 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Правила формирования отношений
|
|
Правила формирования отношений основывается на учете следующего:
- степени связи между сущностями (1:1, 1:М, М:1, М:М);
- класса принадлежности экземпляров сущностей (обязательный и необязательный).
Рассмотрим формулировки шести правил формирования отношений на основе диаграмм ER √ типа.
Формирование отношения для связи 1:1
Правило 1. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей обязательный, то формируется одно отношение. Первичным ключом этого отношения может быть ключ любой из двух сущностей.
Правило 2. Если степень связи 1:1 и класс принадлежности одной сущности обязательный, а второй необязательный, то под каждую из сущностей формируется по отношению с первичными ключами, являющимися ключами соответствующих сущностей. Далее к отношению, сущность которого имеет обязательный КП, добавляется в качестве атрибута ключ сущности с необязательным КП.
Правило 3. Если степень связи 1:1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать три отношения. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя, поэтому его ключ объединяет ключевые атрибуты связываемых отношений.
Формирование отношений для связи 1:М
Если две сущности С1 и С2 связаны как 1:М, сущность С1 будем называть односвязной (1-связной), а сущность С2 многосвязной (м-связной). Определяющим фактором при формировании отношений, связанных этим видом связи, является класс принадлежности м-связной сущности. Так, если класс принадлежности м-связной сущности обязательный, то в результате применения правила получим два отношения, если необязательный - три отношения. Класс принадлежности односвязной сущности не влияет на результат.
Правило 4. Если степень связи между сущностями 1:М (или М:1) и класс принадлежности м-связной сущности обязательный, то достаточно формирование двух отношений (по одному на каждую из сущностей). При этом первичными ключами этих отношений являются ключи их сущностей. Кроме того, ключ 1-связной сущности добавляется как атрибут (внешний ключ) в отношение, соответствующее м-связной сущности.
Правило 5. Если степень связи 1:М (М:1) и класс принадлежности м-связной сущности является необязательным, то необходимо формирование трех отношений. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя (его ключ объединяет ключевые атрибуты связываемых отношений).
Формирование отношений для связи М:М
При наличии связи М:М между двумя сущностями необходимо три отношения независимо от класса принадлежности любой из сущностей. Использование одного или двух отношений в этом случае не избавляет от пустых полей или избыточно дублируемых данных.
Правило 6. Если степень связи М:М, то независимо от класса принадлежности сущностей формируются три отношения. Два отношения соответствуют связываемым сущностям и их ключи являются первичными ключами этих отношений. Третье отношение является связным между первыми двумя, а его ключ объединяет ключевые атрибуты связываемых отношений.
17Реляционная БД: ключи, целостность БД. избыточное дублирование, аномалии изменений, поддержка ссылочной целостности.
Основное назначение баз данных состоит в том, чтобы хранить и предоставлять информацию о реальном мире. Для представления этой информации в базе данных используются привычные для программистов типы данных - строковые, численные, логические и т.п. Однако в реальном мире часто встречается ситуация, когда данные неизвестны или не полны. Например, место жительства или дата рождения человека могут быть неизвестны (база данных разыскиваемых преступников). Если вместо неизвестного адреса уместно было бы вводить пустую строку, то что вводить вместо неизвестной даты? Ответ - пустую дату - не вполне удовлетворителен, т.к. простейший запрос "выдать список людей в порядке возрастания дат рождения" даст заведомо неправильных ответ.
Для того чтобы обойти проблему неполных или неизвестных данных, в базах данных могут использоваться типы данных, пополненные так называемым null-значением. Null-значение - это, собственно, не значение, а некий маркер, показывающий, что значение неизвестно.
По определению, тело отношения есть множество кортежей, поэтому отношения не могут содержать одинаковые кортежи. Это значит, что каждый кортеж должен обладать свойством уникальности. На самом деле, свойством уникальности в пределах отношения могут обладать отдельные атрибуты кортежей или группы атрибутов. Такие уникальные атрибуты удобно использовать для идентификации кортежей.
