 |
Главная Случайная страница Контакты | Мы поможем в написании вашей работы! | |
Современные многоуровневые машины
|
|
Большинство современных компьютеров состоит из двух и более уровней. Существуют машины даже с шестью уровнями (рис. 1.2). Уровень 0 — аппаратное обеспечение машины. Его электронные схемы выполняют программы, написанные наязыке уровня 1. Ради полноты нужно упомянуть о существовании еще одного уровня, расположенного ниже уровня 0. Этот уровень не показан на рис. 1.2, так как он попадает в сферу электронной техники и, следовательно, не рассматривается в этойкниге. Он называется уровнем физических устройств. На этом уровне находятся транзисторы, которые являются примитивами для разработчиков компьютеров.Объяснять, как работают транзисторы, — задача физики.
На самом нижнем уровне, цифровом логическом уровне, объекты называются вентилями. Хотя вентили состоят из аналоговых компонентов, таких как транзисторы, они могут быть точно смоделированы как цифровые средства. У каждого вентиля есть одно или несколько цифровых входных данных (сигналов, представляющих 0 или 1). Вентиль вычисляет простые функции этих сигналов, такие как И или ИЛИ. Каждый вентиль формируется из нескольких транзисторов. Несколько вентилей формируют 1 бит памяти, который может содержать 0 или 1. Биты памяти, объединенные в группы, например, по 16,32 или 64, формируют регистры. Каждый регистр может содержать одно двоичное число до определенного предела.
Из вентилей также может состоять сам компьютер. 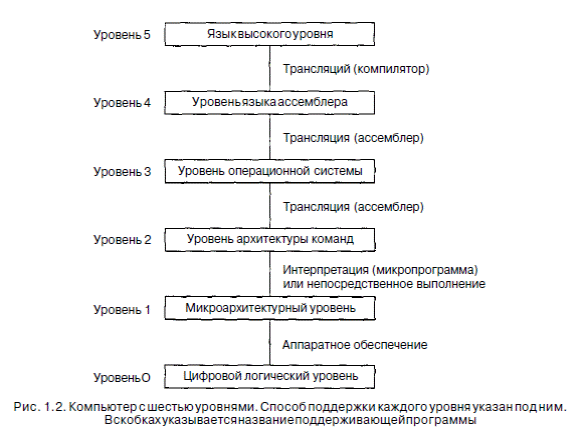
Следующий уровень — микроархитектурный уровень. На этом уровне можно видеть совокупности 8 или 32 регистров, которые формируют локальную память и схему, называемую АЛУ (арифметико-логическое устройство). АЛУ выполняет простые арифметические операции. Регистры вместе с АЛУ формируют тракт данных, по которому поступают данные. Основная операция тракта данных состоит в следующем. Выбирается один или два регистра, АЛУ производит надними какую-либо операцию, например сложения, а результат помещается в одиниз этих регистров.
На некоторых машинах работа тракта данных контролируется особой программой, которая называется микропрограммой. На других машинах тракт данных контролируется аппаратными средствами. В предыдущих изданиях книги мы назвали этот уровень ≪уровнем микропрограммирования≫, потому что раньше он почти всегда был интерпретатором программного обеспечения. Поскольку сейчас тракт данных обычно контролируется аппаратным обеспечением, мы изменили
название, чтобы точнее отразить смысл.
На машинах, где тракт данных контролируется программным обеспечением,
микропрограмма — это интерпретатор для команд на уровне 2. Микропрограмма вызывает команды из памяти и выполняет их одну за другой, используя при этом тракт данных. Например, для того чтобы выполнить команду ADD, эта команда вызывается из памяти, ее операнды помещаются в регистры, АЛУ вычисляет сумму, а затем результат переправляется обратно. На компьютере с аппаратным контролем тракта данных происходит такая же процедура, но при этом нет программы, которая контролирует интерпретацию команд уровня 2.
Многоуровневая компьютерная организация 23
Второй уровень мы будем называть уровнем архитектуры системы команд.
Каждый производитель публикует руководство для компьютеров, которые он продает, под названием ≪Руководство по машинному языку≫ или ≪Принципы работы компьютера Western Wombat Model 100X≫ и т. п. Такие руководства содержат информацию именно об этом уровне. Когда они описывают набор машинных команд, они в действительности описывают команды, которые выполняются микропрограммой-интерпретатором или аппаратным обеспечением. Если производитель поставляет два интерпретатора для одной машины, он должен издать два руководства по машинному языку, отдельно для каждого интерпретатора.
Следующий уровень обычно гибридный. Большинство команд в его языке есть также и на уровне архитектуры системы команд (команды, имеющиеся на одном из уровней, вполне могут находиться на других уровнях). У этого уровня есть некоторые дополнительные особенности: набор новых команд, другая организация памяти, способность выполнять две и более программ одновременно и некоторые другие. При построении третьего уровня возможно больше вариантов, чем при построении первого и второго.
Новые средства, появившиеся на третьем уровне, выполняются интерпретатором, который работает на втором уровне. Этот интерпретатор был когда-то назван операционной системой. Команды третьего уровня, идентичные командам второго уровня, выполняются микропрограммой или аппаратным обеспечением, но не операционной системой. Иными словами, одна часть команд третьего уровня интерпретируется операционной системой, а другая часть — микропрограммой. Вот почему этот уровень считается гибридным. Мы будем называть этот уровень уровнем операционной системы.
Между третьим и четвертым уровнями есть существенная разница. Нижние три уровня конструируются не для того, чтобы с ними работал обычный программист.
Они изначально предназначены для работы интерпретаторов и трансляторов, поддерживающих более высокие уровни. Эти трансляторы и интерпретаторы составляются так называемыми системными программистами, которые специализируются на разработке и построении новых виртуальных машин. Уровни с четвертого и выше предназначены для прикладных программистов, решающих конкретные задачи.
Еще одно изменение, появившееся на уровне 4, — способ, которым поддерживаются более высокие уровни. Уровни 2 и 3 обычно интерпретируются, а уровни 4, 5 и выше обычно, хотя и не всегда, поддерживаются транслятором.
Другое различие между уровнями 1,2,3 и уровнями 4,5 и выше — особенность языка. Машинные языки уровней 1,2 и 3 — цифровые. Программы, написанные на этих языках, состоят из длинных рядов цифр, которые удобны для компьютеров, но совершенно неудобны для людей. Начиная с четвертого уровня, языки содержат слова и сокращения, понятные человеку.
Четвертый уровень представляет собой символическую форму одного из язы-
ков более низкого уровня. На этом уровне можно писать программы в приемлемой для человека форме. Эти программы сначала транслируются на язык уровня 1, 2 или 3, а затем интерпретируются соответствующей виртуальной или фактически существующей машиной. Программа, которая выполняет трансляцию, называется ассемблером.
Пятый уровень обычно состоит из языков, разработанных для прикладных программистов. Такие языки называются языками высокого уровня. Существуют сотни языков высокого уровня. Наиболее известные среди них — BASIC, С, C++, Java, LISP и Prolog. Программы, написанные на этих языках, обычно транслируются на уровень 3 или 4. Трансляторы, которые обрабатывают эти программы, называются компиляторами. Отметим, что иногда также используется метод интерпретации. Например, программы на языке Java обычно интерпретируются.
В некоторых случаях пятый уровень состоит из интерпретатора для такой сферы приложения, как символическая математика. Он обеспечивает данные и операции для решения задач в этой сфере в терминах, понятных людям, сведущим в символической математике.
