 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Выводы по теме. 1. Приведены методы обработки, кодирования и анализа изображений
|
|
1. Приведены методы обработки, кодирования и анализа изображений.
2. Рассмотрено выделение признаков на изображении.
Вопросы для самопроверки
1. Назовите две основные категории улучшения изображений.
2. Что такое Двумерное дискретное преобразование Фурье?
3. Опишите метод обработки изображений – гомоморфная фильтрация.
4. Какие пространственные методы обработки изображений вы знаете?
5. Перечислите основные методы кодирования изображений.
6. В чем суть сжатия данных по методу JPEG?
7. Опишите алгоритм решения задачи сравнения изображений по форме с использованием морфологической проекции.
Тема 16. Моделирование системы распознавания речи
План лекции
16.1. Скрытые марковские модели в задачах распознавания речи.
16.2. Языковые модели.
Скрытые марковские модели в задачах распознавания речи
Применение методов статистической теории распознавания образов стало важным этапом в развитии автоматического распознавания речи (АРР). Практически все наиболее известные системы распознавания речи, созданные за последние двадцать пять лет основаны на статистических принципах и используют аппарат СММ.
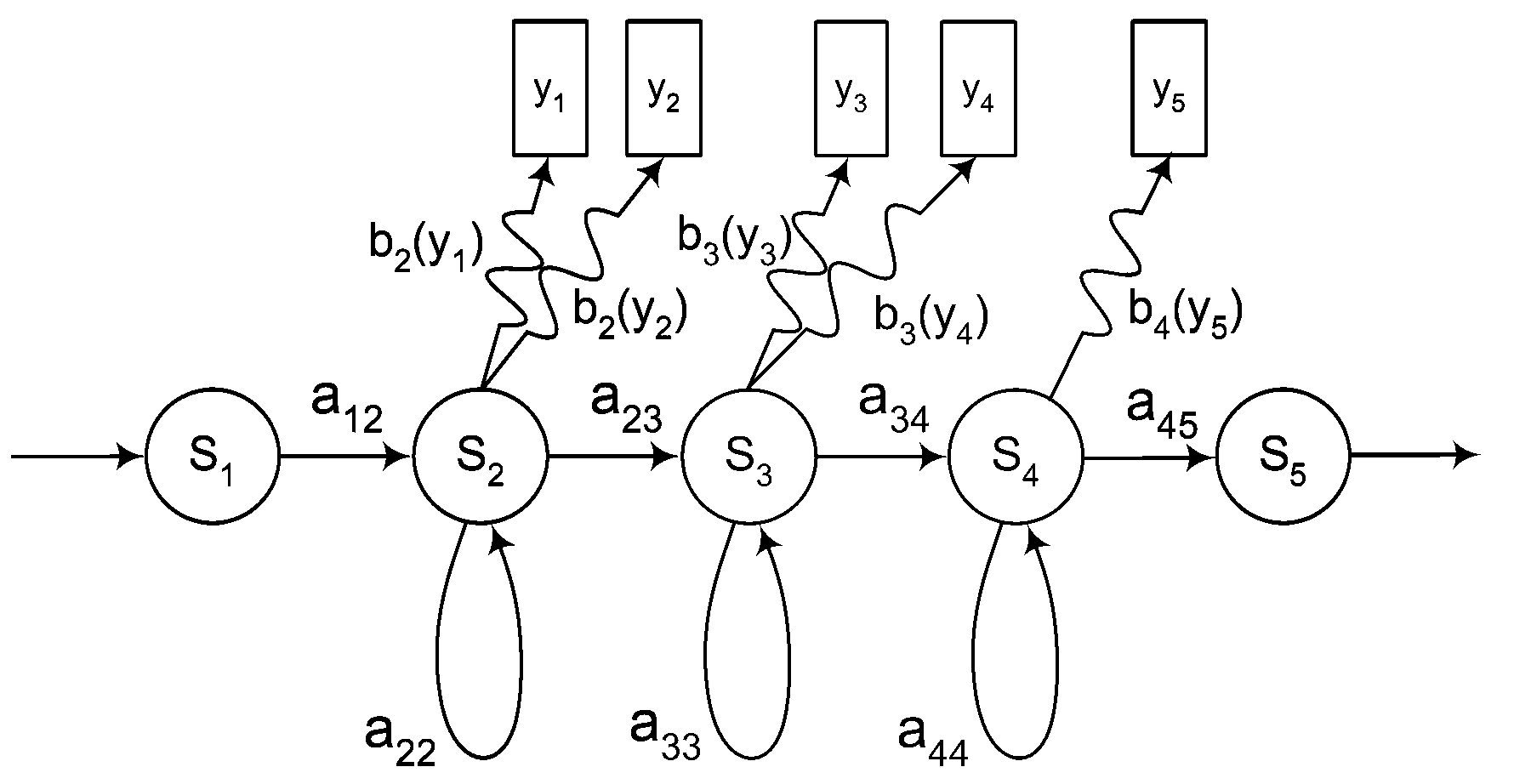
Рассмотрим пример марковской модели для звука, которая изображена на рисунке 16.1.
