 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Модели баз данных
|
|
Дэйт рассматривает базу данных как "вместилище хранимой информации. Она, как правило, одновременно является и интегрированной, и общедоступной. Под "интегрированностью" имеется в виду то, что базу данных можно представить как объединение нескольких отдельных файлов данных, избыточность информации в которых частично или полностью исключена... Под "общедоступностью" имеется в виду то, что информация, содержащаяся в базе, может одновременно использоваться сразу несколькими пользователями" [7]. При централизованном управлении базой данных можно "устранять несоответствия, устанавливать стандарты, накладывать ограничения на доступ к информации и поддерживать целостность базы данных" [8].
Разработка эффективной базы данных является трудной задачей, так как к ней предъявляется много взаимно противоречивых требований. Проектировщик должен учитывать не только функциональные требования к приложению, но также быстродействие и размер базы данных. Базы данных, неэффективные по быстродействию, оказываются, как правило, бесполезными. Системы, для реализации которых надо забить компьютерами все здание и нанять толпу администраторов для ее поддержки, неэффективны с точки зрения стоимости.
Между разработкой базы данных и созданием объектно-ориентированного приложения существует много параллелей. Проектирование баз данных часто рассматривается как процесс итеративного развития, в ходе которого надо принимать решения, касающиеся как программной логики, так и аппаратных аспектов [9]. Вёрковски и Кул указывают на то, что "Объекты, описывающие базу данных в терминах, которыми оперируют пользователи и разработчики, называются логическими. Объекты, отображающие физическое расположение данных в системе, называются физическими" [10]. Разработчики баз данных в процессе проектирования, напоминающем объектно-ориентированное, постоянно перескакивают от рассмотрения логических объектов к обсуждению физических аспектов их реализации. Кроме того, описание элементов базы данных очень напоминает перечисление ключевых абстракций объектно-ориентированного приложения. Проектировщики баз данных часто используют для анализа так называемые диаграммы "сущность-связь" (entity-relationship diagrams). Диаграммы классов, как мы видели, могут быть организованы таким образом, что будут напрямую соответствовать диаграммам сущность-связь, но обладать при этом еще большей выразительностью.
Дэйт утверждает, что при проектировании любой базы данных нужно дать ответ на следующий вопрос: "Какие структуры данных и соответствующие им операторы должна поддерживать система?" [11]. Три различные модели баз данных, перечисленные ниже, дают три различных ответа на этот вопрос:
- иерархическая;
- сетевая;
- реляционная.
Недавно появился четвертый тип, а именно объектно-ориентированные базы данных (ООСУБД). ООСУБД соединяют традиционную технологию проектирования баз данных с объектной моделью. Применение такого подхода оказалось достаточно полезным в таких областях, как компьютерное проектирование (САЕ) и разработка программ с помощью компьютеров (CASE), где нам приходится манипулировать значительными объемами данных с разнообразным семантическим содержанием. Объектно-ориентированные базы данных могут дать для некоторых приложений значительный выигрыш в быстродействии по сравнению с традиционными реляционными базами данных. В частности, в случае наличия большого количества связей между таблицами, объектно-ориентированные базы данных могут работать значительно быстрее, чем реляционные. Более того, ООСУБД гарантируют согласованную "бесшовную" интеграцию данных и бизнес-правил. Чтобы достичь той же семантики, в реляционных базах используют сложную систему триггеров, которые формируются с помощью языков программирования третьего и четвертого поколений - модель, которую никак нельзя назвать ясной и понятной.
Однако по ряду причин многие компании считают, что использование реляционной базы данных в контексте объектно-ориентированной архитектуры менее рискованно. Технология реляционных баз данных значительно более зрелая, она реализована на широком спектре различных платформ и зачастую предлагает более полный набор средств защиты, контроля версий и поддержания целостности. Кроме того, компания, уже вложившая определенный капитал в кадры и в инструменты, поддерживающие реляционную модель, просто не может позволить себе изменить за одну ночь всю технологию работы.
Реляционная модель весьма популярна. Принимая во внимание ее большую распространенность, широкий набор программных продуктов, ее поддерживающих, а также тот факт, что она удовлетворяет функциональным требованиям к системе складского учета, мы выбрали именно ее. Таким образом, мы остановились на гибридном решении: построение объектно-ориентированной оболочки над традиционной реляционной базой и использование преимуществ обоих подходов. Рассмотрим вкратце некоторые основные принципы проектирования реляционных баз данных. Зная их, мы лучше поймем, как создать объектно-ориентированную оболочку.