Вывод: компьютер проектируется как иерархическая структура уровней, каждый из которых надстраивается над предыдущим. Каждый уровень представляет собой определенную абстракцию с различными объектами и операциями. Рассматривая компьютер подобным образом, мы можем не принимать во внимание ненужные нам детали и свести сложный предмет к более простому для понимания.
Набор типов данных, операций и особенностей каждого уровня называется архитектурой. Архитектура связана с аспектами, которые видны программисту. Например, сведения о том, сколько памяти можно использовать при написании программы, — часть архитектуры. А аспекты разработки (например, какая технология используется при создании памяти) не являются частью архитектуры. Изучение того, как разрабатываются те части компьютерной системы, которые видны программистам, называется изучением компьютерной архитектуры. Термины ≪компьютерная архитектура≫ и ≪компьютерная организация≫ означают в сущности одно
и то же.
Развитие многоуровневых машин
В этом разделе мы кратко изложим историю развития многоуровневых машин, покажем, как число и природа уровней менялись с годами. Программы, написанные на машинном языке (уровень 1), могут сразу выполняться электронными схемами компьютера (уровень 0), без применения интерпретаторов и трансляторов. Эти электронные схемы вместе с памятью и средствами ввода-вывода формируют аппаратное обеспечение. Аппаратное обеспечение состоит из осязаемых объектов — интегральных схем, печатных плат, кабелей, источников электропитания, запоминающих устройств и принтеров. Абстрактные понятия, алгоритмы и команды не относятся к аппаратному обеспечению.
Программное обеспечение, напротив, состоит из алгоритмов (подробных последовательностей команд, которые описывают, как решить задачу) и их компьютерных представлений, то есть программ. Программы могут храниться на жестком диске, гибком диске, компакт-диске или других носителях, но в сущности программное обеспечение — это набор команд, составляющих программы, а не физические носители, на которых эти программы записаны.
В самых первых компьютерах граница между аппаратным и программным обеспечением была очевидна. Со временем, однако, произошло значительное размывание этой границы, в первую очередь благодаря тому, что в процессе развития.
Многоуровневая компьютерная организация 25 компьютеров уровни добавлялись, убирались и сливались. В настоящее время очень сложно отделить их друг от друга. В действительности центральная тема этой книги может быть выражена так: аппаратное и программное обеспечение логически
эквивалентны.
Любая операция, выполняемая программным обеспечением, может быть встроена в аппаратное обеспечение (желательно после того, как она осознана). Карен Панетта Ленц говорил; ≪Аппаратное обеспечение — это всего лишь окаменевшее программное обеспечение≫. Конечно, обратное тоже верно: любая команда, выполняемая аппаратным обеспечением, может быть смоделирована в программном обеспечении. Решение разделить функции аппаратного и программного обеспечения основано на таких факторах, как стоимость, скорость, надежность, а также частота ожидаемых изменений. Существует несколько жестких правил, сводящихся к тому, что X должен быть в аппаратном обеспечении, a Y должен программироваться.
Эти решения изменяются в зависимости от тенденций в развитии компьютерных технологий.
2.Типы компьютеров
Технологические и экономические аспекты
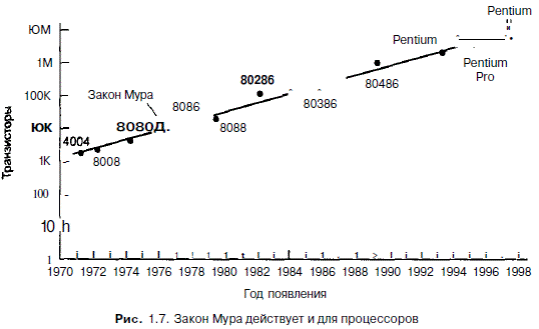
Степень технологического прогресса можно наблюдать, используя закон Мура, названный в честь одного из основателей и главы компании Intel Гордона Мура,который открыл его в 1965 году Закон Мура гласит, что число транзисторовна одной микросхеме удваивается каждые 18 месяцев, то есть увеличивается на60% каждый год. Размеры микросхем и даты их производства, показанные нарис. 1.6, подтверждают, что закон Мура до сих пор действует.
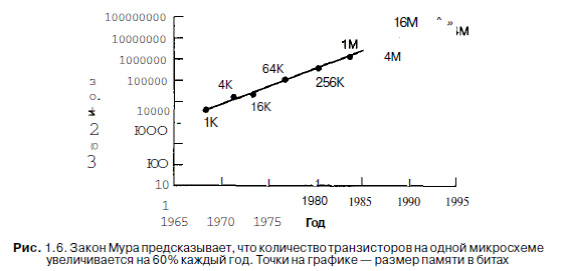
Многие специалисты считают, что закон Мура действует и в XXI веке, возможно, до 2020 года. Вероятно, транзисторы скоро будут состоять всего лишь из нескольких атомов, хотя достижения квантовой компьютерной техники, может быть, позволят использовать для размещения 1 бита спин одного электрона.
Еще один фактор развития компьютерных технологий - первый натановский закон программного обеспечения, названный в честь Натана Мирвольда, главного администратора компании Microsoft. Этот закон гласит: «Программное обеспечение - это газ. Оно распространяется и полностью заполняет резервуар, в котором находится» Современные электронные редакторы занимают десятки мегабайтов. В будущем, несомненно, они будут занимать десятки гигабайтов. Программное обеспечение продолжает развиваться и создает постоянный спрос на процессоры, работающие с более высокой скоростью, на большийобъем памяти, на большую производительность устройств ввода-вывода.
С каждым годом происходит стремительное увеличение количества транзисторов на одной микросхеме. Отметим, что достижения в развитии других частей компьютера столь же велики.
Подсчитать, насколько быстро происходит совершенствование жесткого диска, гораздо сложнее, поскольку тут есть несколько параметров (объем, скорость передачи данных, цена и т. д), но измерение любого из этих параметров покажет, что показатели возрастают, по крайней мере, на 50% в год.
Крупные достижения наблюдаются также и в сфере телекоммуникаций и создания сетей. Меньше чем за два десятилетия мы пришли от модемов, передающих информацию со скоростью 300 бит/с, к аналоговым модемам, работающим со скоростью 56 Кбит/с, телефонным линиям ISDN, где скорость передачи информации 2x64 Кбит/с, оптико-волоконным сетям, где скорость уже больше чем 1 Гбит/с. Оптико-волоконные трансатлантические телефонные кабели (например, ТАТ-12/13) стоят около $700 млн., действуют в течение 10 лет и могут передавать 300 000 звонков одновременно, поэтому стоимость 10-минутной межконтинентальной связи составляет менее 1 цента. Лабораторные исследования подтвердили, что возможны системы связи, работающие со скоростью 1 терабит/с (1012 бит/с) на расстоянии более 100 км без усилителей, Едва ли нужно упоминать здесь о развитии сети Интернет.
3.Семейства компьютеров
3.1. Широкий спектр компьютеров
Ричард Хамминг, бывший исследователь из Bell Laboratories, заметил, что количественное изменение величины на порядок ведет к качественному изменению.
Например, гоночная машина, которая может ездить со скоростью 1000 км/ч попустыне Невада, коренным образом отличается от обычной машины, котораяездит со скоростью 100 км/ч по шоссе Точно так же небоскреб в 100 этажей несопоставим с десятиэтажным многоквартирным домом А если речь идет о компьютерах, то тут за три десятилетия количественные показатели увеличились не в 10, а в 1 000 000 раз.
