 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Недостатки сетевой модели данных
|
|
· Высокая сложность и жесткость схемы БД, построенной на ее основе;
· Сложность в понимании и обработки информации в БД обычному пользователю.
5. Основные понятия реляционных моделей данных
Ответ:
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени.


Отношение - является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные.Термин отношение происходит от англ. relation (отношение).
Сущность - есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении.
Атрибуты -представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы.
Домен - представляет собой множество всех возможных значений определенного атрибута отношения.
Схема отношения (заголовок отношения) - представляет собой список имен атрибутов. Пример схемы отношения Сотрудники(ИД_Код, ФИО, Отдел, Должность).
Первичный ключ (ключ отношения или ключевой атрибут) - называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Ключ может состоять из нескольких атрибутов, тогда такой ключ называется сложным составным.
Ключи обычно используются для достижения следующих целей:
· Исключения дублирования значений в ключевых атрибутах;
· Упорядочивания кортежей;
· Ускорения работы с кортежами отношения;
· Организации связывания таблиц базы данных.
Внешний ключ: п усть в отношении сотрудник имеется неключевой атрибут Отдел, значения которого являются значениями ключевого атрибута отношения Отделы, тогда говорят, что атрибут Отдел отношения Сотрудники является внешним ключом отношения Отделы.
Пример внешнего ключа:
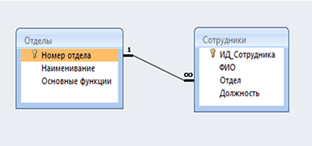
Свойства отношения:
· В таблице нет двух одинаковых строк;
· Все кортежи в одном отношении должны иметь одну структуру, соответствующую именам и типам атрибутов;
· Каждый атрибут в отношении имеет уникальное имя;
· Порядок следования кортежей в отношении произволен.
Основной единицей обработки данных в реляционной базе денных является отношение, а не отдельные его кортежи.
6. Сортировка, поиск и замена данных в таблицах
Ответ:
Сортировка данных в таблицах позволяет упорядочить информацию по какому-либо критерию.
Общий порядок сортировки для БД определяет в разделе Основные диалогового окна Параметры Access. Измененный порядок сортировки будет действовать для всех вновь создаваемых БД. Менять универсальный режим сортировки не рекомендуется.
Сортировка данных:
В MS Access существует два вида сортировки:
· По возрастанию;
· По убыванию.
Обычный порядок сортировки текстовых полей по возрастанию означает упорядочивание полей сверху вниз от начинающихся на букву «А» до начинающихся на букву «Я».
Если атрибуты начинаются с одной и той же буквы, сортировка производится по второй букве и т.д.
Правила сортировки:
· При сортировке по возрастанию значения атрибутов, содержащие значения Null ставятся в начало списка;
· Числа, находящиеся в текстовых полях сортируются как строки символов, а не как числовые значения;
· Если в значениях встречаются и русские и английские символы, при сортировки по возрастанию в начало списка будут английские значения от «А» до «Z», а затем русские от «А» до «Я»;
· Сортировка не применима катрибута таблицы с типами данных OLE, вложения, а поля с типами данных гиперссылка и МЕМО можно отсортировать с помощью расширенного фильтра;
· При сохранении таблицы сохраняется и порядок ее сортировки.
Сортировка таблиц:
Существует два метода сортировки:
· Простая сортировка – в этом случае записи сортируются либо по возрастанию, либо по убыванию (но не в том и другом порядке одновременно);
· Сложная сортировка - когда одни поля упорядочены по возрастанию, а другие по убыванию.
Сложная сортировка доступна в окне расширенного фильтра, в режимах конструкторов запросов, отчетов и др., т. е. там, где для отдельного поля можно установить свой режим сортировки.
Средства поиска и замены:
С помощью диалогового окна Поиск и Замена можно найти конкретные записи или определенные значения в полях, а также произвести их замену на новые.
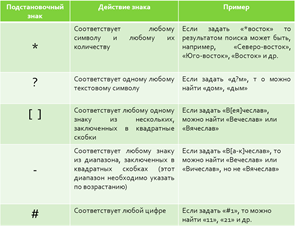
Маска ввода, поиск и замена:
Если в таблицу, уже содержащие данные, была добавлена маска ввода, могут возникнуть сложности при поиске и замене данных, но не удовлетворяющих маске ввода. Чтобы этого не происходило, необходимо сначала удалить маску ввода, произвести поиск или замену, а затем заново добавить маску ввода
Фильтр используется как инструмент работы с данными, их просмотра, проверки и редактирования.
Фильтр – фактически набор условий для отбора подмножества данных (или для сортировки данных).
Фильтры могут применяться не только в таблицах, но и в формах, запросах и отчетах
Виды фильтров:
· Простой фильтр (фильтр по значению поля);
· Фильтр по выделенному;
· Обычный фильтр (фильтр по форме) - может содержать сразу несколько условий по нескольким полям таблицы.Чтобы их задать пользователю предлагается заполнить ячейки в специальном окне – форме фильтра, поэтому этот тип фильтра еще называют «фильтр по форме».
· Расширенный фильтр - имеет окно, очень похожее на окно запроса и открывается на собственной вкладке в рабочей области программы.Команда Масштаб контекстного меню ячейки условий открывает окно Область ввода, которое имеет больше места для задания условий, а также позволяет настроить шрифт.Расширенный фильтр, единственный, который можно сохранить как запрос.
Фильтр по выделенному:

7. Индексирование данных в реляционных таблицах
Ответ:
Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и некоторое отличие.
Под индексом понимают средство ускорения операции поиска записей в таблице, а следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной.
Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, например Paradox, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов.
Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
• вида содержимого в поле ключа записей индексного файла;
• типа используемых ссылок (указателей) на запись основной таблицы;
• метода поиска нужных записей.
В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (так называемыйхеш-код). Преимущество хранения хеш-кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поиско-вых операций. Недостатком хеширования является необходимость выполнения операции свертки (требует определенного времени), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковыйхеш-код).
Для организации ссылки на запись таблицы могут использоваться три типа адресов: абсолютный (действительный), относительный и символический (идентификатор).
На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД как правило индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называются файлами первичных индексов.
Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов.
В системах управления реляционными БД индексация является механизмом повышения их производительности за счет ускорения сортировки и поиска записей.
Поля первичного ключа индексируются по умолчанию.
Поля с типами данных OLE и Вложения индексировать нельзя.
Индексирование полей целесообразно использовать если:
· Они имеют тип данных Текстовый, Числовой, Денежный или Дата/Время;
· По ним часто выполняется сортировка;
· Они используются для поиска значений;
· Они часто используются в операциях объединения.