Определение 1. Пусть дано отношение 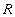 . Подмножество атрибутов
. Подмножество атрибутов 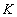 отношения будем называть потенциальным ключом, если обладает следующими свойствами:
отношения будем называть потенциальным ключом, если обладает следующими свойствами:
1. Свойством уникальности - в отношении не может быть двух различных кортежей, с одинаковым значением .
2. Свойством неизбыточности - никакое подмножество в не обладает свойством уникальности.
Любое отношение имеет по крайней мере один потенциальный ключ. Действительно, если никакой атрибут или группа атрибутов не являются потенциальным ключом, то, в силу уникальности кортежей, все атрибуты вместе образуют потенциальный ключ. Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным. Отношение может иметь несколько потенциальных ключей. Традиционно, один из потенциальных ключей объявляется первичным, а остальные - альтернативными. Различия между первичным и альтернативными ключами могут быть важны в конкретной реализации реляционной СУБД, но с точки зрения реляционной модели данных, нет оснований выделять таким образом один из потенциальных ключей.
Т.к. потенциальные ключи фактически служат идентификаторами объектов предметной области (т.е. предназначены для различения объектов), то значения этих идентификаторов не могут содержать неизвестные значения. Действительно, если бы идентификаторы могли содержать null-значения, то мы не могли бы дать ответ "да" или "нет" на вопрос, совпадают или нет два идентификатора. Это определяет следующее правило целостности сущностей: атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Различают следующие виды аномалий:
· Аномалии вставки (INSERT)
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно
· Аномалии обновления (UPDATE)
Причина аномалии - избыточность данных, также порожденная тем, что в одном отношении хранится разнородная информация.
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
· Аномалии удаления (DELETE)
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Ссылочная целостность может нарушиться в результате операций, изменяющих состояние базы данных. Таких операций три - вставка, обновление и удаление кортежей в отношениях. Т.к. в определении ссылочной целостности участвуют два отношения - родительское и дочернее, а в каждом из них возможны три операции - вставка, обновление, удаление, то нужно рассмотреть шесть различных вариантов.
Для родительского отношения:
· Вставка кортежа в родительском отношении. При вставке кортежа в родительское отношение возникает новое значение потенциального ключа.
· Обновление кортежа в родительском отношении. При обновлении кортежа в родительском отношении может измениться значение потенциального ключа
· Удаление кортежа в родительском отношении. При удалении кортежа в родительском отношении удаляется значение потенциального ключа.
Для дочернего отношения:
· Вставка кортежа в дочернее отношение. Нельзя вставить кортеж в дочернее отношение, если вставляемое значение внешнего ключа некорректно
· Обновление кортежа в дочернем отношении. При обновлении кортежа в дочернем отношении можно попытаться некорректно изменить значение внешнего ключа
· Удаление кортежа в дочернем отношении. При удалении кортежа в дочернем отношении ссылочная целостность не нарушается.
Стратегии поддержания ссылочной целостности:
Существуют две основные стратегии поддержания ссылочной целостности:
· RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности.
· CASCADE (КАСКАДИРОВАТЬ) - разрешить выполнение требуемой операции, но внести при этом необходимые поправки в других отношениях так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи.
· SET NULL (УСТАНОВИТЬ В NULL) - все некорректные значения внешних ключей изменять на null-значения.
· SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - все некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию.
В реальных СУБД можно также отказаться от использования какой-либо стратегии поддержания ссылочной целостности:
· IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
19Элементы и сравнение архитектур «файл-сервер» и «клиент/сервер».
Архитектура клиент-сервер - архитектура распределенной вычислительной системы, в которой приложение делится на клиентский и серверный процессы
Архитектура файл-сервер основана на использовании так называемого файлового сервера(file server) — относительно мощной ЭВМ, управляющей созданием, поддержкой и использованием общих информационных ресурсов локальной сети, включая доступ к ее базам данных (БД) и отдельным файлам, а также их защиту.