Основными элементами реляционной базы данных являются "таблицы, в которых столбцы представляют собой предметы и их атрибуты, а строки описывают отдельные экземпляры предметов... Модель также подразумевает наличие операторов для генерации новых таблиц на базе старых: именно таким способом пользователи могут манипулировать данными и получать информацию из базы" [12].
Рассмотрим для примера базу данных склада с радиоэлектронными товарами, на котором хранятся резисторы, конденсаторы и микросхемы. Каждый тип продукции в соответствии с предыдущей диаграммой классов обладает уникальным идентификационным номером и описательным именем. Например:
Products
| productId | description |
| Resistor, 10 ае 1/4 watt | |
| Resistor, 10 ае 1/4 watt | |
| Capacitor, 100 pF | |
| 7400 1С quad NAND | |
| 74LS00 1С quad HAND |
Мы видим таблицу с двумя столбцами, каждый из которых представляет определенный атрибут. В данном случае порядок, в котором расположены строки (столбцы), не важен; количество строк не ограничено, но каждая из них должна быть уникальной. Первый столбец, productID, является первичным ключом, то есть он может быть использован для однозначной идентификации детали.
Товары поступают от поставщиков; информация о каждом из них должна содержать уникальный идентификатор поставщика, имя компании, ее адрес, и, возможно, телефонный номер. Таким образом, можно составить следующую таблицу:
Suppliers
| SupplierID | Company | Address | Telephone |
| Interstate Supply | 2222 Fannin, Amarillo, TX | 806-555-0036 | |
| Interstate Supply | 3320 Scott, Santa Clara, CA | 408-555-3600 | |
| Universal Products | 2171 Parfet Ct, Lakewood, CD | 303-555-2405 |
supplierID - первичный ключ в том смысле, что им можно однозначно идентифицировать поставщика. Отметим, что все строки в этой таблице уникальны, однако у двух из них имя поставщика одинаково.
Различные поставщики предлагают различные продукты по различным ценам, поэтому мы можем организовать также таблицу стоимости продуктов. Она содержит текущую цену для каждой комбинации товар/поставщик:
Prices
| productID | SupplierID | Price |
| $0.10 | ||
| $0.09 | ||
| $367.75 | ||
| $10.69 | ||
| $0.09 | ||
| $1.75 |
В этой таблице нет простого первичного ключа. Для однозначной идентификации строк мы должны использовать комбинацию ключей productID и supplierID. Ключ, образуемый из значений различных столбцов, называется составным. Заметьте, что мы не включили в эту таблицу названия деталей и поставщиков - это было бы излишним; данную информацию можно отыскать по значениям полей productID и supplierID в таблицах товаров и поставщиков. Поля productID и supplierID называются внешними ключами, так как они представляют первичные ключи других таблиц.
На рис. 10-5 представлена структура классов, соответствующая этим таблицам. Здесь, для обозначения записей, которые имеют смысл только в совокупности с записями из других таблиц, мы используем ассоциацию с атрибутом. Первичные ключи таблиц заключены в квадратные скобки.
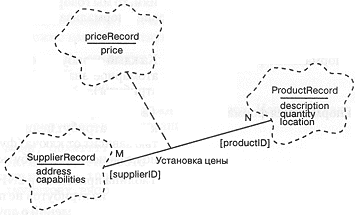
Рис. 10-5. Ассоциация с атрибутами.
Далее, мы можем проверить состояние склада с помощью таблицы, содержащей количество всех имеющихся в наличии продуктов:
Inventory
| ProductId | Quantity |
Эта таблица показывает, что объектно-ориентированное представление данных системы может отличаться от их представления в базе данных. В схеме, представленной на рис. 10-4, quantity является атрибутом класса ProductRecord, a здесь, в целях обеспечения быстродействия, мы решили разместить quantity в отдельной таблице. Дело в том, что, как правило, описание товара (description) модифицируется очень редко, в то время как количество (quantity) меняется постоянно по мере того, как со склада отгружаются товары и на склад прибывают новые грузы. Для оптимизации доступа к количеству товара разумнее выделить его в отдельную таблицу.
Данная деталь реализации системы, как следует из рис. 10-4, не будет видна клиентам нашего приложения. Класс ProductRecord создает иллюзию того, что quantity является его частью.
Самой очевидной и в то же время наиболее важной целью проектирования базы данных является построение такой схемы размещения данных, при которой каждый факт хранится в одном и только в одном месте. При этом не происходит дублирования информации, упрощается процесс внесения изменений в базу данных и поддержания ее целостности (согласованности и правильности данных). Достигнуть цели не всегда бывает легко (оказывается, что это и не всегда нужно). Тем не менее, в нашем случае данное свойство будет очень желательным.