Развивать компьютерные технологии можно двумя путями: или создавать компьютеры все большей и большей мощности при постоянной цене, или выпускать один и тот же компьютер, с каждым годом снижая цену. Компьютерная промышленность использует оба эти пути, создавая широкий спектр разнообразных компьютеров. Очень приблизительная классификация современных компьютеров представлена в табл. 1.3.
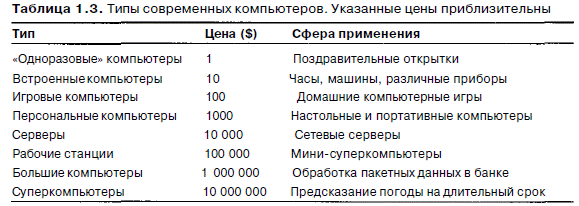
В самой верхней строчке находятся микросхемы, которые приклеиваются на внутреннюю сторону поздравительных открыток для проигрывания мелодий «Happy Birthday», свадебного марша или чего-нибудь подобного. Автор идеи еще не придумал открытки с соболезнованиями, которые играют похоронный марш, но поскольку он выпустил эту идею в потребительскую сферу, вскоре можно будет ожидать появления и таких открыток. Тот, кто воспитывался на компьютерах стоимостью в миллионы долларов, воспринимает такие доступные всем компьютеры примерно так же, как доступный всем самолет. Тем не менее такие компьютеры, вне всяких сомнений, должны существовать (а как насчет говорящих мешков для мусора, которые просят вас не выбрасывать алюминиевые банки?).
Вторая строчка — компьютеры, которые помещаются внутрь телефонов, телевизоров, микроволновых печей, CD-плейеров, игрушек, кукол и т. п. Через несколько лет во всех электрических приборах будут находиться встроенные компьютеры, количество которых будет измеряться в миллиардах. Такие компьютеры состоят из процессора, памяти менее 1 Мбайт и устройств ввода-вывода, и все это на одной маленькой микросхеме, которая стоит всего несколько долларов.
Следующая строка — игровые компьютеры. Это обычные компьютеры с особой графикой, но с ограниченным программным обеспечением и почти полным отсутствием открытости, то есть возможности перепрограммирования. Примерно равны им по стоимости электронные записные книжки и прочие карманные компьютеры, а также сетевые компьютеры и web-терминалы. Все они содержат процессор, несколько мегабайтов памяти, какой-либо дисплей (может быть, даже телевизионный) и больше ничего. Поэтому они такие дешевые.
Далее идут персональные компьютеры. Именно они ассоциируются у большинства людей со словом «компьютер». Персональные компьютеры бывают двух видов: настольные и ноутбуки. Они обычно содержат несколько мегабайтов памяти, жесткий диск с данными на несколько гигабайтов, CD-ROM, модем, звуковую карту и другие периферийные устройства. Они снабжены сложными операционными системами, имеют возможность наращивания, при работе с ними используется широкий спектр программного обеспечения. Компьютеры с процессором Intel обычно называются «персональными компьютерами», а компьютеры с другими
процессорами — «рабочими станциями», хотя особой разницы между ними нет.
Персональные компьютеры и рабочие станции часто используются в качестве сетевых серверов как для локальных сетей (обычно в пределах одной организации), так и для Интернета. У этих компьютеров обычно один или несколько процессоров, несколько гигабайтов памяти и много Гбайт на диске. Такие компьютеры способны работать в сети с очень высокой скоростью. Некоторые из них могут обрабатывать тысячи поступающих сообщений одновременно.
Помимо небольших серверов с несколькими процессорами существуют системы, которые называются сетями рабочих станций (NOW — Networks of Workstations) или кластерами рабочих станций (COW — Clusters of Workstations). Они состоят из обычных персональных компьютеров или рабочих станций, связанных в сеть, по которой информация передается со скоростью 1 Гбит/с, и специального программного обеспечения, позволяющего всем машинам одновременно работать над одной задачей. Такие системы широко применяются в науке и технике. Кластеры рабочих станций могут включать в себя от нескольких компьютеров до нескольких тысяч. Благодаря низкой цене компонентов отдельные организации могут приобретать такие машины, которые по эффективности являются мини-суперкомпьютерами.
А теперь мы дошли до больших компьютеров размером с комнату, напоминающих компьютеры 60-х годов. В большинстве случаев эти системы - прямые потомки больших компьютеров серии IBM-360. Обычно они работают ненамного быстрее, чем мощные серверы, но у них выше скорость процессов ввода-вывода и обладают они довольно большим пространством на диске — 1 терабайт и более(1 терабайт=1012байт). Такие системы стоят очень дорого и требуют крупных вложений в программное обеспечение, данные и персонал, обслуживающий эти компьютеры. Многие компании считают, что дешевле заплатить несколько миллионов долларов один раз за такую систему, чем даже думать о том, что нужно будет заново программировать все прикладные программы для маленьких компьютеров.
Именно этот класс компьютеров привел к проблеме 2000 года. Проблема возникла из-за того, что в 60-е и 70-е годы программисты, пишущие программы на языке COBOL, представляли год двузначным десятичным числом с целью экономиипамяти. Они не смогли предвидеть, что их программное обеспечение будет использоваться через три или четыре десятилетия. Многие компании повторили ту же ошибку, добавив к числу года только два десятичных разряда. Автор этой книги предсказывает, что конец цивилизации произойдет в полночь 31 декабря 9999 года, когда сразу уничтожатся все COBOL-программы, написанные за 8000 лет.
Вслед за большими компьютерами идут настоящие суперкомпьютеры. Их процессоры работают с очень высокой скоростью, объем памяти у них составляет множество гигабайтов, диски и сети также работают очень быстро. В последние годы многие суперкомпьютеры стали очень похожи, они почти не отличаются от кластеров рабочих станций, но у них больше составляющих и они работают быстрее. Суперкомпьютеры используются для решения различных научных и технических задач, которые требуют сложных вычислений, например таких, как моделирование сталкивающихся галактик, разработка новых лекарств, моделирование потока воздуха вокруг крыла аэроплана.
3.2.Семейства компьютеров
В этом разделе мы дадим краткое описание трех компьютеров, которые будут использоваться в качестве примеров в этой книге: Pentium II, UltraSPARC II и picojava II.
Pentium II
В 1968 году Роберт Нойс, изобретатель кремниевой интегральной схемы, Гордон Мур, автор известного закона Мура, и Артур Рок, капиталист из Сан-Франциско, основали корпорацию Intel для производства компьютерных микросхем. За первый год своего существования корпорация продала микросхем всего на $3000, но потом объем продаж компании заметно увеличился.
В конце 60-х годов калькуляторы представляли собой большие электромеханические машины размером с современный лазерный принтер и весили около 20 кг.
В сентябре 1969 года японская компания Busicom обратилась к корпорации Intel с просьбой выпустить 12 несерийных микросхем для электронной вычислительной машины. Инженер компании Intel Тед Хофф, назначенный на выполнение этого проекта, решил, что можно поместить 4-битный универсальный процессор на одну микросхему, которая будет выполнять те же функции и при этом окажется проще и дешевле. Так в 1970 году появился первый процессор на одной микросхеме, процессор 4004 на 2300 транзисторах.