Индекс нецелесообразно использовать, если:
· Поля редко используются в запросах;
· Поля часто используются в запросах на изменение;
· Поля имеют только несколько возможных значений (или много повторяющихся значений), например, пол человека;
· Поля небольших таблиц с несколькими записями.
В SQL Server поддерживает два типа индексов – кластерные и некластерные.
Кластерный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листов) содержатся страницы актуальных данных таблицы, а физически информация хранится в логическом порядке данного индекса.
В случае некластерных индексов странницы листового уровня содержат не актуальные данные таблицы (как в случае кластерного индекса), а указатель на строку данных, включающий номер страницы данных и порядковый номер записи на странице. Некластерный индекс не требует физического переупорядочения данных таблицы. Создание некластерного индекса не требует наличия в базе данных большого свободного дискового пространства, которое необходимо при создании кластерных индексов.
Для одной таблицы может быть создано не более одного кластерного индекса и до 249 некластерных индексов.
Индексы не могут быть созданы для столбцов со следующими типами данных BIT, TEXT и IMAGE. Индексы не могут также создаваться для видов.
Для создания индексов используется команда CREATEINDEX. Общий синтаксис которой показан ниже:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]
INDEX index_name
ON table (column [,...n])
[WITH [PAD_INDEX][[,] FILLFACTOR = fillfactor][[,]
IGNORE_DUP_KEY][[,] DROP_EXISTING][[,]
STATISTICS_NORECOMPUTE]][ON filegroup],
гдеindex_name – имясоздаваемогоиндекса;
table – имя таблицы, в которой создается;
column – имя столбца таблицы;
PAD_INDEX – этот параметр определяет размер пространства, оставляемого открытым на каждой внутренней странице;
IGNORE_DUP_KEY – этот параметр не отменяет установленного требования уникальности ключей, но позволяет продолжить работу даже при попытке поместить в таблицу строку с дублирующимся значением уникального ключевого поля;
DROP_EXISTING – этот параметр используется только при создании кластерных индексов и определяет обработку существующих некластерных индексов таблицы;
STATISTICS_NORECOMPUTE – этот параметр блокирует автоматическое обновление статистических сведений по индексам, что потребует выполнения команды UPDATE STATISTICS вручную.
Пример создания простого индекса:
USEbiblio
GO
CREATE INDEX numbil_id_ind
ON Tbl_Chiteteli (NumBillet)
GO
Пример создания уникального кластерного индекса
USEbiblio
GO
CREATE UNIQUE CLUSTERED INDEX TelephonID_ind
ON Tbl_Chiteteli (Telephon)
GO
Просмотриндексовбазыданных
Для получения подробных сведений о связанных с таблицами индексах можно воспользоваться командами sp_helpindex и sp_statistics.
Переименование индексов базы данных
Для переименования индекса используется системная хранимая процедура sp_rename. Команда вызова которой имеет приведенный ниже синтаксис:
Sp_renameindex_old, index_new [, COLUMN | INDEX]
Удаление индексов базы данных
Для удаления индекса используется команда, формат которой показан ниже:
DROP INDEX [owner] table_name.index_name
[, [owner,] table_name.index_name]
где owner – владелец базы данных;
index_name – имя индекса;
table_name – имя таблицы, в которой удаляется индекс.
8. Концептуальная модель данных, основные понятия и определения
Ответ:
Главными элементами концептуальной модели данных являются объекты и отношения.
Объекты обычно представляют в виде существительных, а отношения в виде глаголов.
Объекты – вещи, которые пользователи считают важными в моделируемой предметной области: люди, автомобили, деревья, дома, книги и т.д.
Концептуальными объектами являются компании, навыки, организации, проекты товаров, деловые операции, штатное расписание и т. д.
Объектное множество (ОМ) – множество вещей одного типа (все люди, все автомобили, все банки);
Объект-элемент – конкретный элемент объектного множества.
Объектные множества могут быть лексическими и абстрактными.
Элементы лексических объектных множеств можно написать, абстрактных же – нет!!!
Например: (ИМЯ, ДАТА, КОЛИЧЕСТВО, – лексические ОМ, ЧЕЛОВЕК – абстрактное ОМ).
Элементы лексических множеств обычно представляют в виде строк символов; элементы абстрактных множеств представляют внутренними номерами, не имеющими смысла вне компьютерной системы (идентификаторами или суррогатными ключами).
Внутри одних объектных множеств могут содержаться другие ОМ.
Например ОМ МУЖЧИНА содержится внутри ОМ ЧЕЛОВЕК.
Конкретизация – это ОМ, являющееся подмножеством другого множества.
Если ОМ является конкретизацией другого ОМ, он наследует все атрибуты и отношения обобщённого объекта.
Пример конкретизации:

Обобщение – это объектное множество, являющееся надмножеством другого объектного множества (содержащее его).
Пример обобщения:

Отношение – это связь между элементами двух объектных множеств.
Рассмотрим пример: для служащих компании можно выделить два ОМ ИНСПЕКТОР и РАБОЧИЙ, причём инспекторы контролируют рабочих.
Отношение Контролирует связывает каждого инспектора с рабочими, которых он контролирует.
Пример отношения Контролирует:

Мощность отношения – максимальное количество элементов одного объектного множества, связанных с одним элементом другого объектного множества.

Типы отношений объектных множеств:
· Функциональным называется отношение, максимальная мощность которого как минимум в одном направлении равна 1.Отношение один-к-одному означает, что максимальная мощность равна 1 в обоих направлениях (1:1). Например, у АВТОМОБИЛЯ один ВОДИТЕЛЬ, у ВОДИТЕЛЯ один АВТОМОБИЛЬ.
· Отношение один-ко-многим означает, что максимальная мощность равна 1 в одном направлении и многим в обратном (1:М). Например СЛУЖАЩИЙ работает в одном ОТДЕЛЕ, но в ОТДЕЛЕ работает много СЛУЖАЩИХ.
· Отношение многие-ко-многим означает, что максимальная мощность в обоих направлениях равна многим (М:М). Например: СТУДЕНТ посещает много КУРСОВ, каждый КУРС слушает много СТУДЕНТОВ.
Если в отношении участвуют два объектных множества, они называются бинарными.Отношения высокого порядка называют n-арными. 3-арное отношение называется терарным (трёхсторонним).
Концептуальное объектное множество – объектное множество, элементами которого являются абстрактные понятия.
9. Язык SQL, стандарты, основные операторы SQLзапроса
Ответ:
SQL («язык структурированных запросов») — формальный непроцедурный язык программирования, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных, управляемой соответствующей системой управления базами данных (СУБД). SQL основывается на исчислении кортежей.
Экспериментальная версия языка называлась SEQUEL (StructuredEnglishQUEryLanguage) структурированный английский язык запросов.
Официальная версия была названа короче – SQL (StructuredQueryLanguage).
