 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Запись Паскаля – структурированный комбинированный тип данных, состоящий из фиксированного числа компонент (полей) разного типа
|
|
type < имя _ типа >=record
<имя_поля1>: тип;
<имя_поля2>: тип;
………………….
<имя_поля K >: тип
end;
где record – служебное слово, а <имя_типа> и <имя_поля> - правильные идентификаторы языка Паскаль. Обращение к полям with <переменная типа «Запись»> do <операторы>
var s: name;
with s do
N2:= N3 + 17;
Используют при работе с таблицами, где каждая запись – одна строка таблицы. Массивы записей.
Строки – последовательность символов.
Заключаются в апострофы. Длина – до 255 символов.
<имя_переменной>: string[n]
Множество
Множество — это структурированный тип данных, представляющий собой набор взаимосвязанных по какому-либо признаку или группе признаков объектов, которые можно рассматривать как единое целое. Каждый объект в множестве называется элементом множества.
Множественный тип описывается с помощью служебных слов Set of, например:
type M = Set of B;Здесь М - множественный тип, В - базовый тип.
Пример описания переменной множественного типа:
Type M = Set of 'A'..'D'; Var MS: M;Принадлежность переменных к множественному типу может быть определена прямо в разделе описания переменных:
var C: Set of 0..7;Динамические структуры данных.
Статическими величинами называются такие, память под которые выделяется во время компиляции и сохраняется в течение всей работы программы.
В языках программирования (Pascal, C, др.) существует и другой способ выделения памяти под данные, который называется динамическим. В этом случае память под величины отводится во время выполнения программы. Такие величины будем называть динамическими. Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически распределяемый раздел памяти называется динамической памятью (динамически распределяемой памятью).
Использование динамических величин предоставляет программисту ряд дополнительных возможностей. Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных. Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. В-третьих, использование динамической памяти позволяет создавать структуры данных переменного размера.
Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа. Величины, имеющие ссылочный тип, называют указателями.
Указатель содержит адрес поля в динамической памяти, хранящего величину определенного типа. Сам указатель располагается в статической памяти.
Адрес величины — это номер первого байта поля памяти, в котором располагается величина. Размер поля однозначно определяется типом.
Величина ссылочного типа (указатель) описывается в разделе описания переменных следующим образом (Pascal):
Var <идентификатор>: ^<имя типа>;Вот примеры описания указателей:
Type Mas1 = Array[1..100] Of Integer; Var P1: ^Integer; P2: ^String; Pm: ^Mas1;Здесь P1 — указатель на динамическую величину целого типа; P2 — указатель на динамическую величину строкового типа; Pm — указатель на динамический массив, тип которого задан в разделе Type.
Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память выделяется только под статические величины. Указатели — это статические величины, поэтому они требуют описания.
Память под динамическую величину, связанную с указателем, выделяется в результате выполнения стандартной процедуры NEW. Формат обращения к этой процедуре:
NEW(<указатель>);Считается, что после выполнения этого оператора создана динамическая величина, имя которой имеет следующий вид:
<имя динамической величины>:= <указатель>^Пусть в программе, в которой имеется приведенное выше описание, присутствуют следующие операторы:
NEW(P1); NEW(P2); NEW(Pm);После их выполнения в динамической памяти оказывается выделенным место под три величины (две скалярные и один массив), которые имеют идентификаторы:
P1^, P2^, Pm^Дальнейшая работа с динамическими переменными происходит точно так же, как со статическими переменными соответствующих типов. Им можно присваивать значения, их можно использовать в качестве операндов в выражениях, параметров подпрограмм и пр. Например, если переменной P1^ нужно присвоить число 25, переменной P2^ присвоить значение символа "Write", а массив Pm^ заполнить по порядку целыми числами от 1 до 100, то это делается так:
P1^:= 25;
P2^:= 'Write';
For I:= 1 To 100 Do Pm^[I]:= I;
Кроме процедуры NEW значение указателя может определяться оператором присваивания:
<указатель>:= <ссылочное выражение>;
В качестве ссылочного выражения можно использовать
- указатель;
- ссылочную функцию (т.е. функцию, значением которой является указатель);
- константу Nil.