Для достижения этой цели (важной, но не единственной [13]) была разработана специальная теория нормализации. Нормализация есть свойство таблицы; если таблица удовлетворяет определенным условиям, то мы говорим что она имеет нормальную форму. Существует несколько уровней нормализации, каждый из которых базируется на предыдущем [14]:
| • Первая нормальная форма (1NF) | Каждый атрибут представляет собой атомарное значение (неразложимые атрибуты). |
| • Вторая нормальная форма (2NF) | Таблица приведена в 1NF, и при этом каждый атрибут целиком и полностью зависит от ключа (функционально независимые атрибуты). |
| • Третья нормальная форма (3NF) | Таблица приведена в 2NF, и при этом ни один из атрибутов не предоставляет никаких сведений о другом атрибуте (взаимно независимые атрибуты). |
Таблица в третьей нормальной форме "содержит свойства ключа, весь ключ и ничего кроме ключа" [15].
Все рассмотренные таблицы находятся в 3NF. Существуют еще более высокие уровни нормализации, в основном связанные с многозначными фактами, но в данном случае они не имеют для нас большого значения.
Для того, чтобы связать воедино объектно-ориентированную схему и реляционную модель, иногда нам приходится сознательно нарушать нормализацию таблиц, внося в них определенную избыточность. При этом нам придется прилагать специальные усилия для поддержания синхронизации избыточных данных, однако взамен мы получаем возможность более быстрого доступа к данным, что для нас важнее.
SQL
При работе с объектно-ориентированной моделью, где данные и формы поведения соединены воедино, пользователю может понадобиться осуществить ряд транзакций с таблицами. Он, например, может захотеть добавить в базу нового поставщика, исключить из нее некоторые товары или изменить количество имеющегося в наличии товара. Может также появиться необходимость сделать различные выборки из базы данных, например, просмотреть список всех продуктов от определенного поставщика или получить список товаров, количество которых на складе недостаточно или избыточно с точки зрения заданного нами критерия. Может, наконец, понадобиться создать исчерпывающий отчет, в котором оценивается стоимость пополнения запасов до определенного уровня, используя наименее дорогих поставщиков. Подобные типы транзакций присутствуют почти в каждом приложении, использующем реляционную базу данных. Для взаимодействия с реляционными СУБД разработан стандартный язык - SQL (Structured Query Language, язык структурированных запросов). SQL может использоваться и в интерактивном режиме, и для программирования.
Самой важной конструкцией языка SQL является предложение SELECT следующего вида:
SELECT <attribute> FROM <relation> WHERE <condition>
Для того чтобы, например, получить коды продуктов, чей запас на складе меньше 100 единиц, можно написать следующее:
SELECT PRODUCTID, QUANTITY FROM INVENTORY WHERE QUANTITY < 100
Возможно создание и более сложных выборок. Например такой, где вместо кода товара фигурирует его наименование:
SELECT NAME, QUANTITY
FROM INVENTORY, PRODUCTS
WHERE QUANTITY < 100 AND INVENTORY.PRODUCTID = PRODUCTS.PRODUCTID
В этом предложении присутствует связь, позволяющая как бы объединять несколько отношений в одно. Данное предложение SELECT не создает новой таблицы, но оно возвращает набор строк. Одна выборка может содержать сколь угодно большое число строк, поэтому мы должны иметь средства для доступа к информации в каждой из них. Для этого в языке SQL введено понятие курсора, смысл которого схож с итерацией, о которой мы говорили в главе 3. Можно, например, определить курсор следующим образом:
DECLARE С CURSOR
FOR SELECT NAME, QUANTITY
FROM INVENTORY, PRODUCTS
WHERE QUANTITY < 100 AND INVENTORY.PRODUCTID = PRODUCTS.PRODUCTID
Чтобы открыть эту выборку, мы пишем
OPEN C
Для прочтения записей выборки используется оператор FETCH:
FETCH C INTO NAME, AMOUNT
И, наконец, после того, как работа завершена, мы закрываем курсор;
CLOSE C
Вместо использования курсора можно пойти другим путем: создать виртуальную таблицу, где содержатся результаты выборки. Такая виртуальная таблица называется представлением. С ним можно работать как с настоящей таблицей. Создадим, например, представление, содержащее наименование товара, имя поставщика и стоимость:
CREATE VIEW V (NAME, COMPANY, COST) AS
SELECT PRODUCTS.NAME, SUPPLIERS.COMPANY, PRICES.PRICE
FROM PRODUCTS, SUPPLIERS, PRICES
WHERE PRODUCTS.PRODUCTID = PRICES.PRODUCTID AND SUPPLIERS.SUPPLIERID = PRICES.SUPPLIERID
Использование представлений предпочтительнее, так как оно позволяет создавать различные представления для различных клиентов системы. Поскольку представления могут существенно отличаться от низкоуровневых связей в базе данных, гарантируется некоторая степень независимости данных. Права доступа пользователей к информации можно определять на основе виртуальных, а не реальных таблиц, позволяя таким образом записывать безопасные транзакции. Представления несколько отличаются от таблиц, хотя бы тем, что связи в представлениях не могут быть обновлены напрямую.