|
| Рисунок 16.1 – Пример скрытой марковской модели |
Эта модель состоит из последовательности состояний, обозначенных S 1, S 2,..., S 5, которые связаны мгновенными вероятностными переходами, изображенные стрелками и имеющие вероятность aij, т.е. вероятность перехода из i -го состояния в j-e. Возможны переходы только в следующее состояние и зацикливание. В каждый момент времени модель осуществляет вероятностный переход из одного состояния в другое или в то же самое состояние, при этом происходит излучение выходного акустического вектора yk с выходным вероятностным распределением bn (yk), соответствующим этому состоянию. Эти вероятности называют эмиссионными вероятностями. Некоторое высказывание, описываемое последовательностью акустических векторов параметров X = { x 1 ,x 2 ,...,xn }, можно промоделировать последовательностью дискретных стационарных состояний Q = { q 1, q 2,..., qk }. К < N, с мгновенными переходами между этими состояниями и последовательностью излученных при этом акустических векторов
Y = {y1,y2,...,yN}.
Таким образом, скрытая марковская модель состоит из марковской цепи с конечным числом состояний Sn и матрицей переходных (транзитивных) вероятностей которые определяют длительность пребывания системы в данном состоянии, т. е. марковская цепь моделирует временные изменения речевого сигнала, а также конечного множества эмиссионных вероятностей bп (yk), которые позволяют моделировать спектральные вариации сигнала. Этот подход определяет два одновременных стохастических процесса, один из которых является основным и ненаблюдаемым (т. е. скрытым) это последовательность СММ-состояний, и судить о нем можно только с помощью другого случайного процесса, т. е. по последовательности наблюдений (собственно, поэтому такая модель называется «скрытой» марковской моделью).
Рассмотрим простую систему распознавания. Идеально было бы иметь СММ для каждого из возможных высказываний. Однако, очевидно, что это выполнимо только для очень ограниченных задач, например распознавание изолированных команд из небольшого словаря. Поэтому используют более мелкие речевые единицы, например фоны, которые с лингвистической точки зрения соответствуют фонемам. Для каждого фона необходимо создать свою отдельную СММ, т. е. М = { m 1, m 2 mU } – множество марковских моделей для всех возможных фонов, а Θ = { λ 1, λ 2,..., λU } – множество связанных с ними параметров. Тогда Mi будет представлять марковскую модель некоторого слова, полученную конкатенацией элементарных моделей из множества М, при этом Мi состоит из Li состояний 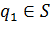 и l = 1, 2,..., Li, а множество параметров этой модели будет Δ i, которое является подмножеством Θ. Произнесение каждого фона описывается последовательностью векторов спектральных характеристик сигнала. На этапе обучения для каждого слова, например, имеется последовательность, состоящая из множества повторений последовательностей векторов параметров ХMi, соответствующих произнесению этого слова одним или несколькими дикторами и необходимо выбрать такое множество параметров Θ, которое максимизировало вероятность Р (Мi|XМi, Θ) для всех обучающих высказываний XМi, связанных с Mi, т. е.
и l = 1, 2,..., Li, а множество параметров этой модели будет Δ i, которое является подмножеством Θ. Произнесение каждого фона описывается последовательностью векторов спектральных характеристик сигнала. На этапе обучения для каждого слова, например, имеется последовательность, состоящая из множества повторений последовательностей векторов параметров ХMi, соответствующих произнесению этого слова одним или несколькими дикторами и необходимо выбрать такое множество параметров Θ, которое максимизировало вероятность Р (Мi|XМi, Θ) для всех обучающих высказываний XМi, связанных с Mi, т. е.