Nil — это зарезервированная константа, обозначающая пустую ссылку, т.е. ссылку, которая ни на что не указывает. При присваивании базовые типы указателя и ссылочного выражения должны быть одинаковы. Константу Nil можно присваивать указателю с любым базовым типом.
До присваивания значения ссылочной переменной (с помощью оператора присваивания или процедуры NEW) она является неопределенной.
Ввод и вывод указателей не допускается.
Рассмотрим пример. Пусть в программе описаны следующие указатели:
Var D, P: ^Integer;
K: ^Boolean;
Тогда допустимыми являются операторы присваивания
D:= P; K:= Nil;
поскольку соблюдается принцип соответствия типов. Оператор K:= D ошибочен, т.к. базовые типы у правой и левой части разные.
Если динамическая величина теряет свой указатель, то она становится "мусором". В программировании под этим словом понимают информацию, которая занимает память, но уже не нужна.
В Паскале имеется стандартная процедура, позволяющая освобождать память от данных, потребность в которых отпала. Ее формат:
DISPOSE(<указатель>);
Например, если динамическая переменная P^ больше не нужна, то оператор
DISPOSE(P)
удалит ее из памяти. После этого значение указателя P становится неопределенным. Особенно существенным становится эффект экономии памяти при удалении больших массивов.
В версиях Турбо-Паскаля, работающих под операционной системой MS DOS, под данные одной программы выделяется 64 килобайта памяти (или, если быть точнее, 65520 байт). Это и есть статическая область памяти. При необходимости работать с большими массивами информации этого может оказаться мало. Размер динамической памяти — много больше (сотни килобайт). Поэтому использование динамической памяти позволяет существенно увеличить объем обрабатываемой информации.
Следует отчетливо понимать, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему — величина.
К динамическим структурам относят:
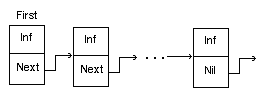
Списки -
Стеки - структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. По определению, элементы извлекаются из стека в порядке, обратном их добавлению в эту структуру, т.е. действует принцип "последний пришёл — первый ушёл".
Очередь — это информационная структура, в которой для добавления элементов доступен только один конец, называемый хвостом, а для удаления — другой, называемый головой. В англоязычной литературе для обозначения очередей довольно часто используется аббревиатура FIFO (first-in-first-out — первый вошёл — первым вышел).
Дерево — это совокупность элементов, называемых узлами (при этом один из них определен как корень), и отношений (родительский–дочерний), образующих иерархическую структуру узлов. Узлы могут являться величинами любого простого или структурированного типа, за исключением файлового. Узлы, которые не имеют ни одного последующего узла, называются листьями.
В линейном списке каждый элемент связан со следующим и, возможно, с предыдущим (односвязный и двусвязный). Если последний элемент связать указателем с первым, получится кольцевой список.
Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо строкой и является частью поля данных.
Стек является простейшей динамической структурой. LIFO. Память под локальные переменные выделяется по принципу LIFO. Стеки широко применяются в СПО, компиляторах, в различных рекурсивных алгоритмах.
Очередь — это динамическая структура данных, добавление элементов в которую выполняется в один конец, а выборка — из другого конца. FIFO. Применяются при буферизованном вводе-выводе или диспетчеризации задач в операционной системе.
3. Объектно-ориентированное программирование. Объекты, свойства, методы, события. Программирование по событиям. Наследование и инкапсуляция.
Объект — элементарная единица в объектно-ориентированном программировании, заключающая в себе как описывающие объект данные, так и средства обработки этих данных.
Объектно-ориентированное программирование (ООП) — это
1)метод программирования, при использовании которого главными элементами программ являются объекты. Примерами объектно-ориентированных сред могут служить Microsoft Visual C++, Borland Delphi, Borland C++ Builder
2) методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
Таким образом, в ООП центральное место занимают объекты, которые объединяют в одно целое (инкапсулируют) свойства объекта и возможные над ним операции (методы).
Если говорить образно, то объекты - это существительные.
Объектом являются, например, графический примитив Окружность.
Свойства объекта, т.е. его качества и характеристики (например, координаты, цвет, радиус) - это прилагательные.
