 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Определение объема выборочной совокупности. Ошибки выборки
|
|
С одной стороны, величина выборочной совокупности должна быть статистически значимой, т. е. достаточно большой, для того, чтобы получить достоверную информацию. С другой стороны, выборка должна быть «экономной», т. е. оптимальной.
Каков же критерий оптимальности?
Математики считают, что таким критерием является числовые значения контрольных признаков респондентов (пол, возраст, стаж и т. д.), точнее их дисперсия (разброс). Напомним, что формы расчета дисперсии и другие формулы расчета выборки студенты проходят на занятиях по математике и статистике. Итак, чем больше дисперсия, тем больший объем выборки потребуется. Допустим, мы осуществляем отбор из генеральной совокупности в 2000 человек по признаку «пол»: 70% - мужчин и 30% - женщин. Согласно теории вероятности, можно предположить, что примерно, из каждых десяти отбираемых респондентов встретится 3 женщины. Если, например, мы хотим опросить 90 женщин, нам необходимо опросить 300 человек.
Когда информация о признаках элементов генеральной совокупности отсутствует, исключается возможность определения объема выборки при помощи формул.
В этом случае можно опереться на многолетний опыт социологов – практиков, свидетельствующий о том, что для пробных опросов достаточна выборка объемом 100-250 человек.
При массовых опросах, если величина генеральной совокупности составляет менее 5000 человек, достаточный объем выборки не менее 500 человек. Если же величина генеральной совокупности 5000 человек и более, то выборка должна быть не менее 10% ее состава, но не более 2000-2500 человек. Это гарантирует достаточно достоверные результаты.
Для телефонных опросов даже в крупных городах достаточна выборка в 100 максимум 300 респондентов.
Определение объема выборки
При проведении устных опросов целесообразно использовать метод случайной бесповоротной выборки (его суть заключается в том, что респондент отбирается случайно и второй раз уже не опрашивается). Формула выборки при этом такова:
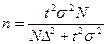 , где
, где
n – объем выборки;
t – коэффициент доверия, вычисляемый по таблицам в зависимости от вероятности, с которой можно гарантировать, что предельная ошибка не превысит t-кратную среднюю ошибку (при вероятности 0,990 он равен 3, а при вероятности 0,999 он равен –3, 28; чаще всего опираются на вероятность 0,954, при которой t составляет 2);
s - среднеквадратическое отклонение в генеральной совокупности или дисперсия;
 - предельная (задаваемая) ошибка выборки;
- предельная (задаваемая) ошибка выборки;
N – численность генеральной совокупности.
Например, объем генеральной совокупности – 50771 человек;
· при уровне доверительной вероятности 95%, коэффициент доверия t =2
· среднеквадратическом отклонении s =50;
· и предельной ошибке выборки 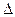 =7;
=7;
· объем выборки n = 203 чел.
Пример. Предположим, что магазин обслуживает за определенный период около 100 000 человек. По данным предыдущих опросов установлено, что дисперсия составляет ± 25 руб./чел. Коэффициент доверия равен 2. Предельную ошибку мы приняли равной 1 руб. Тогда численность выборки составит 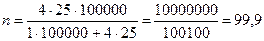 чел.
чел.
Следовательно, для получения надежных представительных данных надо опросить 100 чел.
В целях получения однородности изучаемой совокупности и общей точности расчета совокупность стратифицируют, разбивают на ряд групп по какому-то признаку, например по полу, доходу и т.д. Здесь формула выборки отличается от предыдущей только тем, что выборочная дисперсия заменяется средней из внутригрупповых дисперсий. Однако в этом случае целесообразно вести отбор по каждой группе пропорционально дифференциации признака (ni). Тогда формула выборки (по каждой группе) значительно упрощается:
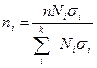 ,
,
где k – число i -х групп населения;
Ni – численность i -й группы населения;
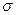 - среднеквадратическое отклонение признака в i- группе.
- среднеквадратическое отклонение признака в i- группе.
Пример. Для обследования, ставящего целью выявить мнение потребителей о новом товаре в населенном пункте, насчитывающем 50тыс. семей, необходимо провести анкетирование. Условно принимается, что в каждой квартире проживает одна семья и на нее будет выделена одна анкета. Предварительные исследования установили, что дисперсия среднего размера покупки составляет ± 25 руб.; t = 2; предельная ошибка не должна превышать 0,01 тыс. руб. Отсюда численность выборки составила:
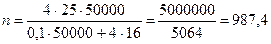 .
.
Эта величина округляется до 1000 семей, т.е. установлена 2%-ная выборка.
Используются в практике расчета выборки и другие формулы:
N= 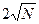
Для малых массивов используется другая формула:
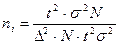
Ошибки выборки
Ошибки выборки бывают случайные (систематические) и ошибки смещения.
Случайные ошибки. Если отклонение полученных результатов в ту или иную сторону не превышает в среднем 5%, то выборка является репрезентативной, а ошибка случайной. Например, из соотношения генеральной совокупности 40% женщин 60% мужчин в выборку должны попасть 40% женщин 60% мужчин, а попало, например, 37% женщин и 62% мужчин, или 42% женщин и 58% мужчин. Указанные ошибки считаются случайными, т. к. они не превышают 5% барьера.
Случайные ошибки можно рассчитать по вышеуказанным формулам.
Ошибки смещения. Ошибки смещения – это более сложные ошибки. Например, в нашем примере вместо желаемых иметь в выборке 40% женщин и 60% мужчин, мы получаем, наоборот, 60% женщин и 40% мужчин. Проблема заключается в том, что рассчитать с помощью формул ошибки смещения невозможно, и они автоматически переходят на результаты и выводы исследования. Ошибки смещения могут являться следствием:
- неверных исходных статистических данных о параметрах контрольных признаков генеральной совокупности;
- слишком малого объема выборки;
- неверного применения способа отбора единиц анализа (например, отбор из неверно составленного списка, неудачный выбор места и времени проведения исследования).
При формировании выборочных совокупностей следует добиваться полноты, точности, адекватности, репрезентативности.
Полнота означает, что в генеральной совокупности должны быть представлены все единицы анализа, ибо неполнота ведет к ошибкам.
Точность характеризует информацию по каждой единице. Точность, например, считается достаточной, если сумма погрешностей и ошибок не превышает 5 %.
Адекватность есть свойство основы выборки. Довольно часто точность выборки отождествляется с ее адекватностью. Между тем это не так. Адекватность же подразумевает характеристику выборки как модели качества исследуемого объекта. Например, список молодых рабочих не может быть основой для выборки всех членов трудового коллектива. В этом случае основа выборки является неадекватной. И, наоборот, список членов трудового коллектива не может быть основой выборки для исследования молодых рабочих.
Свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Репрезентативност ь (представительность) выборки означает, что у всех элементов генеральной совокупности был шанс попасть в выборку, и что выборка отражает генеральную совокупность.
В завершение темы представим стандартные таблицы выборки с учетом предельной ошибки выборки и доверительной вероятности, разработанные социологами - практиками (табл.5).
Таблица 5
Стандартные таблицы выборки
Дата публикования: 2015-10-09; Прочитано: 3148 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
