 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Конспект лекций по курсу операционные системы 4 страница
|
|
1. режим обмена опросом готовности устройства ввода-вывода
2. режим обмена с прерыванием
Для организации ввода-вывода по 1 варианту процессор посылает устройству управления команду для устройства ввода-вывода выполнить некоторое действие. Устройство управления выполнит команду преобразования, её сигналы управления, которое оно передает устройству ввода-вывода. Поскольку быстродействие устройства ввода-вывода меньше на несколько порядков устройства быстродействия процессора, то драйвер управляющий обилием данных с внешних устройств вынужден в цикле опрашивать готовность устройств. При этом нерационально используется время процессора. Выгоднее после команды ввода-вывода перейти на выполнение другой команды, а появление сигнала готовности трактовать как запрос на прерывание. Драйверы работающие в режиме прерывания представляют собой сложный комплекс программных модулей и имеют несколько секций:
· секция запуска
· секция продолжения
· секция завершения
Секция запуска запускается для включения устройств ввода-вывода либо для инициализации очередной операции ввода-вывода.
Секция продолжения осуществляет основную работу по передаче данных
Секция завершения выключает устройства ввода-вывода либо просто завершает операцию.
Управление операциями ввода-вывода в режиме прерывания требует более сложных программ чем те, что работают в режиме опроса готовности.
Так, в операционных системах Windows 95,98 и Windows NT драйвер печати через параллельный код работает не в режиме прерывания, а в режиме опроса готовности, что приводит к 100% загрузке процессора на все время печати. Для организации и выполнения многие параллельно выполняющиеся задачи устройств ввода-вывода вводится понятие виртуального устройства, повышающего эффективность вычислительных систем. Примером служит spooling, то есть имитация работы с устройством в режиме on-line. Главная задача spoolingа — создать единицу параллельно выполняемого устройства ввода-вывода с последовательным доступом.
4.6. Закрепление устройств, общие устройства ввода-вывода.
Как известно, многие устройства и, прежде всего, устройства с последовательным доступом не допускают совместного использования. Такие устройства могут стать закрепленными за процессом, то есть их можно предоставить некоторому вычислительному процессу на все время жизни этого процесса. Однако это приводит к тому, что вычислительные процессы часто не могут выполняться параллельно — они ожидают освобождения устройств ввода-вывода. Чтобы организовать совместное использование многими параллельно выполняющимися задачами тех устройств ввода-вывода, которые не могут быть разделяемыми, вводится понятие виртуальных устройств. Принцип виртуализации позволяет повысить эффективность вычислительной системы.
Вообще говоря, понятие виртуального устройства шире, нежели понятие спулинга spooling — Simultaneous Peripheral Operation On-Line, то есть имитация работы с устройством в режиме непосредственного подключения к нему. Основное назначение спулинга — создать видимость разделения устройства ввода-вывода, которое фактически является устройством с последовательным доступом и должно использоваться только монопольно и быть закрепленным за процессом. Например, мы уже говорили, что в случае, когда несколько приложений должны выводить на печать результаты своей работы, если разрешить каждому такому приложению печатать строку по первому же требованию, то это приведет к потоку строк не представляющих никакой ценности. Однако если каждому вычислительному процессу предоставлять не реальный, а виртуальный принтер, и поток выводимых символов или управляющих кодов для их печати сначала направлять в специальный файл на диске так называемый спул-файл — spool-file и только потом, по окончании виртуальной печати, в соответствии с принятой дисциплиной обслуживания и приоритетами приложений выводить содержимое спул-файла на принтер, то все результаты работы можно будет легко читать. Системные процессы, которые управляют спул-файлом, называются спулером чтения spool-reader или спулером записи spool-writer.
Достаточно рационально организована работа с виртуальными устройствами в системах Windows 9xNT2000XP компании Microsoft. В качестве примера можно кратко рассмотреть подсистему печати. Microsoft различает термины принтер и устройство печати. Принтер — это некоторая виртуализация, объект операционной системы, а устройство печати — это физическое устройство, которое может быть подключено к компьютеру. Принтер может быть локальным или сетевым. При установке локального принтера в операционной системе создается новый объект, связанный с реальным устройством печати через тот или иной интерфейс. Интерфейс может быть и сетевым, то есть передача управляющих кодов в устройство печати может осуществляться через локальную вычислительную сеть, однако принтер все равно будет считаться локальным.
