения к терминалу.
Основные причины снижения производительности системы:
большие накладные расходы на переключение процессора;
переключение на другую задачу в момент выполнения текущей задачей критической секции.
В мультипроцессорных системах повышение производительности достигается вследствие применения:
совместного планирования, при котором все неблокированные потоки одного приложения одновременно ставятся на выполнение процессорами и одновременно снимаются с выполнения;
блокирования прерывания задач, находящихся в критической секции и запрета постановки в очередь на выполнение активно ожидающих задач до освобождения входа в секцию;
планирование с учётом подсказок, в частности указаний процессов подлежащих снятию с процессора и указаний процессов, которые следует поставить на процессор.
3.3. Управление параллельными процессами
3.3.1. Понятие параллельных процессов
В современных мультипрограммных системах могут одновременно выполняться несколько последовательных вычислительных процессов, находящихся в активном состоянии. Такие процессы называются параллельными и могут выполняться как на независимых устройствах, так и разделять различные ресурсы и конкурировать за них между собой. Например, может существовать конкуренция за процессорное время. Параллельные процессы могут быть независимыми и взаимодействующими.
Независимыми процессами называются процессы, которые не имеют общих данных, располагающихся в оперативной и внешней памяти. Независимые процессы не оказывают влияния друг на друга посредством изменения данных. Однако они замедляют исполнение друг друга.
Взаимодействующие процессы имеют общие данные, расположенные как в оперативной памяти, так и во внешней памяти. Они могут также конкурировать за разделяемые ресурсы. Разделяемые ресурсы, которые в каждый конкретный момент времени могут находиться в распоряжении только одного процесса, называются критическими. Два процесса, конкурирующие за критический ресурс должны быть синхронизированы, т.е. согласованы во времени. Это означает, что их обращения к критическим ресурсам должны происходить в разные моменты времени, в противном случае появляются ошибки, которые трудно выявляются и устраняются. Дополнительные трудности в синхронизацию параллельных процессов вносит разная скорость их исполнения, причём процессы не имеют информации ни о содержании, ни о скорости выполнения друг друга.
Программный код, реализуемый каждым процессом можно разбить на две секции. Секция, которая содержит обращение к критическому ресурсу, называется критической, а секция, которая не содержит такого обращения, может быть названа обычной секцией. Следует иметь в виду, что секции в свою очередь могут являться процессами.
Обобщённая модель взаимодействующих процессов показана на рис. 3.2.
 Рис. 3.2. Обобщённая модель взаимодействующих процессов
Рис. 3.2. Обобщённая модель взаимодействующих процессов
| Коды процессов Р1 и Р2 имеют критические (CS1, CS2) и обычные (PR1, PR2) секции. Процессы Р1 и Р2 могут выполняться произвольное число раз, имеют общую область памяти Х и обращаются к критическому разделяемому ресурсу КР. |
Формально описать взаимодействие процессов можно описать следующим программным кодом на языке, подобном Паскалю и Алголу 60 (рис. 3.3).
| Begin ... | {начало программного кода} |
| Parbegin | {начало описания параллельных процессов} |
| S11; S12;... S1N | {список N операторов процесса № 1 } |
| AND | {разделитель описаний процессов } |
| S11; S12;... S1Q | {список Q операторов процесса № 2 } |
| Parend | {конец описания параллельных процессов} |
| End | {конец программного кода} |
Рис. 3.3. Код, описывающий параллельные взаимодействующие процессы
По способу взаимного влияния взаимодействующие процессы можно разделить на конкурирующие и сотрудничающие. Конкурирующие процессы могут в принципе выполняться поодиночке. Однако при параллельном выполнении они начинают конкурировать за разделяемый критический ресурс и оказывать влияние друг на друга. Сотрудничающие процессы совместно обрабатывают общие данные и содержат в явном виде операторы передачи данных из одного процесса в другой.
В [1] описано несколько примеров конкурирующих процессов, в частности два не синхронизированных процесса Р1 и Р2, имеющих общую переменную Х, размещённую в оперативной памяти. Процесс Р1 имеет собственную переменную R1, а процесс Р2 – собственную переменную R2. Разумеется, эти переменные размещаются в памяти по разным адресам. Процесс Р1 состоит из трёх операторов присваивания: R1:=X, R1:=R1+1 и X:=R1[6]. Процесс Р2 включает в себя тоже три оператора присваивания: R2:=X, R2:=R2+1 и X:=R2. Предположим, что к моменту начала выполнения процессов переменная Х имеет значение 10.
Пусть при выполнении процессов сложилась ситуация, в которой сначала выполнялся процесс Р1, а потом Р2. Тогда реализуется цепочка операторов, показанная в табл. 3.1. Ситуация, в которой после первого оператора процесса Р1 выполнится первый оператор процесса Р2 показана в табл. 3.2.
Таблица 3.1. Первый вариант взаимодействия конкурирующих процессов
| Таблица 3.2. Второй вариант взаимодействия конкурирующих процессов
|
Из табл. 3.1 и 3.2 видно, что значения общей переменной Х в первом и втором вариантах получены разные. Очевидно, что хотя бы один из результатов является ошибочным. Вполне возможно, что ошибочными могут оказаться и оба результата выполнения подобных конкурирующих процессов. Для конкурирующих процессов введено понятие " взаимное исключение ", означающее невозможность одновременного обращения двух и более процессов к критическому ресурсу.
Дата публикования: 2014-11-18; Прочитано: 345 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