Методы объекта, т.е. набор операций, которой он может выполнять (например, переместить, изменить цвет) - это глаголы.
Классы – это объединение объектов, инкапсулирующих одинаковый перечень свойств операций.
Экземпляр класса – это каждый объект по отдельности. Экземпляры могут иметь различные значения свойств, но все экземпляры одного класса имеют одинаковые методы..
Такой подход объективно обусловлен тем, что окружающий нас мир состоит из целостных объектов, которые обладают определенными свойствами и поведением. В технологии объектно-ориентированного программирования объекты сохраняют свою целостность, все свойства объекта и его поведение описываются внутри самого объекта.
В основе объектно-ориентированного подхода лежат три понятия:
- инкапсуляция: объединение данных с процедурами и функциями в рамках единого целого — объекта;
- наследование: возможность построения иерархии объектов с использованием наследования их характеристик;
- полиморфизм: задание одного имени действию, которое передается вверх и вниз по иерархии объектов, с реализацией этого действия способом, соответствующим каждому объекту в иерархии.
Инкапсуляция. В ООП объект представляет собой запись, которая служит «оболочкой» для соединения связанных между собой данных и процедур. Другими словами, объект обладает определенными свойствами и поведением. Рассмотрим в качестве примера кнопку — типичный объект, присутствующий в интерфейсе большого количества программ. Кнопка обладает определенным поведением: она может быть нажата, после нажатия на кнопку будут происходить определенные события и т. д. Соединение таких свойств и поведения в одном объекте и называется инкапсуляцией. При описании структуры класса используются спецификаторы доступа (в С++: private, public и protected) которые определяют область видимости элементов класса. Элементы, описанные после спецификатора PRIVATE, видимы только внутри класса. Таким образом, ООП даёт возможность при описании класса задать его открытый интерфейс и скрыть его реализацию. С помощью ограничения областей видимости можно защитить программу от неверного действия пользователей или других программ. Так же может быть использован спецификатора доступа PROTECTED (он используется при наследовании, доступ к protected-членам родительского класса имеют только его потомки)
class A { public: int a, b; //данные открытого интерфейса int Method1 (); //метод открытого интерфейса private: int Aa, Ab; //скрытые данные void Method2 (); //скрытый метод };Наследование. Объекты могут наследовать свойства и поведение от других объектов, которые называются «родительскими объектами». Это понятие можно хорошо проиллюстрировать опять на примере интерфейса программы. Возьмем в качестве «родительского объекта» самое простое окно, при вызове которого запускается определенная процедура. Классическим примером иерархии элементов GUI является окно->элементы интерфейса (кнопка, список, текстовое поле).
Окно обладает стандартными членами-функциями для своего отображения, которые перегружаются (overload) в потомках.
class A{ //базовый класс };class B: public A{ //public наследование }class C: protected A{ //protected наследование }class Z: private A{ //private наследование }
Полиморфизм — это слово из греческого языка, означающее «много форм». Перечень интерфейсных кнопок различных типов (простая кнопка, радиокнопка, кнопка-переключатель и т. д.) представляет собой хороший пример полиморфизма. Каждый тип объекта в этом перечне представляет собой различный тип интерфейсной кнопки. Можно описать метод для каждой кнопки, который изобразит этот объект на экране. В терминах объектно-ориентированного программирования можно сказать, что все эти типы кнопок имеют способность изображения самих себя на экране. Обычно под полиморфизмом понимают ДИНАМИЧЕСКОЕ (run-time) определение, того какой именно метод должен использоваться, т.е. во время выполнения определяется к какому конкретно типу относится объект для которого будет вызываться метод с указанным именем. Обычно это реализуется с помощью доступа к объектам дочерних классов через указатель на базовый класс (механизм виртуальных функций)
Однако способ (процедура), которым каждая кнопка должна изображать себя на экране, является различным для каждого типа кнопки. Простая кнопка рисуется на экране с помощью процедуры «вывод изображения простой кнопки», радиокнопка рисуется на экране с помощью процедуры «вывод изображения радиокнопки» и т. д.
Таким образом, существует единственное для всего перечня интерфейсных кнопок действие (вывод изображения кнопки на экран), которое реализуется специфическим для каждой кнопки способом. Это и является проявлением полиморфизма.