Следует отметить, что к достоинствам языка SQL относится наличие международных стандартов. Первый международный стандарт был принят в 1989 г., и соответствующая версия языка называется SQL-89. Этот стандарт полностью поддерживается практически во всех современных коммерческих реляционных СУБД (например, в Informix, Sybase, Ingres, DB2 и т.д.). Стандарт SQL-89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации.
Возможно, наиболее важными достижениями стандарта SQL-89 являются четкая стандартизация синтаксиса и семантики операторов выборки и манипулирования данными и фиксация средств ограничения целостности БД, включающих возможности определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, позволяющих сформулировать условие для каждой отдельной строки таблицы. Средства определения внешних ключей позволяют легко формулировать требования так называемой целостности БД по ссылкам. Формулировка ограничений целостности на основе понятия внешнего ключа проста и понятна.
Осознавая неполноту стандарта SQL-89, на фоне завершения разработки этого стандарта специалисты различных фирм начали работу над стандартом SQL2. Эта работа также длилась несколько лет, было выпущено 4нескольк 0о проектов стандарта, пока, наконец, в марте 1992 г. не был выработан окончательный проект стандарта (после чего стандарт и соответствующий язык стали называть SQL-92). Этот стандарт существенно более полный и охватывает практически все необходимые для реализации аспекты: манипулирование схемой БД, управление транзакциями и сессиями (сессия - это последовательность транзакций, в пределах которой сохраняются временные отношения), подключение к БД, динамический SQL. Наконец стандартизованы отношения-каталоги БД, что вообще-то не связано с языком непосредственно, но очень сильно влияет на реализацию. Заметим, что в стандарте представлены три уровня языка - базовый, промежуточный и полный. В течение нескольких лет после принятия стандарта производители СУБД, утверждавшие совместимость своих продуктов со стандартом, на самом деле в лучшем случае поддерживали промежуточный уровень языка SQL-92 (естественно, с собственными расширениями). Только в последних выпусках СУБД ведущих производителей обеспечивается совместимость с полным вариантом языка. Наконец, одновременно с завершением работ по определению стандарта SQL-92 была начата разработка стандарта SQL3. Общей точкой зрения ведущих производителей СУБД является то, что будущие продукты, обладая более развитыми возможностями, должны быть совместимы с предыдущими выпусками. Хотя многие разработчики и пользователи реляционных СУБД осознают наличие многих неустранимых недостатков языка SQL, от него теперь уже невозможно отказаться (как невозможно отказаться от использования языка Си в процедурном программировании). Следовательно, нужен новый стандарт языка, обеспечивающий такие очевидно необходимые возможности как определяемые пользователями типы данных, более развитые средства определения таблиц, наличие полного механизма триггеров и т.д. Нужен именно стандарт, а не наличие развитых частных версий языка, поскольку это выгодно и производителям и пользователям СУБД
В 1992 году этот стандарт был назван SQL-92 (ISO/IEC 9075:1992). Последней к моменту написания этой книги версией стандарта SQL является SQL:2003 (ISO/IEC 9075X:2003).
Любая реализация SQL в конкретной СУБД несколько отличается от стандарта, соответствие которому объявлено производителем. Так, многие СУБД (например, MicrosoftAccess 2003, PostgreSQL 7.3) поддерживают SQL-92 не в полной мере, а лишь с некоторым уровнем соответствия. Кроме того, они поддерживают и элементы, которые не входят в стандарт. Однако разработчики СУБД стремятся к тому, чтобы новые версии их продуктов как можно в большей степени соответствовали стандарту SQL.
SQL задумывался как простой язык запросов к реляционной базе данных, близкий к естественному (точнее, к английскому) языку. Предполагалось, что близость по форме к естественному языку сделает SQL средством, доступным для широкого применения обычными пользователями баз данных, а не только программистами. Первоначально SQL не содержал никаких управляющих структур, свойственных обычным языкам программирования. Запросы, синтаксис которых довольно прост, вводились прямо с консоли последовательно один за другим и в этой же последовательности выполнялись. Однако SQL так и не стал инструментом банковских служащих, продавцов авиа-и железнодорожных билетов, экономистов и других служащих различных фирм, использующих информацию, хранимую в базах данных. Для них простой SQL оказался слишком сложным и неудобным, несмотря на свою близость к естественному языку вопросов.
На практике с базой данных обычно работают посредством приложений, написанных программистами на процедурных языках, например, на С, VisualBasic, Pascal, Java и др. Часто приложения создаются в специальных средах визуальной разработки, таких как Delphi, MicrosoftAccess, VisualdBase и т. п. При этом разработчику приложения практически не приходится писать коды программ, поскольку за него это делает система разработки. Во всяком случае, работа с программным кодом оказывается минимальной. Эти приложения имеют удобный графический интерфейс, не вынуждающий пользователя непосредственно вводить запросы на языке SQL. Вместо него это делает приложение. Впрочем, приложение может как использовать, так и не использовать SQL для обращения к базе данных. SQL не единственное, хотя и очень эффективное средство получения, добавления и изменения данных, и если есть возможность использовать его в приложении, то это следует делать. Реляционные базы данных могут и действительно существуют вне зависимости от приложений, обеспечивающих пользовательский интерфейс. Если по каким-либо причинам такого интерфейса нет, то доступ к базе данных можно осуществить с помощью SQL, используя консоль или какое-нибудь приложение, с помощью которого можно соединиться с базой данных, ввести и отправить SQL-запрос (например, Borland SQL Explorer). Язык SQL считают декларативным (описательным) языком, в отличие от языков, на которых пишутся программы. Это означает, что выражения на языке SQL описывают, что требуется сделать, а не каким образом.
Компоненты SQL:
· DML (DataManipulationLanguage — язык манипулирования данными) предназначен для поддержки базы данных: выбора (SELECT), добавления (INSERT), изменения (UPDATE) И удаления (DELETE) данных из таблиц. Эти операторы (команды) могут содержать выражения, в том числе и вычисляемые, а также подзапросы — запросы, содержащиеся внутри другого запроса. В общем случае выражение запроса может быть настолько сложным, что сразу и не скажешь, что он делает. Однако сложный запрос можно мысленно разбить на части, которые легче анализировать. Аналогично, сложные запросы создаются из относительно простых для понимания выражений (подзапросов).
· DDL (DataDefinitionLanguage — язык определения данных) предназначен для создания, модификации и удаления таблиц и всей базы данных. Примерами операторов, входящих в DDL, являются CREATE TABLE (создать Таблицу), CREATE VIEW (создать представление), CREATE SHEMA (создать схему), ALTERTABLE (изменить таблицу), DROP (удалить) и др.
· DCL (DataControlLanguage — язык управления данными) предназначен для обеспечения защиты базы данных от различного рода повреждений. СУБД предусматривает некоторую защиту данных автоматически. Однако в ряде случаев следует предусмотреть дополнительные меры, предоставляемые DCL.