Заметим, что ни Intel, ни Busicom не имели ни малейшего понятия, какое грандиозное открытие они совершили. Когда компания Intel решила, что стоит попробовать использовать процессор 4004 в других разработках, она предложила купить все права на новую микросхему у компании Busicom за $60000, то есть за сумму, которую Busicom заплатила Intel за разработку этой микросхемы. Busicom сразу приняла предложение Intel, и Intel начала работу над 8-битной версией микросхемы 8008, выпущенной в 1972 году.
Компания Intel не ожидала большого спроса на микросхему 8008, поэтому она выпустила небольшое количество этой продукции. К всеобщему удивлению, новая микросхема вызвала большой интерес, поэтому Intel начала разработку еще одного процессора, в котором предел в 16 Кбайт памяти (как у процессора 8008), навязываемый количеством внешних выводов микросхемы, был преодолен. Так появился небольшой универсальный процессор 8080, выпущенный в 1974 году.
Как и PDP-8, он произвел революцию на компьютерном рынке и сразу стал массовым продуктом: только компания DEC продала тысячи PDP-8, a Intel — миллионы процессоров 8080.
В 1978 году появился процессор 8086 — 16-битный процессор на одной микросхеме. Процессор 8086 был во многом похож на 8080, но не был полностью совместим с ним. Затем появился процессор 8088 с такой же архитектурой, как и у 8086.
Он выполнял те же программы, что и 8086, но вместо 16-битной шины у него была 8-битная, из-за чего процессор работал медленнее, но стоил дешевле, чем 80861. Когда IBM выбрала процессор 8088 для IBM PC, эта микросхема стала эталоном в производстве персональных компьютеров.
Ни 8088, ни 8086 не могли обращаться к более 1 Мбайт памяти. К началу 80-х годов это стало серьезной проблемой, поэтому компания Intel разработала модель 80286, совместимую с 8086. Основной набор команд остался, в сущности, таким же, как у процессоров 8086 и 8088, но память была устроена немного по-другому, хотя и могла работать по-прежнему из-за требования совместимости с предыдущими микросхемами. Процессор 80286 использовался в IBM PC/AT и в моделях PS/2.
Он, как и 8088, пользовался большим спросом (главным образом потому, что покупатели рассматривали его как более быстрый процессор 8088).
Следующим шагом был 32-битный процессор 80386, выпущенный в 1985 году. Как и 80286, он был более или менее совместим со всеми старыми версиями. Совместимость такого рода оказывалась благом для тех, кто пользовался старым программным обеспечением, и некоторым неудобством для тех, кто предпочитал современную архитектуру, не обремененную ошибками и технологиями прошлого.
Через четыре года появился процессор 80486. Он работал быстрее, чем 80386, мог выполнять операции с плавающей точкой и имел 8 Кбайт кэш-памяти. Кэш-память используется для того, чтобы держать наиболее часто используемые слова внутри центрального процессора и избегать длительного доступа к основной (оперативной) памяти. Иногда кэш-память находится не внутри центрального процессора, а рядом с ним. 80486 содержал встроенные средства поддержки многопроцессорного режима, что давало производителям возможность конструировать системы с несколькими процессорами.
В этот момент Intel, проиграв судебную тяжбу по поводу нарушения правил наименования товаров, выяснила, что номера (например, 80486) не могут быть торговой маркой, поэтому следующее поколение компьютеров получило название Pentium (от греческого слова ЛЕУТЕ — пять). В отличие от 80486, у которого был один внутренний конвейер, Pentium имел два, что позволяло работать ему почти в два раза быстрее (конвейеры мы рассмотрим подробно в главе 2).
Когда появилось следующее поколение компьютеров, те, кто рассчитывал на название Sexium (sex по-латыни — шесть), были разочарованы. Название Pentium стало так хорошо известно, что его решили оставить, и новую микросхему назвали Pentium Pro. Несмотря на столь незначительное изменение названия, этот процессор очень сильно отличался от предыдущего. У него была совершенно другая внутренняя организация, и он мог выполнять до пяти команд одновременно.
Еще одно нововведение у Pentium Pro — двухуровневая кэш-память. Процессор содержал 8 Кбайт памяти для часто используемых команд и еще 8 Кбайт для часто используемых данных. В корпусе Pentium Pro рядом с процессором (но не на самой микросхеме) находилась другая кэш-память в 256 Кбайт.
Вслед за Pentium Pro появился процессор Pentium II, по существу такой же, как и его предшественник, но с особой системой команд для мультимедиа-задач (ММХ — multimedia extensions). Эта система команд предназначалась для ускорения вычислений, необходимых при воспроизведении изображения и звука. При наличии ММХ специальные сопроцессоры были не нужны. Данные команды имелись в наличии и в более поздних версиях Pentium, но их не было в Pentium Pro.
Таким образом, компьютер Pentium II сочетал в себе функции Pentium Pro с мультимедиа-командами.
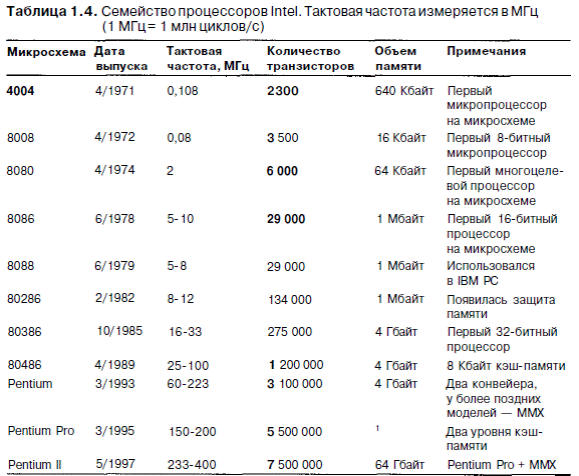
В начале 1998 года Intel запустил новую линию продукции под названием Celeron. Celeron имел меньшую производительность, чем Pentium II, но зато стоилдешевле. Поскольку у компьютера Celeron такая же архитектура, как у Pentium II, мы не будем обсуждать его в этой книге. В июне 1998 года компания Intel выпустила специальную версию Pentium II — Хеоп. Он имел кэш-память большего объема, его внутренняя шина работала быстрее, были усовершенствованы средства поддержки многопроцессорного режима, но во всем остальном он остался обычным Pentium II, поэтому мы его тоже не будем обсуждать. Компьютеры семейства Intel показаны в табл. 1.4.
Все микросхемы Intel совместимы со своими предшественниками вплоть до
процессора 8086. Другими словами, Pentium II может выполнять программы, написанные для процессора 80861. Совместимость всегда была одним из главных требований при разработке новых компьютеров, чтобы покупатели могли продолжать работать со старым программным обеспечением и не тратить деньги на новое. Конечно, Pentium II во много раз сложнее, чем 8086, поэтому он может выполнять многие функции, которые не способен выполнять процессор 8086. Все эти постепенные доработки в каждой новой версии привели к тому, что архитектура Pentium II не так проста, как могла бы быть, если бы разработчикам процессора Pentium II предоставили 7,5 млн транзисторов и команд, чтобы начать все заново.
Интересно, что хотя закон Мура раньше ассоциировался с числом битов в памяти компьютера, он в равной степени применим и по отношению к процессорам.