В нашей системе SQL-запросы будут играть роль абстракций низкого уровня. Пользователи вряд ли будут разбираться в SQL, ведь этот язык не является частью предметной области. Мы будем использовать SQL при реализации программы. Составлять свои SQL-предложения смогут только достаточно искушенные в программировании разработчики инструментальных средств нашей системы. От простых смертных, работающих с системой каждый день, язык запросов будет скрыт.
Рассмотрим следующую задачу: получив заказ, мы хотим определить имя сделавшей его компании. С точки зрения программиста SQL, это нетрудная задача. Однако, в нашем случае, когда основное программирование выполняется на C++, мы предпочли бы использовать следующее выражение:
currentOrder.customer().name()
С точки зрения объектно-ориентированного подхода это выражение вызывает селектор customer, возвращающий ссылку на клиента, а затем - селектор name, возвращающий имя клиента. На самом деле данное выражение вычисляется следующим запросом:
SELECT NAME
FROM ORDERS, CUSTOMERS
WHERE ORDERS.CUSTOMERID = CURRENTORDER.CUSTOMERID
AND ORDERS.CUSTOMERID = CUSTOMERS.CUSTOMERID
Спрятав от клиента детали реализации данного вызова, мы скрыли от него все неприятные особенности работы с SQL.
Отображение объектно-ориентированного представления мира в реляционное концептуально ясно, но обычно требует довольно утомительной проработки деталей [Большая часть преимуществ объектно-ориентированных баз данных заключается как раз в том, что в них эти утомительные детали скрыты от разработчика. Отображение классов в таблицы достаточно легко алгоритмизуемо, поэтому существует альтернатива ООСУБД: инструментальные средства, которые автоматически преобразуют определения классов C++ в реляционную схему и SQL-код. Тогда, например, если приложение запрашивает атрибут данного объекта, сгенерированный код создает необходимые SQL-предложения для стандартной реляционной базы данных, получает требуемые данные и доставляет их клиенту в форме, согласованной с интерфейсом C++]. По замечанию Румбаха, "Соединение объектной модели с реляционной базой данных - в целом довольно простая задача, за исключением вопросов, связанных с обобщением" [16]. Румбах предлагает также некоторые правила, которые следует учитывать при отображении классов и ассоциаций (включая агрегацию) на таблицы:
- Каждый класс отображается в одну или несколько таблиц.
- Каждое отношение "многие ко многим" отображается в отдельную таблицу.
- Каждое отношение "один ко многим" отображается в отдельную таблицу или соотносится с внешним ключом [17].
Далее он предлагает три альтернативных варианта отображения иерархии наследования в таблицы:
- Суперкласс и каждый его подкласс отображаются в таблицу.
- Атрибуты суперкласса реплицируются в каждой таблице (и каждый подкласс отображается в отдельную таблицу).
- Атрибуты всех подклассов переносятся на уровень суперкласса (таким образом мы имеем одну таблицу для всей иерархии наследования) [18].
Нет ничего удивительного в том, что существуют определенные ограничения по использованию SQL в низкоуровневой реализации [Недавно был предложен новый стандарт - SQL3, который содержит объектно-ориентированные расширения. Они существенно уменьшают семантические различия между объектно-ориентированным и реляционным взглядом на мир и устраняют многие другие ограничения SQL]. В частности, этот язык поддерживает ограниченный набор типов данных, а именно, символы, строки фиксированной длины, целые числа и вещественные числа с фиксированной и плавающей точкой. Отдельные реализации иногда умеют работать и с другими типами данных; однако представление информации в виде графических элементов или строк произвольной длины напрямую не поддерживается.
Дата публикования: 2014-11-04; Прочитано: 283 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