CREATE TABLE ИмяТаблицы (
{ Имя поля таблицы Тип данных [(размер)][(ограничение)…].,…}
{ [, CONSTRAINT ограничения таблицы] }
…);
Условные обозначения:
| - все, что предшествует символу, можно заменить тем, что следует за ним;
{ } - единое целое для применения символа;
[ ] - необязательное выражение;
… - повторяется произвольное число раз;
.,… - повторяется произвольное число раз, но любое вхождение отделяется запятой.
Пример создания простой таблицы без ограничений:
CREATE TABLE Студент (
НомерЗачКнижки INTEGER,
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT
);
Определение первичного ключа в таблице:
CREATE TABLE Студент (
НомерЗачКнижки INTEGER PRIMARY KEY NOT NULL,
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT
);
Структура таблицы с составным первичным ключом:
CREATE TABLE Студент (
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT,
CONSTRAINT PRIMARY KEY (Фамилия, Имя, Отчество));
10. Типы данных SQL
Ответ:
Типы данных:
· Строковый (символьный):
· CHARACTER или CHAR (n)
· CHARACTER VARYING или VARCHAR (n)
· TEXT
· Числовой
· Точныечисловыетипы:
o INTEGER
o SMALLINT
o BIGINT
o NUMERIC
o DECIMAL
· Приблизительныечисловыетипы:
o REAL
o DOUBLE PRECISION
o FLOAT
· Логический (булевский)
· BOOLEAN
· Даты-времени
· DATE
· TIME WITHOUT TIME ZONE
· TIME WITH TIME ZONE
· TIMESTAMP WITHOUT TIME ZONE
· TIMESTAMP WITH TIME ZONE
· Интервальный: INTERVAL - представляет собой разность между двумя значениями типа дата-время
· Год-месяц (количество лет и месяцев между двумя датами)
· День-время (количество дней, часов, минут и секунд между двумя моментами в пределах одного месяца)
· Особые типы данных
· ROW - запись
· ARRAY - массив
· MULTISET - мультимножество
11. Операторы создания базы данных на языке SQL
Ответ:
Основной оператор, задающий создание новой таблицы CREATE TABLE (создать таблицу)
CREATE TABLE ИмяТаблицы (
{ Имя поля таблицы Тип данных [(размер)][(ограничение)…].,…}
{ [, CONSTRAINT ограничения таблицы] }
…);
Условные обозначения:
| - все, что предшествует символу, можно заменить тем, что следует за ним;
{ } - единое целое для применения символа;
[ ] - необязательное выражение;
… - повторяется произвольное число раз;
.,… - повторяется произвольное число раз, но любое вхождение отделяется запятой.
Пример создания простой таблицы без ограничений:
CREATE TABLE Студент (
НомерЗачКнижки INTEGER,
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT
);
Определение первичного ключа в таблице:
CREATE TABLE Студент (
НомерЗачКнижки INTEGER PRIMARY KEY NOT NULL,
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT
);
Структура таблицы с составным первичным ключом:
CREATE TABLE Студент (
Фамилия CHAR (15),
Имя CHAR (10),
Отчество CHAR (15),
ДатаРождения Date,
Специальность CHAR (15),
Примечание TEXT,
CONSTRAINT PRIMARY KEY (Фамилия, Имя, Отчество));
Описание примера на языке SQL:
CREATE TABLE Контакты (
КодКонтакта INTEGER PRIMARY KEY NOT NULL,
Имя VARCHAR (10),
Фамилия VARCHAR (15),
Обращение VARCHAR (10),
Адрес VARCHAR (30));
CREATE TABLE Звонки (
КодЗвонка INTEGER PRIMARY KEY NOT NULL,
КодКонтакта INTEGER NOT NULL,
ДатаЗвонка DATE,
Описание TEXT,
CONSTRAINT FK1 FOREIGN KEY (КодКонтакта)
REFERENCES Контакты (КодКонтакта));
Внешний ключ определяется как ограничение для таблицы в выражении с ключевыми словами CONSTRAINT имя связи FOREIGN KEY(ограничение «внешний ключ»)
Синтаксис оператора: CONSTRAINT имя ограничения FOREIGN KEY ВнешнийКлюч REFERENCES
ВнешняяТаблица (ПервичныйКлюч)
Пример:
CREATE TABLE Заказы (
КодЗаказа INTEGER,
кодКлиента INTEGER,
CONSTRAINT FK FOREIGN KEY
(КодКлиента)
REFERENCES Клиенты(КодКлиента));

CREATE TABLE Контакты (
КодКонтакта INTEGER PRIMARY KEY NOT NULL,
Имя VARCHAR (10),
Фамилия VARCHAR (15),
Обращение VARCHAR (10),
Адрес VARCHAR (30));
CREATE TABLE Звонки (
КодЗвонка INTEGER PRIMARY KEY NOT NULL,
КодКонтакта INTEGER NOT NULL,
ДатаЗвонка DATE,
Описание TEXT,
CONSTRAINT FK1 FOREIGN KEY (КодКонтакта)
REFERENCES Контакты (КодКонтакта));
12. Запросы, назначения запросов, виды запросов
Ответ:
Определение:
В результате выполнения запроса создается таблица, которая либо содержит запрашиваемые данные, либо пуста, если данных, соответствующих запросу не нашлось.
Эта таблица называется результирующий или результатной и существует только во время работы с БД и не присоединяется к числу ее таблиц.
Запросы можно использовать для следующих действий:
· Просмотра записей таблицы без ее открытия;
· Объединение на экране данных нескольких таблиц в виде одной таблицы;
· Просмотра отдельных полей таблицы;
· Выполнения вычислений над значениями полей.
Отличие запросов от фильтров:
· Фильтры не позволяют добавить еще несколько таблиц, записи которых включаются в возвращаемый набор записей;
· Фильтры не позволяют указать поля, которые должны отображаться в результате;
· Фильтр нельзя выделить как отдельный объект БД;
· Фильтры не позволяет производить вычислений.
Виды запросов:
· На выборку;
· На изменение;
· На создание таблицы;
· С параметрами;
· С вычисляемыми полями;
· На управление.
Виды запросов:
Список всех видов запросов можно увидеть Конструктор (работа с запросами) Ленты, в разделе Тип зпроса.
Способы создания запросов:
· С помощью мастера запросов
· С помощью конструктора запросов
· Создание запроса из фильтра
Запрос с параметрами:
Запросы с параметрами отличаются от других тем, что при выполнении запроса открываются диалоговые окна, предлагающие ввести параметры для условий на отбор записей.
Вводимых параметров в одном запросе может быть несколько.
Основные SQL-выражения для выборки данных:
SELECTСписокСтолбцов
FROMСписокТаблиц;
Это обязательные SQL-выражения, ни одного из них нельзя пропустить!!!