Локальность принтера означает, что его спул-файл будет находиться на том же компьютере, что и принтер. Если же некоторый локальный принтер предоставить в сети в общий доступ с теми или иными разрешениями, то для других компьютеров и их пользователей он может стать сетевым, Компьютер, на котором имеется локальный принтер, предоставленный в общий доступ, называется принт-сервером.
4.7. Основные системные таблицы ввода-вывода
Организация ввода-вывода требует наличия информации о ресурсах устройствах и их состоянии. Эта информация обычно хранится в системных таблицах, основными из которых являются:
- таблица оборудования ET — eguipment table, список УВВ, подключенных к системе
- таблица виртуальных логических устройств DRT — device reference table
- таблица прерываний IT — interrupt table.
Отдельный элемент первой таблицы называется блоком управления соответствующим устройством обмена UCB — unit control block и содержит следующую информацию об устройстве:
- тип, модель, имя и характеристики устройства
- характеристики подключения тип интерфейса, порт, линия запроса прерывания
- указание на драйвер управления и адреса его секций
- наличие и адрес буфера обмена для устройства
- уставка тайм-аута и адрес ячейки хранения счетчика тайм-аута
- состояние устройства
- дескриптор задачи, использующий устройство в данный момент времени и т.п.
Вторая таблица DRT избавляет программиста от необходимости знания конкретных параметров устройства. Обращаясь к логическому имени устройства, программист посредством таблицы описания виртуальных логических устройств устанавливает связь с конкретным устройством. Т.о., эта таблица перенаправляет запрос ввода-вывода на те модули и структуры данных, которые хранятся в соответствующем элементе первой таблицы.
Третья таблица IT для каждого запроса на прерывание указывает UCB, сопоставленный этому запросу.
Взаимосвязи названных системных таблиц показаны на рис. 24.
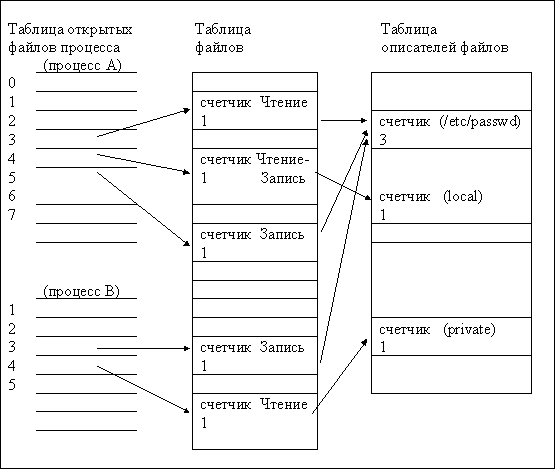
Рис. 24. Взаимосвязь системных таблиц ввода-вывода
Запрос на ввод-вывод от выполняющейся программы поступает на супервизор программ действие 1. Он проверяет вызов на соответствие принятым спецификациям. В случае корректности запроса он перенаправляется в супервизор ввода-вывода действие 2, иначе задаче возвращается соответствующее сообщение действие 1-1.
Супервизор ввода-вывода по логическому виртуальному имени таблицы DRT находит соответствующий элемент UCB в таблице оборудования. Если устройство занято, то описатель задачи помещается в очередь к устройству, иначе запускается препроцессор ввода-вывода. Он формирует последовательность управляемых кодов и данных для устройства ввода-вывода. Когда последовательность сформирована, супервизор ввода-вывода передает управление соответствующему драйверу в секции запуска действие 3.
Драйвер инициирует операцию управления, обнуляет счетчик тайм-аута и возвращает управление диспетчеру задач для постановки задачи на процессор действие 4.