При работе с файл-серверной версией вся ответственность за сохранность и целостность базы данных лежит на программе и сетевой операционной системе. Обработка всех данных происходит на рабочих местах, а сервер используется только как разделяемый накопитель. Каждый пользователь непосредственно использует информацию и вносит изменения в файлы данных и в индексные файлы. При больших объемах данных и работе во многопользовательском режиме существенно снижается быстродействие - ведь чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных. Например, в момент записи в файл может возникнуть сбой сети или авария питания. В этом случае компьютер пользователя прерывает работу, база данных может оказаться поврежденной, а индексный файл - разрушенным. Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов.
Клиент-серверная версия позволяет обойти эти проблемы, так как вся работа с базой данных происходит на сервере, не проходит по проводам и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером. В файл изменения вносятся только после того, как сервер получит сообщение о том, что корректировка файла завершена. Это исключает повреждение индексных файлов и существенно повышает быстродействие системы.
Кроме высокого быстродействия и надежности, архитектура "клиент-сервер" дает много преимуществ и в части технического обеспечения. Во-первых, сервер оптимизирует выполнение функций обработки данных, что избавляет от необходимости оптимизации рабочих станций. Рабочая станция может быть укомплектована не очень быстрым процессором, и тем не менее сервер позволит быстро получить результаты обработки запроса. Во-вторых, поскольку рабочие станции не обрабатывают все промежуточные данные, существенно снижается нагрузка на сеть. Предоставится возможность ведения журнала операций, в котором автоматически регистрируются все прошедшие транзакции что, в свою очередь, поможет быстрому восстановлению системы при аппаратных сбоях.
Тем не менее, в своем классическом варианте клиент-сервер не лишен ряда недостатков.
· 1 Очень высокая сложность администрирования и настройки рабочих мест пользователей системы.
· 2 Сложность интеграции с унаследованными системами.
· 3 Достаточно высокая сложность разработки системы из-за необходимости исполнять бизнес-логику и обеспечивать интерфейс с пользователем в одной программе.
20 Язык запросов SQL: запросы вставки, изменения, удаления данных. Работа с агрегатными функциями, группировка.
Рост количества данных, необходимость их хранить и обрабатывать привели к тому, что возникла потребность в создании стандартного языка запросов к базам данных, который мог бы функционировать в большом количестве различных видов компьютерных систем. Действительно, такой стандартный язык позволяет пользователям манипулировать данными независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ.
SQL (Structured Query Language) - это сокращенное название структурированного языка запросов, предоставляющего средства создания и обработки данных в реляционных базах. Независимость от специфики компьютерных технологий, а также поддержка SQL лидерами промышленности в области технологии реляционных баз данных сделали его основным стандартным языком запросов.
Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволила создать компактный язык с небольшим набором предложений. SQL может использоваться как для выполнения запросов, так и для построения прикладных программ.
В нем существуют:
• предложения определения данных - определение базы данных а также определение и уничтожение таблиц и индексов;
• запросы на выбор данных - предложение SELECT;
• предложения модификации данных - добавление, удаление и изменение данных;
• предложения управления данными - предоставление и отмена привилегий на доступ к данным, управление транзакциями и другие.
SQL предоставляет возможность выполнять
• арифметические вычисления, включая разнообразные функциональные преобразования, обработку текстовых строк и выполнение операций сравнения значений арифметических выражений и текстов;
• упорядочение строк или столбцов при выводе содержимого таблиц на печать или экран дисплея;
• создание представлений, позволяющих пользователям интерпретировать данные без увеличения их объема в БД;
• сохранение выводимого по запросу содержимого таблицы, нескольких таблиц или представления в другой таблице;
• группирование данных и применение к этим группам таких операций, как среднее, сумма, максимум, минимум, число элементов и т.п.
Реляционная база данных - это связанная информация, сохраняемая в двумерных таблицах со строками и столбцами. Строки обычно называются записями, столбцы полями.
В настоящей разработке будут рассмотрены вопросы, связанные с командами языка SQL, позволяющими производить выборку информации из базы данных, изменение информации в таблицах базы данных, но не в их структуре. Эта группа команд языка SQL называется DML - Data Manipulation Language (язык обработки данных).
Дата публикования: 2015-10-09; Прочитано: 2036 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