Инструкция SELECT:
Сразу за оператором SELECT до списка атрибутов можно применять ключевые слова
ALL (все) и DISTINCT(отличающиеся), которые указывают какие записи представить в результирующую таблицу.
Если эти ключевые слова не используются, по подразумевается, что следует выбрать все записи, что соответствует применению ALL.
В случае использования DISTINCT в результатной таблице представляются только уникальные записи.
Использование псевдонимов:
Заголовки столбцов в результатной таблице можно переопределить по своему усмотрению, назначив им так называемые псевдономы, для этого служит операнд
AS (как) Заголовок_Столбца.
Например
SELECT Client.ClientName AS Клиент, Сlient.Adress AS Адрес
FROM Client;
Уточнения запросов:
· WHERE (где)
· GROUP BY (группировать по)
· HAVING (имеющие, при условии)
· ORDER BY (сортировать по)
Структура запроса с уточнениями:
SELECTСписокСтолбцов
FROMИмяТаблицы
WHEREУсловиеПоиска
GROUPBYСтолбецГруппировки
HAVINGУсловиеПоиска
ORDERBYУсловиеСортировки
Порядок выполнения операторов SQL в запросах:
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
Оператор WHERE:
· Предикаты сравнения: (=), (<), (>), (<>), (<=), (>=);
· BETWEEN;
· IN, NOT IN;
· LIKE, NOT LIKE;
· IS NULL;
· ALL, SOME, ANY;
· EXISTS;
· UNIQUE;
· DISTINCT,
· OVERLAPS,
· MATCH,
· SIMILAR.
Оператор GROUP BY:
Служит для группировки записей по значениям одного или нескольких полей.
Если в SQL-выражении используется оператор WHERE, то GROUPBY находится и выполняется после него.
Оператор HAVING:
Обычно применяется совместно с оператором GROUPBY и задает фильтр записей в группах.
Если в SQL-выражении оператора GROUPBY нет, то оператор HAVING применяется ко всем записям, возвращаемым оператором WHERE.
Оператор ORDER BY:
· ASC – по возрастанию (ascending);
· DESC – по убыванию (descending);
13. Использование агрегированных функций запросов
Ответ:
Функция — это поименованная последовательность хранимых на сервере команд, выполняемая как одно целое, которая может вызываться из других частей программы столько раз, сколько необходимо.
Отличия функций от хранимых процедур:
· функция всегда возвращает значение в основную программу, а хранимая процедура лишь осуществляет какие-либо преобразования, не возвращая результата.
· функции как и хранимые процедуры могут иметь входные параметры, но выходных параметров у них быть не может
· функции можно применять в выражениях присваивания, хранимые процедуры – нельзя.
Существует 2 класса функций:
· встроенные
· пользовательские.
Встроенные функции, имеющиеся в распоряжении пользователей при работе с SQL, можно условно разделить на следующие группы:
· математические функции;
· строковые функции;
· функции для работы с датой и временем;
· функции конфигурирования;
· функции системы безопасности;
· функции управления метаданными;
· статистические функции.
Математические функции:
| ABS | вычисляет абсолютное значение числа |
| ACOS | вычисляет арккосинус |
| ASIN | вычисляет арксинус |
| ATAN | вычисляет арктангенс |
| ATN2 | вычисляет арктангенс с учетом квадратов |
| CEILING | выполняет округление вверх |
| COS | вычисляет косинус угла |
| COT | возвращает котангенс угла |
| DEGREES | преобразует значение угла из радиан в градусы |
| EXP | возвращает экспоненту |
| FLOOR | выполняет округление вниз |
| LOG | вычисляет натуральный логарифм |
| LOG10 | вычисляет десятичный логарифм |
| PI | возвращает значение "пи" |
| POWER | возводит число в степень |
| RADIANS | преобразует значение угла из градуса в радианы |
| RAND | возвращает случайное число |
| ROUND | выполняет округление с заданной точностью |
| SIGN | определяет знак числа |
| SIN | вычисляет синус угла |
| SQUARE | выполняет возведение числа в квадрат |
| SQRT | извлекает квадратный корень |
| TAN | возвращает тангенс угла |
Для иллюстрации использования математической функции ROUND дополним БД таблицами: Disc – для хранения дисциплин, Ocenka – для хранения оценок по каждой дисциплине.
create table Disc
(
idDiscint identity primary key,
nameDiscvarchar(200)
)
create table Ocenka
(
idVedint identity primary key,
idStint references Student(idSt),
idDiscint references Disc(idDisc),
ocenkasmallint
)
insert into Disc values ('Математика')
insert into Disc values ('История')
insert into Disc values ('Информатика')
insert into Ocenka values(3,1,5)
insert into Ocenka values(3,2,4)
insert into Ocenka values(3,3,5)
insert into Ocenka values(4,1,3)
insert into Ocenka values(4,2,4)
insert into Ocenka values(4,3,2)
Проведем расчет среднего балла по всем студентам и округлим значение до 2-х знаков после запятой:
select round(convert(float, sum(ocenka))/convert(float,count(*)),2) from Ocenka
Средний балл для каждого студента:
select
nameSt+' '+sNameSt as ФИО,
round(convert(float, sum(ocenka))/convert(float,count(*)),2) as [Среднийбалл]
fromOcenka join Student on (Ocenka.idSt=Student.idSt)
group by nameSt+' '+sNameSt
Строковые функции6
| ASCII | возвращает код ASCII левого символа строки |
| CHAR | по коду ASCII возвращает символ |
| CHARINDEX | определяет порядковый номер символа, с которого начинается вхождение подстроки в строку |
| DIFFERENCE | возвращает показатель совпадения строк |
| LEFT | возвращает указанное число символов с начала строки |
| LEN | возвращает длину строки |
| LOWER | переводит все символы строки в нижний регистр |
| LTRIM | удаляет пробелы в начале строки |
| NCHAR | возвращает по коду символ Unicode |
| PATINDEX | выполняет поиск подстроки в строке по указанному шаблону |
| REPLACE | заменяет вхождения подстроки на указанное значение |
| REVERSE | возвращает строку, символы которой записаны в обратном порядке |
| RIGHT | возвращает указанное число символов с конца строки |
| RTRIM | удаляет пробелы в конце строки |
| SOUNDEX | возвращает код звучания строки |
| SPACE | возвращает указанное число пробелов |
| STR | выполняет конвертирование значения числового типа в символьный формат |
| STUFF | удаляет указанное число символов, заменяя новой подстрокой |
| SUBSTRING | возвращает для строки подстроку указанной длины с заданного символа |
| UPPER | переводит все символы строки в верхний регистр |
Пример: Использование функции LEFT для получения инициалов студентов
selectLEFT(nameSt,1)+'. '+LEFT(lnameSt,1)+'. '+sNameSt asФИО
from Student
Функции для работы с датой и временем
| DATEADD | добавляет к дате указанное значение дней, месяцев, часов и т.д. |
| DATEDIFF | возвращает разницу между указанными частями двух дат |
| DATENAME | выделяет из даты указанную часть и возвращает ее в символьном формате |
| DATEPART | выделяет из даты указанную часть и возвращает ее в числовом формате |
| DAY | возвращает число из указанной даты |
| GETDATE | возвращает текущее системное время |
| ISDATE | проверяет правильность выражения на соответствие одному из возможных форматов ввода даты |
| MONTH | возвращает значение месяца из указанной даты |
| YEAR | возвращает значение года из указанной даты |
Пример: Выделение из даты рождения дня и месяца в строковом формате.