По окончании обработки команды ввода-вывода устройство ввода-вывода выставляет сигнал запроса прерывания, по которому управление передается секции продолжения действие 5.
Получив новую команду, УВВ вновь ее обрабатывает, а управление процессором вновь передаётся диспетчеру задач, и процессор продолжает вычисления. Таким образом реализуется параллельная обработка задач, на фоне которой происходит управление вводом-выводом.
4.8. Синхронный и асинхронный ввод вывод
Задача, выдавшая запрос на операцию ввода-вывода, переводится супервизором в состояние ожидания завершения заказанной операции. Когда супервизор получает от секции завершения сообщение о том, что операция завершилась, он переводит задачу в состояние готовности к выполнению, и она продолжает выполняться. Эта ситуация соответствует синхронному вводу-выводу. Синхронный ввод-вывод является стандартным для большинства операционных систем. Чтобы увеличить скорость выполнения приложений, было предложено при необходимости использовать асинхронный ввод-вывод.
Простейшим вариантом асинхронного вывода является так называемый буферизованный вывод данных на внешнее устройство, при котором данные из приложения передаются не непосредственно на устройство ввода-вывода, а в специальный системный буфер — область памяти, отведенную для временного размещения передаваемых данных. В этом случае логически операция вывода для приложения считается выполненной сразу же, и задача может не ожидать окончания действительного процесса передачи данных на устройство. Реальным выводом данных из системного буфера занимается супервизор ввода-вывода. Естественно, что выделение буфера из системной области памяти берет на себя специальный системный процесс по указанию супервизора ввода-вывода. Итак, для рассмотренного случая вывод будет асинхронным, если, во-первых, в запросе на ввод-вывод указано на необходимость буферизации данных, а во-вторых, устройство ввода-вывода допускает такие асинхронные операции, и это отмечено в UCB.
Можно организовать и асинхронный ввод данных. Однако для этого необходимо не только выделять область памяти для временного хранения считываемых с устройства данных и связывать выделенный буфер с задачей, заказавшей операцию, но и сам запрос на операцию ввода-вывода разбивать на две части на два запроса, о первом запросе указывается операция на считывание данных, подобно тому как это делается при синхронном вводе-выводе, однако тип код запроса используется другой, и в запросе указывается еще по крайней мере один дополнительный Параметр — имя код системного объекта, которое получает задача в ответ на запрос и которое идентифицирует выделенный буфер. Получив имя буфера будем ак условно называть этот системный объект, хотя в различных операционных истемах используются и другие термины, например класс, задача продолжает свою работу. Здесь очень важно подчеркнуть, что в результате запроса на асинхронный ввод данных задача не переводится супервизором ввода-вывода в состояние ожидания завершения операции ввода-вывода, а остается в состоянии выполнения или в состоянии готовности к выполнению. Через некоторое время выполнив необходимый код, который был определен программистом, задача выдает второй запрос на завершение операции ввода-вывода. В этом втором запросе к тому же устройству, который, естественно, имеет другой код или имя запроса, задача указывает имя системного объекта буфера для асинхронного ввода данных и в случае успешного завершения операции считывания данных тут же получает их из системного буфера. Если же данные еще не успели до конца переписаться с внешнего устройства в системный буфер, супервизор ввода-вывода переводит задачу в состояние ожидания завершения операции ввода-вывода, и далее все напоминает обычный синхронный ввод данных.
Асинхронный ввод-вывод характерен для большинства мультипрограммных операционных систем, особенно если операционная система поддерживает мультизадачность с помощью механизма потоков выполнения. Однако если асинхронный ввод-вывод в явном виде отсутствует, его можно реализовать самому, организовав для вывода данных отдельный поток выполнения.