Если напротив даты выпуска каждой микросхемы поставить число транзисторов на этой микросхеме (количество транзисторов показано в табл. 1.4), мы увидим, что закон Мура действует и здесь. График показан на рис.1.7.
UltraSPARC II
В 70-х годах во многих университетах была очень популярна операционная система UNIX, но персональные компьютеры не подходили для этой операционной системы, поэтому любителям UNIX приходилось работать на мини-компьютерах с разделением времени, таких как PDP-11 и VAX. Энди Бехтольсхайм, аспирант Стэнфордского университета, был очень расстроен тем, что ему нужно посещать компьютерный центр, чтобы работать с UNIX. В 1981 году он разрешил эту проблему, самостоятельно построив персональную рабочую станцию UNIX из стандартных частей, имеющихся в продаже, и назвал ее SUN-1 (Stanford University Network – сеть Стэнфордского университета).
На Бехтольсхайма скоро обратил внимание Винод Косла, 27-летний индиец, который горел желанием годам к тридцати стать миллионером и уйти от дел. Косла предложил Бехтольсхайму организовать компанию по производству рабочих станций Sun. Он нанял Скота Мак-Нили, другого аспиранта Стэнфордского университета, чтобы тот возглавил производство. Для написания программного обеспечения они наняли Билла Джоя, главного создателя системы UNIX. В 1982 году они вчетвером основали компанию Sun Microsystems. Первый компьютер компании, Sun-1, был оснащен процессором Motorola 68020 и имел большой успех, как и последующие модели Sun-2 и Sun-З, которые также были сконструированы с использованием микропроцессоров Motorola. Эти машины были гораздо мощнее, чем другие персональные компьютеры того времени (отсюда и название «рабочая станция»), и изначально были предназначены для работы в сети. Каждая рабочая станция Sun была оснащена сетевым адаптером Ethernet и программным обеспечением TCP/IP для связи с сетью ARPANET, предшественницей Интернета.
В 1987 году компания Sun, которая к тому времени продавала рабочих станций на полмиллиарда долларов в год, решила разработать свой собственный процессор, основанный на новом революционном проекте калифорнийского университета в Беркли (RISC II). Этот процессор назывался SPARC (Scalable ProcessorARCitecture — наращиваемая архитектура процессора). Он был использован при производстве рабочей станции Sun-4. Через некоторое время все рабочие станции компании Sun стали производиться на основе этого процессора.
В отличие от многих других компьютерных компаний, Sun решила не заниматься производством процессоров SPARC. Вместо этого она предоставила патент на их изготовление нескольким предприятиям, надеясь, что конкуренция между ними повлечет за собой повышение качества продукции и снижение цен. Эти предприятия выпустили несколько разных микросхем, основанных на разных технологиях, работающих с разной скоростью и отличающихся друг от друга по стоимости.
Микросхемы назывались MicroSPARC, HyperSPARK, SuperSPARK и TurboSPARK. Мало чем отличаясь друг от друга, все они были совместимы и могли выполнять одни и те же программы, которые не приходилось изменять.
Компания Sun всегда хотела, чтобы разные предприятия поставляли для SPARK составные части и системы. Нужно было построить целую индустрию, только в этом случае можно было конкурировать с компанией Intel, лидирующей на рынке персональных компьютеров. Чтобы завоевать доверие компаний, которые были заинтересованы в производстве процессоров SPARC, но не хотели вкладывать средства в продукцию, которую будет подавлять Intel, компания Sun создала промышленный консорциум SPARC International для руководства развитием будущих версий архитектуры SPARC. Важно различать архитектуру SPARC, которая представляет собой набор команд, и собственно выполнение этих команд. В этой книге мы будем говорить и об общей архитектуре SPARC, и о процессоре, используемом в рабочей станции SPARC (предварительно обсудив процессоры в третьей и четвертой главах).
Первый SPARC был 32-битным и работал с частотой 36 МГц. Центральный процессор назывался Ш (Integer Unit — процессор целочисленной арифметики) и был весьма посредственным. У него было только три основных формата команд и в общей сложности всего 55 команд. С появлением процессора с плавающей точкой добавилось еще 14 команд. Отметим, что компания Intel начала с 8- и 16-битных микросхем (модели 8088, 8086, 80286), а уже потом перешла на 32-битные (модель 80386), a Sun, в отличие от Intel, сразу начала с 32-битных.
Грандиозный перелом в развитии SPARC произошел в 1995 году, когда была разработана 64-битная версия (версия 9) с адресами и регистрами по 64 бит. Первой рабочей станцией с такой архитектурой стал UltraSPARC I, вышедший в свет в 1995 году. Он был полностью совместим с 32-битными версиями SPARC, хотя сам был 64-битным.
В то время как предыдущие машины работали с символьными и числовыми данными, UltraSPARC с самого начала был предназначен для работы с изображениями, аудио, видео и мультимедиа вообще. Среди нововведений, помимо 64-битной архитектуры, появились 23 новые команды, в том числе команды для упаковки и распаковки пикселов из 64-битных слов, масштабирования и вращения изображений, перемещения блоков, а также для компрессии и декомпрессии видео в реальном времени. Эти команды назывались VIS (Visual Instruction Set) и предназначались для поддержки мультимедиа. Они были аналогичны командам ММХ.
UltraSPARC предназначался для web-серверов с десятками процессоров и физической памятью до 2 Тбайт (терабайт, 1Тбайт = 1012 байтов). Тем не менее некоторые версии UltraSPARC могут использоваться и в ноутбуках.
За UltraSPARC I последовали UltraSPARC II и UltraSPARC III. Эти модели отличались друг от друга по скорости, и у каждой из них появлялись какие-то новые особенности. Когда мы будем говорить об архитектуре SPARC, мы будем иметь в виду 64-битную версию компьютера UltraSPARC II (версии 9).
PicoJava II
Язык программирования С придумал один из работников компании Bell Laboratories Деннис Ритчи. Этот язык предназначался для работы в операционной системе UNIX. Из-за большой популярности UNIX С скоро стал доминирующим языком в системном программировании. Через несколько лет Бьярн Строуструп, тоже из компании Bell Laboratories, добавил к С некоторые особенности из объектно-ориентированного программирования, и появился язык C++, который также стал очень
популярным.
В середине 90-х годов исследователи в Sun Microsystems думали, как сделать
так, чтобы пользователи могли вызывать двоичные программы через Интернет и загружать их как часть web-страниц. Им нравился C++, но он не был надежным в том смысле, что программа, посланная на некоторый компьютер, могла причинить ущерб этому компьютеру. Тогда они решили на основе C++ создать новый язык программирования Java, с которым не было бы подобных проблем. Java - объектно-ориентированный язык, который применяется при решении различных прикладных задач. Поскольку этот язык прост и популярен, мы будем использовать его для примеров.
Поскольку Java — всего лишь язык программирования, можно написать компилятор, который будет преобразовывать его для Pentium, SPARC или любого другого компьютера. Такие компиляторы существуют. Однако этот язык был создан в первую очередь для того, чтобы пересылать программы между компьютерами по Интернету и чтобы пользователям не приходилось изменять их. Но если программа на языке Java компилировалась для SPARC, то когда она пересылалась по Интернету на Pentium, запустить там эту программу было уже нельзя.
Чтобы разрешить эту проблему, компания Sun придумала новую виртуальную машину JVM (J a v a Virtual Machine — виртуальная машина Java). Память у этой машины состояла из 32-битных слов, машина поддерживала 226 команд. Большинство команд были простыми, но выполнение некоторых довольно сложных команд требовало большого количества циклов обращения к памяти.