Объекты взаимодействуют между собой, посылая и получая сообщения.
Сообщение – это запрос на выполнение действий, содержащий набор необходимых параметров. Механизм сообщений реализуется с помощью вызова соответствующих функций. Таким образом, с помощью ООП реализуется так называемая событийно-управляемая модель.
Примером реализации может служить любая программа, управляемая с помощью меню. После запуска такая программа пассивно ожидает действия пользователей и должна уметь правильно отреагировать на любое из них. Программирование по событиям строится как противоположность традиционной (директивной) модели управления: программа после старта сама предлагает пользователю выполнить действия (ввести данные, выбрать режим) в соответствии с жёстко-заданным алгоритмом. Наступление события (например, нажатие кнопки) вызывает код обработки этого события (например, Кнопка1.ButtonClick()). Предполагается, что событие может произойти в произвольном порядке в случайные моменты времени, и программа должна уметь правильно их обрабатывать.
События и обработчики событий.
Вызов метода, взаимодействие объектов м.б. рассмотрены как отправка сообщения объекту.
Сообщение – это запрос на выполнение действий, содержащий набор необходимых параметров. Механизм сообщений реализуется с помощью вызова соответствующих функций.
Событие – это действие или инцидент обнаруженный программой.
Большинство современных приложений проектируются так, чтобы реагировать на события.
Таким образом, с помощью ООП реализуется так называемая событийно-управляемая модель.
Событие – это указатель на метод определенного экземпляра класса.
Отвечающий код – это обработчик событий, пишется разработчиком приложения.
Пример: программа, управляемая с помощью меню. После запуска программа пассивно ожидает действий пользователя и должна уметь правильно отреагировать на любое из них.
Программирование по событиям строится как противоположность традиционной (директивной) модели управления: программа после старта сама предлагает пользователю выполнить действия (ввести данные, выбрать режим) в соответствии с жёстко-заданным алгоритмом.
Наступление события (например, нажатие кнопки) вызывает код обработки этого события (например, Кнопка1.ButtonClick()). Предполагается, что событие может произойти в произвольном порядке в случайные моменты времени, и программа должна уметь правильно их обрабатывать.
4. Динамическая память. Управление памятью. Управление файлами. Организация ввода –вывода.
Динамическая память. Управление памятью.
Память для хранения данных может выделяться как статически, так и динамически. В первом случае выделение памяти выполняет компилятор, встретивший при компиляции объявление объекта. В соответствии с типом встретившегося объекта вычисляется объем памяти, требуемый для его размещения. Класс памяти задает место, где эти объекты (данные) будут располагаться. Это может быть сегмент данных либо стек. Напомним, что стек (магазин, список LIFO – Last In First Out) представляет собой последовательный список переменной длины, в котором включение и исключение элементов производится только с одной стороны. Главные операции при работе со стеком – включение и исключение элемента – осуществляются с вершины стека, причем в каждый момент доступен элемент, находящийся на вершине стека.
Часто возникают ситуации, когда заранее не известно, сколько объектов– чисел, строк текста и прочих данных будет хранить программа. В этом случае используется динамическое выделение памяти, когда память занимается и освобождается в процессе исполнения программы. При использовании динамической памяти (ДП) отпадает необходимость заранее распределять память для хранения данных, используемых программой. Управление динамической памятью – это способность определять размер объекта и выделять для его хранения соответствующую область памяти в процессе исполнения программы.
При динамическом выделении памяти для хранения данных используется специальная область памяти, так называемая «куча» (heap). Объем «кучи» и ее местоположение зависят от модели памяти, которая определяет логическую структуру памяти программы.
При каждом обращении к функции распределения памяти выделяется запрошенное число байт. Адрес начала выделенной памяти возвращается в точку вызова функции и записывается в переменную-указатель. Созданная таким образом переменная называется динамической переменной. Распределенная память гарантируется от повторного выделения при следующих обращениях за байтами памяти. Дальнейшая работа с выделенной областью осуществляется через переменную-указатель, хранящую адрес выделенной области памяти. Сама же переменная остается безымянной.
