 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Поиск информации в Интернете
|
|
Для получения качественного результата при проведении поиска необходимо соблюдать ряд условий. Основными из них являются контроль полноты охвата ресурсов и достоверности найденной информации.
Прежде всего, возможность нахождения той или иной информации в Сети определяется полнотой охвата ее ресурсов. Зачастую проведение поиска требует задействования максимального объема возможных источников, в роли которых могут выступать не только web-сайты, но и базы данных, региональные телеконференции, FTP-архивы и т. д. При этом необходимым условием успешного планирования и проведения поисковых работ становится знание всех основных существующих на сегодняшний день типов ресурсов Интернета, понимание технической и тематической специфики их информационного наполнения и особенностей доступа к ним.
Наряду с полнотой охвата ресурсов, качество проводимого поиска определяется достоверностью найденной информации. Контроль ее достоверности может производиться разными способами, в которые входит нахождение и сверка с альтернативными источниками информации, установление частоты его использования другими источниками, выяснение статуса документа и сайта, на котором он находится, получение сведений о компетентности и положении автора материала и ряд других.
По способу организации и хранения информации ее источники в Интернете можно разделить на следующие основные категории:
файловые серверы — являются традиционным способом хранения данных и представляют собой компьютеры, часть дискового пространства которых доступна через Интернет. Доступ к данным на таком сервере осуществляется с помощью специальных программ, поддерживающих протокол передачи файлов — FTP. Данный протокол в общем случае требует авторизации, то есть идентификации пользователя. Для осуществления доступа к файлам со стороны произвольного пользователя Сети обычно используется так называемый анонимный вход под регистрационным именем anonymous, для которого пароль не требуется. Этот протокол поддерживается всеми стандартными браузерами;
web-сайты являются сегодня основным и наиболее распространенным типом информационных ресурсов в Сети. Сайт может содержать информацию, представленную в самой произвольной форме: графической, звуковой, видеоизображения и т. д.;
телеконференции могут являться источником необходимой информации, как правило, носящей неофициальный характер. Телеконференции представляют собой способ общения людей, имеющих доступ в Сеть, и предназначены для обсуждения каких-либо вопросов или распространения информации. Они позволяют добиться обратной связи со множеством лиц и произвести детальное обсуждение какой-либо проблемы территориально разобщенными людьми;
базы данных могут содержать самую произвольную информацию: публикации, справочную информацию, другие данные. Наиболее широко распространен способ доступа к базам данных через стандартные браузеры, так как он обеспечивает максимальную потенциальную аудиторию потребителей информации.
Признаки классификации источников информации:
Язык представления — в силу историко-географических причин наиболее распространенным языком в Интернете является английский, однако в Сети представлены практически все основные языки мира и, как отмечают исследовательские компании, их доля постоянно растет. Часто встречается ситуация, когда сайт поддерживают одновременно несколько языков — на выбор пользователя;
Географическая принадлежность домена — у информационных ресурсов обычно есть своя целевая аудитория, и ее местонахождение часто может быть сопоставлено с каким-то географическим регионом. Следует заметить, что территориальное разделение не относится к возможности доступа к ресурсам, который может быть осуществлен из любой точки земного шара;
Виду и характер представляемой информации (новости, рекламная информация, тематическая информация, справочная информация) — это наиболее важное, с практической точки зрения, разделение по виду и характеру представляемой информации, поскольку именно информационное наполнение в конечном итоге оказывается решающим при отборе источников. Например, один и тот же web-сайт может содержать информацию самых разных видов. Поэтому приведенное разделение на подгруппы в достаточной степени условно.
Инструменты поиска информации в интернет:
поисковые машины — являются ключевым инструментом поиска информации, поскольку содержат индексы большинства web-серверов Интернета. Основной недостаток: вывод чрезмерно большого количества информации по запросу, среди которой только незначительная часть является полезной и релевантной. Требуется значительный объем времени для извлечения и обработки информации.
Мета-средства поиска — позволяют ускорить выполнение запроса путем передачи аргументов поиска, то есть ключевых слов, одновременно нескольким поисковым системам. При значительном ускорении процесса и увеличении охвата поиска, этот способ имеет ряд недостатков, связанных с необходимостью координации во времени поступления результатов обработки запроса от нескольких систем, а также тем, что они не позволяют использовать возможности языка запроса каждого из применяемых поисковых средств;
Специализированные средства поиска — представляют собой «программы-пауки», которые в автоматическом режиме просматривают web-страницы, отыскивая на них нужную информацию.
Каталоги —иерархически организованная структура, в которую данные заносится по инициативе пользователей. Как следствие, объем информации в них несколько ограничен по сравнению с поисковыми системами, но в то же время более упорядочен благодаря лежащей в их основе иерархической тематической структуре.