В компании Sun разработали компилятор, преобразующий программы на языке Java на уровень JVM, и интерпретатор JVM для выполнения этих программ.
Этот интерпретатор был написан на языке С и, значит, мог использоваться практически на любом компьютере. Следовательно, чтобы компьютер мог выполнять двоичные программы на языке Java, нужно было всего лишь достать интерпретатор JVM для соответствующего компьютера (например, для Pentium II с системой Windows 98 или для SPARC с системой UNIX) вместе с определенными программами поддержки и библиотеками. Кроме того, большинство браузеров в Интернете содержат интерпретатор JVM, что позволяет легко запускать апплеты (небольшие двоичные программы на Java, связанные со страницами World Wide Web).
Большинство этих апплетов поддерживают анимацию и звук.
Интерпретация программ JVM (и любых других программ) происходит медленно. Альтернативный подход — сначала скомпилировать апплет или другую программу JVM для вашей собственной машины, а затем запустить скомпилированную программу. Такая стратегия требует наличия компилятора с JVM на машинный язык внутри браузера и возможности активизировать его, когда необходимо. Эти компиляторы называются JIT-компиляторами (Just In Time — «как раз вовремя»), и они широко распространены. Однако эта система создает некоторую задержку между получением JVM-программы и ее выполнением, поскольку JVM-программа компилируется на машинный язык.
Кроме программного обеспечения JVM (JVM-интерпретаторов и JIT-компиляторов) Sun и другие компании разработали микросхемы JVM — процессоры, которые сразу выполняют двоичные программы JVM без какой-либо интерпретации и компиляции. Picojava I и picojava II были разработаны для рынка встроенных систем. На этом рынке требуются мощные и очень дешевые процессоры (цена ниже $50), встраиваемые внутрь пластиковых карточек, телевизоров, телефонов и других устройств, особенно таких, которые обеспечивают связь с внешним миром. Предприятия, имеющие патент на производство микросхем компании Sun, могли производить собственные микросхемы на основе проекта picojava, в той или иной степени изменяя их, включая и убирая процессор с плавающей точкой, преобразуя размер кэш-памяти и т. п.
Ценность микросхемы Java состоит в том, что она способна менять функции процессе работы. Например, представим себе администратора, у которого есть телефон с процессором Java. Администратору никогда не приходилось читать факсы на крошечном экране телефона, но в один прекрасный день ему это понадобилось. Тогда он звонит провайдеру и просит предоставить ему апплет для просмотра факсов, и таким образом добавляет новую функцию к своему телефону. Но из-за некоторых особенностей прибора и недостатка памяти невозможно использовать интерпретаторы и JIT-компиляторы, поэтому именно в таких случаях необходимы микросхемы JVM.
Picojava II — не физическая микросхема (вы не можете пойти в магазин и купить ее), а проект, который является основой для ряда микросхем, например Sun Microjava 701 и других. Эти микросхемы производятся предприятиями, получившими патент Sun. Мы будем использовать процессор picojava II в качестве иллюстративного примера, поскольку он очень сильно отличается от Pentium II и UltraSPARC II и имеет совершенно другую сферу применения. Picojava II представляет особый интерес для нас, поскольку в главе 4 мы расскажем, как можно создать JVM с помощью микропрограммирования. Тогда мы сможем сравнить спрограммированный JVM с аппаратным обеспечением JVM. Picojava II содержит два факультативных процессора: кэш-память и процессор с плавающей точкой, которые каждый производитель может включать или не включать в разработку. В целях простоты мы будем рассматривать picojava II как микросхему, хотя на самом деле это не микросхема, а проект микросхемы. Иногда мы будем говорить о микросхеме Sun Microjava 701, которая является воплощением проекта picojava II. Но даже если мы не будем упоминать конкретные микросхемы, читатели должны помнить, что picojava II — это не физическая микросхема, а проект, на основе которого производители разрабатывают разные микросхемы.
Используя Pentium II, UltraSPARC II и picojava II в качестве примеров, мы можем изучить три разных типа процессоров. Первый из них представляет собой CISC с суперскалярным процессором, второй — RISC с суперскалярным процессором. Третий используется во встроенных системах. Эти три процессора сильно отличаются друг от друга, что дает нам возможность лучше увидеть диапазон компьютерных разработок.
Лекция 2. Процессоры
1. Устройство центрального процессора.
2. Механизм выполнения команд.
3. Системы команд RICS и CISC
1.Устройство центрального процессора
1.1.Процессоры
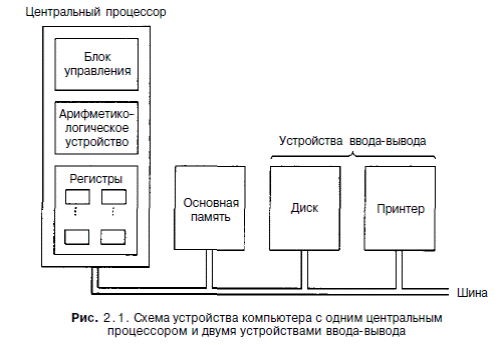
На рис. 2.1 показано устройство обычного компьютера. Центральный процессор - это мозг компьютера. Его задача — выполнять программы, находящиеся в основной памяти. Он вызывает команды из памяти, определяет их тип, а затем выполняет их одну за другой. Компоненты соединены шиной, представляющей собой набор параллельно связанных проводов, по которым передаются адреса, данные и сигналы управления. Шины могут быть внешними (связывающими процессор с памятью и устройствами ввода-вывода) и внутренними.
Процессор состоит из нескольких частей. Блок управления отвечает за вызов
команд из памяти и определение их типа. Арифметико-логическое устройство выполняет арифметические операции (например, сложение) и логические операции (например, логическое И).
Внутри центрального процессора находится память для хранения промежуточных результатов и некоторых команд управления. Эта память состоит из нескольких регистров, каждый из которых выполняет определенную функцию. Обычно все регистры одинакового размера. Каждый регистр содержит одно число, которое ограничивается размером регистра. Регистры считываются и записываются очень быстро, поскольку они находятся внутри центрального процессора.
Самый важный регистр - счетчик команд, который указывает, какую команду нужно выполнять дальше. Название «счетчик команд» не соответствует действительности, поскольку он ничего не считает, но этот термин употребляется повсеместно1.
Еще есть регистр команд, в котором находится команда, выполняемая в данный момент. У большинства компьютеров имеются и другие регистры, одни из них многофункциональны, другие выполняют только какие-либо специфические функции.
1.2.Устройство центрального процессора
Внутреннее устройство тракта данных типичного фон-неймановского процессора показано на рис. 2.2. Тракт данных состоит из регистров (обычно от 1 до 32), АЛУ (арифметико-логического устройства) и нескольких соединяющих шин. Содержимое регистров поступает во входные регистры АЛУ, которые на рис. 2.2 обозначены буквами А и В. В них находятся входные данные АЛУ, пока АЛУ производит вычисления. Тракт данных - важная составная часть всех компьютеров, и мы обсудим его очень подробно.
АЛУ выполняет сложение, вычитание и другие простые операции над входными данными и помещает результат в выходной регистр. Этот выходной регистр может помещаться обратно в один из регистров. Он может быть сохранен в памяти, если это необходимо. На рис. 2.2 показана операция сложения. Отметим, что входные и выходные регистры есть не у всех компьютеров.