Если выделенный участок памяти больше не требуется, он может быть освобожден. При высокой активности по динамическому распределению памяти «куча» фрагментируется. Для смягчения отрицательных последствий фрагментации служат функции повторного распределения памяти. Они пытаются либо расширить, либо уменьшить размер ранее выделенного блока памяти.
Для языка С:
| Функция управления памятью | Действие | Заголовочный файл в BC++ 3.1 | Заголовочный файл в VC++ 6.0 |
| malloc() | Распределение | stdlib.h alloc.h | stdlib.h malloc.h |
| calloc() | Распределение | ||
| realloc() | Перераспределение | ||
| free() | Освобождение |
Управление файлами.
Имена файлов
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. До недавнего времени эти границы были весьма узкими. Так в популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов - собственно имя, 3 символа - расширение имени), а в ОС UNIX System V имя не может содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов. Например, Windows NT в своей новой файловой системе NTFS устанавливает, что имя файла может содержать до 255 символов, не считая завершающего нулевого символа.
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. В некоторых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно-однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе UNIX.
Типы файлов
Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги.
Обычные файлы в свою очередь подразделяются на текстовые и двоичные. Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Это могут быть документы, исходные тексты программ и т.п. Текстовые файлы можно прочитать на экране и распечатать на принтере. Двоичные файлы не используют ASCII-коды, они часто имеют сложную внутреннюю структуру, например, объектный код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов - их собственные исполняемые файлы.
Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции ввода-вывода, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством. Специальные файлы, так же как и устройства ввода-вывода, делятся на блок-ориентированные и байт-ориентированные.
Каталог - это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет), а с другой стороны - это файл, содержащий системную информацию о группе файлов, его составляющих. В каталоге содержится список файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками (атрибутами).
Физическая организация и адрес файла
Физическая организация файла описывает правила расположения файла на устройстве внешней памяти, в частности на диске. Файл состоит из физических записей - блоков. Блок - наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью. Непрерывное размещение - простейший вариант физической организации (рисунок), при котором файлу предоставляется последовательность блоков диска, образующих единый сплошной участок дисковой памяти. Для задания адреса файла в этом случае достаточно указать только номер начального блока. Другое достоинство этого метода - простота. Но имеются и два существенных недостатка. Во-первых, во время создания файла заранее не известна его длина, а значит не известно, сколько памяти надо зарезервировать для этого файла, во-вторых, при таком порядке размещения неизбежно возникает фрагментация, и пространство на диске используется не эффективно, так как отдельные участки маленького размера (минимально 1 блок) могут остаться не используемыми.
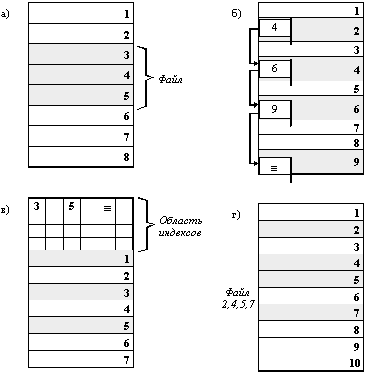 Следующий способ физической организации - размещение в виде связанного списка блоков дисковой памяти (рисунок 2.34,б). При таком способе в начале каждого блока содержится указатель на следующий блок. В этом случае адрес файла также может быть задан одним числом - номером первого блока. В отличие от предыдущего способа, каждый блок может быть присоединен в цепочку какого-либо файла, следовательно фрагментация отсутствует. Файл может изменяться во время своего существования, наращивая число блоков. Недостатком является сложность реализации доступа к произвольно заданному месту файла: для того, чтобы прочитать пятый по порядку блок файла, необходимо последовательно прочитать четыре первых блока, прослеживая цепочку номеров блоков. Кроме того, при этом способе количество данных файла, содержащихся в одном блоке, не равно степени двойки (одно слово израсходовано на номер следующего блока), а многие программы читают данные блоками, размер которых равен степени двойки.