Аппаратуру ввода-вывода можно рассматривать как совокупность аппаратных процессоров, которые способны работать параллельно друг другу, а также параллельно центральному процессору процессорам. На таких процессорах выполняются так называемые внешние процессы. Например, для печатающего устройства внешнее устройство вывода данных внешний процесс может представлять собой совокупность операций, обеспечивающих перевод печатающей головки, продвижение бумаги на одну позицию, смену цвета чернил или печать каких-то символов. Внешние процессы, используя аппаратуру ввода-вывода, взаимодействуют как между собой, так и с обычными программными процессами, выполняющимися на центральном процессоре. Важным при этом является обстоятельство, что скорости выполнения внешних процессов будут существенно порой на порядок или больше отличаться от скорости выполнения обычных {внутренних процессов. Для своей нормальной работы внешние и внутренние процессы обязательно должны синхронизироваться. Для сглаживания эффекта значительного несоответствия скоростей между внутренними и внешними процессами используют упомянутую выше буферизацию. Таким образом, можно говорить о системе параллельных взаимодействующих процессов см. главу 7.
Буферы буфер являются критическим ресурсом в отношении внутренних программных и внешних процессов, которые при параллельном своем развитии информационно взаимодействуют. Через буферы данные либо посылаются от некоторого процесса к адресуемому внешнему операция вывода данных на внешнее устройство, либо от внешнего процесса передаются некоторому программному процессу операция считывания данных. Введение буферизации как средства информационного взаимодействия выдвигает проблему управления этими системными буферами, которая решается средствами супервизорной части операционной системы. При этом на супервизор возлагаются задачи не только по выделению и освобождению буферов в системной области памяти, но и по синхронизации процессов в соответствии с состоянием операций заполнения или освобождения буферов, а также по их ожиданию, если свободных буферов в наличии нет, а запрос на ввод-вывод требует буферизации. Обычно супервизор ввода-вывода для решения перечисленных задач использует стандартные средства синхронизации, принятые в данной операционной системе. Поэтому если операционная система имеет развитые средства для решения проблем параллельного выполнения взаимодействующих приложений и задач, то, как правило, она реализует и асинхронный ввод-вывод.
4.9. Организация внешней памяти на магнитных дисках
Магнитные диски представляют собой пакеты магнитных пластин поверхностей, между которыми на одном рычаге двигается пакет магнитных головок рис. 1.1. Шаг движения пакета головок является дискретным, и каждому положению пакета головок логически соответствует цилиндр пакета магнитных дисков. На каждой поверхности цилиндр высекает дорожку, так что каждая поверхность содержит число дорожек, равное числу цилиндров. При разметке магнитного диска специальном действии, предшествующем использованию диска каждая дорожка размечается на одно и то же количество блоков; таким образом, предельная емкость каждого блока составляет одно и то же число байтов. Для задания обмена с магнитным диском на уровне аппаратуры нужно указать номер цилиндра, номер поверхности, номер блока на соответствующей дорожке и число байтов, которое нужно записать или прочитать от начала этого блока.
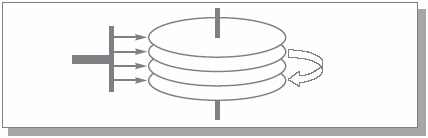
Рис. 1.1. Грубая схема дискового устройства памяти с подвижными головками
При выполнении обмена с диском аппаратура выполняет три основных действия: подвод головок к нужному цилиндру обозначим время выполнения этого действия как tпг, поиск на дорожке нужного блока время выполнения — tпб и собственно обмен с этим блоком время выполнения — tоб. Тогда, как правило, tпгtпбtоб, потому что подвод головок — это механическое действие, причем в среднем нужно переместить головки на расстояние, равное половине радиуса поверхности, а скорость передвижения головок не может быть слишком большой по физическим соображениям. Поиск блока на дорожке требует прокручивания пакета магнитных дисков в среднем на половину длины внешней окружности; скорость вращения диска может быть существенно больше скорости движения головок, но она тоже ограничена законами физики. Для выполнения же собственно чтения или записи нужно прокрутить пакет дисков всего лишь на угловое расстояние, соответствующее размеру блока. Таким образом, из всех этих действий в среднем наибольшее время занимает первое, и поэтому существенный выигрыш в суммарном времени обмена при считывании или записи только части блока получить практически невозможно.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной и внешней памятью с помощью программно-аппаратных средств низкого уровня машинных команд или вызовов соответствующих программ операционной системы. Такой режим работы не позволял или очень затруднял поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