selectLEFT(nameSt,1)+'. '+LEFT(lnameSt,1)+'. '+sNameSt asФИО,
DATENAME(day,dateB)+' '+DATENAME(month,dateB)
from Student
Пользовательские функции очень похожи на хранимые процедуры. Так же в них можно передавать параметры и они выполняют некоторые действия, однако их главным отличием от хранимых процедур является то, что они выводят (возвращают) какой то результат. Более того, они вызываются только при помощи оператора SELECT, аналогично встроенным функциям. Все пользовательские функции делятся на 2 вида:
· Скалярные функции - функции, которые возвращают число или текст, то есть одно или несколько значений;
· Табличные функции - функции, которые выводят результат в виде таблицы.
Для создания новой пользовательской функции используется команда CREATE FUNCTION имеющая следующий синтаксис:
CREATE FUNCTION <Имяфункции>
([@<Параметр1><Тип1>[=<Значение1>],
@<Параметр2><Тип2>[=<Значение2>],...])
RETURNS <Тип>/TABLE
AS
RETURN([<Команды SQL>])
Здесь:
· Имя функции - имя создаваемой пользовательской функции.
· Параметр1, Параметр2,.. - параметры передаваемые в функцию.
· Значение1, Значение2, … - значения параметров по умолчанию.
· Тип1, Тип2,... - типы данных параметров.
После служебного слова RETURNS в скалярных функциях ставится тип данных результата, который возвращает скалярная функция, либо ставится служебное слово TABLE в табличных функциях.
После служебного слова RETURN ставится SQL команда самой функции.
Замечание: После служебного слова RETURN может быть несколько команд, которые располагаются между словами BEGIN и END. В этом случае служебное слово RETURN не ставится.
Замечание: Тип данных параметра должен совпадать с типом данных выражения, в котором он используется.
Замечание: Если используются несколько SQL команд и BEGIN и END, то перед END нужно ставить команду RETURN <результат функции>.
Пример (скалярная пользовательская функция): Функция для вычисления возраста:
createfunction Age
(@date datetime)
returnsvarchar(10)
as
begin
declare @a varchar(10)
select @a=DATEDIFF(year, @date,getdate())
return @a
end
Использование созданной функции:
selectLEFT(nameSt,1)+'. '+LEFT(lnameSt,1)+'. '+sNameSt asФИО,
dbo.Age(dateB)+' лет'asВозраст
from Student
Представленная выше пользовательская функция реализована при помощи нескольких команд SQL, но ее можно реализовать при помощи одной строки следующим образом:
createfunction Age1
(@date datetime)
returnsvarchar(10)
as
begin
returnDATEDIFF(year, @date,getdate())
end
Пример (табличная пользовательская функция): Из таблицы Студенты выводятся поля ИД студента, возраст, который вычисляется как разница дат в годах, между датой рождения и текущей датой (процедура без параметров).
createfunction AgeStud
()
returnstable
as
return(select idSt,DATEDIFF(year, dateB,getdate())as Age from Student)
Использование функции:
selectLEFT(nameSt,1)+'. '+LEFT(lnameSt,1)+'. '+sNameSt asФИО, Age
from Student join AgeStud()on(student.idSt=AgeStud.idSt)
14. Использование вложенных запросов
Ответ:
В SQL вложенным запросом называется такой запрос, в котором внешний замыкающий оператор содержит подзапрос. Этот подзапрос может сам быть замыкающим оператором для другого вложенного подзапроса. Теоретически число уровней вложенности для подзапросов не ограничено, а на практике зависит от реализации.
Подзапросы обязательно должны быть операторами SELECT, но самый внешний замыкающий оператор может также быть INSERT, UPDATE или DELETE.
Второй способ извлечения данных из множества таблиц основан на том, что подзапрос может работать с одной таблицей, а его замыкающий оператор — с другой.
Подзапросы находятся в предложении WHERE внешнего оператора. Их роль состоит в том, чтобы задавать для этого предложения условия поиска.
Сложные запросы получаются из других запросов следующими способами:
· Вложением SQL-выражения запроса в SQL-выражение другого запроса. Первый из них называют подзапросом, а второй – внешним или основным запросом;
· Применением к SQL-запросам операторов объединения или соединения наборов записей, возвращаемых запросами.
Подзапрос – это SQL-выражение, начинающееся с оператора SELECT, которое содержится в условии оператора WHERE или HAVING для другого запроса.
Внешний запрос, если только он не является подзапросом, не обязательно начинается с оператора SELECT. Подзапрос сам может содержать подзапрос и т.д. При этом сначала выполняется подзапрос, имеющий самый глубокий уровень вложения.
Часто внешний запрос обращается к одной таблице, а подзапрос – к другой.
Выделяют три частных случая простых подзапросов:
· Подзапросы, возвращающие единственное значение;
· Подзапросы, возвращающие список значений из одного столбца таблицы;
· Подзапросы, возвращающие набор записей.
Например, необходимо выбрать из таблицы Клиенты те записи, сумма заказов которых больше среднего значения.
SELECT * FROM Клиенты
WHERE Сумма заказа > (SELECT AVG (Сумма заказа) FROM Клиенты);
Связанные (коррелированные) подзапросы ссылаются на таблицу, которая упоминается в основном запросе и должен выполнятся в некотором контексте с текущим состоянием основного запроса.
SELECT A FROM T1 WHERE B= (SELECT B FROM T2 WHERE C=T1.C);
MS Access позволяет изменять данные посредством запросов. Такие запросы называются запросами на изменение и делятся на четыре категории:
· Запросы на создание таблиц: создают таблицы на основе данных, содержащихся в результирующем множестве запросов. Чаще всего такой тип запросов используется при экспорте информации в другие приложения. В SQL запрос на создание таблицы добавляется оператором INTO [новая таблицы] внутри инструкции SELECT;
· Запросы на добавление записей: запрос на добавление данных используется часто с целью копирования данных из одной таблицы в другую.На SQL запрос на добавление начинается с оператора INSERT. Например,
INSERT INTO [ЛичныеДела 1] (лдТип, лдПредложил, лдДатаНазначено)
SELECT ЛичныеДела.лдТип, ЛичныеДела.лдПредложил, ЛичныеДела.лдДатаНазначено
FROM ЛичныеДела;
· Запрос на обновление записей: изменяют значения существующих полей таблицы в соответствии с записями результирующего множества.Такие запросы применяются, чтобы внести изменения сразу в большое число записей с помощью одного запроса.Инструкция на языке SQL- оператор UPDATE.Например, необходимо изменить адрес улицы сим. Фрунзе на проспект Славы в таблице Клиенты.