Большинство команд можно разделить на две группы: команды типа регистр-
память и типа регистр-регистр. Команды первого типа вызывают слова из памяти, помещают их в регистры, где они используются в качестве входных данных АЛУ. («Слова» — это такие элементы данных, которые перемещаются между памятью и регистрами1.) Словом может быть целое число. Устройство памяти мы обсудим ниже в этой главе. Другие команды этого типа помещают регистры обратно в память.
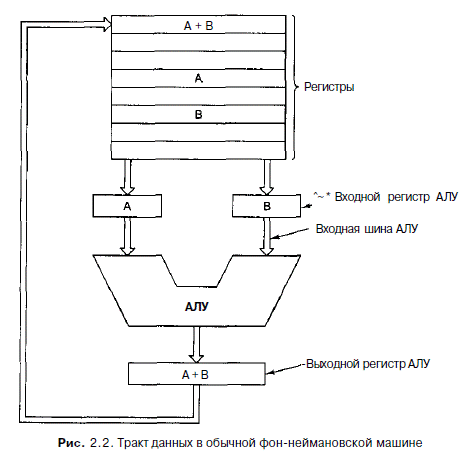
Команды второго типа вызывают два операнда из регистров, помещают их во входные регистры АЛУ, выполняют над ними какую-нибудь арифметическую или логическую операцию и переносят результат обратно в один из регистров. Этот процесс называется циклом тракта данных. В какой-то степени он определяет, что может делать машина. Чем быстрее происходит цикл тракта данных, тем быстрее компьютер работает.
2.Механизм выполнение команд
Центральный процессор выполняет каждую команду за несколько шагов:
1) вызывает следующую команду из памяти и переносит ее в регистр команд;
2) меняет положение счетчика команд, который теперь должен указывать на
следующую команду;
3) определяет тип вызванной команды;
4) если команда использует слово из памяти, определяет, где находится это слово;
5) переносит слово, если это необходимо, в регистр центрального процессора;
6) выполняет команду;
7) переходит к шагу 1, чтобы начать выполнение следующей команды.
Такая последовательность шагов (выборка—декодирование—исполнение) является основой работы всех компьютеров.
Описание работы центрального процессора можно представить в виде программы на английском языке. В листинге 2.1 приведена такая программа-интерпретатор на языке Java. В описываемом компьютере есть два регистра: счетчик команд, который содержит путь к адресу следующей команды, и аккумулятор, в котором хранятся результаты арифметических операций. Кроме того, имеются внутренние регистры, в которых хранится текущая команда (instr), тип текущей команды (instr_type), адрес операнда команды (datajloc) и сам операнд (data). Каждая команда содержит один адрес ячейки памяти. В ячейке памяти находится операнд, например кусок данных, который нужно добавить в аккумулятор.
Сама возможность написать программу, имитирующей работу центрального процессора, показывает, что программа не обязательно должна выполняться реальным процессором, относящимся к аппаратному обеспечению. Напротив, вызывать из памяти, определять тип команд и выполнять эти команды может другая программа. Такая программа называется интерпретатором. Об интерпретаторах мы говорили в главе 1.
Написание программ-интерпретаторов, которые имитируют работу процессора, широко используется при разработке компьютерных систем. После того как разработчики выбрали машинный язык (Я) для нового компьютера, они должны решить, строить ли им процессор, который будет выполнять программы на языке Я, или написать специальную программу для интерпретации программ на языке Я. Если они решают написать интерпретатор, они должны создать аппаратное обеспечение для выполнения этого интерпретатора. Возможны также гибридные конструкции, когда часть команд выполняется аппаратным обеспечением, а часть интерпретируется.
Интерпретатор разбивает команды на маленькие шаги. Таким образом, машина с интерпретатором может быть гораздо проще по строению и дешевле, чем процессор, выполняющий программы без интерпретации. Такая экономия особенно важна, если компьютер содержит большое количество сложных команд с различными опциями. В сущности, экономия проистекает из самой замены аппаратного обеспечения программным обеспечением (интерпретатором). Первые компьютеры содержали небольшое количество команд, и эти команды были простыми. Но поиски более мощных компьютеров привели, кроме всего прочего, к появлению более сложных команд. Вскоре разработчики поняли, что при наличии сложных команд программы выполняются быстрее, хотя выполнение отдельных команд занимает больше времени. В качестве примеров сложных команд можно назвать выполнение операций с плавающей точкой, обеспечение прямого доступа к элементам массива и т. п. Если обнаруживалось, что две определенные команды часто выполнялись последовательно одна за другой, то вводилась новая команда, заменяющая работу этих двух.
Сложные команды были лучше, потому что некоторые операции иногда перекрывались. Какие-то операции могли выполняться параллельно, для этого использовались разные части аппаратного обеспечения. Для дорогих компьютеров с высокой производительностью стоимость этого дополнительного аппаратного обеспечения была вполне оправданна. Таким образом, у дорогих компьютеров было гораздо больше команд, чем у дешевых. Однако развитие программного обеспечения и требования совместимости команд привели к тому, что сложные команды стали использоваться и в дешевых компьютерах, хотя там во главу угла ставилась стоимость, а не скорость работы.
К концу 50-х годов компания IBM, которая лидировала тогда на компьютерном рынке, решила, что производство семейства компьютеров, каждый из которых выполняет одни и те же команды, имеет много преимуществ и для самой компании, и для покупателей. Чтобы описать этот уровень совместимости, компания IBM ввела термин архитектура. Новое семейство компьютеров должно было иметь одну общую архитектуру и много разных разработок, различающихся по цене и скорости, которые могли выполнять одну и ту же программу. Но как построить дешевый компьютер, который будет выполнять все сложные команды, предназначенные для высокоэффективных дорогостоящих машин?
Решением этой проблемы стала интерпретация. Эта технология, впервые предложенная Уилксом в 1951 году, позволяла разрабатывать простые дешевые компьютеры, которые, тем не менее, могли выполнять большое количество команд. В результате IBM создала архитектуру System/360, семейство совместимых компьютеров, различных по цене и производительности. Аппаратное обеспечение без интерпретации использовалось только в самых дорогих моделях.
Простые компьютеры с интерпретированными командами имели некоторые другие преимущества. Наиболее важными среди них были:
1) возможность фиксировать неправильно выполненные команды или даже восполнять недостатки аппаратного обеспечения;
2) возможность добавлять новые команды при минимальных затратах, даже после покупки компьютера;
3) структурированная организация, которая позволяла разрабатывать, проверять и документировать сложные команды.
В 70-е годы компьютерный рынок быстро разрастался, новые компьютеры могли выполнять все больше и больше функций. Спрос на дешевые компьютеры провоцировал создание компьютеров с использованием интерпретаторов. Возможность разрабатывать аппаратное обеспечение и интерпретатор для определенного набора команд вылилась в создание дешевых процессоров. Полупроводниковые технологии быстро развивались, преимущества низкой стоимости преобладали над возможностями более высокой производительности, и использование интерпретаторов при разработке компьютеров стало широко применимо. Интерпретация использовалась практически во всех компьютерах, выпущенных в 70-е годы, от мини-компьютеров до самых больших машин.