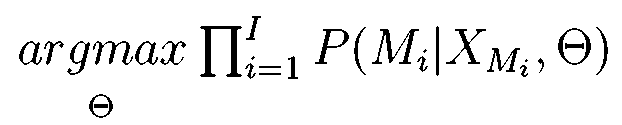 (16.1)
(16.1)
Таким образом, обучение состоит в подборе параметров модели Θ в соответствии с некоторым критерием оптимальности. К сожалению, не существует известного аналитического выражения для этих параметров. Кроме того, на практике, располагая некоторой последовательностью наблюдений в качестве обучающих данных, нельзя указать оптимальный способ оценки параметров. Однако, используя итеративные процедуры, например алгоритм Наума-Уэлча или, что эквивалентно, ЕМ-метод (метод математического ожидания-модификации), или градиентные методы, можно подобрать параметры модели таким образом, чтобы локально максимизировать вероятность 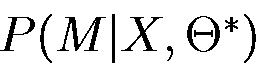 . Следует отметить, что эти алгоритмы принадлежат классу алгоритмов обучения «без учителя», так как они производят ненаблюдаемую оценку параметров распределения вероятностей, не требуя предварительной разметки. На этапе распознавания неизвестного высказывания X необходимо найти наиболее подходящую модель Mi, которая максимизировала
. Следует отметить, что эти алгоритмы принадлежат классу алгоритмов обучения «без учителя», так как они производят ненаблюдаемую оценку параметров распределения вероятностей, не требуя предварительной разметки. На этапе распознавания неизвестного высказывания X необходимо найти наиболее подходящую модель Mi, которая максимизировала 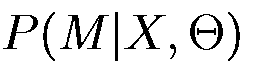 при уже фиксированном множестве параметров Θ и наблюдаемой в данный момент последовательности X. Таким образом, результатом распознавания высказывания X будет слово, связанное с моделью Mi такое, что:
при уже фиксированном множестве параметров Θ и наблюдаемой в данный момент последовательности X. Таким образом, результатом распознавания высказывания X будет слово, связанное с моделью Mi такое, что:
 (16.2)
(16.2)
Метод нахождения наилучшей модели основан на динамическом программировании и называется алгоритмом Витерби.
Обучение и распознавание связано с выбором некоторого критерия оптимальности. Таких критериев существует несколько. Все они имеют физический смысл и используются на практике. Выбранный критерий оптимальности (например, максимум правдоподобия или максимум апостериорной вероятности) оказывает влияние на такие параметры модели, как объем данных для обучения и требования к вычислительным ресурсам, точность распознавания, способность к обобщению данных из обучающей выборки. Одним из наилучших критериев может считаться Байесовский классификатор, основанный на апостериорной вероятности P (Mi|X,Θ) (или классификатор по максимуму апостериорной вероятности, МАР-оцениватель) того, что последовательность акустических векторов X была порождена Mi моделью с множеством параметров Θ. Используя правило Байеса P (Mi|Х, Θ), можно записать в виде выражения:
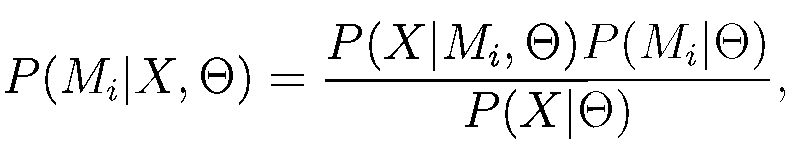 (16.3)
(16.3)
которое разделяет процесс оценки вероятности на две части: задачу акустического (16.4) и языкового P (Mi |Θ) моделирования.
 (16.4)
(16.4)
Целью языкового моделирования является оценка априорных вероятностей моделей высказываний P (Mi |Θ). Эта языковая модель обычно полагается независимой от акустических моделей и описывается в терминах независимого множества параметров Θ*. Параметры языковой модели обычно оцениваются на больших текстовых базах данных.
Задачей акустического моделирования является оценка плотностей вероятностей (16.4), как правило, независимо от других моделей. Так как вероятность P (X|Mi, Θ) обусловлена только Mi, то она зависит только от параметров Mi модели и, опуская Р (Х |Θ) выражение (16.4) можно переписать как Р (Х | Мi, Δ i), где Δ i - множество параметров, связанных с моделью Mi. Таким образом, и обучение, и распознавание требует оценки вероятности P(X\Mi, Ai), которая называется глобальным правдоподобием последовательности векторов параметров X при заданной Mi.