UPDATE Клиенты SET Клиенты.Адрес = "проспект Славы"
WHERE (((Клиенты.Адрес) =“им. Фрунзе”));
· Запросы на удаление записей: позволяют отобрать требуемые записи и удалить их за один прием.Однако, удаляя данные из связанных таблиц необходимо помнить о целостности данных. Оператор SQL эквивалентный удалению DELETE.
Перекрестные запросы: Это запросы в которых происходит статистическая обработка данных.
Перекрестные запросы обладают рядом достоинств:
· Возможность обработки большого объема данных и вывода их в формате, удобном для автоматического создания графиков и диаграмм;
· Простота и скорость разработки сложных запросов.
Недостаток перекрёстных запросов: Нельзя сортировать таблицу результатов по значениям, содержащимся в столбцах, т.к. в подавляющем большинстве случаев одновременное упорядочивание данных в столбцах и по всем кортежам невозможно.
Инструкция SQL перекрестных запросов содержит операторы:
· TRANSFORM – определяет условие для записей результирующей таблицы;
· PIVOT – задает заголовки столбцов результирующего запроса.
15. Операторы соединения на языке SQL
Ответ:
Операции соединения наборов записей возвращают таблицы, записи в которых получаются путем некоторой комбинации записей соединяемых таблиц. Для этого используется оператор JOIN (соединить).
Внутреннее соединение (эквисоединение): если таблицы связаны отношением «один-ко-многим», соединения основываются на уникальном значении поля первичного ключа одной таблицы и значениях поля внешнего ключа в другой таблице. В результирующее множество запроса попадают все записи из главной таблицы, для которых имеются соответствующие записи в подчиненной таблице.
Если в подчиненной таблице записи с заданной величиной отсутствуют, то соответствующие записи из главной таблицы в результирующее множество не включаются. Такие соединения между таблицами создаются автоматически, если:
· В таблицах имеются поля с одинаковыми именами и согласованными типами данных, причем, одно из полей является ключевым;
· Соединение было явно создано в окне схемы данных.
Результатом такого запроса являются все записи, значения связанных полей которых в обеих таблицах совпадают.
Другими словами, эквисоединение связывает данные полей записей таблиц отношением равенства.
Оператор SQL описывающие внутренние соединения INNER JOIN.
Для создания запроса, объединяющего все записи из одной таблицы и только те записи из другой таблицы, в которых связанные поля совпадают, используют внешние соединения.
Независимо от того имеются ли соответствующие записи во второй таблице, все записи первой таблицы попадают в результирующее множество запроса.
Различают два вида внешних соединений:
· Левое внешние соединение LEFT JOIN;
· Правое внешние соединение RIGHT JOIN.
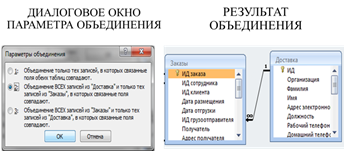
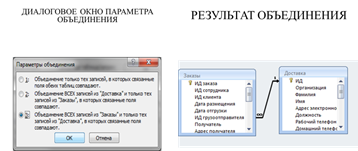
Если необходимо связать данные любым отношением, кроме отношения равенства, используют соединения по отношению или тэта-соединения.
Например, необходимо отобрать клиентов, у которых атрибуты Адрес клиента и Адрес получателя не совпадают:
SelectКлиенты.Адрес, Заказы.Адрес получателя
From Клиенты INNER JOIN Заказы ON Клиенты.ИД = Заказы.ИД клиента
WhereЗаказы.Адрес получателя<>Клиенты.Адрес;
Для связывания данных в одной таблице применяют рекурсивные соединения.
Для этих целей в конструкторе запроса помещают копию таблицы (Таблица 1) и связывают поля идентичных таблиц.
16. Типы отношений в концептуальной модели данных
Ответ:
Обобщение – это объектное множество, являющееся надмножеством другого объектного множества (содержащее его).
Пример обобщения:

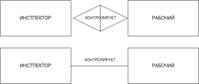
Отношение – это связь между элементами двух объектных множеств.
Рассмотрим пример: для служащих компании можно выделить два ОМ ИНСПЕКТОР и РАБОЧИЙ, причём инспекторы контролируют рабочих.
Отношение Контролирует связывает каждого инспектора с рабочими, которых он контролирует.
Пример отношения Контролирует:
Мощность отношения – максимальное количество элементов одного объектного множества, связанных с одним элементом другого объектного множества.

Типы отношений объектных множеств:
· Функциональным называется отношение, максимальная мощность которого как минимум в одном направлении равна 1.Отношение один-к-одному означает, что максимальная мощность равна 1 в обоих направлениях (1:1). Например, у АВТОМОБИЛЯ один ВОДИТЕЛЬ, у ВОДИТЕЛЯ один АВТОМОБИЛЬ.
· Отношение один-ко-многим означает, что максимальная мощность равна 1 в одном направлении и многим в обратном (1:М). Например СЛУЖАЩИЙ работает в одном ОТДЕЛЕ, но в ОТДЕЛЕ работает много СЛУЖАЩИХ.
· Отношение многие-ко-многим означает, что максимальная мощность в обоих направлениях равна многим (М:М). Например: СТУДЕНТ посещает много КУРСОВ, каждый КУРС слушает много СТУДЕНТОВ.
Если в отношении участвуют два объектных множества, они называются бинарными.Отношения высокого порядка называют n-арными. 3-арное отношение называется терарным (трёхсторонним).
17. Теоретико-множественные операции реляционной алгебры (с примерами)
Ответ:
Реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных.
Первоначальный набор из 8 операций был предложен Э. Коддом в 1970-е годы и включал как операции, которые до сих пор используются (проекция, соединение и т.д.), так и операции, которые не вошли в употребление (например, деление отношений).
Реляционная алгебра представляет собой набор таких операций над отношениями, что результат каждой из операций также является отношениям. Это свойство алгебры называется замкнутостью.
Операции над одним отношение называются унарными, над двумя отношениями — бинарными, над тремя — тернарными (таковые практически неизвестны).
Пример унарной операции — проекция, пример бинарной операции — объединение.