4.10. Кэширование операций ввода вывода при работе с накопителями на магнитных дисках
Как известно, накопители на магнитных дисках обладают крайне низкой скоростью по сравнению с быстродействием центральной части компьютера. Разница в быстродействии отличается на несколько порядков. Например, современные процессоры за один такт работы, а они работают уже с частотами в 1 ГГц и более, могут выполнять по две операции. Таким образом, время выполнения операции с позиции внешнего наблюдателя, не видящего конвейеризации при выполнении, машинных команд, благодаря которой производительность возрастает в несколько раз может составлять 0,5 нс!. В то же время переход магнитной головки с дорожки на дорожку составляет несколько миллисекунд. Такие же временные интервалы имеют место и при ожидании, пока под головкой чтения записи не окажется нужный сектор данных. Как известно, в современных приводах средняя длительность на чтение случайным образом выбранного сектора данных составляет около 20 мс, что существенно медленнее, чем выборка команды или операнда из оперативной памяти и уж тем более из кэша. Правда, после этого данные читаются большим пакетом сектор, как мы уже говорили, имеет размер в 512 байтов, а при операциях с диском часто читается или записывается сразу несколько секторов. Таким образом, средняя скорость работы процессора с оперативной памятью на 2-3 порядка выше, чем средняя скорость передачи данных из внешней памяти на магнитных дисках в оперативную память.
Для того чтобы сгладить такое сильное несоответствие в производительности основных подсистем, используется буферирование иили кэширование данных. Простейшим вариантом ускорения дисковых операций чтения данных можно считать использование двойного буферирования. Его суть заключается в том, что пока в один буфер заносятся данные с магнитного диска, из второго буфера ранее считанные данные могут быть прочитаны и переданы запросившей их задаче. Аналогичный процесс происходит и при записи данных. Буферирование используется во всех операционных системах, но помимо буферирования применяется и кэширование. Кэширование исключительно полезно в том случае, когда программа неоднократно читает с диска одни и те же данные. После того как они один раз будут помещены в кэш, обращений к диску больше не потребуется и скорость работы программы значительно возрастет.
Если не вдаваться в подробности, то под кэшем можно понимать некий пул буферов, которыми мы управляем с помощью соответствующего системного процесса. Если мы считываем какое-то множество секторов, содержащих записи того или иного файла, то эти данные, пройдя через кэш, там остаются до тех пор, пока другие секторы не заменят эти буферы. Если впоследствии потребуется повторное чтение, то данные могут быть извлечены непосредственно из оперативной памяти без фактического обращения к диску. Ускорить можно и операции записи: данные помещаются в кэш, и для запросившей эту операцию задачи можно считать, что они уже фактически и записаны. Задача может продолжить свое выполнение, а системные внешние процессы через некоторое время запишут данные на диск. Это называется операцией отложенной записи lazy write, ленивая запись. Если отложенная запись отключена, только одна задача может записывать на диск свои данные. Остальные приложения должны ждать своей очереди. Это ожидание подвергает информацию риску не меньшему если не большему, чем отложенная запись, которая к тому же и более эффективна по скорости работы с диском.
Интервал времени, после которого данные будут фактически записываться, с одной стороны, желательно выбрать больше, поскольку если потребуется еще раз прочитать эти данные, то они уже и так фактически находятся в кэше. И после модификации эти данные опять же помещаются в быстродействующий кэш. С другой стороны, для большей надежности данные желательно поскорее отправить во внешнюю память, поскольку она энергонезависима и в случае какой-нибудь аварии например, нарушения питания данные в оперативной памяти пропадут, в то время как на магнитном диске они с большой вероятностью останутся в безопасности. Количество буферов, составляющих кэш, ограничено, поэтому возникает ситуация, когда вновь прочитанные или записываемые новые секторы данных должны будут заменить данные в этих буферах. Возможно использование различных дисциплин, в соответствии с которыми будет назначен какой-либо буфер под вновь затребованную операцию кэширования.
