 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Неклассические типы архитектур вычислительных машин
|
|
В ЭВМ классической архитектуры, чтобы найти значение элемента данных мы указываем начальное значение адреса блока памяти, а затем смещение конкретно элемента относительно начального адреса. Эти два значения складываются и получается искомый адрес. Этот вид памяти называется адресуемым. При ассоциативной адресации данные выбираются не по адресу, а по содержимому полей. Вначале пытались отразить ассоциативную адресацию и параллельную обработку на ЭВМ классической архитектуры, в которой один процессор обращается к памяти по адресу. В этой архитектуре для обработки всей информации мы располагаем всего лишь одним процессором. При этом миллиарды символов информации находятся в состоянии ожидания передачи через канал и обработки. При этом затраты времени будут очень большими. При использовании вышеизложенных концепций на этом уровне требуется внести в архитектуру два изменения:
А) использовать параллельные процессоров, т.е. параллелизм обработки;
Б) приблизить процессоры к данным, чтобы устранить постоянную передачу данных, т.е. распределенную логику. Кроме того в ЭВМ классической архитектуры обращение к памяти происходит по адресу, что приемлимо при числовой обработке, однако для организации нечисловой обработки, где обращение происходит по содержание приходится вводить режим эмуляции ассоциативной адресации с помощью основного адресного доступа. При этом создаются специальные таблицы для перевода ассоциативного запроса в адрес. Учитывая, количество информации, легко представить с какими затратами связана обработка этих таблиц.
Высокопараллельные МПВС имеют несколько разновидностей:
магистральные (конвейерные) МПВС, в которых процессоры одновременно выполняют разные операции над последовательным потоком обрабатываемых данных; по принятой классификации такие МПВС относятся к системам с многократным потоком команд и однократным потоком данных (МКОД или MISD – Multiple Instruction Single Data);
векторные МПВС, в которых все процессоры одновременно выполняют одну команду над различными данными – однократный поток команд с многократным потоком данных (ОКМД или SIMD – Single Instruction Multiple Data);
матричные МПВС, в которых МП одновременно выполняют разные операции над несколькими последовательными потоками обрабатываемых данных – многократный поток команд с многократным потоком данных (МКМД или МIМD – Multiple Instruction Multiple Data).
Условные структуры однопроцессорной (SISD – Single Instruction Single Data) и названных многопроцессорных вычислительных систем показаны на рис. 3.8.
В суперЭВМ используются все три варианта архитектуры МПВС:
структура MIMD в классическом ее варианте (например, в суперкомпьютере BSP фирмы Burroughs);
параллельно-конвейерная модификация, или MMISD, т. е. многопроцессорная (Multiple) MISD-архитектура (например, в суперкомпьютере Эльбрус 3);
параллельно-векторная модификация, или MMISD, т. е. многопроцессорная SIMD‑архитектура (например, в суперкомпьютере Cray 2).
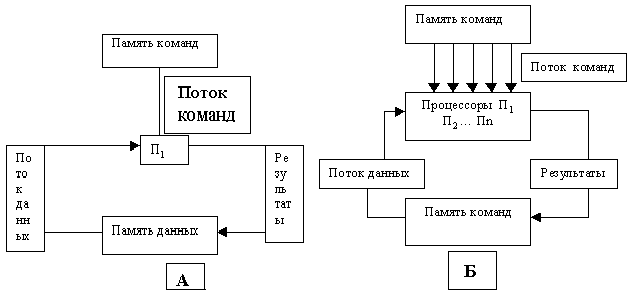
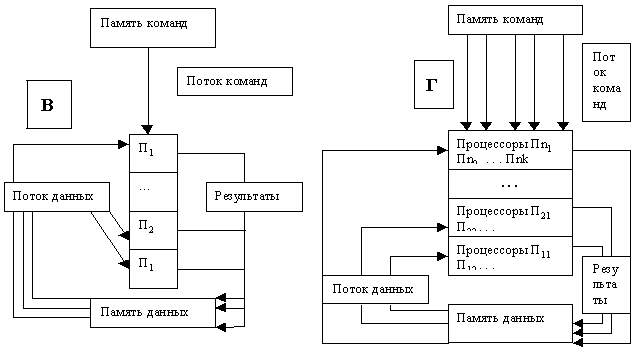
Рис. 3.8. Условные структуры вычислительных систем: А – SISD (однопроцессорная);
Б – MISD (конвейерная); В – SIMD (векторная); Г – MIMD (матричная)
Наибольшую эффективность показала MSIMD-архитектура.
Cуперскалярная обработка. Смысл этого термина заключается в том, что в аппаратуру процессора закладываются средства, позволяющие одновременно выполнять две или более скалярные операции, т.е. команды обработки пары чисел. Суперскалярная архитектура базируется на многофункциональном параллелизме и позволяет увеличить производительность компьютера пропорционально числу одновременно выполняемых операций. Способы реализации суперскалярной обработки могут быть разными.
Аппаратная реализация суперскалярной обработки применяется как в CISC, так и в RISC - процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение. Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
VLIW-архитектуры суперскалярной обработки. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет - это четыре разнотипные операции; (сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими. Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Дата публикования: 2015-09-17; Прочитано: 1628 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