Далее P (X|Mi, Δ i) можно оценить как сумму:
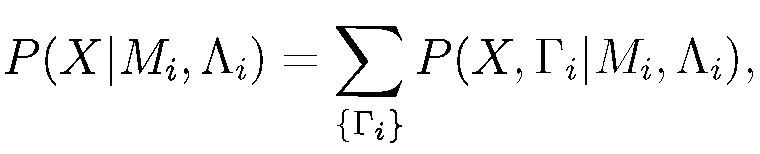 (16.5)
(16.5)
где {Г i } представляет собой множество всех возможных путей (последовательности состояний) длины L в модели М i. При этом для каждой последовательности состояний вероятность появления последовательности наблюдений X 1L = { x 1, x 2 ,...xL } определяется выражением:
 (16.6)
(16.6)
Можно показать, что (16.5) можно вычислить с помощью алгоритма прямого-обратного хода, для которого необходимо рекурсивно вычислять так называемую прямую переменную:
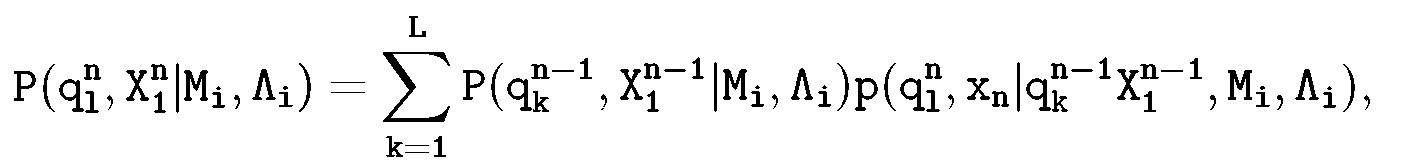 (16.7)
(16.7)
где 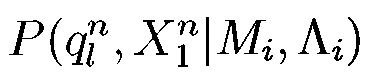 представляет собой вероятность того, что частичная подпоследовательность наблюдений
представляет собой вероятность того, что частичная подпоследовательность наблюдений 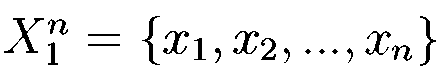 была порождена моделью Mi, а в момент времени п наблюдалось состояние
была порождена моделью Mi, а в момент времени п наблюдалось состояние 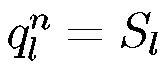 и был сгенерирован вектор наблюдений хп.
и был сгенерирован вектор наблюдений хп.
Второй сомножитель в правой части равенства (10) можно представить в виде произведения вероятностей:
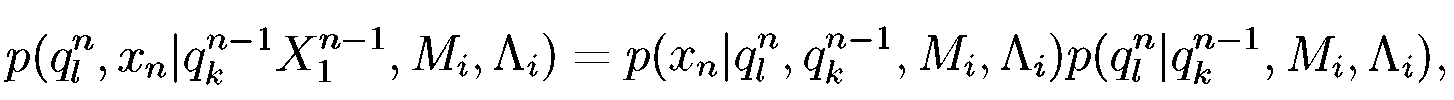 (16.8)
(16.8)
где первый сомножитель 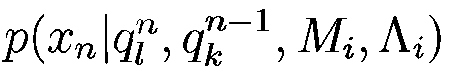 представляет эмиссионную вероятность, а второй
представляет эмиссионную вероятность, а второй 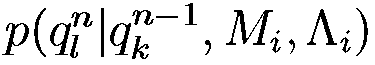 – транзитивную вероятность. Обычно эмиссионную вероятность упрощают, чтобы снизить число свободных параметров, полагая, что наблюдаемый акустический вектор хп зависит только от текущего состояния процесса
– транзитивную вероятность. Обычно эмиссионную вероятность упрощают, чтобы снизить число свободных параметров, полагая, что наблюдаемый акустический вектор хп зависит только от текущего состояния процесса 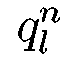 , т. е. используют эмиссионную вероятность в виде
, т. е. используют эмиссионную вероятность в виде 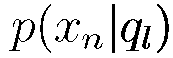 .
.
Описанная стандартная СММ является довольно мощным инструментом, позволившим разработчикам существенно повысить качество распознавания речевого сигнала.
Дата публикования: 2015-09-17; Прочитано: 643 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