К концу 70-х годов интерпретаторы стали применяться практически во всех моделях, кроме самых дорогостоящих машин с очень высокой производительностью (например, Сгау-1 и компьютеров серии Control Data Cyber). Использование интерпретаторов исключало высокую стоимость сложных команд, и разработчики могли вводить все более и более сложные команды, в особенности различные способы определения используемых операндов.
Эта тенденция достигла пика своего развития в разработке компьютера VAX (производитель Digital Equipment Corporation), у которого было несколько сотен команд и более 200 способов определения операндов в каждой команде. К несчастью, архитектура VAX с самого начала разрабатывалась с использованием интерпретатора, а производительности уделялось мало внимания. Это привело к появлению большого количества команд второстепенного значения, которые трудно было выполнять сразу без интерпретации. Данное упущение стало фатальным как для VAX, так и для его производителя (компании DEC). Compaq купил DEC в 1998 году.
Хотя самые первые 8-битные микропроцессоры были очень простыми и содержали небольшой набор команд, к концу 70-х годов даже они стали разрабатываться с использованием интерпретаторов. В этот период основной проблемой для разработчиков стала возрастающая сложность микропроцессоров. Главное преимущество интерпретации заключалось в том, что можно было разработать простой процессор, а вся сложность сводилась к созданию интерпретатора. Таким образом, разработка сложного аппаратного обеспечения замещалась разработкой сложного программного обеспечения.
Успех Motorola 68000 с большим набором интерпретируемых команд и одно-
временный провал Zilog Z8000, у которого был столь же обширный набор команд, но не было интерпретатора, продемонстрировали все преимущества использования интерпретаторов при разработке новых машин. Успех Motorola 68000 был несколько неожиданным, учитывая, что Z80 (предшественник Zilog Z8000) пользовался большей популярностью, чем Motorola 6800 (предшественник Motorola 68000).
Конечно, важную роль здесь играли и другие факторы, например то, что Motorola много лет занималась производством микросхем, a Exxon (владелец Zilog) долгое время был нефтяной компанией. Еще один фактор в пользу интерпретации - существование быстрых постоянных запоминающих устройств (так называемых командных ПЗУ) для хранения
интерпретаторов. Предположим, что для выполнения обычной интерпретируемой команды Motorola 68000 интерпретатору нужно выполнить 10 команд, которые называются микрокомандами, по 100 не каждая, и произвести 2 обращения к оперативной памяти по 500 не каждое. Общее время выполнения команды составит, следовательно, 2000 не, всего лишь в два раза больше, чем в лучшем случае могло бы занять непосредственное выполнение этой команды без интерпретации. А если
бы не было специального быстродействующего постоянного запоминающего
устройства, выполнение этой команды заняло бы целых 6000 не. Таким образом, важность наличия командных ПЗУ очевидна.
3.Системы команд RISC и CISC
В конце 70-х годов проводилось много экспериментов с очень сложными командами, появление которых стало возможным благодаря интерпретации. Разработчики пытались уменьшить пропасть между тем, что компьютеры способны делать, и тем, что требуют языки высокого уровня. Едва ли кто-нибудь тогда думал о разработке более простых машин, так же как сейчас мало кто занимается разработкой менее мощных операционных систем, сетей, редакторов и т. д. (к несчастью). В компании IBM группа разработчиков во главе с Джоном Коком противостояла этой тенденции; они попытались воплотить идеи Сеймура Крея, создав экспериментальный высокоэффективный мини-компьютер 801. Хотя IBM не занималась сбытом этой машины, а результаты эксперимента были опубликованы только через несколько лет, весть быстро разнеслась по свету, и другие производители
тоже занялись разработкой подобных архитектур.
В 1980 году группа разработчиков в университете Беркли во главе с Дэвидом
Паттерсоном и Карло Секвином начала разработку процессоров VLSI без использования интерпретации. Для обозначения этого понятия они придумали термин RISC и назвали новый процессор RISC I, вслед за которым вскоре был выпущен RISC II. Немного позже, в 1981 году, Джон Хеннеси в Стенфорде разработал и выпустил другую микросхему, которую он назвал MIPS. Эти две микросхемы развились в коммерчески важные продукты SPARC и MIPS соответственно.
Новые процессоры существенно отличались от коммерческих процессоров того времени. Поскольку они не были совместимы с существующей продукцией, разработчики вправе были включать туда новые наборы команд, которые могли бы увеличить общую производительность системы. Так как основное внимание уделялось простым командам, которые могли быстро выполняться, разработчики вскоре осознали, что ключом к высокой производительности компьютера была разработка команд, к выполнению которых можно быстро приступать. Сколько времени занимает выполнение одной команды, было не так важно, как то, сколько команд может быть начато в секунду.
В то время как разрабатывались эти простые процессоры, всеобщее внимание
привлекало относительно небольшое количество команд (обычно их было около 50). Для сравнения: число команд в DEC VAX и больших IBM в то время составляло от 200 до 300. RISC — это сокращение от Reduced Instruction Set Computer - компьютер с сокращенным набором команд. RISC противопоставлялся CISC (Complex Instruction Set Computer — компьютер с полным набором команд). В качестве примера CISC можно привести VAX, который доминировал в то время в научных компьютерных центрах. На сегодняшний день мало кто считает, что главное различие RISC и CISC состоит в количестве команд, но название сохраняется до сих пор.
С этого момента началась грандиозная идеологическая война между сторонниками RISC и разработчиками VAX, Intel и больших IBM. По их мнению, наилучший способ разработки компьютеров — включение туда небольшого количества простых команд, каждая из которых выполняется за один цикл тракта данных (см. рис. 2.2), то есть берет два регистра, производит над ними какую-либо арифметическую или логическую операцию (например, сложения или логическое И) и помещает результат обратно в регистр. В качестве аргумента они утверждали, что даже если RISC должна выполнять 4 или 5 команд вместо одной, которую выполняет CISC, притом что команды RISC выполняются в 10 раз быстрее (поскольку они не интерпретируются), он выигрывает в скорости. Следует также отметить,
что к этому времени скорость работы основной памяти приблизилась к скорости специальных управляющих постоянных запоминающих устройств, потому недостатки интерпретации были налицо, что повышало популярность компью i-теров RISC.
Учитывая преимущества производительности RISC, можно было бы предпо-
ложить, что такие компьютеры, как Alpha компании DEC, стали доминировать над компьютерами CISC (Pentium и т. д.) на рынке. Однако ничего подобного не произошло. Возникает вопрос: почему?
Во-первых, компьютеры RISC были несовместимы с другими моделями, а многие компании вложили миллиарды долларов в программное обеспечение для продукции Intel. Во-вторых, как ни странно, компания Intel сумела воплотить те же идеи в архитектуре CISC. Процессоры Intel, начиная с 486-го, содержат ядро RISC, которое выполняет самые простые (и обычно самые распространенные) команды за один цикл тракта данных, а по обычной технологии CISC интерпретируются более сложные команды. В результате обычные команды выполняются быстро, а более сложные и редкие - медленно. Хотя при таком «гибридном» подходе работа происходит не так быстро, как у RISC, данная архитектура имеет ряд преимуществ, поскольку позволяет использовать старое программное обеспечение без изменений.
Лекция 3. Принципы разработки современных компьютеров.
1. Основные принципы разработки.
2. Параллелизм на уровне команд.
3. Параллелизм на уровне процессоров.
Дата публикования: 2014-10-17; Прочитано: 1853 | Нарушение авторского права страницы | Мы поможем в написании вашей работы!