Методы поиска информации в интернет:
· использование поисковых систем
· последовательный переход по гипертекстовым ссылкам
Наиболее широко используемым, но в то же время наиболее сложным является метод поиска с использованием поисковых систем. Его широкая распространенность обусловлена тем, что поисковые системы содержат в себе индексы большого количества сайтов и при правильно сформированном запросе можно сразу же получить ссылки на интересующие ресурсы. Сложность метода состоит в том, что для того, чтобы результат был качественным, необходимо уметь выбрать наиболее подходящие поисковые системы, правильно формулировать запросы к ним, учитывать их особенности и функциональные возможности. Двоякая характеристика данного метода связана с тем, что проведение эффективного поиска требует одновременного решения двух противоположных задач: увеличении охвата с целью извлечения максимального количества значимой информации и уменьшении охвата с целью минимизации шумовой информации.
Составление тезауруса
Для эффективного использования поисковых серверов, прежде всего необходим список ключевых слов, организованный с учетом семантических отношений между ними, то есть тезаурус.
Одним из подходов к составлению тезауруса может стать использование законов Ципфа. Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется рангом частоты. Вероятность обнаружения слова в тексте равно отношению частоты вхождения слова к числу слов в тексте. Ципф определил, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
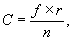
где f — частота вхождения слов, r — ранг частоты, n — число слов
Это значит, что график зависимости ранга от частоты представляет из себя равностороннюю гиперболу. Ципф также установил, что зависимость количества слов с данной частотой от частоты постоянна для всех текстов в пределах одного языка и также является гиперболой. Исследование вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой, как правило, являются предлогами, частицами, местоимениями, в английском языке — артиклями (так называемые «стоп-слова»), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Таким образом, данная особенность может помочь правильно выбрать ключевые слова для проведения поиска информации. Процедура оптимального выбора ключевых слов, основанная на применении законов Ципфа, заключается в следующем: берут любой текст-источник, близкий к искомой теме, то есть «образец», и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, web-страница, любой другой документ. Анализ текста производится в следующем порядке:
1. «стоп-слова» удаляются из текста;
2. вычисляется частота вхождения каждого слова и составляется список, в котором слова расположены в порядке убывания их частоты;
3. выбирается диапазон частот, лежащий в середине списка, и из него отбираются слова, наиболее полно соответствующие смыслу текста;
4. составляется запрос к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором OR(ИЛИ) Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов, то есть расположению их в порядке убывания частоты вхождения в документ слов запроса, применяемому в большинстве поисковых машин, на первых страницах найденных ресурсов практически все документы должны оказаться релевантными.
На основе тезауруса формируются запросы к выбранным поисковым серверам. После получения первоначальных результатов возможно уточнение запросов с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска, и данные с ресурсов, признанных релевантными, собираются для последующего анализа. Как формат, так и семантика запросов может варьироваться в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы должны составляться так, чтобы область поиска была максимально конкретизирована и сужена, то есть предпочтение следует отдавать использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится их пробная реализация — как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Языки запроса различных машин поиска в основном являются сочетанием следующих функций:
осуществление поиска документов при помощи операторов булевой алгебры:
· AND (И) — содержащих все термины, соединенные им,
· OR (ИЛИ) — искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором;
· NOT (НЕ) — поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором;
осуществление поиска документов при помощи операторов расстояния, ограничения порядка следования и расстояния между словами:
· NEAR — второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов;
· FOLLOWED BY — термины следуют в заданном порядке;
· ADJ — термины, соединенные оператором, являются смежными;
возможность усечения терминов — использование символа * вместо его окончания термина; позволяет включить в искомый список все слова, производные от его начальной части шаблона;
учет морфологии языка — машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск;
возможность поиска по словосочетанию, фразе;
ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т. д.);
ограничение по дате опубликования документа;
ограничение на количество совпадений терминов;
возможность поиска графических изображений;
чувствительность к строчным и прописным буквам.
Результат запроса, то есть выведенный системой список ссылок на найденные ресурсы, обрабатывается в два этапа. На первом этапе производится отсечение очевидно нерелевантных источников, попавших в выборку в силу несовершенства поисковой машины или недостаточной «интеллектуальности» запроса. Параллельно проводится семантический анализ, имеющий целью уточнение тезауруса для модификации последующих запросов. Дальнейшая обработка производится путем последовательного обращения на каждый из найденных ресурсов и анализа находящейся там информации.
Конечной стадией поиска является анализ ресурсов и сбор искомой информации. Первичный анализ ресурсов может основываться на аннотациях, если они есть, а при их отсутствии — на ознакомлении с информационным наполнением ресурса. Далее информация извлекается с отобранных источников и используется в соответствующих поиску целях.
3.
Дата публикования: 2015-10-09; Прочитано: 1071 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