Реляционную операцию f можно представить функцией с отношениями в качестве аргументов:R = f(R1, R2, …, Rn
Поскольку реляционная алгебра является замкнутой, в качестве операндов в реляционные операции можно подставлять другие выражения реляционной алгебры (подходящие по типу):
R = f(f1(R11, R12, …), f2(R21, R22,…),…)
В реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
В общем это множество избыточное, так как одни операции могут быть представлены через другие, однако множество операций выбрано из соображений максимального удобства при реализации произвольных запросов к БД.
Все множество операций можно разделить на две группы: теоретико-множественные операции или традиционные и специальные операции.
В первую группу входят 4 операции. Три первые теоретико-множественные операции являются бинарными, то есть в них участвуют два отношения и они требуют эквивалентных схем исходных отношений.
Теоретико-множественные операции:
Объединением двух отношении называется отношение, содержащее множество кортежей, принадлежащих либо первому, либо второму исходным отношениям, либо обоим отношениям одновременно. R1ÈR2=R3

Разностью отношений R1 и R2 называется отношение, содержащее множество кортежей, принадлежащих R1 и не принадлежащих R2. R3 = R1 \ R2

В отличие от навигационных средств манипулирования данными в теоретико-графовых моделях операции реляционной алгебры позволяют получить сразу иной качественный результат, который является семантически гораздо более ценным и понятным пользователям.
Например, сравнение результатов объединения и разности номенклатуры двух участков позволит оценить специфику производства: насколько оно уникально на каждом участке, и, в зависимости от необходимости, принять соответствующее решение по изменению номенклатуры.
Кроме перечисленных трех теоретико-множественных операций в рамках реляционной алгебры определена еще одна теоретико-множественная операция — расширенное декартово произведение.
Эта операция не накладывает никаких дополнительных условий на схемы исходных отношений, поэтому операция расширенного декартова произведения, обозначаемая R1 х R2, допустима для любых двух отношений. Но прежде чем определить саму операцию, введем дополнительно понятие конкатенации, или сцепления, кортежей.
Сцеплением, пли конкатенацией, кортежей с = <c1, с2,..., сn> и q = <q1, q2,..., qm> называется кортеж, полученный добавлением значений второго в конец первого. Сцепление кортежей с и q обозначается как (с, q). (с, q) = <с1 с2,..., сn, q1, q2,.... qm>
Здесь n — число элементов в первом кортеже с, m — число элементов во втором кортеже. q.
Все предыдущие операции не меняли степени или арности отношений — это следует из определения эквивалентности схем отношений.
Операция декартова произведения меняет степень результирующего отношения.
Декартовым произведением отношения R, степени n со схемой SR1=(А1,А2...,Аn) и отношения R2 степени m со схемой SR2=(В1,В2,..., Вm) называется отношение R3 степени n+m со схемой SR3 = (А1, А2,..., Аn, В1, В2,..., Вm), содержащее кортежи, полученные сцеплением каждого кортежа отношения R1 с каждым кортежем q отношения R2.
То есть если R1 = { r }, R2 = { q }, тоR1 * R2 = R3
Операцию декартова произведения с учетом возможности перестановки атрибутов в отношении можно считать симметричной. Очень часто операция расширенного декартова произведения используется для получения некоторого универсума — т. е. отношения, которое характеризует все возможные комбинации между элементами отдельных множеств.
Однако самостоятельного значения результат выполнения операции обычно не имеет, он участвует в дальнейшей обработке.
18. Специальные операции реляционной алгебры (с примерами)
Ответ:
Реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных.
Первоначальный набор из 8 операций был предложен Э. Коддом в 1970-е годы и включал как операции, которые до сих пор используются (проекция, соединение и т.д.), так и операции, которые не вошли в употребление (например, деление отношений).
Реляционная алгебра представляет собой набор таких операций над отношениями, что результат каждой из операций также является отношениям. Это свойство алгебры называется замкнутостью.
Операции над одним отношение называются унарными, над двумя отношениями — бинарными, над тремя — тернарными (таковые практически неизвестны).
Пример унарной операции — проекция, пример бинарной операции — объединение.
Реляционную операцию f можно представить функцией с отношениями в качестве аргументов:R = f(R1, R2, …, Rn
Поскольку реляционная алгебра является замкнутой, в качестве операндов в реляционные операции можно подставлять другие выражения реляционной алгебры (подходящие по типу):
R = f(f1(R11, R12, …), f2(R21, R22,…),…)
В реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
В общем это множество избыточное, так как одни операции могут быть представлены через другие, однако множество операций выбрано из соображений максимального удобства при реализации произвольных запросов к БД.
Все множество операций можно разделить на две группы: теоретико-множественные операции или традиционные и специальные операции.
Первой специальной операцией реляционной алгебры является горизонтальный выбор, или операция фильтрации, или операция ограничения отношений.
Для определения этой операции нам необходимо ввести дополнительные обозначения.
Пусть а — булевское выражение, составленное из термов сравнения с помощью связок И, ИЛИ, НЕ и, возможно, скобок.
В качестве термов сравнения допускаются:
· терм А ос а, где А — имя некоторого атрибута, принимающего значения из домена D; а — константа, взятая из того же домена D, a D; ос — одна из допустимых для данного домена D операций сравнения;
· терм А ос В, где А, В — имена некоторых Q-сравнимых атрибутов, то есть атрибутов, принимающих значения из одного и то же домена D.
Тогда результатом операции выбора, или фильтрации, заданной на отношении R в виде булевского выражения, определенного на атрибутах отношения R, называется отношение R[G], включающее те кортежи из исходного отношения, для которых истинно условие выбора или фильтрации:
R[G(r)] = {r | r R ^ G(r) = "Истина"}
Операция фильтрации является одной из основных при работе с реляционной моделью данных. Условие а может быть сколь угодно сложным.
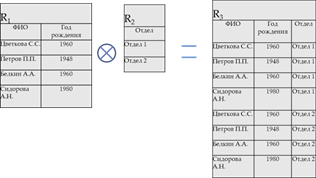
Пример операции горизонтальной выборки:
Например, выбрать из R4 детали с шифром «0011003».
R5=R4[Шифрдетали=«0011003»]

Выбрать из R1 Сотрудников, родившихся в 1960 году.
R2 =R1[ Год рождения= «1960»]

Проекция в реляционной алгебре — унарная операция, которая позволяет получить «вертикальное» подмножество данного отношения,то есть такое подмножество, которое получается выбором специфицированных атрибутов с последующим исключением, если это необходимо, избыточных дубликатов кортежей.
Пусть дана таблица T с атрибутами, то есть и некоторое подмножество множества атрибутов. Результатом проекции отношения по выбранным атрибутам называется новое отношения, полученное из исходного отношения вычеркиванием атрибутов, не входящих в выбранное множество, с последующи
Дата публикования: 2015-10-09; Прочитано: 624 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