Следующий способ физической организации - размещение в виде связанного списка блоков дисковой памяти (рисунок 2.34,б). При таком способе в начале каждого блока содержится указатель на следующий блок. В этом случае адрес файла также может быть задан одним числом - номером первого блока. В отличие от предыдущего способа, каждый блок может быть присоединен в цепочку какого-либо файла, следовательно фрагментация отсутствует. Файл может изменяться во время своего существования, наращивая число блоков. Недостатком является сложность реализации доступа к произвольно заданному месту файла: для того, чтобы прочитать пятый по порядку блок файла, необходимо последовательно прочитать четыре первых блока, прослеживая цепочку номеров блоков. Кроме того, при этом способе количество данных файла, содержащихся в одном блоке, не равно степени двойки (одно слово израсходовано на номер следующего блока), а многие программы читают данные блоками, размер которых равен степени двойки.
Общая модель файловой системы
Функционирование любой файловой системы можно представить многоуровневой моделью (рисунок), в которой каждый уровень предоставляет некоторый интерфейс (набор функций) вышележащему уровню, а сам, в свою очередь, для выполнения своей работы использует интерфейс (обращается с набором запросов) нижележащего уровня.
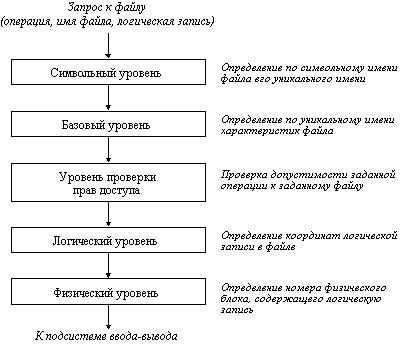 Задачей символьного уровня является определение по символьному имени файла его уникального имени. В файловых системах, в которых каждый файл может иметь только одно символьное имя (например, MS-DOS), этот уровень отсутствует, так как символьное имя, присвоенное файлу пользователем, является одновременно уникальным и может быть использовано операционной системой. В других файловых системах, в которых один и тот же файл может иметь несколько символьных имен, на данном уровне просматривается цепочка каталогов для определения уникального имени файла. В файловой системе UNIX, например, уникальным именем является номер индексного дескриптора файла (i-node).
Задачей символьного уровня является определение по символьному имени файла его уникального имени. В файловых системах, в которых каждый файл может иметь только одно символьное имя (например, MS-DOS), этот уровень отсутствует, так как символьное имя, присвоенное файлу пользователем, является одновременно уникальным и может быть использовано операционной системой. В других файловых системах, в которых один и тот же файл может иметь несколько символьных имен, на данном уровне просматривается цепочка каталогов для определения уникального имени файла. В файловой системе UNIX, например, уникальным именем является номер индексного дескриптора файла (i-node).
На следующем, базовом уровне по уникальному имени файла определяются его характеристики: права доступа, адрес, размер и другие. Как уже было сказано, характеристики файла могут входить в состав каталога или храниться в отдельных таблицах. При открытии файла его характеристики перемещаются с диска в оперативную память, чтобы уменьшить среднее время доступа к файлу. В некоторых файловых системах (например, HPFS) при открытии файла вместе с его характеристиками в оперативную память перемещаются несколько первых блоков файла, содержащих данные.
Следующим этапом реализации запроса к файлу является проверка прав доступа к нему. Для этого сравниваются полномочия пользователя или процесса, выдавших запрос, со списком разрешенных видов доступа к данному файлу. Если запрашиваемый вид доступа разрешен, то выполнение запроса продолжается, если нет, то выдается сообщение о нарушении прав доступа.
На логическом уровне определяются координаты запрашиваемой логической записи в файле, то есть требуется определить, на каком расстоянии (в байтах) от начала файла находится требуемая логическая запись. При этом абстрагируются от физического расположения файла, он представляется в виде непрерывной последовательности байт. Алгоритм работы данного уровня зависит от логической организации файла.
1 и 2 используются в тех случаях, когда все процессы целиком помещаются в памяти.
1. Схема с фиксированными разделами
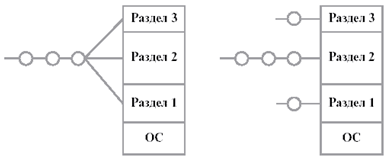 Память предварительно разбивают на несколько разделов фиксированной величины. Поступающие процессы помещаются в тот или иной раздел. При этом происходит условное разбиение физического адресного пространства. Связывание логических и физических адресов процесса происходит на этапе его загрузки в конкретный раздел, иногда – на этапе компиляции.