Кэширование дисковых операций может быть существенно улучшено за счет введения техники упреждающего чтения read ahead. Она основана на чтении с диска гораздо большего количества данных, чем на самом деле запросила операционная система или приложение. Когда некоторой программе требуется считать с диска только один сектор, программа кэширования читает еще и несколько дополнительных блоков данных. А операции последовательного чтения нескольких секторов фактически несущественно замедляют операцию чтения затребованного сектора с данными. Поэтому, если программа вновь обратится к диску, вероятность того, что нужные ей данные уже находятся в кэше, достаточно высока. Поскольку передача данных из одной области памяти в другую происходит во много раз быстрее, чем чтение их с диска, кэширование существенно сокращает время выполнения операций с файлами.
Итак, путь информации от диска к прикладной программе пролегает как через буфер, так и через файловый кэш. Когда приложение запрашивает с диска данные, программа кэширования перехватывает этот запрос и читает вместе с необходимыми секторами еще и несколько дополнительных. Затем она помещает в буфер требующуюся задаче информацию и ставит об этом в известность операционную систему. Операционная система сообщает задаче, что ее запрос выполнен и данные с диска находятся в буфере. При следующем обращении приложения к диску программа кэширования прежде всего проверяет, не находятся ли уже в памяти затребованные данные. Если это так, то она копирует их в буфер; если же их в кэше нет, то запрос на чтение диска передается операционной системе. Когда задача изменяет данные в буфере, они копируются в кэш.
В ряде ОС имеется возможность указать в явном виде параметры кэширования, в то время как в других за эти параметры отвечает сама ОС. Так, например, в системе Windows NT нет возможности в явном виде управлять ни объемом файлового кэша, ни параметрами кэширования. В системах Windows 9598 такая возможность уже имеется, но она представляет не слишком богатый выбор. Фактически мы можем указать только объем памяти, отводимый для кэширования, и объем порции данных буфер или chunk, из которых набирается кэш. В файле System.ini есть возможность в секции [VCACHE] прописать, например, следующие значения:
[vcache]
MinFileCache=4096
MaxFileCache-32768
ChunkSize=512
Здесь указано, что минимально под кэширование данных зарезервировано 4 Мбайт оперативной памяти, максимальный объем кэша может достигать 32 Мбайт, а размер данных, которыми манипулирует менеджер кэша, равен одному сектору.
В других ОС можно указывать больше параметров, определяющих работу подсистемы кэширования.
Помимо описанных действий ОС может выполнять и работу по оптимизации перемещения головок чтениязаписи данных, связанного с выполнением запросов от параллельно выполняющихся задач. Время, необходимое на получение данных с магнитного диска, складывается из времени перемещения магнитной головки на требуемый цилиндр и времени ожидания заданного сектора; временем считывания найденного сектора и затратами на передачу этих данных в оперативную память мы можем пренебречь. Таким образом, основные затраты времени уходят на поиск данных. В мультипрограммных ОС при выполнении многих задач запросы на чтение и запись данных могут идти таким потоком, что при их обслуживании образуется очередь. Если выполнять эти запросы в порядке поступления их в очередь, то вследствие случайного характера обращений к тому или иному сектору магнитного диска мы можем иметь значительные потери времени на поиск данных. Напрашивается очевидное решение: поскольку выполнение переупорядочивания запросов с целью минимизации затрат времени на поиск данных можно выполнить очень быстро практически этим временем можно пренебречь, учитывая разницу в быстродействии центральной части и устройств ввода-вывода, то необходимо найти метод, позволяющий перестраивать очередь запросов оптимальным образом. Изучение этой проблемы позволило найти наиболее эффективные дисциплины планирования.
Перечислим известные дисциплины, в соответствии с которыми можно перестраивать очередь запросов на операции чтения записи данных:
STF shortest seek time — first — с наименьшим временем поиска — первым. В соответствии с этой дисциплиной при позиционировании магнитных головок следующим выбирается запрос, для которого необходимо минимальное перемещение с цилиндра на цилиндр, даже если этот запрос не был первым в очереди на вводвывод. Однако для этой дисциплины характерна резкая дискриминация определенных запросов, а ведь они могут идти от высокоприоритетных задач. Обращения к диску проявляют тенденцию концентрироваться, в результате чего запросы на обращение к самым внешним и самым внутренним дорожкам могут обслуживаться. Существенно дольше и нет никакой гарантии обслуживания. Достоинством такой дисциплины является максимально возможная пропускная способность дисковой подсистемы.
can сканирование. По этой дисциплине головки перемещаются то в одном, то в другом привилегированном направлении, обслуживая по пути подходящие запросы. Если при перемещении головок чтения-записи более нет попутных запросов, то движение начинается в обратном направлении.
ext-Step Scan — отличается от предыдущей дисциплины тем, что на каждом проходе обслуживаются только запросы, которые уже существовали на момент начала прохода. Новые запросы, появляющиеся в процессе перемещения головок чтениязаписи, формируют новую очередь запросов, причем таким образом, чтобы их можно было оптимально обслужить на обратном ходу.
C-Scan циклическое сканирование. По этой дисциплине головки перемещаются циклически с самой наружной дорожки к внутренним, по пути обслуживая имеющиеся запросы, после чего вновь переносятся к наружным цилиндрам. Эту дисциплину иногда реализуют таким образом, чтобы запросы, поступающие во время текущего прямого хода головок, обслуживались не попутно, а при следующем ходе, что позволяет исключить дискриминацию запросов к самым крайним цилиндрам; она характеризуется очень малой дисперсией времени ожидания обслуживания. Эту дисциплину обслуживания часто называют элеваторной.
5. Принципы построения и классификация
5.1. Принципы построения
Принцип модульности
Модуль — функционально значимый элемент системы, обладающий установленным межмодульным интерфейсом. Последний предполагает возможность замены его любым другим модулем, обладающим таким же интерфейсом.
Принцип модульности даёт максимальный эффект, если он распространяется на ОС, прикладные программы и аппаратуру.
Принцип функциональной избирательности
Некоторая часть модулей ОС должна частично находиться в памяти для более эффективной организации вычислительного процесса. Она называется ядром ОС. К ядру предъявляются требования минимальности требуемого объема памяти и наиболее часто используемым функциям. К ядру, как правило, относят модули управления системой прерываний, управления задачами, модули управления ресурсами.
Остальные модули ОС называются транзитными или диск-резидентными. Они загружаются в память по необходимости, а при отсутствии свободного пространства памяти замещаются другими, более необходимыми в данный момент.
Принцип генерируемости
Суть его в том, что способ исходного представления ядра ОС должен позволять настройку его на непосредственную конфигурацию вычислительного комплекса на круг решаемых задач. Процесс генерации осуществляется программой генерации ОС с использованием соответствующего программного языка, позволяющего описывать программные возможности системы и конфигурацию машины. В результате генерируется полная рабочая версия ОС.
Использование принципа модульности упрощает настройку ОС.
В большинстве современных ОС для персональных компьютеров конфигурирование под имеющийся состав оборудования производится на этапе инсталляции, а последующие изменения параметров ОС или состава драйверов производятся редактированием файла конфигурации.
Единственной ОС, генерируемой в полном смысле является ОС Linux. В ней можно сгенерировать ядро, оптимальное для данного компьютера и указать набор подгружаемых драйверов и служб.
Принцип функциональной избыточности
Он учитывает возможность выполнения одной и той же работы различными средствами. Наличие возможности использования нескольких типов мониторов или планировщиков ресурсов, систем управления файлами и т.д. позволяет быстро и адекватно адаптировать ОС к данной конфигурации вычислительной системы, эффективно загружать технические средства, получить максимальную производительность.
Принцип виртуализации
Он позволяет представить структуру системы в виде набора планировщиков процессов и распределителей ресурсов и использовать единую схему распределения ресурсов. Наиболее полно принцип проявляется в понятии виртуальной машины машины вообще, обладающей идеальными для пользователя архитектурными характеристиками:
Дата публикования: 2015-10-09; Прочитано: 586 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