Память предварительно разбивают на несколько разделов фиксированной величины. Поступающие процессы помещаются в тот или иной раздел. При этом происходит условное разбиение физического адресного пространства. Связывание логических и физических адресов процесса происходит на этапе его загрузки в конкретный раздел, иногда – на этапе компиляции.
Подсистема управления памятью оценивает размер поступившего процесса, выбирает подходящий для него раздел, осуществляет загрузку процесса в этот раздел и настройку адресов.
Самый простой способ управления оперативной памятью
«–» число одновременно выполняемых процессов ограничено числом разделов.
внутренняя фрагментация – потеря части памяти, выделенной процессу, но не используемой им. Фрагментация возникает потому, что процесс не полностью занимает выделенный ему раздел или потому, что некоторые разделы слишком малы для выполняемых пользовательских программ.
2. 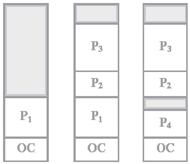 Схема с переменными разделами
Схема с переменными разделами
Вся память свободна и не разделена заранее на разделы. Вновь поступающей задаче выделяется строго необходимое количество памяти, не более.
После выгрузки процесса память временно освобождается.
Смежные свободные участки могут быть объединены.
3 стратегии размещения разделов в памяти:
Стратегия первого подходящего.
Стратегия наиболее подходящего. Где после загрузки останется меньше свободного места.
Стратегия наименее подходящего. Где останется место для еще одного процесса.
«–» внешняя фрагментация – наличие большого числа участков неиспользуемой памяти,
область может остаться не выделенной ни одному процессу. Метод наиболее подходящего может оказаться наихудшим, так как он оставляет множество мелких незанятых блоков.
Одно из решений проблемы внешней фрагментации – организовать сжатие, то есть перемещение всех занятых (свободных) участков в сторону старших (младших) адресов, так, чтобы вся свободная память образовала непрерывную область.
Сжатие требует значительного времени, алгоритм выбора стратегии сжатия очень труден и, как правило, сжатие осуществляется в комбинации с выгрузкой и загрузкой по другим адресам.
Задачи ОС:
· ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти,
· при поступлении новой задачи - анализ запроса, просмотр таблицы свободных областей и выбор раздела, загрузка задачи в выделенный ей раздел и корректировка таблиц,
· после завершения задачи – корректировка таблиц свободных и занятых областей.
3. Оверлейная структура
Так как размер логического адресного пространства процесса может быть больше, чем размер выделенного ему раздела (или больше, чем размер самого большого раздела), иногда используется оверлейная (overlay) структура (структура с перекрытием).
Основная идея – держать в памяти только те инструкции программы, которые нужны в данный момент.
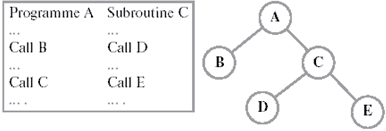 A-(B,C)
A-(B,C)
C-(D,E)
Привязка к физической памяти происходит в момент очередной загрузки одной из ветвей программы.
«+» процесс м. поместить в адр. пространство, которое < адр. пространства процесса.
«–» программист должен сам определять части программы.
4. Динамическое распределение. Свопинг
Свопинг (swapping) – перемещение процессов из главной памяти на диск и обратно целиком. Частичная выгрузка процессов на диск осуществляется в системах со страничной организацией (paging).
Выгруженный процесс может быть возвращен в то же самое адресное пространство или в другое.
Свопинг увеличивает время переключения контекста.
Время выгрузки может быть сокращено за счет организации специально отведенного пространства на диске (раздел для свопинга). Обмен с диском при этом осуществляется блоками большего размера, то есть быстрее, чем через стандартную файловую систему.
Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает.
Виртуальная память – это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
· размещает данные в ЗУ разного типа, например, часть программы в ОЗУ, а часть на диске;
· перемещает по мере необходимости данные между ЗУ разного типа, например, подгружает нужную часть программы с диска в оперативную память;
· преобразует виртуальные адреса в физические.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти.
Дата публикования: 2015-10-09; Прочитано: 406 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
